Что такое SEO и как самостоятельно начать Сео оптимизацию и продвижение сайта
Здравствуйте, уважаемые читатели блога KtoNaNovenkogo.ru. Сегодня я хочу поговорить про то, что такое Seo, показать современные методы Сео оптимизации, которая способна буквально творить чудеса в продвижении сайта и ответить на вопрос, почему не стоит ни в коем случае пренебрегать Search Engine Optimization.
На самом деле, хоть эта статья и адресована в первую очередь начинающим вебмастерам, но по своему опыту могу судить, что многие состоявшиеся вебмастера Seo продвижением просто пренебрегают и даже не стараются понять его суть.

Есть очень избитая фраза, которая почему-то стала для многих догмой — пишите статьи для людей и успех не заставит себя ждать. Да, контент (содержимое) безусловно является основополагающим столпом успешного развития сайта, но далеко не единственным и уж никак не достаточным.
Seo — что это такое
Если говорить максимально простыми словами, то:
SEO — это любые действия, направленные на вывод вашего сайта или любого другого вашего ресурса в топовые позиции поисковиков для привлечение посетителей.
SEO — это аббревиатура от Search Engine Optimization, что можно перевести как «оптимизация под поисковые движки» или «поисковая оптимизация». Т.е. сюда относятся любые способы улучшения позиций вашего сайта в выдачах поисковых систем по нужным вам запросам. Это влечет к увеличению целевого трафика (потока посетителей) на ваш сайта с поисковиков.
Теперь дадим более научно определение термину:
Поисковая оптимизация (SEO) — это комплекс мер по внутренней и внешней оптимизации для поднятия позиций сайта в результатах выдачи поисковых систем по определённым запросам пользователей, с целью увеличения сетевого трафика (для информационных ресурсов) и потенциальных клиентов (для коммерческих ресурсов) и последующей монетизации (получение дохода) этого трафика.
Этой статьей я хочу приоткрыть вам глаза на реальное положение дел (как его вижу я) и попробовать переманить вас на «темную сторону силы» (ведь Seo это не совсем и не всегда белые методы). Вообще заниматься оптимизацией, как внутренней, так и внешней, нужно обязательно с четким понимание того, что именно вы делаете и к чему это может привести. Уже страшно? Хочется все бросить и сказать: «ну его на фиг, пусть все идет как шло»? Тоже выход, но не лучший.
Начнем с каменного века. Интернет формировался как большая помойка, где наряду с алмазами соседствовали огромные массы гумна. Собственно, он и до сих пор таким остается. Главная проблема как пользователя, так и вебмастера создавшего качественный ресурс, это найти друг друга.
Решение есть и его предложили разработчики поисковых систем (читайте о том, как работают поисковики). Они создали площадки (нечто похожее на биржи), где пользователь мог найти ресурсы отвечающие на заданный им вопрос. Но это решение имеет некоторое ограничение. Реальные шансы на переходы из поисковой выдачи имеют только те ресурсы, которые смогли попасть на ее первую страницу (так называемый Топ 10). А это означает, что рано или поздно за место в Топ 10 начнется грызня и эта грызня началась.
SEO — это, по большому счету, искусство попадания на первую страницу выдачи Яндекса или Гугла по интересующему вас поисковому запросу.
Поисковики до сих пор не могут предложить какое-нибудь решение, позволяющее сайтам, находящимся в выдаче существенно ниже 10 позиции, получать хотя бы капелюшечку от числа тех посетителей, которые вводят в поисковике интересующий их вопрос.
Фактически получается, что жизни за Топ 10 нет. Поэтому драка идет не шуточная и любые методы Сео оптимизации, способные перетянуть чащу весов в свою сторону, используются обязательно. Вообще ситуация очень похожа на то, как это было изображено на заглавной картинке в статье про ранжирование и релевантность сайтов в поисковой выдаче:
Но ведь Сео это не только технология, но еще и огромный бизнес.
Знаете сколько заработают ведущие компании из этой отрасли? В сумме, думаю, сотни миллионов долларов, что вполне сравнимо с доходами Яндекса. Как, вы не знали, что поисковики это сверхдоходные и сверхприбыльные предприятия? Ну, вот теперь знайте. Зарабатывают поисковые системы Гугл и Яндекс на показе контекстной рекламы (Директ и Адвордс).
А кто заказывает у поисковиков рекламу? В большинстве своем владельцы коммерческих ресурсов для привлечения к себе посетителей. И вся фишка в том, что оба эти бизнеса (контекстная реклама и оказание услуг Сео продвижения) являются по отношению друг к другу конкурентными.
Т.е. вы должны понимать, что Seo реально работает и не использовать его было бы большой оплошностью. Ваши потенциальные читатели, которые не смогут найти ваш замечательный сайт через Яндекс или Гугл, вам этого не простят.
Мало создать хороший проект с уникальным и нужным контентом, его обязательно нужно продвинуть в Топ 10 хотя бы по ряду не очень частотных запросов, чтобы начать привлекать к себе внимание читателей.
Легко ли сейчас быть Сео-шником
Сейчас работать в области SEO может далеко не каждый человек. Тут нужен особый склад характера, ибо существует целый ряд проблем, с которыми постоянно сталкивается подобный специалист:
- Работать приходится в условиях постоянно (перманентно) изменяющихся алгоритмов работы поисковых систем. Базовые принципы, описанные в приведенной по ссылке статье, остаются постоянными, однако меняются нюансы, которые оказывают существенное влияние на успех кампании по продвижению сайта. По сути, любые ранее обнаруженные Сеошниками закономерности могут перестать работать в одночасье, и никто не может гарантировать работоспособность используемых сейчас методов. Люди, любящие стабильность и определенность, на такой работе не приживутся.
- Будучи SEO специалистом вы можете не спать ночами, думать, делать, и в течении полугода буквально «жить» проектом заказчика, но в результате дела у продвигаемого сайта могут даже ухудшиться. Одновременно кто-то может палец о палец не ударить, а продвигаемый им проект будет расти в выдаче. Отсюда следует достаточно низкая мотивация Сеошников к свершению трудового подвига. Многое просто не в их власти, и успех зачастую может определить что-то, что воле сеошника не подвластно.
- Мало того, что результат в SEO по большому счету не гарантирован, так еще и действительно грамотных (опытных) специалистов в этой области довольно-таки мало, и уж точно меньше, чем это востребовано рынком. Поэтому средняя квалификация среднего сеошника довольно низкая. По сути, нет институтов или академий, которые бы их готовили. Или, во всяком случае, в достаточном количестве и надлежащего качества. Люди учатся по курсам, уже не актуальным книгам, статьям и блогам.
- Процессу повышения образованности сеошников прежде всего препятствует то, что предмет их изучения не хочет, чтобы они его изучали и узнавали. Поисковые системы ни в коей мере не заинтересованы в открытом диалоге с SEO специалистами, ибо, по сути, находятся с ними по разные стороны баррикад. Поэтому знания приходится получать путем наблюдения за поисковыми машинами и постановкой экспериментов, что не является самым простым и эффективным способом. Между собой сеошники тоже не так уж и охотно делятся своими наработками.
- Не все сайты предлагаемые заказчиками можно продвинуть средствами SEO в современных условиях. Они могли быть разработаны либо очень давно, либо без учета их возможного продвижения в поисковых системах.
- Зачастую владельцы сайтов сами не знают чего хотят, и сформулированные ими в задачах цели продвижения совершенно не соответствуют тому, что они на самом деле хотят получить в результате работы Сео специалиста. Возникают непонятки, но клиент, как всегда, прав и...
Под какой поисковик продвигаться?
Кроме всех описанных выше сложностей, Сео-шники вынуждены при продвижении сайтов пытаться «услужить» по крайней мере двум хозяевам — Яндексу и Гуглу. А если брать в расчет и поиск Mail.ru, то трем.
Если верить показаниям счетчика Ливинтернет, то в рунете (доменной зоне RU) сейчас наблюдается примерный паритет между Яндексом и Гуглом, а доля остальных поисковых систем исчезающе мала на их фоне (разве что только за исключение Майла, но там особая аудитория, которая в основном состоит из пользователей других сервисов этой корпорации).
Гул здорово подрос за последние годы, ибо раньше перевес у Яндекса был чуть ли не двухкратный. Секрет кроется в том, что сейчас идет тенденция к увеличению доли мобильного трафика (посетителей, заходящих на сайты со смартфонов и планшетов), а у Google тут огромное преимущество в виде собственной мобильной платформы Андроид и предустановленным там по умолчанию их поиском. Ход конем, что называется.
Как видно из данных того же Лайвинтернета, трафик с Андроида составляет больше трети от всего трафика рунета. Вы только вдумайтесь? А если брать в расчет и другие мобильные платформы, то число людей заходящих в сеть с мобильника уже превысило число тех, кто заходит с ПК или ноутбука. Дальше будет еще больший уход в мобильность и это опять же добавляет новых проблем сеошникам и маркетолагам, ибо существенно меняется поведение пользователей на сайте.
По-любому, от продвижения в Google (а уже тем более в Яндексе, ибо именно там сидит большая часть целевой аудитории по многим коммерческим тематикам) никто просто так отказаться не может, и практически все коммерческие сайты сейчас продвигаются под оба этих поисковика.
Ну, а если сайт будет ориентирован на буржунет, то там уже у Гугла вообще практически нет достойных конкурентов. На мировом уровне они даже не сопоставимы. Людские, финансовые и аппаратные ресурсы отличаются на порядок. А это влияет на то, как работают алгоритмы Google, и на то, как быстро он работает в целом.
Кроме этого, если опять вернуться к рунету, у Яндекса и Гугла существенно отличаются аудитории. Может вполне оказаться так, что вся ваша целевая аудитория пользуется только Гуглом (или только Яндексом).
Скажем так, в Яндексе больше чайников. И это вовсе не плохо, ибо из них получаются отличные покупатели, но если ваш товар или услуга ориентирована на чуть более продвинутых пользователей, то Google может стать для вас основным источником трафика. Какие-то глобальные исследования на этот счет вы вряд ли найдете в паблике, но я думаю, что начав развивать и продвигать сайт, вы быстро поймете, какая поисковая машина для вас является приоритетной.
Если говорить про поиск Майл.ру, то его доля в рунете составляет где-то около пяти процентов и обусловлена она прежде всего тем, что все сервисы Майла собирают огромную аудиторию в рунете (даже большую, чем все сервисы Яндекса). При этом у них периодически меняется поисковый движок. Они постоянно торгуются с Яндексом и Google о предоставлении им лучших условий, а когда договориться не удается, то временно используют свой собственный движок gogo.ru.
Белое, серое и черное SEO
Итак, SEO специалист должен будет всеми правдами и неправдами заставить упомянутые выше поисковые системы обратить внимание на продвигаемый им сайт (хотя бы в плане его полной индексации) и каким-то хитрым и непонятным способом принудить их его полюбить. И это все при том, что поисковики в своих лицензиях четко говорят, что при ранжировании и определении релевантности документов ими будут учитываться исключительно интересы пользователей поиска, а отнюдь не владельцев ресурсов.
Значит придется «хитрить» и зачастую идти на сознательное нарушение всех этих лицензий. В зависимости от степени ухищрений и глубины нарушений правил поисковых систем SEO продвижение можно разделить на три группы:
- Белая SEO оптимизация — все предпринимаемые действия будут идти в полном согласии с лицензиями поисковиков. Этот путь сложен, трудоемок, с низкой и сильно оттянутой по времени отдачей. Но в то же время он самый надежный, стабильный и за его использование не последует пессимизация, фильтры или бан.
- Прогнозирование запросов, по которым пользователи Яндекса или Гугла могут попасть на ваш сайт. Фактически это сборка семантического ядра с помощью, например, подбора ключевых слов в Вордстате и создания страниц под них оптимизированных. Поисковые системы это приветствуют, ибо им потом проще будет искать релевантную запросу информацию. Но тут, естественно, не идет речь о переоптимизации, ибо это уже является нарушением лицензии.
- Оптимизация структуры контента и его внутренней перелинковки. Поисковики опять же не будут возражать, если вы таким образом поможете их роботам быстрее найти и правильно обработать имеющийся контент. А также показать степень важности тех или иных материалов на вашем сайте. Но опять же без фанатизма.
- Естественное наращивание ссылочной массы. Ключевое слово здесь «естественное», но об этом мы поговорим чуть позже.
- Серое SEO — не совсем согласуется с лицензиями поисковых систем, но именно этот способ оптимизации является наиболее популярным и массовым среди Сеошников. Однако, это может быть воспринято, как попытки манипуляции выдачей, и на ваш сайт могут быть наложены санкции (фильтры).
- Покупка и обмен ссылками в больших масштабах
- Переоптимизация текстов (спам ключевыми словами) для повышения их релевантности в глазах поисковых систем
- Черная оптимизация — откровенное нарушение лицензии поисковиков, за что гарантированно можно получить наложение санкций (вопрос только в сроках, в течении которых вас обнаружат и прижучат).

Однако, эти методы по-прежнему используются, и в выдаче Яндекса и Гугла можно по некоторым запросам наблюдать, например, засилье дорвеев, а в индексе поиска все так же имеется огромное количество ГС (смотрите непонятные вам термины в статье про то, как начать понимать Сеошников).
Перечислю примеры черного SEO без вдавания в конкретику, ибо никогда этим не занимался и заниматься не намерен:
- ГС и Дорвеи — создаваемые вручную или автоматически «плохие» сайты, которые призваны обманывать поисковики (попадать в индекс, чтобы с них можно было продавать ссылки, или даже в Топ выдачи, чтобы на них шел трафик, который потом будет перепродаваться), но никакой полезности для посетителей не имеющие.
- Клоакинг
- Скрытый (невидимый) текст
- Что-то еще, о чем можно прочитать в лицензиях (см. лицензию Яндекса для примера).

Что нужно знать про работу поисковых систем
Однако для того, чтобы применять озвученные способы оптимизации, сеошник должен прежде всего понимать хотя бы общие принципы работы поисковых машин. И чем более рискованным SEO он собирается заниматься, тем более глубокими и детальными должны быть его познания.
Индексация сайтов
Работу начинает поисковый робот (бот), который представляет из себя обычный компьютер (сервер) с соответствующим ПО. Он обходит страницы с потенциальным наличием качественного и уникального контента, находит вебстраницу, определяет ее содержимое (объем, качество), и если она ему понравится, то он передает ее на следующий уровень, который можно определить, как поисковик.
В силу аппаратных ограничений роботы не снуют в интернете как заведенные, а руководствуются определенными принципами. Во-первых, они ходят на страницы, на которые проставлено много ссылок со страниц, которые уже есть в индексной базе. Во-вторых, частота повторного посещения не всегда высока и рассчитывается индивидуально.

У Яндекса можно выделить два типа роботов:
- Основной робот — индексация основного контента, не имеющего новостного характера, когда нужно будет быстро добавить его в выдачу. Тут ранжирование идет по полному циклу, в отличии от описанного ниже быстробота.
- Быстробот — поисковый робот, который призван наполнять выдачу наисвежайшими материалами. Он посещает сайты, где часто появляется новая информации (например, блоги с RSS лентой или новостные ресурсы). Найденные им страницы ранжируются, опираясь лишь на некоторые внутренние факторы, и они мгновенно появляются в выдаче с указанием даты их создания. Но на следующий день позиции по этим запросам могут измениться после прихода основного робота индексатора.
Поиск нужной информации в индексе
Поисковик представляет из себя опять же обычный сервер (что такое сервер), но с уже другим программным обеспечением. В его задачу входит обход найденных ботом страниц, скачивание их содержимого и дальнейшая его обработка (создание индекса).
Все помеченные поисковым роботом страницы выкачиваются (в виде исходных Html кодов), из них извлекается контент (текст заключенный в Html коде, который должен видеть посетитель) и производится его первичный разбор и анализ. Текст вебстраницы записывается в отдельный файл (условно) и туда же записываются все ссылки, найденные на странице (они потом отправляются поисковому роботу, чтобы он туда сходил тоже).
Из полученного текста удаляются все стоп-слова (союзы, предлоги) и знаки препинания. Полученный в результате набор слов разбивают на так называемые пассажи. По сути, это предложения, но с некоторыми допущениями. Пассажи, как и предложения, объединяются смысловой законченностью, но оперировать именно предложениями, при машинном анализе русского текста, практически не возможно (в силу его «великости и могучести»).
Т.е. анализ ведется не по физическим (изначально имеющимся в тексте) предложениям, а по вновь созданным (машинным), которые и назвали пассажами. Ну, а эти самые пассажи уже складываются в индексную базу и каждому пассажу присваивается свой вес, характеризующий его значимость внутри этого текста. Отчего может зависеть вес? Например, от того, насколько пассаж релевантен данному тексту, сколько раз он в нем повторяется и где внутри текста он расположен.
В результате формируется база данных (поисковый индекс), в которой каждая проиндексированная вебстраница представлена набором пассажей с удаленными шумовыми словами (бессмысленными, связующими, паразитными, повторениями). Именно по этой базе (индексу) ведется поиск.
Когда вам нужно будет вогнать в индекс новые страницы, появившиеся на сайте, то лучшим вариантом будут сервисы по привлечению быстробота (индексатора) поисковых систем. Среди них могу выделить два похожих — IndexGator и GetBot. Стоит это дело совсем не дорого, а эффект достаточно стабилен.
Определение релевантности и ранжирование результатов
На самом верхнем (к пользователям поисковых систем) находится поисковый сервис, который принимает запросы от пользователей, и на основании расчета релевантности и применения факторов ранжирования выбирает (из созданного на предыдущем этапе поисковиком обратного индекса) нужные вебстранички, которые потом и будут показаны пользователю в качестве выдачи (серпа).
Упрощенно это можно представить так, что посетитель Яндекса задает свой вопрос и поисковая система начинает искать в своей индексной базе страницы содержащие пассажи, максимально соответствующие этому запросу. Полученный список релевантных страниц теперь нужно будет ранжировать (расставить приоритеты), т.е. определить последовательность расположения этих вебстраниц в выдаче.

Первый принцип, который начал использоваться уже очень давно, называется индексом цитирования. В его базовой версии он учитывал число упоминаний данной страницы (число ведущих на нее ссылок). Об этой системе я довольно подробно писал в статье про то, что такое Тиц и Виц сайта в Яндексе. Недостаток такого подхода состоит в том, что учитывается только общее количество ссылок, но не их качество.
Поэтому далее был придуман взвешенный индекс цитирования, который учитывает авторитет и качество ссылающихся сайтов. Появляются так называемые веса (статические), которые передаются по ссылкам. В Google это индекс называется Пейдж Ранком, тулбарное значение которого раньше можно было узнать для любой страницы любого сайта (сейчас это дело прикрыли).
Взвешенный индекс цитирования можно описать, как коэффициент вероятности попадания посетителя на данную вебстраницу с любой другой страницы сети интернет. Другими словами, чем больше на эту страницу ссылок и чем больше среди ссылающихся ресурсов будет авторитетных, тем вероятнее будет посещение данной страницы и тем выше будет ее вес. Рассчитывается он с помощью формулы в несколько итераций. Формула эта периодически изменяется и дорабатывается.
Раньше мы могли наблюдать тулбарное значение ПейджРанка, которое обновлялось раз в несколько месяцев и было построено на основе логарифмической шкалы, когда реальная разница между весом страницы с ПР=1 и ПР=7 могла быть тысячекратной или даже больше. Подробности читайте в упомянутой чуть выше статье.
Также следует понимать, что то или иное значение ПейдРанка для вашей страницы на ее позицию в выдаче по тому или иному поисковому запросу прямого влияния оказывать не будет. Но в то же время алгоритм, заложенный в расчете ПР, используется при ранжировании страниц, а значит его нужно знать и понимать, чтобы в дальнейшем использовать для своей пользы.
Учет трансляции ссылочных весов при ранжировании
В схеме ПейджРанка (взвешенного индекса цитирования) имеется такое понятие, как передаваемый по ссылке вес.
Статический вес передаваемый по ссылкам
Передача веса является не совсем правильным термином, ибо вес не передается, а транслируется, т.е. донор (читайте статью про SEO термины) ничего не теряет при установке ссылки, но при этом акцептор получает по ней определенный статический вес. Под термином статический следует понимать то, что этот вес не зависит от того, что используется в качестве анкора ссылки.
Сколько веса может передать та или иная вебстраница в интернете могут знать только алгоритмы поисковиков. Но доподлинно известно, что этот самый вес будет поровну поделен между всеми страницами-акцепторами, на который будут вести ссылки с этого донора. Исходя из этого принципа можно сделать массу выводов по внешней и внутренней перелинковки своего сайта.
Общий вывод по принципу трансляции весов — для того, чтобы прокачать какую-либо свою страницу, нужно получать на нее ссылки, желательно с авторитетных страниц. А как узнать, высок ли авторитет той или иной страницы в интернете? Правильно, нужно посмотреть на значение ПейджРанка для нее.
У Яндекса тоже имеется аналог пейджранка, который рассчитывается для всех страниц (ВИЦ), но узнать его значение сейчас не представляется возможным. Также у нашего поисковика имеется в арсенале еще и тематический индекс цитирования Тиц, при расчете которого прежде всего учитывается тематика ссылающихся ресурсов.
Измеряется он для всего сайта целиком. Для тематических ссылок (оценивается тематика по содержанию текста) применяется повышающий коэффициент, по сравнению с околотематическими и нетематическими, для которых может применяться серьезная сбавка передаваемого веса. Поэтому для наращивания Тиц важны ссылки не просто с авторитетных ресурсов, а желательно, чтобы они были близкой или совпадающей тематики с вашим сайтом. Напрямую на ранжирование он не влияет, но те же принципы используются для построения сайтов в выдаче.
Что такое PageRank, в чем он измеряется и как формируется
По сути он является своеобразным мерилом (критерием ценности) той или иной странички в интернете. Его значение зависит от количества и качества обратных ссылок, ведущих с других страниц на данный документ. Чем больше ссылок — тем выше будет значение ПР.
Но так же очень важным является то, какое значение статического веса имеет та страничка, с которой ведет ссылка на документ. Дело в том, что по ссылке передается часть значения PageRank странички донора.
Но и это еще не все. Дело в том, что если со странички донора проставлено несколько ссылок (одна из которых на наш документ), то передаваемый статический вес будет поделен между всеми этим линками поровну.
То количество PR, которое страничка может передать по ссылке, намного меньше ее собственного значения (раньше это было 85 процентов, а сейчас по наблюдениям уже меньше 10%). Это количество статвеса и будет делиться между документами, на которые она ссылается.
Идеальным будет случай, если со странички имеющей Page Rank равный 10 (максимально значение) на ваш документ будет проставлена ссылка, открытая для индексации (без атрибута rel="nofollow"). И совсем здорово будет, если она будет одна единственная.
В этом случае вашем документу будет передан гигантский вес, достаточный, наверное, чтобы ПР вашей странички поднялся до 9. Если же с этого идеального донора будет проставлено еще несколько ссылок (включая вашу), то вес, передаваемый по каждой из них, будет уже поделен на общее количество и девятку вы уже не получите. Обидно, правда? А так хотелось.
Да, чуть не забыл рассказать о том, как и в чем измеряется значение PageRank, а так же о том, как запретить передачу голоса (веса) по ссылке, ведущей со страничек вашего проекта. Сначала о единицах измерения. Тут существует две шкалы и, соответственно, два значения.
Первый из вариантов представления выражает его вещественным числом и имеет линейный характер изменения. Т.е. увеличение этого значения будет пропорционально увеличению количества статического веса, передаваемого на данный документ по ссылкам с других ресурсов интернета. Это число обновляется практически в реальном времени и постоянно учитывается при ранжировании.
Второй вариант представлял PR является производным от первого. Это значение называлось тулбарным значением и имело диапазон изменения от 0 до 10 (всего получается одиннадцать возможных вариантов).
Сейчас Гугл не дает возможности посмотреть тулбарное значение ПейжРанка.
Тулбарная цифра получалась из вещественного числа по закону близкому к логарифмическому (сильно нелинейному):
| Вещественное число, обозначающее реальный статвес | Тулбарное число, получаемое в результате |
|---|---|
| от 0,00000001 до 5 | 1 |
| от 6 до 25 | 2 |
| от 26 до 125 | 3 |
| от 126 до 625 | 4 |
| от 626 до 3125 | 5 |
| от 3126 до 15625 | 6 |
| от 15626 до 78125 | 7 |
| от 78126 до 390625 | 8 |
| от 390626 до 1953125 | 9 |
| от 1953126 до бесконечности | 10 |
Тулбарная цифирька обновлялась не часто — раз в несколько месяцев. Его нулевое значение обычно имеют новые ресурсы или же проекты, попавшие под бан Google, а цифру равную 10 имеют только несколько колоссов во всем интернете.
Как вы можете видеть из приведенной выше таблицы — сначала для наращивания Page Rank не потребуется много ссылок с хорошим весом, но с каждым новой цифирькой его дальнейшее увеличение становится все более сложной, а зачастую и невыполнимой задачей.
В среднем, хорошо оптимизированные (и внутренне, и внешне) ресурсы имеют PR главной страницы равный 4 или 5, а некоторые добиваются даже шестерки, но дальнейший рост этого показателя доступен только очень серьезным и глобальным проектам.
Так что, предел наших с вами мечтаний и возможностей — это скорей всего 6, да и то вряд ли. Скажете, что я пессимист?! Да нет, скорее я реалист. Но если вы вдруг получите (или уже получили) Пейдж Ранк равный 7, то отпишитесь, пожалуйста, об этом в комментариях (и обязательно поставьте ссылку на https://ktonanovenkogo.ru, чтобы и у меня стало все хорошо).
Запрещаем передачу статического веса через внешние ссылки
В принципе, сделать это совсем не сложно. Google позаботился о том, чтобы была возможность не отдавать голос на другой ресурс. Для этого достаточно будет добавить в тег ссылки A атрибут rel="nofollow" (чуть выше я уже приводил линк на статью, где это подробно все разжевывается). Например так:
<a href="https://ktonanovenkogo.ru" >Все о создании сайтов, блогов, форумов, интернет-магазинов, их продвижении в поисковых системах и заработке на сайте</a>
После этого статвес с донора не будет передаваться на акцептор (тот документ, на который ведет линк). Для чего может понадобиться запрещать передачу веса? Тут все довольно просто. Нужно только вспомнить, что PR может передаваться не только по ссылкам, ведущим на другие проекты, но и по линкам, ведущим на внутренние страницы вашего же ресурса.
Теперь представьте такую ситуацию, что у вас в одном документе проставлено десять внутренних и десять внешних ссылок. Всего получается двадцать. Статический вес, передаваемый по каждой из них, будет равен одной двадцатой от максимально возможного, который способен отдать данный документ (донор). Следовательно, акцепторы получат одну двадцатую максимально возможного веса (пейджранка).
А теперь представьте, что во всех внешних ссылка вы прописали атрибут rel="nofollow", тем самым запретив передавать по ним вес. В результате весь вес, который способен отдать донор, будет распределен между десятью внутренними ссылками. По каждой из них будет передан вес в одну десятую от максимально возможного, что в два раза больше, чем в случае без использования атрибута rel="nofollow".
Таким образом, вы препятствуете утеканию PageRank с вашего проекта, аккумулируя его внутри и повышая свои собственные пузомерки. В результате, эти странички вашего ресурса при прочих равных условиях смогут занять более высокое место в поисковой выдаче Google за счет сбереженного статвеса.
P.S. Есть мнение, что сейчас Гугл несколько изменил действие атрибута rel="nofollow" и ваши внутренние документы в приведенном примере все равно получат по одной двадцатой веса, а все остальное утечет неизвестно куда. Мнение спорно, но...
Динамический вес, зависящий от текста ссылки (анкора)
До этого момента мы говорили только про статические веса. Однако, при расчете трансляции веса для любой ссылки, поисковые машины используют два типа весов. Первый — статический, о котором мы уже поговорили и который рассчитывается без учета текста ссылки (ее анкора). Второй — динамический (анкорный), который рассчитывается на основании нескольких параметров:
- Тематика донора (откуда проставлена ссылка)
- Содержимое (тематика) анкора
- Тематичность акцептора (страницы вашего сайта)
Чем более релевантны эти три составляющие, тем более высокий анкорный вес будет транслировать ссылка. Если у ссылки нет анкора (безанкорная), то динамический вес, передаваемый по ней, не рассчитывается вовсе. Статический вес передается всегда, если только сайт донор не находится под фильтром поисковых систем за продажу бэклинков.
Отсюда можно сделать очень важный вывод — любая ссылка, проставленная на ваш сайт, может быть ценна для вас двумя своими весами. Во-первых, мы нагоняем статический вес своей вебстраницы, что есть хорошо. Но если еще грамотно использовать анкор, то значимость этой же ссылки может быть увеличена в несколько раз.
Что нужно сделать, чтобы получить высокий анкорный вес? Попробуем расписать по пунктам:
- Донор должен иметь максимально возможный авторитет в поисковых системах. Точнее та страница, откуда проставляется бэклинк. Раньше можно было об этом судить, глядя на значение ПейджРанка этой страницы — чем меньше оно будет отличаться от 10, тем лучше, но сейчас это увы в прошлом. Придется пользоваться платными инструментами различных сервисов проверки сайта.
- Страница-донор должна быть максимально близка по тематике к странице-акцептору (продвигаемой вами).
- Анкор ссылки тоже должен быть максимально тематическим странице-акцептору (ее контенту, т.е. тексту).
Про использование в анкорах прямых и разбавленных вхождений ключевых слов вы можете почитать по приведенной чуть выше ссылке.
Алгоритмы прямых и обратных индексов
Очевидно, что метод простого перебора всех страниц, хранящихся в базе данных, не будет являться оптимальным. Этот метод называется алгоритмом прямого поиска и при том, что этот метод позволяет наверняка найти нужную информацию не пропустив ничего важного, он совершенно не подходит для работы с большими объемами данных, ибо поиск будет занимать слишком много времени.
Поэтому для эффективной работы с большими объемами данных был разработан алгоритм обратных (инвертированных) индексов. И, что примечательно, именно он используется всеми крупными поисковыми системами в мире. Поэтому на нем мы остановимся подробнее и рассмотрим принципы его работы.
При использовании алгоритма обратных индексов происходит преобразование документов в текстовые файлы, содержащие список всех имеющихся в них слов.
Слова в таких списках (индекс-файлах) располагаются в алфавитном порядке и рядом с каждым из них указаны в виде координат те места в вебстранице, где это слово встречается. Кроме позиции в документе для каждого слова приводятся еще и другие параметры, определяющие его значение.
Если вы вспомните, то во многих книгах (в основном технических или научных) на последних страницах приводится список слов, используемых в данной книге, с указанием номеров страниц, где они встречаются. Конечно же, этот список не включает вообще всех слов, используемых в книге, но тем не менее может служить примером построения индекс-файла с помощью инвертированных индексов.
Обращаю ваше внимание, что поисковики ищут информацию не в интернете, а в обратных индексах обработанных ими вебстраниц сети. Хотя и прямые индексы (оригинальный текст) они тоже сохраняют, т.к. он в последствии понадобится для составления сниппетов, но об этом мы уже говорили в начале этой публикации.
Алгоритм обратных индексов используется всеми системами, т.к. он позволяет ускорить процесс, но при этом будут неизбежны потери информации за счет искажений внесенных преобразованием документа в индекс-файл. Для удобства хранения файлы обратных индексов обычно хитрым способом сжимаются.
Математическая модель используемая для ранжирования
Для того, чтобы осуществлять поиск по обратным индексам, используется математическая модель, позволяющая упростить процесс обнаружения нужных вебстраниц (по введенному пользователем запросу) и процесс определения релевантности всех найденных документов этому запросу. Чем больше он соответствует данному запросу (чем он релевантнее), тем выше он должен стоять в поисковой выдаче.
Значит основная задача, выполняемая математической моделью — это поиск страниц в своей базе обратных индексов соответствующих данному запросу и их последующая сортировка в порядке убывания релевантности данному запросу.
Использование простой логической модели, когда документ будет являться найденным, если в нем встречается искомая фраза, нам не подойдет, в силу огромного количества таких вебстраниц, выдаваемых на рассмотрение пользователю.
Поисковая система должна не только предоставить список всех веб-страниц, на которых встречаются слова из запроса. Она должна предоставить этот список в такой форме, когда в самом начале будут находиться наиболее соответствующие запросу пользователя документы (осуществить сортировку по релевантности). Эта задача не тривиальна и по умолчанию не может быть выполнена идеально.
Кстати, неидеальностью любой математической модели и пользуются оптимизаторы, влияя теми или иными способами на ранжирование документов в выдаче (в пользу продвигаемого ими сайта, естественно). Матмодель, используемая всеми поисковиками, относится к классу векторных. В ней используется такое понятие, как вес документа по отношению к заданному пользователем запросу.
В базовой векторной модели вес документа по заданному запросу высчитывается исходя из двух основных параметров: частоты, с которой в нем встречается данное слово (TF — term frequency) и тем, насколько редко это слово встречается во всех других страницах коллекции (IDF — inverse document frequency).
Под коллекцией имеется в виду вся совокупность страниц, известных поисковой системе. Умножив эти два параметра друг на друга, мы получим вес документа по заданному запросу.
Естественно, что различные поисковики, кроме параметров TF и IDF, используют множество различных коэффициентов для расчета веса, но суть остается прежней: вес страницы будет тем больше, чем чаще слово из поискового запроса встречается в ней (до определенных пределов, после которых документ может быть признан спамом) и чем реже встречается это слово во всех остальных документах проиндексированных этой системой.
Оценка качества работы формулы асессорами
Таким образом получается, что формирование выдач по тем или иным запросам осуществляется полностью по формуле без участия человека. Но никакая формула не будет работать идеально, особенно на первых порах, поэтому нужно осуществлять контроль за работой математической модели.
Для этих целей используются специально обученные люди — асессоры, которые просматривают выдачу (конкретно той поисковой системы, которая их наняла) по различным запросам и оценивают качество работы текущей формулы.
Все внесенные ими замечания учитываются людьми, отвечающими за настройку матмодели. В ее формулу вносятся изменения или дополнения, в результате чего качество работы поисковика повышается. Получается, что асессоры выполняют роль такой своеобразной обратной связи между разработчиками алгоритма и его пользователями, которая необходима для улучшения качества.
Основными критериями в оценке качества работы формулы являются:
- Точность выдачи поисковой системы — процент релевантных документов (соответствующих запросу). Чем меньше не относящихся к теме запроса вебстраниц (например, дорвеев) будет присутствовать, тем лучше
- Полнота поисковой выдачи — процентное отношение соответствующих заданному запросу (релевантных) вебстраниц к общему числу релевантных документов, имеющихся во всей коллекции. Т.е. получается так, что во всей базе документов, которые известны поиску вебстраниц соответствующих заданному запросу будет больше, чем показано в поисковой выдаче. В этом случае можно говорить о неполноте выдаче. Возможно, что часть релевантных страниц попала под фильтр и была, например, принята за дорвеи или же еще какой-нибудь шлак.
- Актуальность выдачи — степень соответствия реальной вебстраницы на сайте в интернете тому, что о нем написано в результатах поиска. Например, документ может уже не существовать или быть сильно измененным, но при этом в выдаче по заданному запросу он будет присутствовать, несмотря на его физическое отсутствие по указанному адресу или же на его текущее не соответствие данному запросу. Актуальность выдачи зависит от частоты сканирования поисковыми роботами документов из своей коллекции.
SEO словарь — как начать понимать термины, которые используют СЕО-шники
Люди, работающие в какой-то отрасли, используют в своем общении термины, которые помогают быстро объяснить суть дела не отвлекаясь на детали.
Из-за этого разговор профессионалов часто кажется непонятным неподготовленному слушателю, которому эти детали, ох как важны для понимания. То же самое происходит и в SEO отрасли, где общение происходит с использованием устоявшейся терминологии.

Все мы, конечно же, люди догадливые и по контексту можем домыслить смысл непонятных слов, но все же лучше будет разом с ними всеми ознакомиться, чтобы уже потом не ломать над этим голову. Собственно, в этой статье я и собрал те фразы, которыми изобилует речь Сеошников или тех, кто хочет ими казаться. Если что-то упустил или допустил ошибку в интерпретации, то попинайте в комментариях.
Серп, Топ, сниппет и тайтл
- SERP (выдача) — страница поисковой системы, которую видит пользователь в ответ на введенный им запрос. Состоит он из двух частей — органическая выдача (по десять результатов на одной странице) и контекстная реклама (несколько блоков сверху, снизу или сбоку от основных результатов поиска). Как раз за попадание в Топ 10 органики и ведут борьбу SEO специалисты.
Органическая выдача состоит из вебстраниц, которые признаны поисковой системой релевантными запросу. Чаще всего один сайт в выдаче представлен только один раз, но бывают и исключения. Например, в серпе по брендовым запросам.
Само объявление для каждой такой вебстраницы в выдаче (серпе) оформлено по определенным правилам. В Яндексе и Гугле их внешний вид чуток отличается (например, в Яндексе имеются фавиконы, а в Google могут быть фото авторов статей).
Заголовок этого объявления обычно берется из тайтла страницы (метатега Title, взятого из исходного Html кода) представленного сайта, но могут быть варианты и использования в качестве оного промежуточных заголовков имеющихся на этой странице. - Сниппет — располагается в выдаче чуть ниже тайтла и Урла любого объявления. Представляет из себя фрагмент текста взятого с вебстраницы попавшей в серп. Иногда поисковики формируют его на основе содержимого метатега description (описания страницы), но также этот текст может быть взят из самого тела статьи. Так же сниппет может изредка представлять из себя надпись «Ссылки на страницу содержат», когда искомый запрос не встречается на странице, а присутствует только в текстах ссылок, ведущих на нее. Пример смотрите чуть ниже при пояснении термина НПС.
По сути, это краткое содержание вебстраницы, которое берется из ее текста или содержимого мегатега дескрипшен. По нему пользователь поисковой системы может составить мнение о странице без перехода на нее. Сеошники пытаются влиять на сниппеты, ибо это позволит привлечь больше посетителей. Как это сделать? Думаю, что мы еще об этом поговорим поподробнее.
- Топ — как правило, под этим подразумевается первая страница выдачи поисковой системы. По умолчанию, на ней отображается десять наиболее релевантных запросу вебстраниц различных сайтов. Это можно назвать Топ 10. Однако, у Сеошников бывают разные задачи, поэтому встречаются такие вещи, как Топ 1, 3, 5, которые показывают тот потолок, которого они хотят достигнуть в результате продвижения (попасть на первое места серпа, в тройку или в пятерку первых). Процент переходов с разных мест первой страницы выдачи настолько разнится, что драка за Топ идет не на жизнь, а на смерть.
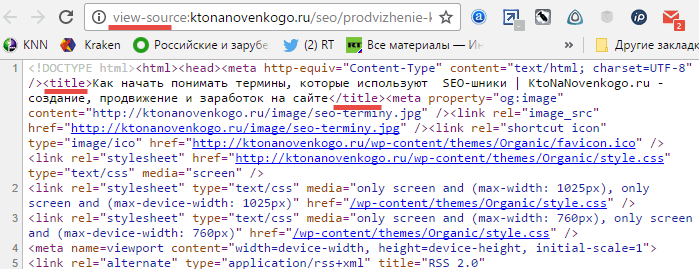
- Тайтл (title) — в Сео терминологии под этим понимают заголовок вебстраницы. Физически это текст, который в Html коде окружается тегами title и располагается в головной части (между тегами head).
В браузере его можно посмотреть, подведя курсор мыши к одной из открытых вкладок.
Заключенные в него ключевые слова будут иметь больший вес для поисковиков, и его содержимое часто используется в качестве заголовка объявления в поисковой выдаче (см. скриншот выше).
Индекс, ранжирование, фильтры и дэнс
- Индекс — база данных поисковых систем, где они хранят в разобранном на слова виде все содержимое интернета, которое им удалось проиндексировать. Поиск ведется не по «живым» текстам на сайтах, а именно по словам в этом индексе, что в сотни раз ускоряет процесс. Для того, чтобы начать продвижение страницы сайта, надо сначала дождаться того, пока она попадет в индекс и начнет участвовать в ранжировании по релевантным ее ключевым словам запросам (эти термины описаны чуть ниже).
- Ранжирование — сортировка сайтов в поисковой выдаче. У поисковых систем существует множество факторов (сотни) для ранжирования. Обычно, среди них выделяют такие группы, как внутренние (оптимизация сайта, внутренняя перелинковка), внешние (статический и динамический вес проставленных из вне ссылок), поведенческие факторы (поведение пользователей в выдаче и на самом сайте), а также социальные (расшаривания страниц в соцсетях, лайки, комментарии т.п.).
- Ключевые слова — они характеризуют содержимое вебстраницы, чтобы поисковой системе было проще понять о чем идет речь и каким запросам релевантна данная страница. В SEO это архиважный термин, ибо от правильного подбора ключевых слов и их дальнейшего использования на страницах сайта, а также в анкорах ссылок зависит успех продвижения.
- Поисковые запросы — то, что вводят пользователи в поисковую строку Яндекса, Гугла и других систем. Где можно посмотреть статистику поисковых запросов, чтобы на их основании выбрать себе ключевые слова? Правильно, в самих поисковиках. У них есть инструменты, помогающие пользователям контекстной рекламы получить доступ к этой информации. Читайте про это в статье по приведенной ссылке.
- Релевантность — соответствие поискового запроса содержимому вебстраницы. Все релевантные запросу документы попадают на стадию ранжирования, чтобы определить их позицию в итоговой выдаче. Хотите больше информации? Читайте статью про релевантность и ранжирование.
- Пессимизация — понижение страниц сайта в выдаче по каким-то отдельным или даже по всем поисковым запросам (ключевым словам). По сути, это искусственное занижение релевантности. Обычно является следствием каких-либо выявленных нарушений в оптимизации или продвижении. В следствии этого снижается трафик на сайт и сеошник начинает искать и исправлять причины наложения фильтра и пессимизм сайта.
- Фильтры — способы автоматической борьбы поисковых систем с сайтами, которые путем накруток пытаются занять место выше, чем они того заслуживают. С помощью фильтров поисковики пытаются нивелировать действия накруток. Чтобы выйти из под фильтра, нужно будет устранить причину его наложения (например, переоптимизацию текста, как это было в моем случае).
- Бан — полное исключение страниц сайта из индексной базы поисковой системы. Налагается за очень грубое нарушение лицензии использования поисковых систем (например, невидимый текст, клоакинг и другое). Более подробно про фильтры, пессимизацию и бан в Яндексе вы можете почитать по приведенной ссылке.
- Апдейт (ап) — в общем смысле слова, это обновление. Применительно к Сео и поисковым системам это может быть апдейт алгоритма ранжирования и вызванное этим обновление базы данных (рассчитанных на основе этих алгоритмов), которое происходит не сразу, а от апа к апу. Это приводит к изменению серпа (выдачи), т.е. меняются позиции сайтов по тем или иным запросам. Это и есть апдейт выдачи, который чаще всего и понимают под общим термином апдейта применительно к SEO. Можете почитать про апдейты, которые бывают в Яндексе.
- Дэнс — процесс изменения выдачи, который мы наблюдаем мониторя позиции своего сайта (они при этом могут прыгать на десятки и даже на сотни мест вверх или вниз). Дело в том, что поисковую выдачу не возможно обновить одномоментно после обновления или подкрутки алгоритма (программного обеспечения поисковиков). Это связано с ограниченностью технических возможностей. Кроме этого, сами алгоритмы имеют обратную связь и подстраиваться могут постоянно, поэтому дэнс может длится как днями, так и месяцами, пока все более-менее не устаканится.
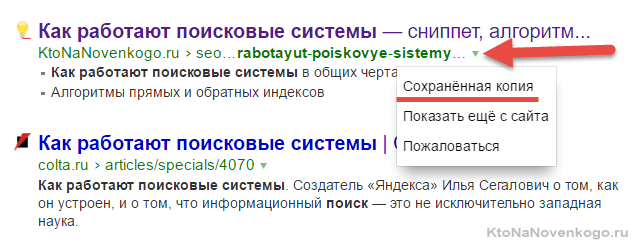
- Кэш (сохраненная копия) — html версия вебстарницы из выдачи, которая хранитяс в базе поисковых систем. Ее можно посмотреть, например, в Яндексе, воспользовавшись ссылкой «Сохранная ккопия», которая появится при клике по спойлеру в виде маленькой стрелочку в конце URL адреса страницы:
Иногда, эта ссылка помогает увидеть страницу на сайте, который сейчас временно недоступен (есть еще и архив интернета, но это уже возиться надо). Кэш нужен поисковикам для того, чтобы иметь возможность формировать сниппеты для своей выдачи, ибо вытащить его из обратного индекса крайне затруднительно, а лазить постоянно на страницу-источник весьма накладно.
Аффилиат, асессор, сквозняк и стоп-слова
- Аффилиат — в выдаче по какому-либо запросу чаще всего представлены разные сайты. Однако, у многих возникает желание оккупировать весь Топ10. Но как это сделать? Правильно, нужно создать десять разных сайтов, которые будут принадлежать вам и все их продвигать в Топ. Это и будет аффилиат. Яндекс и Гугл с этим борются, определяя интернет-магазины и другие коммерческие сайты принадлежащие одному владельцу, и оставляют в индексе только одни из них. Этим, кстати, пользуются и мошенники, выкидывая из индекса таким образом сайты конкурентов.
- Трафик — довольно общий термин (что такое трафик), но в SEO обычно под этим понимают трафик на страницу или на сайт (количество посетителей пришедших за определенный промежуток времени, например, за сутки). Трафик бывает поисковый (из выдач Яндекса, Гугла и других поисковиков), из закладок (имеются в виду закладки в браузере), покупной и т.п.
- Контент — я уже довольно подробно писал про то, что такое контент и насколько он важен для продвижения сайта. Понятие это несколько более широкое, чем просто текст, но при разговоре о Сео имеется в виду именно его текстовая составляющая. Очень часто идет разговор об уникальном контенте, о защите контента от копирования и т.п. вещах, ибо поисковые системы удаляют дубли со своих серверов и они не участвуют в поиске. Существуют специальные биржи контента, где при желании можно заказать или купить уже готовую статью.
- Копипаст — банально скопированный контент. Я не скажу, что, используя копипаст на своем сайте, вы гарантированно попадете под фильтр, но однозначно ни к чему хорошему это не приведет. Тем не менее, это одна из основных составляющих современного интернета.
- Копирайтинг — уникальные тексты написанные «с нуля». Предпочтительный вид контента для СДЛ (термин описан ниже), ибо при должном подходе имеет все шансы занимать высокие позиции в выдаче.
- Рерайт — что-то среднее между двумя описанными выше терминами. Берется какой-то текст и переписывается другими словами с сохранением смысла. В общем-то, это лучше, чем копипаст, но поисковиками «палится на раз», поэтому используйте рерайт только высокого класса, а еще лучше переходите на копирайтинг.
- Асессор — штатный сотрудник Яндекса или Гугла, в задачу которого входит оценка поисковой выдачи по определенным критериям (и для определенных запросов), которая была получена в результате работы алгоритма. Эти оценки служат обратной связью, позволяющей вносить изменения в этот самый алгоритм, чтобы пользователи поисковика оставались им довольны, а выдача была бы релевантной (см. термин чуть ниже) запросу.
- Донор (отдает) — в Сео под этим термином понимают вебстраницу (или сайт), с которой проставлена ссылка на продвигаемую вами страницу. Подразумевается, что донор передает часть своего веса (крови) по этой ссылке (при этом свой собственный вес не теряя, как не парадоксально это звучит). Если я из этой статьи поставлю ссылку на вашу статью, то стану донором, а вы акцептором.
- Акцептор (принимает) — вебстраница, на которую ведет ссылка с донора. По сути вся сеть пронизана донор-акцепторными связями, ибо это изначально было заложено при определении что такое будет интернет Тимом Бернерсом-Ли (технология гипертекста с гиперссылками в качестве связующих элементов).
- Бэклинки (обратные ссылки) — ссылки на ваш сайт с других ресурсов (доноров).
- Анкор — текст ссылки (то, что находится между открывающим и закрывающим Html тегами гиперссылки). Тут не добавить, не убавить. Ссылки могут быть анкорными и безанкорными. Очень важный Сео термин, который учитывается при ранжировании поисковыми системами, и вы можете встретить в сети множество советов о процентном соотношении использовании ключевых слов в анкорах обратных ссылок (чуть ниже этот термин смотрите). Есть такие понятия, как прямые вхождения ключа в анкоре, разбавленные или безанкорные. Читайте подробнее про анкоры тут.
- Статический вес ссылки — поисковые системы в ранжировании учитывают не только динамический вес ссылок (анкоры), но и статический, который определяется изначальным весом страницы донора и числом вебстраниц, на которые она ссылается. Подробности читайте в упомянутой чуть выше статье.
- Жирная ссылка — так называют обратную ссылку (бэклинк) полученную с очень трастового ресурса (с высоким Тиц, например). Еще лучше, если эта ссылка будет проставлена с главной страницы, например, как в случае со студией Лебедева, на которую ведет бэклинк с главной самого Яндекса. К получению жирных ссылок все стремятся, ибо это поднимает траст всего ресурса в целом и может повлечь за собой рост трафика.
- НПС — найдено по ссылке (сейчас в выдаче Яндекса это обозначается чуть по другому: «Ссылки на страницу содержат»). Дело в том, что при ранжировании вебстраниц учитываются также и анкоры (тексты) ссылок, которые ведут на эту страницу. Поэтому при ответе на ваш запрос поисковая система может предлагать документы, в которых вводимый вами запрос не встречается, но зато имеются ведущие на него ссылки, содержащие эти слова.
Соответственно, не имея возможности сформировать сниппет со словами запроса, Яндекс пишет «Ссылки на страницу содержат: текст запроса». Лет семь-восемь назад можно было загнать в Топ любую страницу с любым содержанием, просто проставив на нее кучу анкорных ссылок с нужными ключевыми словами. - Сквозняк — сквозная ссылка, которая имеет место быть на всех страницах сайта. Например, на моем блоге это ссылка с названия блога KtoNaNovenkogo.ru или со счетчика посещений, размещенного на всех страницах. Сеошники при покупке сквозных ссылок стараются каким-то хитрым образом получить в них разные анкоры, чтобы в глазах поисковых систем она не склеилась, т.е. приравнялась к одной.
- Перелинковка — чаще всего под этим подразумевается внутренняя перелинковка, которая может служить как удобству пользования сайтом, так и для перераспределения статического веса между страницами сайта нужным образом. Реализовываться может как вручную (из контекста статей), так и автоматически (хлебные крошки, облако тегов, меню, похожие материалы, карта сайта и т.п.).
- Стоп-слова — в русском языке существуют служебные части речи (союзы, предлоги), которые при анализе текста практически на влияют не его смысл (семантику). При разборе текста, в поисковых системах и создании обратного индекса, зачастую они просто отбрасываются для упрощения и экономии ресурса. Иногда их еще называют минус-словами.
- Пассажи — при индексации сайтов поисковики из загруженного Html кода вебстраницы извлекают текст видимый посетителям, удаляют из него все стоп-слова (союзы, предлоги) и знаки препинания. Полученный в результате набор слов бьют на так называемые пассажи. По сути это предложения, но с некоторыми допущениями. Пассажи, как и предложения, объединяются смысловой законченностью, но оперировать именно предложениями при машинном анализе русского текста практически не возможно (в силу его «великости и могучести»). Т.е. анализ ведется не по физическим (изначально имеющимся в тексте) предложениям, а по вновь созданным (машинным), которые и назвали пассажами.
СДЛ, ГС, конверсия и алиас
- СДЛ (сайт для людей) — такие ресурсы создаются и развиваются в непосредственном контакте со своими посетителями. В общем, нормальные сайты, какими они и должны быть. Существуют СДЛ, как правило, балансируя между потребностями посетителей и желанием владельцев побольше заработать (на рекламе, продаже ссылок и т.п. вещах, описанных в статье про заработок на СДЛ).
- ГС (го-но сайты) — создаются исключительно для обмана поисковых машин и заработка на привлеченном поисковом трафике (либо на продаже ссылок со страниц, попавших в индекс поисковиков). Многие ГС можно с первого взгляда отличить от СДЛ, но поисковики не могут видеть, а потому таких ресурсов до сих пор полным-полно в выдаче. Сейчас Яндекс и Google активно с ними борются, но ГС живее всех живых. У Яндекса имеются фильтры АГС (анти ГС) с номерами 17, 30 и 40, которые призваны выкашивать этих паразитов.
- Дорвей (дор) — автоматически создаваемый ГС. Технологии их изготовления мне не известны (используются доргены, по-моему). По некоторым запросам и в Яндексе, и в Гугле можно наблюдать засилье доров, что не есть гуд. Живут они в индексе поисковиков не долго, но в силу автоматизации их создания на смену умершего приходит парочка новых.
- MFA — сайт, созданный под заработок на Адсенсе (Made for AdSense), хотя и под Рекламную сеть Яндекса, наверное, тоже делают. По сути, это разновидность ГС. Оптимизируются MFA под поисковые системы, в то же время не имея на своих страницах (многочисленных) чего-то, что может заинтересовать пользователя. Попадая туда, посетитель зачастую кроме объявлений Адсенса для себя ничего интересного не видит, поэтому кликает по ним с завидной регулярностью (на радость владельца).
- Морда — главная страница сайта (хомяк). Это страница сайта, которая открывается при наборе в адресной строке браузера основного хоста (ktonanovenkogo.ru, например). В Сео ссылки с морды стоят существенно дороже, чем ссылки с внутренних страниц.
- Конверсия — характеризует соотношение общего количества посетителей (трафика) пришедших на сайт к числу тех из них, кто совершил целевое действие (купил товар, заполнил форму, подал заявку на услугу, сделал звонок и т.п.). Для расчета конверсии число правильных посетителей делится на их общее число число и умножается на сто процентов.
- Сопли — Supplemental Results или, другими словами, дополнительный индекс поисковой системы Google. Сей поисковик настолько велик, что может позволить себе индексировать все подряд, однако не все попадает в основной индекс, по которому, собственно, и ведется поиск. Можете определить процент страниц своего сайта, находящихся в соплях, с помощью сервиса, описанного по приведенной выше ссылке или все в том же РДС баре.
- Быстробот — поисковый робот, который призван наполнять выдачу наисвежайшими материалами. Он посещает сайты, где часто появляется новая информации (например, блоги с RSS лентой или новостные ресурсы). Найденные страницы он ранжирует, опираясь лишь на некоторые внутренние факторы, и они мгновенно появляются в выдаче с указанием даты их создания. У меня не раз бывали всплески посещаемости, когда новая статья попадала в Топ Яндекса стараниями быстробота. Но на следующий день позиции резко ухудшались после прихода основного робота индексатора.
- Пузомерки — ИКС Яндекса, рейтинг домена в Ахрефс и другие показатели, которые могут так или иначе охарактеризовать успешность развития сайта.
- Чайник — это профан или начинающий пользователь. Подавляющая часть пользователей интернета (около 90%) являются чайниками и именно они определяют многие аспекты функционирования сети. По сути, весь интернет настроен на них, а значит это нужно учитывать при создании своего сайта.
- Яндексоид — сотрудник Яндекса.
- Платон Щукин — собирательный образ работника техподдержки Яндекса.
- Адурилка — форма для добавления новых страниц в поисковые системы. По ссылке вы найдет статью со ссылками на наиболее известные аддурилки.
- Алиас — псевдоним или же дополнительное доменное имя, которое приводит на один и то же физический сайт. Про самый распространенный алиас я писал в статье про домены с WWW без оного.
- Зеркало — копия основного сайта на другом домене. Такая ситуация может возникнуть, например, при переносе сайта на новое доменное имя. В индексе поисковика новый сайт (основной) появится только после того, когда робот зеркальщик выполнить свою работу (иногда приходится ждать месяцами его прихода). Так же зеркала могут использоваться для распределения нагрузки на сервера или для перераспределения трафика между регионами.
- Серч (searchengines.guru) — один из самых популярных в рунете форумов посвященных SEO продвижению. Там обсуждают нововведения поисковиков, решаются разные проблемы, ну, и просто иногда очень интересно бывает почитать мнения по тому или иному вопросу.
SEO, обратные ссылки, ПР, Тиц, ИКС и дорвеи
- SEO (Search Engine Optimization, Поисковая оптимизация) — ряд мероприятий, осуществляемых seo специалистами или seo любителями с вебсайтом, направленных на поднятие позиций по определенным запросам пользователей в выдаче (списке результатов поиска) Яндекса и Гугла. SEO оптимизация включает в себя работы по изменению текстового наполнения, кода, структуры, ссылочных связей и т.п.
- Аддурилка — форма для добавления урла — add url.
- Белый каталог — каталог, который не требует размещения на вашем ресурсе обратной ссылки на этот каталог, как плату за то, что вы добавили в него свой сайт.
- БЭК-линк (back link) — обратная ссылка, ссылка на ваш ресурс, размещенная на другом вебсайте.
- Яша — поисковая машина номер 1 в рунете (читайте про настройка главной Яндекса).
- Рама — Рамблер.
- Болт — Webalta.ru (поисковая система).
- Морда — ссылка на главной странице сайта. Вес ссылки с морды в разы выше, чем на второстепенных страницах.
- Внутрянка или Внутряк — внутренняя страница вебсайта. С них тоже можно продавать ссылки в такой системе как sape и xap. Ссылки с внутренних страниц намного меньше ценятся при продвижении по сравнению с главными, но большое количество внутряков позволит увеличить тиц
- Линкопомойка — много ссылок ведущих на ресурсы разных тематик, размещенные на странице только для продвижения под Yandex и Google, а не для пользователя. За такие страницы Яндекс, как правило, применяет различные санкции вплоть до бана. Не рекомендуется на своем проекте разводить линкопомойки, для продвижения необходимо делать как минимум строго тематический каталог, удобный для пользования.
- SE (Search Engines) — поисковые системы. Их довольно много, но для рунета, на данный момент, самыми важными являются Yandex и Google. Именно они дают вебмастерам рунета основной приток посетителей. Причем, не стоит недооценивать роль Google, на многих ресурсах трафик с Яндекса и Google примерно одинаковый.
- SERP (Search Engine Result Page) — страница выдачи результатов поиска (читайте про то, как нужно правильно гуглить).
- ПР или PR (Google PageRank) — это алгоритм расчёта авторитетности страницы (не всего сайта) в Google. Используются значения от 0 до 10. Проверить можно с помощью различных сервисов или же с помощью Google Toolbar. Более подробную информацию о PageRank вы сможете получить в этой статье — Google PageRank (PR) — что это такое и от чего зависит PR, в чем измеряется и как посмотреть PageRank, как PR влияет на положение в выдаче Google, информеры PageRank
- ВИЦ — взвешенный Индекс Цитирования (ИЦ) Yandex, учитывающий число страниц ссылающихся на документ и значимость этих вебстраниц. Рассчитывается для каждой страницы в базе этого поисковика. Обновляется два раза в неделю. Является одним из факторов, влияющих на положение страницы в результатах поиска при продвижении. В настоящее время значения ВИЦ не транслируются Яндексом и мы никак не может его оценить.
- ТИЦ — тематический индекс цитирования — это алгоритм расчёта авторитетности ресурса с учетом тематических ссылок на него. Сегодня уже устарел (его заменил ИКС, о котором речь пойдет ниже). Используется в системе Yandex. Проверить ТиЦ можно по адресу: http://search.yaca.yandex.ru/yca/cy/ch/ktonanovenkogo.ru — где ktonanovenkogo.ru нужно будет заменить на свое доменное имя (что это такое?). Рассчитывается для сайта в целом и показывает авторитетность ресурса относительно других, близких по тематике ресурсов (а не всего Интернета в целом). ТИЦ используется для ранжирования в каталоге Яндекса и не влияет на прямую на результаты поиска в Яндексе. Узнать больше о ТИЦ вы сможете из этой статьи — Тематический индекс цитирования Яндекса
- ИКС Яндекса (индекс качества сайта) это показатель, то или иное значение которого присваивается любому интернет-ресурсу. Поисковая система ввела этот параметр на смену тематическому индексу цитирования, который определял авторитетность сайта на основе того, сколько ссылок на него ведёт, причём разные ссылки имели разный вес.
- Сниппет — небольшой отрывок текста из найденной поисковой машиной вебстраницы, использующийся в качестве описания ссылки в результатах поиска (читайте про то, как правильно искать в Яндексе). Как правило, они содержат контекст, в котором встретилось ключевое слово в тексте на странице. В качестве сниппетов также может выводиться текст из метатэга Description. Почитать подробнее о назначении других мета-тегов вы можете в статье про оптимизацию блога на Вордрессе
- Хомяк — ваша домашняя страничка.
- Платник — хостинг на платном сервере. Например, Инфобокс или ProGoldHost (Проголдхост)
- Дорвей — это специально созданная html-страничка под определенный запрос пользователя, не несущая полезной информации, а предназначенная исключительно для продвижения. Обычно дорвеи содержат специально написанный нечитаемый текст, состоящий из популярных запросов пользователей. Как правило, посетители не успевают увидеть сам дорвей: их автоматически переадресовывают («редиректят») на раскручиваемый сайт, в то время как поисковому роботу туда путь закрыт. Если будет доказана причастность ресурса к дорвею, он будет исключен из базы данных поисковой системы в силу запрещенного метода продвижения. Дорвей является запрещенным методом продвижения.
- HTML — язык гипертекстовой разметки, который указывает браузеру с помощью тегов и их атрибутов, как именно должна выглядеть загружаемая вебстраница. На этом блоге есть рубрика под названием HTML для начинающих, в которой вы сможете найти ответы на основные вопросы по HTML.
- Урл или URL (Universal Resource Locator) — символьный адрес ресурса в Интернете. Представляет цифровой IP-адрес ресурса 89.208.146.82 в виде строки, например: https://ktonanovenkogo.ru или https://ktonanovenkogo.ru/vokrug-da-okolo/hosting-i-vse-chto-s-nim-svyzano.html
Индексация, боты трафик и хиты
- Весовой коэффициент — увеличивать релевантность (степень соответствия запроса и найденного, то есть уместность результата) документа может не только количество содержащихся в нем ключевых слов, но и их расположение в документе. Больший «вес» имеют слова в заголовке страницы (заголовок — это то, что находится между парным тегом H или внутри метатега Title), слова выделенные тегами, слова находящиеся ближе к началу документа.
- Индекс — индекс поисковой системы представляет собой гигантский информационный массив, где хранятся преобразованные особым образом текстовые составляющие всех посещенных и проиндексированных роботом НТМL-страниц и текстовых файлов. Робот не только пополняет массив новыми поступлениями, но и регулярно обновляет уже имеющиеся в индексах документы.
- Индексация страницы поисковой системой — внесение документа в базу данных Яндекса или Гугла. Как правило, происходит через некоторое время после подачи заявки на регистрацию.
- Концептуальный поиск — поиск документов, имеющих прямое отношение к указанному слову, а не просто содержащих его.
- Морфологический поиск — позволяет искать информацию не только по строго заданному слову, но и по всем его морфологическим формам (разных падежах, родах, числах и т.п.).
- Позиционирование в поисковых системах — мероприятия, предназначенные для достижения более высокого места в результатах поиска.
- Релевантность (уместность) документа — мера того, насколько полно тот или иной документ отвечает критериям, указанным в запросе пользователя. Разумеется, далеко не всегда документ, признанный Яндексом или Google наиболее релевантным, будет таким по мнению самого пользователя.
- Робот поисковой системы (бот) — это программа, являющаяся составной частью поисковика и предназначенная для обхода Интернета с целью занесения найденных документов в базу. Порядок обхода вебстраниц, частота визитов регулируется алгоритмами поисковой машины. С помощью файла robots.txt можно запретить индексацию всего сайта или его части, содержащего инструкции для ботов.
- Сабмитинг — подача заявки на регистрацию в поисковую систему.
- Стоп-слова — это Служебные единицы языка не несущие самостоятельной смысловой нагрузки. К ним относятся предлоги, союзы, междометия и т.д. Как правило, удаляются поисковой машиной из образа индексируемой страницы с целью снижения нагрузки на сервер и уменьшения размеров индекса. Оптимизация подразумевает уменьшение количества стоп слов по сравнению с полезным текстом. При обработке запроса пользователя стоп-слова также удаляются из запроса. У каждой машины обычно имеется свой собственный набор стоп-слов. К стоп-словам могут относиться и просто слишком часто встречающиеся в Интернете служебные последовательности знаков, например, http, www,.com.
- Трафик — объем данных, переданных и принятых web-сервером. Зависит от количества пользователей. Трафик появляется за счет продвижения по ключевым запросам.
- Хит — обращения пользователя к вебстранице, исключая перезагрузки. Повторный хит засчитывается при повторном обращении пользователя к документу по истечении 60 секунд по умолчанию.
- Хост — уникальный IP-адрес посетителя. Один посетитель может иметь несколько IP-адресов в случае, когда он выходит в интернет через Dial-Up соединение (модем) с провайдером и, наоборот, много посетителей на одном хосте (IP-адресе) — один офис подключен через выделенную линию, а все его сотрудники выходят в интернет через прокси-сервер.
- Чувствительность к регистру — чувствительность поисковой системы к заглавным и строчным буквам в запросе.
Частотность запросов, апдейты, тошнота, бан и релевантность
- НЧ-запрос (низкочастотник) — низкочастотный запрос. Они вводятся по нескольку сотен раз в месяц. Продвинуться по НЧ можно, вообще не используя внешнюю оптимизацию. Для этого достаточно будет грамотно провести оптимизацию внутреннюю (перелинковать статьи).
- Ссылка сквозная (сквозняк) — вебссылка со всех страниц сайта (главная + все внутренние). С помощью сквозняка хорошо поднимать PR или ТИЦ сайта, но при продвижении по запросам (для попадания по ним в топ) сквозняк не имеет особого преимущества по сравнению с обычной вебссылкой с главной страницы.
- Яка — каталог Яндекса.
- ДМОЗ (DMOZ) — Open Directory Project — популярный ненашенский каталог (dmoz.org ). К сожалению, уже закрылся. Имеет большое влияние на pr при продвижении (есть мнение, что на рунет это не распространяется). Добавление в ДМОЗ (DMOZ) производится на бесплатной основе. Русскоязычный ресурс можно добавить по адресу — dmoz.org/World/Russian.
- Клоакинг (Cloaking) — метод оптимизации, при котором поисковому роботу предоставляется один контент, а посетителям ресурса — другой. При обнаружении карается баном (ресурс исключается из базы поисковика).
- Пессимизация сайта — занижение позиций ресурса при его ранжировании в результатах поиска. Обычно возникает в результате использования методов «чёрной оптимизации». Яндекс и Гугл делают в целях повышения релевантности своей выдачи.
- Релевантность поиска — соответствие ответа вопросу. Важны две составляющие – полнота (ничего не потеряно) и точность (не найдено ничего лишнего).
- Бан — запрещение ресурса к индексации одним или несколькими поисковиками. Например, если Яндекс вас забанил, то ваш сайт на стартовой странице яндекса не найдется ни по одному из запросов.
- Тошнота страницы — степень неествественности текста. Тошнота увеличивается при явном переборе ключевых слов, большом кол-ве тегов strong и др. Она не обязательно ведет к пессимизации и уж тем более к бану, но может подпортить мнение поисковиков о вашем ресурсе.
- Поисковый спам — это любые приёмы или тексты, рассчитанные только на роботов поисковиков и не предназначенные для “живого” посетителя. Например, размещение невидимых для пользователя гиперссылок (как вариант — в виде прозрачной картинки размером 1×1) и создание, так называемых, Link Farm (линк-ферм, или ссылкопомоек) — вебстраниц с огромным количеством гиперссылок на разные ресурсы.
- АП (апдейт) — это обновление индекса Яндекса (у Google все происходит практически в реальном времени), приводящее к изменению позиций в выдаче. Апдейты проходят двумя способами — мгновенная очистка кеша и постепенная замена. В первом случае, во время начала апдейта мы видим сильные изменения в выдаче сразу, т.к. кеш очищен и выдача формируется в реальном времени, а во втором — выдача обновляется постепенно.
- Поисковая выдача SERP (search engine result page) — набор ссылок на сайты и их описания, выдаваемый в результате поиска. Ввели запрос и в результате получили список ресурсов, соответствующих по мнению поисковика вашему запросу. Этот список и будет поисковой выдачей.
- Семантическое ядро — это полный список запросов, по которым проект будет продвигаться. Разрабатывать структуру сайта нужно только после составления семантического ядра. Это даст Вам представление о разделах Вашего не созданного вебсайта и о материалах, которые на нем нужно будет размещать.
Ссылочное ранжирование (Link Popularity) — это влияние текстовой составляющей гиперссылки, проставленной с чужого сайта, на релевантность вебстраницы вашего ресурса по поисковым запросам, содержащимся в текстовой составляющей ссылки (ее анкоре). Это поиск по лексике анкоров, который является, пожалуй, самым интересным из критериев, оказывающих влияние на ранжирование документов в результатах поиска.
Ссылочное ранжирование — это иерархия по авторитету в выдаче Яндекса или Google. Если на ресурс ссылаются много других ресурсов, значит он авторитетный. Управлять всеми ссылающимися вебсайтами вебмастер не может, поэтому ссылочный критерий более объективный, чем текстовый. Дополняя друг друга, оба критерия позволяют поисковикам обеспечивать лучшие результаты поиска.
- Ссылочная популярность — это показатель того, сколько гиперссылок с внешних ресурсов ведет на ваш сайт, документ или домен, на котором он находится. Ссылочная популярность будет меняться в зависимости от поисковой системы, поскольку каждый поисковик имеет свою собственную базу данных и количество ссылок, хранящихся в базах различных систем различно. Гугловский PR и яндексовский ВИЦ являются показателями ссылочной популярности.
- Free-for-all (FFA) страницы — это место, где каждый может добавить свою гиперссылку. Т.к процесс автоматизирован, то нет никакой возможности его контролировать. Тысячи и тысячи нетематических ссылок находятся на страницах FFA. Единственная цель — это увеличение link popularity.
Анкоры, движки, виды оптимизации парсеры и песочница
- Анкор (anchor) — текст ссылки.
- «Черная» оптимизация — продвижение нечестными методами, поисковый спам. Для достижения результата используется размещение невидимого текста, использование дорвеев с редиректом, клоакинг, ссылочный спам (размещение невидимых для пользователя гиперссылок.)
- «Серая» оптимизация — оптимизация «вслепую», без учета особенностей проекта. Осуществляется, например, созданием дорвеев без редиректа, хаотичный обмен ссылками. Эффект от такой оптимизации минимальный.
- «Белая» оптимизация — работа с контентом и структурой сайта с целью сделать его наиболее удобным для посетителей и доступным для индексации поисковиками. Проводится путем оптимизации навигации на сайте, чисткой кода, добавлением контента, размещением ссылок на тематических ресурсах. Вы так же можете ознакомиться со статьей — Внутренняя оптимизация сайта
- Двиг, движок — программный код, на основе которого построен сайт. Чаще всего имеются в виду CMS (Content Management System) – Системы управления контентом. Оптимизация выдвигает к «движкам» ряд требований, которыми обычно пренебрегают многие разработчики CMS.
- Жирная ссылка — гиперссылка с вебстраницы с большим авторитетом (ТИЦ, PR). Важность этой ссылающейся страницы, в свою очередь, тем выше, чем больше количество и чем авторитетнее ссылки ведущую на эту вебстраницу.
- Затачивать — применительно к SEO, это оптимизация под поисковик, либо текста под ключевое слово.
- Киберсквоттеры — это те, кто регистрирует домены для продажи. Маржа киберсквоттера может превышать несколько сотен процентов.
- Мордовские ссылки — с главных вебстраниц (морд) сайтов.
- Непот фильтр — отказ поисковика учитывать гиперссылки с сайтов-спамеров.
- Непот лист — список ресурсов, которые попали под ограничения накладываемые непот фильтром.
- Парсер — программа, которая обеспечивает автоматическую обработку (разборку) вебстраниц сайтов с целью получения нужных данных. Парсеров в природе существует огромное множество, в зависимости от задачи, например, парсеры для сбора ключевых слов из сервиса wordstat.yandex.ru.
- Парсить — процесс проверки (разборки) данных, основной целью которого является обнаружение необходимых элементов файла (ссылка, логические части текста и т.п.).
- Парсить можно выдачу на предмет позиций ресурса, можно страницы на предмет нахождения там нужной ссылки и т.п.
- Песочница — это одно из самых серьезных препятствий, которое необходимо преодолеть новому проекту, прежде чем попасть в результаты поиска русского Google. Песочница Google не позволяет новым ресурсам искусственным путем улучшать свои позиции. Далеко не каждая поисковая система имеет подобную фильтрацию. Сайты, оказавшиеся в песочнице, могут пробыть там от двух недель до года. В течение этого периода новые проекты успеют занять высокие позиции в других поисковиках, но не в Google.
SEO умерло? Нет, просто вы не умеете его готовить
Сегодня хочу выступить в роли адвоката Сео методов продвижения и попытаться объяснить основные причины, по которым возникают проблемы у тех, кто пытался или пытается понравится поисковым системам с целью получить от них в ответ поток целевых посетителей на свой сайт. На самом деле, набор ошибок получается довольно стандартным (большинство их совершают), но именно очевидные вещи зачастую ускользают от внимания.

Последнее время SEO серьезно эволюционировало и закупка ссылок теперь стоит далеко не на первом месте. Да что там ссылки, даже внутренняя оптимизация сайта уже не имеет решающего значения в успехе продвижения. Особенно это касается коммерческих сайтов, где поисковики используют довольно-таки специфические факторы ранжирования, которые могут показаться неожиданными. Какие именно? Думаю, что при внимательном прочтении данной статьи вы сможете получить ответ на этот и ряд других не менее важных вопросов.
Сейчас по-настоящему разобраться в SEO довольно сложно, ибо почти вся информация, имеющаяся в паблике (статьи, конференции, форумы и т.п.) огромна по своим размерам, но крайне не содержательна. Почти все, что вам может встретиться — это сплошная вода, общие фразы и принципы, которые уже давно не работают. Те, кто в продвижении сайтов действительно разбираются, активно зарабатывают на этом и мало делятся информацией (их время стоит дорого).
Тоже самое можно сказать и про подавляющее большинство платных курсов (вне зависимости от их стоимости) — они по большей части не представляют никакого практического интереса. В SEO кампаниях также ощущается огромный дефицит специалистов, и большинство из работающих там людей умеют лишь закупать ссылки (или предлагать удаленную работу фрилансерам).

Из-за этого авторитет Сео-продвижения сильно подрывается, и уже кажется, что все это сплошное шарлатанство (оптимизаторы не отвечают за результат, ибо его нельзя гарантировать априори, да и дорого все это — хотя контекст бывает в разы дороже). На самом деле тут и кроется основная ошибка, которая в итоге очень сильно подрывает авторитет SEO. Пытаясь продать свои услуги, Сео-конторы и фрилансеры обещают все что угодно (зачастую совершенно нереальные вещи), лишь бы клиент «поплыл».
На самом деле, даже если вы не верите в возможности поискового продвижения, то это не значит, что эту тему не следует изучать. Это необходимо хотя бы для того, чтобы исправить элементарные ошибки в работе сайта (например, те, о которых я писал в статьях про зеркала и дубли страниц на сайте, а также про Http ответы сервера и редиректы).
Но кроме этого существует еще масса «граблей», на которые наступают очень многие владельцы интернет-проектов. Это мешает естественному продвижению вашего сайта в поисковых системах, а также не позволяет получить результаты при намеренном продвижении, ибо сводит все усилия на нет. Ошибка может заключаться даже в самом подходе к продвижению, ибо он должен состоять из последовательного выполнения некоторых базовых действий, которые не желательно пропускать или менять местами.
Все это особенно важно при работе с коммерческим сайтом. Во многих тематиках наблюдается поистине феноменальная конкуренция и возникают ситуации, когда, например, использовать контекстную рекламу не всегда получает рентабельно. Грамотный подход (маркетинговый) к продвижению сайта может существенно уменьшить номинальные расходы на привлечение клиентов. Причем это не будет связано с какими-то особыми рисками. Думаю, что огульно отвергать возможности SEO в современных реалиях является контрпродуктивным действом, способным поставить под удар само существование бизнеса.
Естественно, что в каждой нише (тематике) есть свои особенности, да и вообще все сайты индивидуальны и подходить к ним с одной линейкой не стоит. Но в то же время есть типовые ошибки, которые встречаются у большинства интернет-проектов, и вот именно про них мы и будем говорить в этой статье. Даже само их осознание может служить первым шагом в нужном направлении.
Пять основных проблем при продвижение коммерческого сайта
В большинстве случаев именно неправильный подход и непонимание того, что нужно делать, а чего делать нельзя категорически, является причиной неудач в SEO продвижении сайтов. Поэтому я попробую пока тезисно, а в следующих статьях — более развернуто описать те вещи, которые могут стать камнем преткновения в успехе вашего бизнеса.
В статье про способы продвижения коммерческого сайта я акцентировал ваше внимание на том моменте, что очень важно очертить свою целевую аудиторию. А как это сделать? Правильно, собрать наиболее полное семантическое ядро (оно понадобится не только для Сео, но при использовании Яндекс Директа или Гугл Адвордса в качестве площадок по привлечению целевого трафика на ваш сайт). Собрать его можно, проанализировав спрос на предлагаемые вами услуги или товары.
Так вот, основной и наиболее частой ошибкой владельцев сайтов (или маркетологов, которые занимаются привлечением на него трафика) является пренебрежение полноценным анализом спроса (очерчиванием своей целевой аудитории) и, как следствие, сбор слишком маленького семантического ядра (в пределах ста поисковых запросов). Т.е. идет сбор ВЧ и СЧ запросов, а «длинный хвост» (трех, четырех, пяти и даже шести словники) упускается из вида в силу сложности или непонимания способов его сбора.
На самом деле, следуя такой тактике вы упускаете девяносто процентов потенциальных посетителей и, возможно, клиентов вашего сайта. Мало того, эти самые НЧ и сверх-НЧ запросы лучше всего конвертируются, ибо по ним заходят уже практически готовые к покупке пользователи. Хорошее семантическое ядро должно состоять не из ста, а из нескольких тысяч или даже десятков тысяч запросов. В противном случае вы будете нести многократные потери в виде недополученной прибыли. И, естественно, не ощутите должного эффекта от SEO продвижения (равно как от рекламы в Директе или Адвордсе).При ранжировании коммерческих сайтов поисковые системы используют такую метрику, как полнота представленной информации и качество ее структурирования на сайте. Чтобы попадать в Топ по тематическим запросам, нужно не просто иметь страницу, отвечающую на данный вопрос, но и иметь полный набор страниц, отвечающих на большинство вопросов в данной нише. Полноту и структуру сайта оценивает не только алгоритм поисковой системы, но и асессоры (специально обученные сотрудники поисковика).
Соответственно, вы не добьетесь нужной полноты, имея маленькое семантическое ядро, поэтому его расширение и создание на его основе понятной и хорошо читаемой структуры является чуть ли не первостепенной задачей. Убогая структура не позволит пришедшему пользователю быстро сориентироваться и найти нужную ему информацию, что ухудшит карму вашего сайта в глазах поисковиков. Хотите быть в Топе — должны соответствовать.
Иногда о полноте и говорить как-то не с руки, если на сайте имеют место быть страницы вообще без контента (в разработке), нет цен в интернет-магазине (каталоге товаров), в блоке новостей последняя датирована концом прошлого века, а на странице контактов указан лишь телефон. А ведь один из факторов ранжирования коммерческого сайта асессорами — наличие схемы проезда (а также внятного описания кампании, наличие фото сотрудников, сертификатов, лицензий и т.п.).
Ну, а без указания цен очень сложно будет попасть в Топ или удержаться там (даже при сложности определения расценок следует указывать их возможный диапазон), ибо алгоритмы поисковых систем при ранжировании по коммерческим запросам все это учитывают, да и поведенческие характеристики в интернет-магазине (или каталоге) без указания цен будут сильно хуже (по понятным причинам).- При продвижении по сложным (высококонкурентным) запросам очень часто оптимизаторы пренебрегают изучением сайтов конкурентов из Топ 10. Не оценивают их с точки зрения сильных и слабых сторон, не изучают их ценовую политику и т.п. У конкурентов ведь еще можно почерпнуть массу идей все по той же структуре или по дизайнерским решениям, не говоря уже про анализ их методов продвижения и маркетинговых ходов. Все это, на самом деле, нужно делать, чтобы получить шанс потеснить их в Топе.
- Не устаю из раза в раз повторять, что времена, когда абсолютно любой сайт можно было затащить в Топ одними лишь ссылками (даже проставленными на него с тематических и высокотрастовых сайтов) уже давно прошли. Парадокс заключается в том, что многие до сих пор не понимают аксиому — ссылки сейчас работают только в совокупности с идеальными внутренними факторами. Без работы внутри сайта вы теряете девяносто процентов своей потенциальной аудитории при том же самом раскладе по другим факторам ранжирования.
С другой стороны, наверное, многим не понятно, а почему, зная эту аксиому, многие оптимизаторы продолжают закрывать глаза на внутреннюю оптимизацию сайта и целиком окунаются в закупку ссылок? Ну, просто работа над внутренними факторами очень сложна и довольно-таки затратна (в плане времени и денег). Многие SEO-шники пытаются идти по пути наименьшего сопротивления, который на данный момент крайне неэффективен и приводит к дискредитации Сео продвижения в глазах владельцев сайтов. Путь в никуда.
Под внутренними факторами, которые требуется оптимизировать, следует понимать: Html код, непосредственно тексты, заголовки страниц (title должен быть обязательно и они должны быть разными для всех страниц сайта) и внутренние заголовки статей (на каждую страницу должен быть один тег H1), мета-теги (description и keywords), внутреннюю перелинковку, файл роботс.тхт, коды ответа сервера, редиректы и прочие вещи. Про Seo оптимизацию текстов на сайте мы с вами недавно говорили, да и про все остальное тоже, но возможно, что еще не раз поговорим более подробно.
Как раз в статье про оптимизацию текстов (см. ссылку в предыдущем абзаце) одним из главных факторов, влияющих на успех, являлось написание текстов не для поисковых систем, а для людей. Не надо делать упор на количество ключевых слов в тексте, а также не следует один текст оптимизировать сразу под десяток-другой запросов (особенно при его небольшом размере). Такие «перлы» никто читать не будет, да и асессоры поисковых систем (живые люди, которые постоянно вручную оценивают сайты по ряду параметров и тем самым обучают алгоритм поисковиков) однозначно это отметят не в вашу пользу.
Еще раз вкратце повторю то, о чем говорил в приведенной выше статье про оптимизацию текстов на сайте. Следует избегать выделения в тексте жирным всех ключевых слов (такой моветон нет, нет, да и встретится на просторах сети), не допускать переспама ключами в тексте (1-3 ключевых слова на 2-3 тысячи знаков можно считать допустимой нормой) и в заголовках (не повторять ключи), обязательно проверять грамматику, правильно форматировать тексты (использовать списки, заголовки, подзаголовки, абзацы, выделения по смыслу, иначе будут низкие поведенческие факторы и сайт не сможет занять высоких мест) и не писать бестолковые тексты (только факты, лаконично и без воды).
Контент для SEO — это прежде всего текст. Бывают случаи, когда в качестве контента предлагаются сканы (допустим, бумажной версии каталога продукции). Поисковики распознавать и учитывать в ранжировании тест с картинок пока еще не начали, а значит такие страницы будут восприняты ими, как не содержащие контента и, априори, не имеющие шансов на место под солнцем (в Топе и вообще в выдаче). Нужны именно тексты, грамотно написанные и отформатированные.



Еще несколько распространенных проблем с сайтом
- Не только тексты нужно писать для людей, но и весь сайт должен отвечать этому требованию. Если провести глобальную оценку всех имеющихся в рунете ресурсов, то лишь малую их часть (не более пяти процентов) можно будет отнести к категории «сайты для людей» (качественно сделанные ресурсы, отвечающие минимальным требованиям удобства и юзабилити). Все остальное не отвечает этому высокому требованию, например, из-за отвратного внешнего вида или из-за очень плохого юзабилити.
Сайт «сделанный на коленке» не получит высокую оценку от асессоров (они обращают на дизайн внимание тоже), а при этом качество дизайна является сейчас для коммерческих сайтов одним из факторов ранжирования. Усилия по оптимизации и продвижению проекта с плохим или сильно устаревшим дизайном будут потрачены напрасно. Сами можете убедиться в том, что в Топе по высококонкурентым коммерческим запросам находятся исключительно сайты с очень качественным дизайном (бывают редкие исключения, но они лишь подтверждают правило).
- Теперь про ссылки — куда же без них. Обратите внимание, что про них мы говорим только сейчас, поставив выше работу с контентом и всем сайтом целиком. Это не спроста, ибо ссылки по-прежнему участвуют в ранжирования (по крайней меру у Гугла, хотя и Яндекс их учитывает, но возможно уже чуть по другому), но они не всесильны. Во-первых, ссылки работают только в совокупности с хорошим сайтом (критерии смотрите чуть выше — должны быть дизайн, структура и контент на высоком уровне).
Во-вторых, по статистике реально учитываются поисковиками и работают лишь несколько процентов от всей закупленной ссылочной массы. Большинство SEO-оптимизаторов просто сливают ссылочный бюджет (не малый, как правило) в унитаз. Нужно понимать, что поисковики очень с высокой долей вероятность знают, что ссылка платная, но могут ее учитывать, если она по делу. Поэтому главным критерием будет жесткая фильтрация доноров, с которых будут вести ссылки (методов много, но дело это хлопотное и времязатратное), чтобы исключить все потенциально неэффективные и не переплачивать лишнего.
Мало просто привлекать посетителей (пусть даже и из вашей целевой аудитории) — нужно еще постоянно работать над повышением эффективности сайта (воронкой конверсий). Зачастую конверсия владельцами не измеряется, а эффективность продвижения оценивается по принципу «есть звонки или их нет вовсе». И это при том, что уже давно существуют такие услуги, как отслеживание звонков от посетителей сайта (тот же «Целевой звонок» в Метрике или описанный мною не так давно CoMagic). Повесив разные номера на разные каналы привлечения посетителей (СЕО, Директ, Адвордс, социальные сети и т.п.) или даже на разные поисковые запросы, по которым приходят посетители, вы поймете, что и где нужно менять.
Не измеряя конверсию, вы не сможете ее повышать (нужна обратная связь для оценки эффективности предпринятых мер), а это ведь дополнительные клиенты и продажи. Владелец бизнеса должен знать стоимость привлечения одного клиента по разным каналам. А как улучшать конверсию? Только за счет улучшения самого сайта и оптимизации пути по нему вашего потенциального клиента (например, делать АБ-тесты разных целевых страниц с целью выявления лучшего варианта).
Как ни странно это звучит, но конверсия является фактором ранжирования для коммерческих сайтов, ибо формирует поведенческие факторы ресурса. Улучшая ее, вы повышаете позиции своего интернет-проекта в выдаче поисковых систем (читайте про SEO терминологию по приведенной ссылке). В конкурентных тематиках все, кто сидит в Топе, уделяют конверсии сверх пристальное внимание каждый день.- Кроме показателей конверсии следует анализировать и целый ряд других параметров, например, показатель отказов и другие характеристики поведения пользователя на сайте. Для этих целей установки счетчиков, типа ХотЛог или Лайвинтернет, не достаточно, ибо они не позволяют получить всю полноту картины. Собственно, даже относительно продвинутые системы сбора статистики типа Яндекс Метрики и Гугл Аналитикса без соответствующих настроек тоже малоэффективны (не настроены цели, распознавание роботов, Вебвизор, модуль электронной коммерции в Аналитиксе и другие необходимые инструменты).
Для успешного существования и продвижения коммерческого сайта необходимо постоянно анализировать статистику и делать из этого соответствующие выводы. Изучая показатели отказа (высокие значения говорят о несоответствии содержания данной страницы чаяниям пользователя, которого вы на нее привели)
и поведения пользователей на сайте (Вебвизор позволяет бесплатно посмотреть видео с действиями пользователя на сайте, а, например, тепловые карты в Метрике — визуально оценить кликабельность на страницах) можно понять, как именно все это улучшить и что нужно изменить на сайте для удержания внимания пользователей.
Например, если у вас на сайте есть кликабельные ссылки, по которым все постоянно переходят, и тексты этих ссылок содержат ключевые запросы, то ваш сайт (а точнее те страницы, на которые ведут эти линки) может выйти в Топ по этим запросам даже без покупки внешних ссылок. Правда это касается в основном НЧ и СЧ запросов, но и этого вполне достаточно. Однако, закрывая на это глаза (не анализируя статистику) вы лишаете себя козыря в борьбе за Топ по нужным вам запросам и, как правило, проигрываете битву.
Вебвизор же позволяет посмотреть действия пользователей и понять, какие из задуманных вами путей по сайту посетители проходят, а какие не выполняются по тем или иным причинам (их как раз и нужно понять). Анализ этих действий позволит улучшить ваш сайт и сделать его более конверсионным и «милым сердцу» поисковых систем. Раньше для этого приходилось проводить тестирование юзабилити с привлечением «подопытных тестеров» (как правило, неопытных пользователей интернета — «чайников», коих большинство в сети), а сейчас можно просто подсмотреть за посетителями своего сайта посредством Вебвизора.
Давно минули те времена, когда SEO-шники только покупали ссылки и оптимизировали сам сайт (хотя еще не всех их успели об этом предупредить). В современных реалиях Сеошники потихоньку эволюционируют в маркетологов, ибо по другому работать становится просто не возможно. Сейчас им приходится читать книги по маркетингу и юзабилити, составлять задания по изменению дизайна сайта, разбираться в собранной по сайту аналитике, работать над увеличением конверсии, проверять работу отдела продаж (контрольные звонки), вплотную работать с копирайтерами и форматировать написанные ими тексты.
Естественно, что проведение SEO-аудита и работу внутри сайта на основе полученных результатов тоже никто не отменял. Да и ссылки по-прежнему покупать нужно, но опять же, как мы говорили чуть выше, сейчас отбор доноров существенно усложнился, и даже тут жизнь сеошников уже не кажется медом (можете почитать статью — Легко ли сейчас быть Сео-шником). Ну и, кончено же, с контекстной рекламой сеошник обязан уметь работать, ибо для продвижения сайтов желательно использовать максимум из доступных каналов, включая, кстати, и социальные сети (читайте про продвижение сайта в Facebook).
Делаем вывод — сейчас результат приносит только комплексная работа с сайтом. Если что-то выпадает или этому не уделяется должное внимание, то под угрозу ставится весь результат работы. Поисковики постоянно улучшают свои алгоритмы и попытка «закрывать на это глаза» и делать то же, что делали пару-тройку лет назад, приведет, скорее всего, к краху.



Что же делать, чтобы SEO приносило выгоду, а не проблемы?
Итак, попробуем подытожить. Как же нам извлечь выгоду из SEO, а не потратить впустую «галимую кучу бабла».
- Во-первых, наверное, стоит учесть все то, о чем мы говорили чуть выше и подходить к SEO, как к сложному технологическому процессу, где все должно делаться в обязательном порядке и желательно в нужной последовательности. Наверное, вы встречали в сети различные чек-листы от разных именитых оптимизаторов, например, от Деваки. Ну и, конечно же, не допускать описанных выше ошибок.
- Обязательно проводите технический SEO-аудит сайта на предмет выявления ошибок, недоработок и пробелов. Прежде, чем начинать продвигать коммерческий ресурс, его нужно вылизать до блеска, чтобы не к чему было подкопаться (тайтлы, роботс.тхт, настройки сервера, Html теги, настроить перелинковку и все остальное, что можно отнести к внутренним факторам ранжирования).
- Поставить себя на место вашего посетителя (а еще лучше потенциального клиента) и постараться сделать сайт удобным для него (вебвизор вам в помощь). Это улучшит поведенческие и повысит оценки, полученные от асессоров. Сейчас как никогда актуально вкладывать деньги в юзабилити, причем на это следует обращать особое внимание, ибо за этим будущее.
- Постоянно стараться улучшать сайт и следить за конкурентами по Топу (в наиболее востребованных и интересных вам запросах), чтобы вовремя перенимать и внедрять необходимые новшества. Одним только улучшением дизайна и изменением функциональных блоков (или структуры сайта) можно добиться роста позиций по конкурентному запросу.
Без постоянного совершенствования можно в Топ либо вообще не попасть, либо вылететь из него за несоответствие текущим стандартам качества и функциональности сайта в вашей нише. Более того, если вы, наконец, попали в Топ, то пахать придется еще больше, чтобы там удержаться. Асессоры ставят в Топ 10 по высококонкурентной тематике только тех, кто хорошо работает с сайтом.
- Надо понимать, что даже правильная работа по технологии не позволит вам получить мгновенных результатов. Что-то начнет проклевываться в конкурентной тематике только после года усердной работы, которая на девяносто процентов будет состоять из улучшения юзабилити (тексты, структура, дизайн и другие виды внутренней оптимизации) и лишь небольшой закупки ссылок. Ну, а Топ этот сайт начнет штурмовать лишь года через полтора или два после начала процесса продвижения (опять же грамотного).
- Априори, правильно проведенная и периодически поддерживаемая SEO (сейчас уже правильнее говорить маркетинговая) кампания способна приводить к вам целевых клиентов, итоговая стоимость привлечения которых может быть в разы ниже тех, кого вы привлекаете посредством контекстной рекламы. Но Сео — это то блюдо, которое нужно уметь готовить, ибо в неумелых и неграмотных руках оно может вызвать серьезное несварение желудка и полное разочарование. А масса «неумелых поваров» (горе-сеошников), присутствующих на рынке, дискредитирует это вкуснейшее при правильном приготовлении яство (SEO) в глазах потребителей (владельцев сайтов).


Как создать сайт пригодный к SEO продвижению
Коммерческий сайт, в идеале, должен являться основным или одним из основных инструментов для привлечения клиентов (решать бизнес задачу). Однако, зачастую, в силу неправильного подхода, сайт кампании являет собой непонятно для чего созданную сущность, продвигать которую средствами SEO практически не возможно.

С каких позиций нужно подходить к созданию сайта или к оценке уже существующего интернет-проекта? Имеется в виду его будущая пригодность к SEO продвижению. Какой канал продвижения выбрать? На эти вопросы мы и попытаемся получить ответы в этой статье.
Дело в том, что существует масса примеров, когда создается сайт, на разработку и доработку которого тратятся огромные средства, а после его анализа на предмет пригодности к продвижению оказывается, что все нужно начинать делать с нуля.
Поэтому, еще до момента начала работ по созданию нового проекта, вы обязательно должны ответить на ряд архиважных вопросов.
4 шага ведущие к успеху будущего сайта
- Первым из них является вопрос о целях и задачах, которые сайт должен решать после того, как он будет создан и начнет функционировать. Вопрос непростой.
- Вторым важным вопросом начального этапа работы над проектом является определение целевой аудитории, которой этот сайт будет интересен и которая будет интересна владельцу сайта (чтобы это были потенциальные клиенты, а не праздношатающиеся граждане рунета). Другими словами, нужно определить круг людей, которые с высокой вероятностью купят ваш товар или закажут услугу.
Нельзя делать коммерческий сайт «для всех» — нужно сегментироваться. Т.е. максимально узко изначально определить свою целевую аудиторию, а уже по мере развития проекта вы сможете расширяться при благоприятных обстоятельствах.При описании целевой аудитории следует ориентироваться на район проживания этих самых желанных посетителей, их пол и возраст, стиль жизни, поводы для покупки вашего товара и т.п. вещи.
- После того, как целевая аудитория будущего сайта будет каким-то образом определена, то нужно сконцентрироваться на вопросе того, что именно эта аудитория ожидает найти на вашем сайте.
- Когда и это вы для себя определите, то останется уже решить технический вопросы функционала будущего сайта, чтобы он отвечал ожиданиям целевой аудитории.
На основании описанных выше пунктов вы составляете задание для тех, кто будет делать вам сайт (ну, или для себя самого, если делать его будете сами).
Самое главное — выбрать правильный путь
При этом проще всего будет начать с того, чтобы попытаться максимально объективно ответить еще на несколько вопросов:
- Для чего вы создаете сайт? Для чего он нужен вам лично? А также чем ваш сайт может быть полезен потенциальным посетителям? Понятно, что ваша цель это, скорее всего, заработать, и чем больше, тем лучше. А пользователю, по большей части, интересно, наоборот, сэкономить. Тем не менее, нужно найти соприкосновения между этими противоположными интересами и придумать, что вы можете предложить посетителям такого, из-за чего они с радостью захотят расстаться со своими деньгами.
- Чем ваш сайт будет отличаться от ресурсов конкурентов? Чем он будет лучше других?
Имеется в виду, что нужно будет изучить аудиторию ваших будущих конкурентов и, в идеале, предложить то, что никто из них до сих пор еще не реализовал (сделать потенциальным покупателям уникальное предложение). - Ну и после этого можно будет продумать тот функционал, который должен быть у вашего будущего ресурса для реализации задуманного.
- Также следует трезво оценить возможности своего бизнеса, чтобы отлично работающий сайт не споткнулся о невозможность выполнения всех полученных через него заказов на товары или заявок на выполнение услуг. В таком случае все вложенные вами силы и средства будут потрачены впустую, ибо это грозит потерей репутации, которую восстановить будет уже не возможно.
Что такое продвижение сайта и какие цели оно преследует?
Только после того, как вы определитесь со всеми этими вопросам, можно приступать уже непосредственно к постановке задач, которые должны помочь в продвижении сайта.
А что такое продвижение сайта? Если говорить формальным языком, это совокупность действий, направленных на то, чтобы ваш интернет ресурс достиг высот по основным показателям оценки его эффективности.
Для разных сайтов эти самые показатели эффективности могут быть совершенно различными (например, для коммерческих ресурсов это может быть конверсия, а для информационных — заработок на рекламе).

В связи с этим вам нужно сформулировать цели продвижения, достижение которых будет решать SEO. В первую очередь определиться с тем, что вы хотите от продвижения:
- Получить целевую, лояльную и постоянную аудиторию, которая будет проявлять активность на вашем сайте, совершая покупки или оставляя заявки на услуги
- Брендирование — повышение узнаваемости бренда, если таковой у вас имеется
- Ну и самое интересное — увеличение продаж (повышение конверсии)
- Что-то еще
Однако, чтобы реализовались описанные выше желания, вам потребуется решить ряд технических вопросов, которые в большинстве случаев могут выглядеть так:
- Попадание в ТОП 1-10 в органической выдаче Яндекса или Гугла по тем поисковым запросам, из которых состоит семантическое ядро вашего сайта (такие запросы потенциально могут приводить вам клиентов из поисковых машин).
- Увеличение посещаемости сайта.
- Наращивание Тиц и ПР — как правило, эти пузомерки не влияют напрямую на успех сайта, но многие считают их важными.
- Что-то еще
Однако, следует четко понимать, что сами по себе позиции в Яндексе, посещаемость или Тиц не могут быть вашими основными целями — это лишь способ реализации основных задач. На основе всего вышеперечисленного вы составляете так называемый Бриф для создания сайта, пример которого можно найти в интернете. Например, тут имеется «рыба» по его составлению.
5 основных способов продвижения коммерческих сайтов
После того, как вы определили цели, решаемые вашим интернет-проектом, и те показатели эффективности, по которым будете оценивать успешность его продвижения, можно приступать к изучению способов этого самого продвижения (пока сайт вам будут ваять). Их не так уж и мало.
Основными способами продвижения коммерческого сайта являются:
- SEO — оптимизация сайта (внешняя и внутренняя) под требования поисковых машин с целью занятия высоких позиций в органической выдаче по целевым запросам.
- Различные виды интернет-рекламы:
- Контекст (Яндекс Директ или Гугл Адвордс)
- Баннерная реклама (например, на информационных ресурсах подходящей тематики)
- Емайл маркетинг (рассылки)
- Тизерные сети
- Продвижение в социальных сетях (SMM)
- Размещение на различных торговых площадках и сервисах (Яндекс Маркет, Гугл Мерчант, Викимарт и т.п.).
- Непрямая реклама (BTL) — вирусный маркетинг, интернет-конференции, спонсорство, промоакции и другое. Успех здесь во много зависит от креативности и удачи. Сильно специфическая ниша.
Поисковое продвижение
Рассмотрим SEO. Суть его заключается в попытке занять позицию в органической выдаче (Яндекса или Гугла) максимально близкую к первой. Нужно понимать, что позицию занимает не сайт, а конкретная вебстраница, отвечающая данному запросу пользователя.
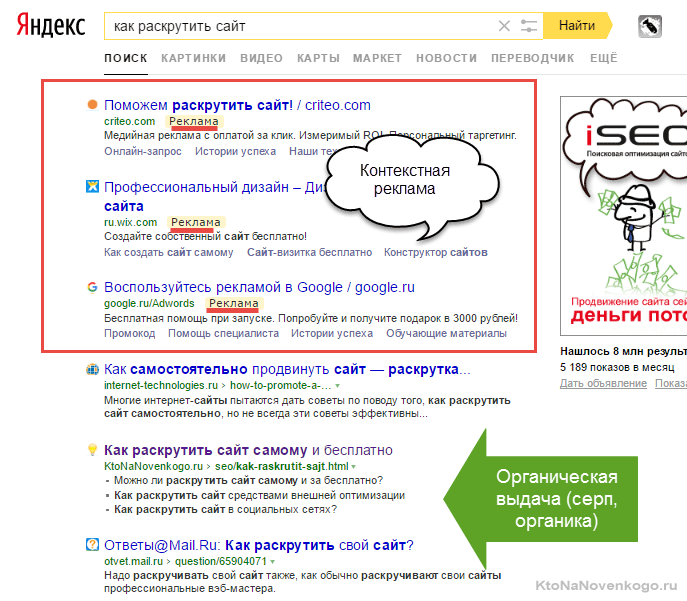
Сео имеет ряд особенностей, которые нужно учитывать при его использовании для продвижения своего сайта:
- У SEO достаточно длительный эффект, во всяком случае так было. Вполне нормальной является ситуации, когда благодаря поисковой оптимизации сайты стоят в Топе «как прибитые» по нескольку лет. Поэтому получается, что вложения в этот способ продвижения имеют долгосрочный характер (в пику, например, контекстной рекламе).
- С помощью СЕО можно привлечь большое количество более-менее целевых посетителей, ибо популярность поисковых систем очень велика. Другое дело, что доля отказов (просмотр всего одной страницы вебсайта в течении менее, чем 15 секунд) будет высокой среди аудитории, приходящей с поисковиков (50 — 70 процентов считается нормой). Это в разы хуже, чем при использовании контекстной рекламы. И это понятно, ибо пользователи не всегда корректно и четко формируют свои запросы поисковой системе, которая, в свою очередь, мысли читать не умеет.
- Время, необходимое на то, чтобы попасть в Топ по нужному запросу, может исчисляться половиной года. Все это время вы должны оплачивать временные ссылки, если они будут использоваться в продвижении.
- SEO — это еще и дорогое удовольствие. Полгода вам нужно будет не только ссылки оплачивать, не получая результата, но и зарплату сеошникам платить, если делаете это не сами. Конечно же, многое зависит от конкуренции в вашей нише, но кроме ссылок нужно еще оплачивать и оптимизацию сайта.
- Самое неприятное в Сео (кроме сроков продвижения и затрат) — это возможность наложения санкций на ваш сайт поисковыми системами (фильтр, бан, пессимизация и прочая напасть). Чем это грозит? Собственно, потерей всех вложенных средств. SEO — это рискованное предприятие.
Контекстная реклама
Ее блок видно на приведенном чуть выше скриншоте. Расположена она в окне выдачи поисковых систем на самом видном месте, ну, а также возможно размещение вашей рекламы и на сайтах партнеров (читайте про РСЯ и Гугл Адсенс). У контекстной рекламы тоже есть свои особенности, которые нужно знать и учитывать:

- Контекстной рекламой удобно управлять и планировать расходы. Все прозрачно в отличии от СЕО. Вы точно сможете рассчитать цену привлечения посетителя и, ориентируясь на нее, планировать свой рекламный бюджет.
- Еще одним плюсом контекста является практически мгновенная отдача. За пару дней можно разобраться в нюансах, создать и настроить рекламную кампанию, после чего ее запустить и сразу почувствовать отдачу в виде наплыва посетителей.
- Однако, если вы хотите получить высокоцелевой и высокоэффективный трафик, то потребуется вести постоянный контроль за расходами и производить подстройку рекламной кампании для увеличения конверсии этих самых посетителей на вашем сайте. Кстати, совсем недавно писал про интересный сервис CoMagic, помогающий высчитывать рентабельность рекламной кампании даже среди тех посетителей, которые делают заказ по телефону (а таких около половины от общего числа).
- Из предыдущего пункта можно сделать вывод, что рентабельность использования контекстной рекламы для продвижения сайта полностью зависит от квалификации специалиста, который создавал и оптимизировал рекламную кампанию. Если сравнивать с Сео, то цена привлечения одного посетителя будет, скорее всего, выше в контексте, но вот цена привлечения покупателя (сделавшего транзакцию) может быть ниже в силу более целевого трафика. Но это далеко не постулат.
Продвижение в социальных сетях
Социальные сети, как источник привлечения пользователей на сайт, сейчас все больше и больше набирают популярность, но, тем не менее, развит этот канал продвижения, по сравнения с СЕО и контекстом, пока еще только как дополнительный. Это, конечно же, относится к рунету, т.к. в буржунете социалки используют куда как более активно и профессионально.

В чем заключаются особенности продвижения сайта в социальных сетях?
- При правильном ведении работы в социальных сетях, вы получаете контакт непосредственно с вашей целевой аудиторией (без примесей).
- В следствии чего, конверсия этого канала привлечения посетителей будет очень высокой, ибо все они являются вашими потенциальными клиентами.
- Для реализации задач продвижения в социальных сетях создаются страницы, группы и любые другие сообщества, объединяемые общим интересом, который так или иначе пересекается с вашим сайтом. С этой аудиторией нужно постоянно работать (чуть ли не круглосуточно). Выкатывать какие-то интересные материалы, заманчивые предложения, отвечать на вопросы, общаться и т.д. Поэтому этот канал продвижения требует повышенного и, что не очень приятно, постоянного внимания.
- Поток посетителей с групп в социальных сетях, скорее всего, будет не очень большой. Но так как он высококачественный, то отдача будет высокой.
- Результат такого способа продвижения наперед предсказать очень сложно.
Торговые площадки
Ярким примером может служить Яндекс Маркет.
Давайте по традиции рассмотрим особенности и этого метода продвижения:
- По скорости отдачи торговые площадки ничем не уступают контексту.
- Затраты тоже не малые, ибо вы платите за клики (переходы на ваш сайт) по аналогии с контекстной рекламой.
К сожалению, рентабельность этого канал продвижения крайне низкая. Почему? Ну, потому что по одному и тому же запросу могут конкурировать многие тысячи сайтов, а единственным значимым для покупателя критерием будет цена. Следовательно, вам придется ее снижать, и маржа будет выходить минимальная.
Есть еще такая вещь в Яндекс Маркете, как рейтинг магазина (звездочки), но на практике это особо ничего не значит, если цена у вашего конкурента будет на десять рублей ниже (при той же стоимости доставки). Поэтому не всякие товары имеет смысл выгружать на торговые площадки — только те, где изначальная наценка крайне высокая (процентов сорок и выше).
- На сайте должны быть установлены специальные технические средства, которые будут подготавливать обновления для файла, который используется для выгрузки на Маркет. Это необходимо для того, чтобы на торговой площадке ассортимент вашего магазина полностью соответствовал реальности (добавлялись новинки и снимались распроданные товары).
Что делать дальше?
Следует проанализировать все возможные каналы продвижения сайта (описанные выше), оценить каждый из них на предмет того, подходит ли он для увеличения показателей эффективности именно вашего интернет-проекта и сделать окончательный выбор. При этом вам вовсе не обязательно выбирать что-то одно. Чаще всего используется несколько каналов.
Также следует понимать, что есть ниши, в которых нет особого смысла уповать на SEO, а есть ниши, где контекстная реклама будет не эффективна. Ну, а социальные сети вообще имеют еще большую избирательность, ибо интересы пользователи социалок далеко не со всеми коммерческими тематиками имеют хоть какое-то пересечение. Ну, а Яндекс Маркет подойдет только для продажи товаров (но не услуг), да и далеко не всех товаров подряд.
После этого вы составляет опять же Бриф на продвижение сайта, и специалист начинает проводить в жизнь выбранную вами стратегию. Это мы как бы побывали в шкуре владельца сайта, а вот в последующих публикациях уже попробуем влезть в шкуру Сео-специалиста и понять, как действовать после получения задания на продвижение интернет-ресурса.
Ссылочная масса — что это такое и как ее правильно сформировать
Хочу еще поговорить про основополагающую в современном SEO концепцию продвижения — получение естественных ссылок. Начнем мы с того, что определимся зачем это нужно и как их следует формировать. Хотя, конечно же, слово «естественных» тут стоит брать в кавычки, ибо формировать ссылки мы будем в том числе и целенаправленно, что с понятием «естественный» несколько расходится.
Но не суть — главное, чтобы для поисковых систем все это выглядело натурально (в границах допустимого) и не вызывало бы у них желание пессимизировать продвигаемый таким образом сайт. Как раз для этого нужно будет соблюдать некоторые правила (например, не превышать допустимую скорость прироста ссылок), что в особенности актуально при продвижении молодых сайтов.

Методы получения «как бы естественных» и «реально естественных» ссылок будем рассматривать различные, в числе которых и часто упоминаемый мною в последнее время «контент-маркетинг», а также безанкорные ссылки и анализ успешных (твердо находящихся в Топе) конкурентов.
Сразу оговорюсь, что полученные «естественные обратные ссылки» будут положительно сказываться на сайте в течении длительного времени (таким образом вы делаете долгосрочные вложения), но с другой стороны — вы должны будете заниматься этим делом постоянно (это не одноразовая акция). Ко всему прочему, дело это долгое (нужно будет провести целый комплекс мероприятий) и может быть очень даже не дешевым. Но для тех кто хочет стабильности, а не «минуты в Топе», альтернативы этому методу по сути и нет.
Шесть доводов «за» естественность и ни одного «против»
Если начнете думать (и что важно — начнете делать) об этом прямо сейчас, то результаты не замедлят сказаться в срок от полугода до двух лет. Ничего себе перспективка? Да! Но это современные реалии — от этого никуда не уйдешь. Дешево это тоже не будет. Придется тратиться на качественные тексты, инфографику, видеоматериалы, а также на распространение всего этого «нажитого непосильным трудом» по тематическим и околотематическим ресурсам. Взамен вы получите как раз те самые «естественные» обратные ссылки.
Как только появится отдача от ваших трудов (через полгода, год или два) вы сможете с этим делом завязать (успокоиться и просто снимать пенки). Или нет? Конечно же, нет. Всей этой «мутной тенью» придется заниматься ровно столько, сколько живет ваш сайт. Ни больше, ни меньше. Ладно бы еще терпимо, если вы продвигаете свой проект и сами себя уговорить сможете. А если сайт клиентский? Придется и клиента убедить в ценности естественной ссылочной массы, и главное стоящих за этим «чудовищных» трат и непрерывного процесса совершенствования. Но это уже ваша проблема... Мы же подойдем к вопросу «технически».
Хотя можете клиентам (и себе при желании) «поездить по ушам» такими вот доводами в пользу естественности (натуральности):
- Естественные ссылки сейчас в тренде и это неимоверно круто. Ну, ооочень круто... Буржуи уже давно на это только и уповают, в ведь они чутка впереди нас бегут на поприще СЕО...
- Если клиенты на слово не поверят, то можно еще аргументиков накидать. Например, с таким ссылочным багажом сайт получает некую универсальную прививку, помогающую не бояться попадания под фильтры поисковых систем за чрезмерное увлечение внешней оптимизацией. Это, конечно же, не броня, но шансы попасть под пресс многократно уменьшаются, по сравнению с классическим (в рунете) методом набора ссылочной массы.
- В теории (по типу сферического коня в вакууме) такие обратные ссылки должны быть в большинстве своем тематические и жуть как интересными посетителям этих тематических ресурсов, а значит с них можно будет получить либо временный, либо постоянный приток целевого трафика (не с поисковых машин), хорошо конвертирующегося в дополнительную прибыль.
- Кроме прямой выгоды разнообразие источников трафика замечательно воспринимается поисковиками, что может положительно сказаться и на росте трафика с Яндекса (и Гугла). Со всех сторон хорошо, куда не глянь (в теории, по крайней мере).
- Степень расхождения теории с практикой будет зависеть сугубо от вас — насколько серьезно подойдете к делу (продумаете, изучите подрядчиков, найдете подходящих исполнителей), сколь компромиссными будут выбранные решения и сколь щедры вы будете в итоге. Ну, и от везения, конечно же, многое зависеть будет.
- Даже если впряжетесь в создание естественного ссылочного кластера «по полной» и не зная отдыха начнете линкбилдить, то все равно рост ссылочной массы будет постепенным. Устроить таким образом «ссылочный взрыв» будет крайне затруднительно (если вообще возможно). Хотя бы одно проблемой будет меньше.
В принципе, именно так нужно было набирать ссылочную массу всегда (пять и даже десять лет назад), но в силу сырости алгоритмов ранжирования поисковиков в то время, можно было этого не делать, но в Топе сидеть чуть ли не безвылазно. Потом стало чуток похуже, но по-прежнему существовали методы обмана поисковиков, когда срабатывал метод «дешево и сердито». Сейчас же стало совсем невмоготу «юлить» и все старые трюки поисковыми системами выявляются и по большей части фильтруются.
Яндекс и Гугл прекрасно понимают, какая именно ссылка ведет на ваш сайт — покупная или естественная. Ну, не то что бы все секут, но то что делается на потоке — практически с близкой к стопроцентной вероятностью. Это знание, в зависимости от многих других факторов связанных с продвигаемым сайтом, могут выражаться в игнорировании таких беклинков, их частичном учете, либо их учете с отрицательным влиянием на ранжирвоание, или же поисковики вообще могут наказывать за них. Последнее хорошо можно видеть на примере Минусинска и Пингвина. Минусинск похоже оказался настолько эффективным, что Яндекс даже начинает сдавать назад в своем намерении совсем отказаться от учета ссылок. Точнее уже окончательно сдал (ссылки уже учитываются даже по коммерческой московской выдаче).
В общем, продвигать сайты стало сложнее, но многие говорят, что интереснее (возможно, что это энтузиасты своего дела, либо мазохисты).
Если бы вы пять-десять лет назад начали бы формировать естественную ссылочную массу, то 99% ваших коллег не переставая ерничали и подтрунивали бы над вами, ибо их методы позволяли добиться результата быстрее, дешевле и с большей вероятностью. Правда сегодня пришла бы ваш очередь смеяться, но думаю, что коллеги в большинстве своем уже «перешли на светлую сторону силы» (следуя тренду), либо вообще слились из этого бизнеса (либо находятся в упадке). «Дешево и сердито» оказалось синонимом не долговечно («не долго музыка играла»), а Естественность же обещает как раз стабильность в очень продолжительной перспективе.
Чем характерна неестественная ссылочная масса
- Имеет место быть засилье коммерческих анкоров (явно не естественный анкор-лист, когда используются лишь слова ВЧ, СЧ и НЧ запросов данной ниши). Кто-либо из реальных жителей сети в здравом уме не будет ссылаться на какой-то сайт с анкором (текстом ссылки), например, «бруски железные купить». Да и просто «бруски железные» употребит один из тысячи гипотетических ценителей, который под впечатлением решил поделиться столь ценной для общества информацией.
- В ссылочной массе полученной неестественным путем отсутствуют ссылки с адресом продвигаемого сайта вида «ktonanovenkogo.ru», «https://ktonanovenkogo.ru» или «www.ktonanovenkogo.ru», то это крайне противоестественно. Ну, просто фи, как неестественно.
- Отсутствуют ничего не значащие анкоры (текст которых по сути не учитывается поисковиками, поэтому их и прозвали безанкорными ссылками). О том, какие именно слова подходят под это определение, можно спорить, но поисковики просто смотрят на то, с какими анкорами чаще всего ссылаются на сайты со стопроцентным естественным ссылочным кластером (Вики, например, и подобные ей ресурсы) и ждут, что у продвигаемого вами сайта будет примерно так же (или хотя бы похоже). Например, такая запись будет, наверное, выглядеть естественно: «глянь тут (с этого слова ставится ссылка) железные бруски по вкусной цене можно отхватить (почти халява)».
- Методы из описанной выше серии «дешево и сердито», как правило, не предусматривали того, чтобы бэклинки закупались строго с тематических сайтов, ибо это усложняло процесс, да и почти всегда в нише не находилось достаточно «продажных ресурсов» нужной тематики, готовых сослаться на вас за «малую толику» (основной принцип оптимизатора тогда был — чем больше, тем лучше). Таким образом, засилье нетематических ссылок также стало одним из маркеров для поисковых систем, говорящих о том, что их пытаются надуть.
- «Скажи мне кто твой друг и я скажу кто ты». Ссылка по сути должна представлять «голос дружественного ресурса» отданный за ваш ресурс, как авторитетный по данному вопросу. Так вот, если на вас будут ссылаться в огромном количестве отстойные, убогие и ущербные ресурсы (ГС, сателлиты — по минимумы пользы, по максимуму извлекаемой выгоды), которым самое место только на помойке истории, то и вас поисковики с радостью запишут в ту же когорту. Поэтому бойтесь испачкаться.
- Как я уже упоминал чуть выше, строить естественный ссылочный плацдарм пять-десять лет назад было моветоном (что это такое?) — зачем упираться, когда и так все продвигается в Топ замечательно. Сейчас с таким же скепсисом кто-то относится к кликабельности ссылок (получить их реально сложно, а выгода от их присутствия в анкор-листе не всегда очевидна на данный момент). Ну да, это работа по большей части на перспективу, но и естественное продвижение это тоже на перспективу.
Возможно, что через пару лет беклинки, по которым нет и не было никогда переходов живых (не подставных) жителей интернета, вообще учитываться не будут, а может быть они уже перестали учитываться. Как только поисковики будут готовы, они обязательно запустят учет кликабельности ссылок на полную катушку, как это, например, сейчас пытается сделать Яндекс с поведенческими факторами. Все упирается не в желание, а в возможности и актуальность выполнения этой задачи. В планах у поисковиков это уже точно есть, а значит и мы должны быть готовы — какая-то часть ссылочной массы обязательно должна быть кликабельной уже сейчас. И наоборот, при методе «дешево и сердито» , скорее всего, не будет вообще заходов по ссылкам.
- Естественность также характеризуется наличием линков с разных типов сайтов, а не только с тех, которые представлены в биржах ссылок (по сути все ГС и сателиты для поисковиков на одно лицо), а еще которые были получены прогонами (например, по форумам или по ГС-каталогам ). У «хорошего хозяина» в загашнике должно быть всего до кучи: беклинки с блогов, форумов, социальных сетей, новостных сайтов, региональных, сайтов из Топа вашей ниши, тематических, околотематических и других всяких разных и желательно полезных пользователям ресурсов.
Что придает ссылочной массе признаки естественности?
В принципе, можно часть из признаков получить из предыдущего списка путем логического инвертирования, но все же стоит частично повториться, чтобы разложить все по полочкам.
- В естественной массе будет очень много ссылок с названием сайта (типа, Кто На Новенького или ktonanovenkogo), его Урлом (URL адресом или хостом — https://ktonanovenkogo.ru или ktonanovenkogo.ru ) или названием бренда, который он представляет.
- Будут в том числе и не активные ссылки (не все кто ссылается умеет это правильно оформить в виде гиперссылки — особливо с форумов, соцсетей и т.п.), по которым переход как таковой совершить нельзя, но можно скопировать текст ссылки и вставить в адресную строку.
- Достаточное количество бэклинков идущих с картинок придает налет естественности.
- Много безанкорных обратных ссылок (со словами здесь, тут, этот, ссылка и т.п.). Сюда же наверное можно отнести и анкоры со сверхнизкочастотными ключами (грубо говоря, очень сильно разбавленные).
- Коммерческие анкоры в естественном ссылочном фундаменте безусловно имеют место быть, но совсем не доминируют.
- Много тематических ссылок вы найдете в любом абсолютно честном или совсем не продвигающемся, но успешном сайте.
- Имеется достаточное количество кликабельных линков, по которым идет реальный трафик на сайт, о двойной пользе которого мы говорили чуть выше.
- Социальные сети среди доноров тоже должны быть широко представлены.
- Как уже говорилось выше, у «натуралов» должны присутствовать разные типы сайтов-доноров в обойме: СМИ, соцсети, блоги, форумы, региональные сайты (вашего и соседних регионов), глобальные проекты из ниши, сайты широко представленные в Топе вашей ниши, государственные проекты и ресурсы учебных заведений (важно в основном для буржунета), просто ресурсы вашей тематики и прочая, прочая, прочая... Чем шире (не выходя за пределы разумного), тем лучше.
В общем, где-то так получается. Ситуация складывается несколько нетипичная для тех, кто привык «дешево и сердито». Придется, например, смириться, что при создании и продвижении сайта возникает необходимость довольно много внимания (времени и денег) уделить созданию качественного контента (вирусных текстов, видео, инфографики) не для размещения непосредственно на самом ресурсе, а для распространения в интернете.
Если сравнивать с рыбалкой, то к наживке находящейся на крючке (контенту на сайте) рыбку (посетителя) еще нужно будет привлечь прикормкой (этим самым контент-маркетингом, крауд-маркетингом и т.п.). И это лишь одна из особенностей присущих набору оптимального ссылочного веса. Как я уже говорил выше, продвигать сайты действительно стало сложнее в разы, но в какой-то степени интереснее (чем сложнее задача, тем больше испытываешь удовлетворения от ее разрешения).
Набор оптимального ссылочного веса — Шаг второй: осмысление
В связи со всем высказанным, было бы логично обрисовать (пока только в общих чертах) метод формирования естественного ссылочного пула. Способы реализации могут разниться, но используемые принципы можно описать так: берем пул запросов, идем в Яндекс, находим тех кто в Топ 10, смотрим их бэклинки (сервисы приведены будут ниже) и выбираем лучшее, после чего договариваемся с владельцами этих «золотых» сайтов-доноров о размещении и в результате получаем «респект и уважение» от поисковиков, выраженные в непомерном росте тематического трафика и ваших доходов.
Начать можно будет, например, так. Сразу оговорюсь, что дело это муторное и трудоемкое, но вполне выполнимое. В результате вы сможете получить, скорее всего, лишь десяток другой ссылок (где-то за деньги, где-то за счет размещения своего первоклассного контента), но они в итоге могут стоить сотен и даже тысяч закупленных по старой схеме. Готовы? Ну, тады продолжаем.
- Есть такой замечательный сервис, о котором я уже немного писал в одной из относительно недавних статей — Rankinity — сервис проверки позиций сайта в режиме реального времени. Сервис платный, но цены вполне реалистичные. Детально его описывать не буду, ибо уже это в какой-то мере сделал, да и вы сами в состоянии разобраться (дочитали же до этого момента...). Опишу лишь суть того, что можно с помощью этого реализовать.
Если кратко, то вы загружает в Rankinity ключевые слова, по которым планируете продвигаться. По ним система поможет отыскать те сайты (входящие в первую сотню Топа по этим запросам), которые довольно быстро в этот Топ вышли (т.е. предполагаем, что ссылочная масса у них была просто замечательная и поэтому в Топ их занесло как на крыльях).
Их ссылочную массу данный онлайн-сервис позволяет довольно быстро проанализировать и выбрать для себя перспективных доноров. Замечательно, что можно будет отслеживать все новые бэклинки получаемые вашими успешными конкурентами практически в реальном времени и иметь возможность выстроить их по рангу (качеству), чтобы удобнее было снимать сливки особо не напрягаясь.
Отобранные таким образом доноры будут с высокой долей вероятности качественными, а проставленные с них ссылки (если удастся на них разместиться — придется списываться с владельцами и делать предложения, от которых трудно отказаться) тематическими и зачастую даже кликабельными (а это два важных принципа формирования естественного ссылочного плацдарма). Последнее, конечно же, сильно зависит от того, где именно на донорах вы договоритесь разместить ссылку.
Например, если это будет нишевый информационный ресурс, то можно предложить для публикации «взрывающую мозг» статью или инфографику, что вполне может послужить причиной очень приличного трафика с этого ресурса на ваш. Главный цимус в том, что вы не будете «метать бисер перед свиньями» (и идти на ощупь), а ударите из крупного калибра именно по большому скоплению вашей целевой аудитории, которую априори высоко оценили поисковики.
Наверное, то же самое можно проделать и в каком-то похожем онлайн-сервисе, но в Rankinity сделать это проще, как мне показалось. Вы имеете другое мнение? Замечательно. Если это не «фамильный секрет», то намекните в комментарии.
- Ahrefs — «серьезный» ресурс из разряда «должно быть у всех». Тоже позволяет реализовать похожую схему упрощенного розыска жемчужин в куче д... Расценки тут в доллорях, но тоже вполне себе вменяемые. Куда нужно смотреть?
Ссылки не работают? А так ли это на самом деле?
Очень многие используя SEO продвижение через некоторое время начинают терзаться сомнениями, что, наверное, они как-то не так или не там закупают ссылки, либо не правильно крутят поведенческие. Результата-то нет, хотя уже и прошло много времени. Но в большинстве случаев «ларчик отрывался вообще с другой стороны». Дело в том, что любые действия помноженные на ноль в результате дадут ноль. Под нулем я имею в виду работу по внутренней оптимизации сайта. Без этого ссылки и какие-либо другие способы внешнего воздействия на сайт работать не будут.
Начинать продвижение нужно по-любому с внутренней оптимизации. Сделать технический аудит (статья немного устарела, но я постараюсь написать новую, а пока можете почитать про зеркала и редиректы с ответами сервера), чтобы удостовериться, что нет никаких препятствий к успешному продвижению сайта в плане правильности работы сервера и прочих вещей.

Опять же, нужно разработать для сайта полноценное и полноразмерное семантическое ядро (можно самому напрямую с помощью Вордстата собратть, хотя лучше использовать автоматизацию, например, Кейколлектор, о котором хочу поговорить подробно в ближайших статьях.
Ну и проверить свой сайт на наличие других ошибок, которые могут мешать его SEO продвижению, тоже нужно. На что именно смотреть и как это исправлять читайте в статье «Что мешает SEO-продвижению вашего сайта и как это исправить». Дело-то серьезное, и подходить к нему нужно со всей ответственностью и соблюдением последовательности действий.
Собственно, через несколько месяцев после внутренней оптимизации, даже без закупки ссылок часть запросов из вашего семантического ядра может вполне попасть в Топ. Понятно, что это не будут высокочастотники, но ведь как раз по НЧ (читайте про SEO терминологию по ссылке) процент конверсий намного больше (с условием, что семядро вы составили адекватное). Однако, несмотря на всю очевидность этого факта, мало кто сначала проводит внутреннюю оптимизацию, предпочитая сразу переходить к закупке ссылок. Так делать нельзя, даже если очень хочется.
Таким образом, по поводу внутренней оптимизации сайта никаких других мнений кроме того, что делать ее надо обязательно, быть не может. А вот по поводу того, влияют ли сегодня ссылки на ранжирование сайтов в поисковых системах, все больше и больше возникает споров. Понятно, что вопрос этот далеко не такой однозначный, как упомянутые внутренние факторы, но все же однозначно можно утверждать, что ссылки по-прежнему влияют на успех продвижения сайта.
Другое дело, что это влияние существенно снизилось за последние годы. Споры же возникают в основном из-за того, что ссылочное ранжирование за это время перешло из разряда топовых факторов в разряд не основных. Т.е. сейчас закупка тонны ссылок на молодой сайт не вознесет его до небес, как это было раньше. В этом смысле сайты стало продвигать намного сложнее, хотя и не так уж, чтобы совсем сложно или не возможно. Просто нужно правильно расставлять акценты и приоритеты, не зацикливаясь как раньше только на наборе ссылочного.
Кроме этого, если рассматривать всю ссылочную массу, которую коммерческие сайты смогут собрать за время своего существования, окажется, что в лучшем случае только десять процентов ссылок (а то и меньше) реально будут влиять на ранжирование сайта, а остальные являются просто балластом. Этот процент можно повысить, но для этого надо будет знать некоторые тонкости и тратить на это время, а также прикладывать мозг. Все на той же Сапе, по грубым прикидкам, процентов пять вполне себе хорошо работающих ссылок (в абсолютных цифрах это очень много), но их надо искать, фильтровать ГС и нетематические, проверять вручную и т.п.
Поэтому на данный момент я бы рекомендовал вам уделять получению внешних ссылок не более десяти процентов своего времени, а все основные усилия бросить на внутреннюю оптимизацию сайта. Дело это не простое, а в случае коммерческих сайтов, кроме технического аудита и сборки семядра, придется еще думать над дизайном и функционалом сайта, чтобы он как минимум не был хуже сайтов конкурентов (только достойный продукт сейчас получает право закрепиться в Топе). Еще раз предлагаю посмотреть на некоторые особенности продвижения коммерческих сайтов.
Будем считать, что порядок на своем сайте вы навели, тем самым удостоились права закрепиться в Топе по нужным вам запросам. Но вот уже для того, чтобы попасть в этот Топ, нам пригодятся любые мало-мальски значимые факторы ранжирования, которыми можно в той или иной степени пытаться манипулировать (можно использовать слово улучшить, но будем называть вещи своими именами). Одним из них по-прежнему являются ссылки. Однако, для того, чтобы их правильно использовать, нужно для себя уяснить — зачем же вообще сайту нужны ссылки (любые, не только внешние).
Как ссылки на сайт сейчас учитываются поисковыми системами?
На самом деле я об этом уже частично говорил в статье «Анкор — что это такое и насколько они важны в продвижении сайта», но повторюсь. У ссылки в связке с той страницей, на которую она ведет (ее еще называют обратной ссылкой), есть несколько основных качеств, каждое из которых учитывается поисковыми системами при ранжировании:

- Во-первых, это накапливание страницами вашего сайта так называемого статического веса. Для каждого докуметна, размещенного в сети интернет (веб-страницы), этот вес рассчитывается отдельно. Зависит он от числа ведущих на данную страницу (ее называют в этой схеме акцептором) ссылок с других страниц (их называют донорами) этого же или какого-либо другого сайта. Причем статвес акцептора будет зависить не только от числа доноров, но и от их собственного статвеса. Тексты ссылок при этом в расчет никак не принимаются. По сути, этот же алгоритм лежит в основе расчета Пейдж Ранка.
- Кроме статвеса каждая страница вашего сайта накапливает еще и анкорный вес (его еще иногда называют динамическим). Он полностью зависит от имеющегося у ведущей на данную страницу ссылки текста (он как раз и называется анкором). Чем точнее анкор совпадает с поисковым запросом, по которому вы данную страницу пытаетесь продвигать (чем выше будет плотность вхождения), тем больший динамический вес сможет передать эта гиперссылка.
- Как ни странно это звучит, но гиперссылки придумали для того, чтобы по ним можно было переходить на другие документы в сети. Соответственно, ссылки — это худо-бедно, но все же еще и трафик, т.е. определенный поток посетителей, привлекаемых на ваш сайт. Отсюда следует еще одно свойство ссылки — ее кликабельность. Не важно, внутренняя или внешняя ссылка, но если по ней переходят пользователи (живые люди, а не боты), то это является ярким свидетельством ее качества, ибо она востребована. Получение кликабельных обратных ссылок очень актуально на сегодняшний момент и является нашей основной задачей, хотя получить их не просто и стоят они не дешево.
Также не стоит строить иллюзий, что поисковые системы не способны отличить естественные ссылки от покупных. Уже лет пять как это может делать Яндекс (алгоритмически и с помощью асессоров) и, возможно, еще дольше это умеет делать Гугл. Другой вопрос, что зная это, поисковая система все же не отбрасывает этот фактор ранжирования, продолжая учитывать часть из покупных ссылок. Особенно это касается тех из них, по которым осуществляются переходы (кликабельных).
В статье про анкоры (см. чуть выше) я довольно подробно останавливался на вопросе влияния текста обратных ссылок (ведущих на данную страницу) на ее ранжирование по определенному поисковому запросу. Мы упоминали, что наибольший вклад, по идее, должны приносить ссылки, текст которых полностью совпадает с ключевым запросом, по которому продвигается данная страница. Новички Seo-шники (или выступающие в их роли владельцы сайтов) воспринимают этот факт упрощенно и покупают сразу сотни, а то и тысячи беэклинков с прямым вхождением.
Добиться таким образом сейчас прогресса очень сложно, если не сказать, что не возможно. Поисковики прекрасно видят и количество, и качество закупаемых вами ссылок. Констатируя появление большого количества бэклинков, ведущих на ваш сайт, с прямым вхождением какого-либо высокочастотного запроса (да еще и коммерческого), поисковые системы все это дело замечательно отфильтровывают, и вложенные вами средства оказываются потраченными нерационально.
Потом такой человек добавляет свой голос к армии тех, кто говорит о том, что ссылки уже не работают, SEO умерло и пора идти в Директ. Собственно, в Директ (и вообще в контекстную рекламу) можно идти и параллельно с поисковым продвижением, ибо это даст мгновенный приток посетителей, а результатов от Сео еще годик или даже поболе придется подождать. Но вот зато когда они появятся, вы, скорее всего, ощутите, что стоимость привлечения покупателя в этом случае получается существенно ниже. Но это уж как повезет.
Теперь еще пару слов про статический вес. Я забыл чуть выше упомянуть, что передаваемый страницей вес делится поровну между всеми исходящими с нее ссылками (не важно, внутренние они или внешние). Что это нам дает? Ну, на основе этого факта можно фильтровать страницы-доноры, которые особой пользы вам в продвижении не принесут. Каков будет портрет идеальной страницы-донора в плане статвеса, с которой вам было бы желательно получить ссылку?
Ответ очевиден. С этой страницы должно вести как можно меньшее число исходящих внутренних и исходящих внешних ссылок, и одновременно с этим на нее должно ссылаться как можно большее количество других страниц (если они будут еще и тематичны вашей, то кроме этого повысится вероятность учета данного бэклинка поисковиками). В этом случае у донора будет хороший статический вес и он сможет довольно серьезную его часть передать вам (статвес будет поделен между всеми исходящими ссылками, включая и вашу).
То же самое касается и вашего собственного сайта. В теории, если с него будет проставлено много внешних ссылок, то тем самым вы несколько уменьшите статический вес, передаваемый на внутренние страницы сайта. Но, скорее всего, это будет справедливо только при серьезном их количестве, а в большинстве случаев с этим заморачиваться не стоит. Хотя, ссылаться со своего сайта на множество ГС тоже не стоит, уже из других соображений (поиск может вас самих причислить к ГС). На хорошие же сайты ссылаться можно и даже нужно, если это будет уместно (естественность и еще раз естественность).
Какие бэклинки покупают и зачем?
Так, идем дальше. Мы узнали, как ссылки могут влиять на ранжирование вашего сайта. Теперь давайте посмотрим, какие бывают ссылки с точки зрения текста, заключенного внутри них (анкора). На всякий случай напомню вам, что гиперссылки в Html представляют из себя конструкцию вида:
<a href="путь до файла web страницы">анкор (текст, который будет являться ссылкой)</a>
Поэтому возможны следующие варианты беклинков (обратных ссылок на ваш сайт):

- Безанкорные — несмотря на название, текст в таких ссылках присутствует, но осуществлять по нему ранжирование поисковым системам крайне затруднительно, ибо этот текст представляет из себя какие-нибудь распространенные слова типа наречий «тут», «здесь», «там» или других общих слов (например, «этот сайт»). К ним еще можно отнести бэки, где в качестве текста выступает адрес этого сайта (его Урл, например, так — https://ktonanovenkogo.ru).
Для чего они нужны? Очевидно, что для разбавления анкор-листа (это тексты всех ссылок, ведущих на данную продвигаемую вами страницу). Это придает ссылочной массе налет некой естественности. Что примечательно, поисковые машины даже из безанкорных бэклинков пытаются выжать какую-то информацию, могущую пригодиться при ранжировании. Поэтому они, не найдя в тексте ссылки чего-либо имеющего смысл, начинают искать где-то рядом, и могут учесть в качестве анкора околоссылочный текст (перед или после ссылки). Можете им помочь и расположить рядом ключевые слова или их синонимы.
- С прямым вхождением ключевых слов — самый распространенный и очевидный тип анкора, ибо достаточно просто взять поисковый запрос, по которому вы планируете продвигать данную страницу своего сайта, и окружить его открывающим и закрывающим тегами гиперссылки. Ничего выдумывать не надо. Именно это и является их слабым местом, ибо покупная суть таких бэклинков видна поисковым системам даже невооруженным взглядом. Судите сами.
В естественном анкор-листе сайта, на который ссылки никогда не закупались, бэков с прямым вхождением будет крайне мало (там будет больше безанкорных бэклинков с упомянутыми выше словами, или просто с адресом сайта в качестве анкора). А вот уже в случае сайта, продвигающегося покупкой ссылок, подобных анкоров будет гораздо больше (да чуть ли не все, потому что по определению эффект от прямого вхождения должен быть больше). Но не стоит забывать, что поисковики все это замечательно фильтруют при обнаружении признака перехода за границы естественности.
- С разбавленным вхождением — в этом случае в качестве анкора используется текст запроса, плюс к нему добавляется какое-то разбавочное слово. Слова для разбавки зачастую берутся просто из семантического ядра, либо используется что-то универсальное, подходящее в большинстве случаев (дешево, недорого, город и т.п.).
- С околоссылочным текстом — они довольно часто используются при закупке в Сапе и ей подобных биржах, либо в ссылочных агрегаторах (таких, как, например, Мегаиндекс, Сеопульт и им подобных). По сути, они из себя представляют законченное предложение, похожее на заголовок рекламного объявления, но тегами ссылки окружается только нужный ключевой запрос (не обязательно в прямом вхождении):
Быстрое <a href="Урл">создание сайтов</a> всего за 100 рублей
При повременном размещении ссылок (например, в Сапе) этот вариант считается более предпочтительным, ибо ссылка получается как бы вписанной в текст, а не стоящая сбоку-припеку (повышается вероятность, что по ней кто-нибудь кликнет). При закупке вечных ссылок в Гогетлинке, и уж тем более при размещении статей, подобный вид ссылок вам не понадобится, ибо будет реальная возможность не только вписать ссылку в текст, но и весь текст написать под эту ссылку. Но это стоит дороже, поэтому при закупке арендных ссылок такой вид анкоров довольно часто используется. - Ссылки, в которых в качестве анкора используются изображения — в естественном анкор-листе подобные ссылки встречаются, поэтому никто не мешает вам их купить. При этом было бы не плохо, если бы рядом с этой картинкой в тексте встречались ключевые слова, по которым вы продвигаетесь, ну и в атрибуте alt (или title) тега A (гиперссылки) тоже ключевые слова можно было бы упомянуть.
Быстрое создание сайтов без предоплаты в Москве. <a href="Урл"><img src="урл картинки" alt="Создание сайтов" /></a> Сайты-визитки, интернет-магазины и другие сложные сайты по сходной цене.
Служат они опять же для разбавки анкор-листа, как и упомянутые в начале безанкорные ссылки.

Чуть выше я приводил оценочные данные, говорящие о том, что лишь около пяти процентов ссылок, имеющихся в базе Сапе, могут помочь вам подрасти в выдаче. Если посмотреть на это с другой стороны, то мы увидим, что в «среднем по больнице» более девяносто процентов вложенных в ссылочное продвижение денежных средств расходуется крайне не рентабельно (фактически, в пустую). Обычно считается, что двадцать процентов от предпринятых действий приносят восемьдесят процентов результата, но тут дело обстоит похуже. При совсем неудачном подходе можно слить впустую вообще весь ссылочный бюджет.
Кроме этого, как уже упоминал, ссылки сами по себе потихоньку перешли из разряда основных факторов ранжирования во второстепенные. Поисковые системы стараются таким образом бороться с влиянием ссылочного спама на результаты выдачи, но совсем отказаться от учета ссылок пока не могут (хотя и пробуют это сделать периодически). По этой причине, кстати, добавился временной лаг (во всяком случае в Яндексе), в течении которого купленные ссылки никакого влияния на ранжирование оказывать не будут, даже если они сами по себе вполне рабочие (лаг может составлять от трех месяцев до полугода).
Чтобы SEO-шники не дремали, поисковики периодически меняют свои алгоритмы, в результате чего когда-то хорошо работающие схемы становятся не работоспособными. Причем отследить все это достаточно оперативно бывает не так-то уж и просто, в следствии чего, даже при грамотном подходе к внешней оптимизации, гарантий по стопроцентной рентабельности вложенных средств получить не возможно (всегда есть доля риска). А в неумелых руках этот инструмент вообще может быть бесполезным, что и вызывает массу кривотолков — мол, ссылки-то уже не работают.
Все выше сказанное относится именно к ссылкам, закупаемых на различных биржах, особенно если при их закупке не применяются какие-то продуманные фильтры, ибо большинство из стандартных схем (обкатанных годами) перестают работать или снижается их эффективность. Например, нельзя ориентироваться только на пузомерки сайта (Тиц и Пр).
Так называемые жирные (трастовые) ссылки зачастую вовсе не стоят потраченных на них денег, ибо параметров в оценке доноров должно быть намного больше, и среди них «трастовость» (тиц и пр) не является определяющим. Хотя, конечно же, получить рабочую (проходящую по всем остальным критериям отбора) ссылку с трастового сайта вашей же тематики было бы здорово, но их не так уж и много найдется.
Ну и как мы уже обсуждали чуть выше — лучшим вариантом будет приобретение ссылок, по которым будут переходить живые люди. Это придает им немалый налет естественности и повышает отдачу, но их еще надо поискать.
Где сейчас можно получать внешние ссылки, а где нельзя?
В связи со всем вышесказанным нужно будет очень серьезно подходить к процессу продвижения за счет получения (бесплатного или платного) внешних ссылок на свой сайт. О том, что и как желательно было делать, мы с вами еще поговорим в продолжении этой серии статей, но хочу сразу остановиться на том, что делать для набора ссылочной массы не надо:

- Не такое уж важное замечание, но... В идеале, с одного сайта вам достаточно получить одну ссылку (для получения максимума результата при минимуме вложенных средств). Но хороших доноров в любой тематике довольно-таки мало, поэтому получение нескольких ссылок с одного сайта (например, на разные страницы вашего ресурса) можно считать делом обычным. Однако, не стоит покупать с одного сайта сотни, и уж тем более тысячи беклинков, ибо это лишено смысла.
- Не стоит закупать ссылки в ссылочных биржах типа Сапе без использования фильтров. Почему? Да потому, что в этом случае процент напрасно потраченных денег у вас может приблизиться к сотне (читайте об этом выше).
- Если сами с фильтрами боитесь не справиться, то переложите эту задачу на плечи ссылочных агрегаторов (Визарда, Сеопульта, Мегаиндекса, Руки, Вебэффектора, Сеохамера или кого-то еще). Они, правда, возьмут с вас за это процент от стоимости закупленных ссылок, но при отборе будут применять свои наработанные фильтры и будут следить за донорами в дальнейшем, чтобы снимать неэффективные ссылки. Другое дело, что не стоит создавать кампании в агрегаторах без ограничения бюджета, ибо это чревато чрезмерным расходом средств.
- Забудьте про услуги прогона по тысячам ГС каталогов, которые до сих пор активно предлагаются на рынке. Этот поезд уже лет десять, как ушел. Не путайте ГС с трастовыми и качественными тематическими каталогами, которые до сих прекрасно работают (читайте про регистрацию в Яндекс Каталоге и Дмозе). Но вряд ли вы найдете таких больше десятка, и уж точно не сотни и тысячи.
- Не производите одновременной закупки огромного числа ссылок на молодой сайт, ибо нужно имитировать естественный рост ссылочной массы (хотя бы по нескольку штук в неделю).
- Собственно, даже для уже возрастного сайта не стоит закупаться тысячами ссылок одновременно (особенно в автоматическом режиме), ибо можно попасть под фильтр «ссылочный взрыв», что приведет к их неучету поисковой системой. Опять же, стараемся имитировать естественность процесса.
- Коммерческому сайту не стоит участвовать в различных системах по обмену ссылками. Да и ручной обмен лучше ограничить, и вообще стараться поменьше размещать внешних ссылок на другие ресурсы.
Ну и в двух словах опишем источники получения внешних ссылок применительно к коммерческому сайту:
- Необходимый пакет для бизнес-сайта заключается в попытке попадания в Яндекс Каталог, Дмоз, качественные тематические каталоги, добавление в Яндекс Справочник, чтобы показываться в поиске по Яндекс Картам, а также в Гугл Картах. Создание аккаунтов в популярных социальных сетях (Вконтакте, Твиттер, Ютуб — это тоже обратные ссылки). Ну и чего-нибудь еще трастового и имиджевого. Например, в Википедию попытаться прорваться, но это уже сложнее.
- Работа с биржами арендных ссылок (Сапа, ТрастЛинк) напрямую, либо посредством агрегаторов (их перечислял чуть выше). Ссылки там оплачиваются помесячно и поэтому их можно снимать, если обнаружится с ними проблема (бан донора, выпадение из индекса и т.п.). Их преимущества кроются в огромном количестве имеющихся доноров и возможности автоматизации процесса закупки и снятия через агрегаторы. Минусы были описаны выше.
- Работа с вечными ссылками на биржах типа Гогетлинкс, Ротапост, Гетгудлинкс, либо на биржах, где имеется возможность размещать целые статьи с имеющимися там ссылками на ваш сайт (это Миралинкс или Вебартекс). С недавних под появился способ автоматизации закупки вечных ссылок с помощью Гогеттоп. Преимуществом такого вида линкбилдинга является более органичное вписывание вашей ссылки в текст страницы, где она размещается. Недостатки, впрочем, практически те же, что и у Сапы — много доноров, размещение на которых можно считать напрасной тратой денег. Опять же, нужно тщательно фильтровать площадки.
- Свободный поиск доноров без использования каких-либо бирж. Намного сложнее и трудозатратнее, но зато вы с большой вероятностью получите реально работающую ссылку, если сайт-донор будет тематичным вашему и не будет участвовать в упомянутых выше ссылочных биржах, а ссылка будет расположена в месте, где по ней будут кликать. Кроме этого было бы замечательно, если этот донор не был бы ГС, а напротив, был бы добавлен в Яндекс Каталог и Дмоз. Ну и уж совсем идеализируя можно указать, чтобы кроме вашей ссылки со страницы-донора других бы линков проставлено не было.
100 советов по работе с SEO-ссылками и способам их получения
Сегодня мы все это детализируем и поговорим про требования к ссылкам, про уже изжившие себя и даже ставшие вредными способы их получения, а еще про те варианты получения бэклинков, которые нужно использовать в обязательном порядке. Поговорим и про Сапу (стратегии, фильтрацию доноров, построение анкор-листа), ну и вечные ссылки, и бэки с сайтов не участвующих в биржах тоже обязательно обсудим. Надеюсь, что будет интересно.

Требования к ссылками и неприемлемые методы работы с ними
Работа с ссылками, как любая другая работа по оптимизации должна проводиться в определенной последовательности (по технологии). Можно выделить следующие шаги отбора. Всех потенциальных доноров (сайты, с которых вы планируете получить обратную ссылку на свой ресурс — см. статью «Как начать понимать то, о чем говорят SEO-шники») следует досконально проверить на соответствие следующим требованиям:
- Та страница донора, с которой будет проставлена обратная ссылка, должна быть тематична вашему ресурсу (или близка ему по тематике). Даже соответствие донора всем описанным ниже критериям не может перевесить тот факт, что бэклинк не будет соответствовать вашей тематике. Это один из самых важных сейчас критериев отбора.
- На этой странице ваш бэклинк должен быть расположен в в основной части контента, чтобы существовала вероятность клика по нему людей, эту страницу просматривающих. Не соглашайтесь на варианты размещения в подвале. Как я уже говорил в первой статье, кликабельность ссылки может существенно повысить ее эффективность.
- Визуально проверяете сайт-донор на принадлежность к ГС (это сайты, которые создаются исключительно для обмана поисковых машин и заработка на привлеченном поисковом трафике). При визуальном их просмотре становится ясно, что людям на них делать нечего.
- Кандидат не должен участвовать в ссылочных биржах типа Сапы, ибо это повышает вероятность того, что он будет сильно заспамлен исходящими с него ссылками.
- Желательно, чтобы донор был добавлен либо в Дмоз, либо в Яндекс.Каталог (либо в оба каталога), ибо там имеет место быть предварительная модерация, а значит вы в какой-то мере уже будете застрахованы от ошибки.
- Желательно, чтобы ваша ссылка была единственной или одной из нескольких исходящих со страницы-донора (но не одной из сотен). Это способствует передаче большего статического веса (читайте об этом в первой статье).
Что может нанести вред вашему ссылочному профилю?
Избегайте «простых и быстрых» способов попадания в Топ, которые выражаются в таких вот неприемлемых способах работы со ссылками:
- Не пользуйтесь услугами прогона по тысячам ГС каталогов, которые до сих пор активно предлагаются на рынке (особенно пагубно это может отразиться на молодых сайтах). Однако, не путайте ГС с трастовыми и качественными тематическими каталогами, которые до сих прекрасно работают (Дмоз, Яндекс каталог и ряд других тематических).
- Если все-таки решите закупаться в Сапе, то обязательно используйте фильтры (с умом). В случае закупки без фильтров процент напрасно потраченных денег у вас может приблизиться к абсолюту.
- Если сами с фильтрами боитесь не справиться, то переложите эту задачу на плечи ссылочных агрегаторов (Визарда, Сеопульта, Мегаиндекса, Руки, Вебэффектора, Сеохамера или кого-то еще). Они, правда, возьмут с вас за это процент от стоимости закупленных ссылок, но при отборе будут применять свои наработанные фильтры и будут следить за донорами в дальнейшем, чтобы снимать неэффективные ссылки. Другое дело, что не стоит создавать кампании в агрегаторах без ограничения бюджета, ибо это чревато чрезмерным расходом средств.
- Не производите одновременной закупки огромного числа ссылок на молодой сайт (возраст домена которого меньше года), ибо нужно имитировать естественный рост ссылочной массы (хотя бы по нескольку штук в неделю).
- Собственно, даже для уже возрастного сайта не стоит закупаться тысячами ссылок одновременно (особенно в автоматическом режиме), ибо можно попасть под фильтр «ссылочный взрыв», что приведет к их неучету поисковой системой. Опять же, стараемся имитировать естественность процесса.
- Коммерческому сайту не стоит участвовать в различных системах по обмену ссылками. Да и ручной обмен лучше ограничить, и вообще стараться поменьше размещать внешних ссылок на другие ресурсы.
- Не стоит покупать с одного сайта сотни, и уж тем более тысячи беклинков, ибо это лишено смысла. Достаточно будет и одного бэклинка с одного донора, но если в вашей тематике достойных кандидатов на размещение не много, то можно и несколько бэков проставить, но с разных страниц донора на разные страницы вашего сайта. Правда, для крупных сайтов (больших интернет-магазинов или порталов) этим правилом пренебрегают, закупаясь большим количеством ссылок с одного ресурса для ускорения индексации, ну и для роста позиций.
Стратегия оптимизации и обязательный пакет ссылок
- Как мы уже неоднократно говорили, ссылки сами по себе ничего не решают, поэтому нужно четко придерживаться стратегии оптимизации:
- Во-первых, нужно провести полную внутреннюю оптимизацию сайта (технический аудит — «Зеркала, дубли страниц, урл адреса» и «Http ответы сервера, редиректы», а так же сбор полного семантического ядра из тысяч и десятков тысяч запросов — одна страница сайта решает одну проблему, продумывание навигации и перелинковки).
- Во-вторых, под собранное семантическое ядро пишем контент (для всех запросов из ядра) и распределяем его по страницам сайта. При этом не забывайте применять методы форматирования текста, и вообще старайтесь придерживаться правил написания контента озвученных в статье «Seo оптимизация текстов для коммерческого сайта»
- Прежде, чем приступать к закупке ссылок, стоит подождать несколько месяцев, пока весь новый контент на вашем сайте проиндексируется. После это снимите позиции по всем запросам из вашего семантического ядра (например, с помощью Rank Tracker) и посмотрите, какие из них уже попали в Топ просто за счет хорошей внутренней оптимизации (в основном это будет низко- и сверхнизкочастотные запросы, ну и часть среднечастотных). При должном подходе таких запросов может быть довольно много, ибо не ссылкам едиными...
- Следует также учесть то, что для старого и молодого сайта будут допустимы разные скорости закупки ссылок. Наращивать ссылочную массу у молодого ресурса (домен, которого зарегистрирован не более года назад) нужно будет плавно и очень осторожно.
- Определяете для себя, будете ли вы использовать агрегаторы (Визард, Сеопульт, Мегаиндекс, Руки, Вебэффектор, Сеохамер), либо будете напрямую работать с Сапой или биржами вечных ссылок и статей (WebArtex, ГоГетЛинкс, ГетГудЛинкс, РотаПост). Везде есть свои плюсы и свои минусы:
- Плюсы самостоятельной закупки ссылок заключаются в том, что вы экономите деньги на отчисления агрегаторам, получаете возможность закупать разные типы ссылок (с повременной оплатой, вечные) и при должном навыке может отфильтровать (забраковать) гораздо больше доноров, чем это сделает агрегатор, что, собственно, позволит еще больше сэкономить.
- Минусы самостоятельной работы с ссылками — нужно иметь за плечами немалый опыт и навыки (нужны наработанные фильтры по отбору ссылок для всех случаев жизни), чтобы действительно экономить, а не бросать деньги на ветер. Кроме этого, процесс этот крайне трудоемкий и отнимет у вас уйму времени (те же самые анкор-листы вам придется составлять самостоятельно).
- Плюсы работы с агрегаторам — можно продвигать одновременно сотни сайтов и не надорвать пупок (нет ограничений на человеко-часы). Почти всю нагрузку по работе с ссылками берет на себя агрегатор и вы можете вообще об этом не думать — анкор-листы попытаются за вас составить (т.е. собрать семядро, правда, не всегда вменяемое) и о фильтрах по отсеву доноров вам тоже беспокоиться не придется.
- Минусы работы с агрегаторами — фактически это посредник между вами и биржами, что влечет за собой дополнительные траты (около 20% они накидывают за свои труды). Кроме этого, не по всем тематикам найдутся ссылки в агрегаторах, да и высока вероятность того, что грамотные конкуренты (умеющие работать с ссылками самостоятельно) смогут вас обогнать. В общем, агрегатор это далеко не панацея, а скорее серьезный компромисс.
- Есть еще и обязательный пакет ссылок, получить который должен стараться любой коммерческий сайт:
- После того, как ваш сайт примет свой окончательный вид (будет полностью проведена внутренняя оптимизация), следует подавать заявки на добавление его в Яндекс.Каталог (на платных условиях, ибо бесплатно попасть туда коммерческому сайту не реально) и в Дмоз (выбрав предварительно подходящую категорию). Подробности и нюансы смотрите тут.
- В любой тематике также наверняка найдется ряд трастовых каталогов, куда обязательно нужно попытаться попасть. Их список будет зависеть от той ниши, в которой вы работаете. То же самое можно сказать и про трастовые региональные каталоги.
- Кроме этого стоит попробовать получить ссылки с крупных и авторитетных информационных ресурсов. Это может быть Википедия (читайте про то что такое Wikipedia для вебмастера), популярные социальные сети (читайте про создание бизнес-страницы и канала на Ютюбе), сервис вопросов и ответов от Майл.ру, трастовые сайты вакансий, доски объявлений, желтые страницы или что-то еще подобное.
- Также следует добавить свой сайт в сервисы поисковых систем. Например, в Яндекс.Справочник, чтобы отображаться на Яндекс.Картах или в Google Maps.
Несколько советов по работе с ссылкам в Sape
Что бы мы там не говорили, но большинство SEO-оптимизаторов так или иначе работают через Sape, поэтому стоит потратить время на пояснения некоторых нюансов работы с этой биржей при работе с арендными ссылками.
- Предварительно составляется анкор-лист, размер и содержание которого зависят от возраста вашего сайта и сложности продвигаемых запросов
- При покупке обычных ссылок вы традиционно:
- Создаете проект на Сапе на вкладке «Оптимизатору»;
- Добавляете в него продвигаемые Урл адреса и соответствующие им анкоры;
- Настраиваете предфильтры (на вкладке «Быстрый набор»)
- Задаете настройку закупки ссылок в полуавтоматическом режиме (но ни в коем случае не в автоматическом)
- Настраиваете плагин Винка и кучу других разных фильтров (например, Rds бар или CS Sape Master), чтобы по максимуму отсеять ГС.
- Далее вы глазами фильтруете оставшиеся «вкусняшки». Самыми вкусными среди них будут те сайты, что добавлены в Сапу не позднее месяца назад, ибо они еще не сильно заспамлены и от них можно ожидать хорошей отдачи.
- Обратите внимание, что в Сапе еще имеется возможность осуществления релевантного подбора площадок для размещения, когда биржа будет искать среди имеющихся в ней доноров страницы, релевантные введенным вами запросам (т.е. те, которые находятся по этим самым запросам в Топ 50).
Выданные биржей в результате страницы будут более-менее тематическими для вашего сайта, что, как мы уже разобрали чуть выше, является сейчас очень важной метрикой для учета ссылки поисковыми системами. Правда по некоторым из подобранных доноров вы не увидите Урла (вместо него будет надпись «URL закрыт») и не сможете своими глазами оценить ресурс, что не есть хорошо. Отбирайте не очень дорогих (тысячерублевых в топку) доноров, чтобы соответствовать принципу «дешево и сердито».
- Также при поиске площадок для размещения ссылок через Сапу вам будет доступна вкладка «Контекстные ссылки». Подразумевается, что ссылки будут проставлены непосредственно из контента (основного содержимого страницы), что есть хорошо (говорили об этом чуть выше по тексту). Для выбора подходящих доноров вам предлагается целый набор фильтров, но обязательным будет заполнение поля с ключевыми словами. Таким образом можно будет получить как раз и нужные нам тематические или околотематические ссылки.
- Если же планируете покупку обычных ссылок на Сапе, то не примените со всем должным вниманием отнестись к заполнению предфильтра на вкладке «Быстрый подбор» (доменные зоны, уровне вложенности, тематике площадок, региональность и т.п.). Собственно, об этом я уже упоминал во втором пункте.
Как отфильтровать плохих доноров(ГС)?
Основная проблема бирж ссылок, как я уже не раз отмечал, заключается в том, что среди находящихся в их базе сайтов преобладают именно ГС. В результате этого получается, что более девяноста процента закупаемых средним коммерческим сайтом ссылок вообще не оказывают никакого воздействия на ранжирование (не дают нужного эффекта). Чтобы не уподобляться им, следует использовать целый ряд фильтров, по которым можно в той или иной степени отсеять не эффективных доноров:
- Чем меньше внешних ссылок будет проставлено со страницы донора, тем будет лучше. В любом случае они должны измеряться единицами, а не десятками (допустим, не более двух).
- То же самое можно сказать и про внутренние ссылки, которые ведут не на внешние сайты, а на другие страницы донора. Правда, тут счет обычно идет на десятки, но я бы не стал советовать покупать беки со страниц с более, чем со ста внутренними линками.
- Желательно, чтобы в контенте страницы-донора не встречалось нецензурных и относящихся к табу-тематикам слов (фарма, т.е. лекарства, оружие, азартные игры и т.п., если вы, конечно же, не продвигаете сайт именно в этих тематиках). А еще другие слова и фразы, характеризующие нежелательных вам доноров (например, рефераты, результаты поиска, скачать бесплатно, доска объявлений и т.п.). Их еще называют «стоп-слова».
- То же самое касается и урл-адресов страниц-доноров. Таким образом можно отсеять очень приличное число недостойных размещения вашего бэклинка страниц. Например, в стоп-лист урлов добавляют различные варианты типичных окончаний для админок сайтов, служебные папки движков, страницы авторизации, пагинации (разбиения на страницы) и поиска, версии страниц для печати, урлы с параметрами (действия, сессии), страницы тегов, временных архивов, рсс лент и т.п. Например, так:
Списки стоп-слов в Урлах и контенте обычно нарабатываются оптимизаторами годами, либо покупаются или каким-то еще образом получаются. - Желательно, чтобы на доноре было достаточное количество контента. Абсолютных цифр, наверное, не существует, но думаю, что полторы тысячи — это тот самый минимальный порог.
- Как я уже не раз упоминал выше, тематичость донора вашему ресурсу будет являться плюсом, но и все остальные факторы должны соответствовать. Очевидно, что при закупке желательно следовать правилу:
- Среди всех прошедших сквозь сито фильтров сайтов-доноров в первую очередь нужно использовать все тематические. В некоторых тематиках заканчиваются они, к сожалению, очень быстро
- Затем уже можно использовать околотематеских доноров
- Ну, а затем уже все оставшиеся, которые удовлетворяют вашему набору фильтров, но с тематикой вашего ресурса не пересекаются
- При продвижении региональных запросов, приоритет следует отдавать и донорам из того же региона.
- Сайт должен быть «живым», т.е. на него должны заходить реальные посетители. Проверить это можно, поискав счетчики посещений (читайте про то, как узнать посещаемость чужого сайта), либо обратить внимание на значение Алексы Ранк, которое косвенно отражает поток трафика на данных ресурс.
- Значение Тиц по-прежнему является качеством показателя донора, но не стоит на него обращать внимания больше, чем не другие факторы. Тиц больше трех сотен можно считать хорошим показателем.
- Также косвенно за качественный донор говорит его наличие в Дмозе или ЯК (Яндекс каталоге), ибо в этих каталогах имеется обязательная модерация. Но это опять же не основной фактор, а один из многих.
- Наличие в индексе Яндекса и Гугла определенного количества страниц. Лучше если их будет больше нескольких сотен.
- Еще важно обращать внимание на тех доноров, у которых слишком большая разница между числом страниц, проиндексированных этими поисковиками
- Уровень вложенности относительно главной страницы, наверное, не стоит задавать выше трех.
- Уровень домена, с которого проставляется бэклинк, тоже может играть свою роль. Обычно выбирают домены второго уровня (типа ktonanovenkogo.ru) и не выше (типа blog.ktonanovenkogo.ru).
- Возраст домена тоже может снижать риски нарваться на ГС. В этом смысле можно ориентироваться на домены старше десяти месяцев.
- Цена ссылки тоже является важным фактором отбора, она не должна быть сильно высокой (не забывайте, что это цена за месяц размещения). Например, неплохим будет фильтр в 11 рублев, это не сильно дороже 10, но откроет для вас пласт доноров, которые по традиции отсеиваются стандартным фильтром в десяточку.

Если вы всех ваших потенциальных доноров будете отсеивать по данным фильтрам, то сумеете избавиться от подавляющего большинства ГС (процентов на девяносто, а то и больше). В итоге от пришедших вам тысяч заявок останутся десятки или даже единицы доноров, прошедших сквозь сито ваших фильтров.
Визуальные отбор и фильтры для съема ссылок
В принципе, уже можно покупать с них ссылки, но лучше все же просмотреть их все визуально (своими глазами), чтобы убедиться, что это не ГС и что-то еще не приемлемое. Правда при продвижении множества сайтов одновременно, вы можете просто не успевать просматривать всех отобранных доноров, но нужно стремиться это делать.
При визуальной оценке сайтов-доноров стоит обращать внимание на следующие вещи:
- Должна быть контактная информация. Проверять ее на достоверность нет смысла, но она должна быть на сайте для людей.
- Не должно быть засилье рекламы
- Текст соответствующим образом должен быть оформлен и отформатирован, а не представлять из себя неудобоваримый «кирпич» с набором слов.
- Кратко можно пробежаться и по содержанию текста (хотя бы первых абзацев), чтобы оценить их читабельность.
- Имеются картинки окромя текста
- Дизайн отличается от шаблонного (добавлена оригинальная шапка и т.п.), нет каких-то нахлестов и прочей кривизны верстки, которая очень часто бросается в глаза на ГС
- Должны иметься признаки «живости» данного ресурса:
- Проставляются даты публикаций
- Имеются комментарии
- Добавляются лайки, если соответствующие кнопки на страницах наличествуют
- Имеется счетчик количества просмотров страницы
Но кроме этого нужны еще и фильтры для съема ссылок, которые по тем или иным причинам стали неэффективными. Такими причинами могут быть:
- Если ссылка по истечении какого-то промежутка времени (допустим, месяц) не индексируется, то имеет смысл ее снять.
- Если донор с течением времени перестает удовлетворять тем фильтрам, которые использовались вами на этапе отбора площадок (например, выросло число внешних ссылок, удален контент или еще что-то изменилось). Такую проверку лучше делать ежедневно, чтобы вовремя пресекать такие вот попытки вас «надуть».
Построение анкор-листа — вхождения, пропорции и скорость
В первой статье «Нужны ли сейчас внешние ссылки для SEO-продвижения сайта» мы говорили про то, какие бэклинки покупают и зачем. Так вот, все эти типы должны использоваться при построении вашего анкор-листа:
- Прямые ссылки — достаточно просто взять поисковый запрос, по которому вы планируете продвигать данную страницу своего сайта, и окружить его открывающим и закрывающим тегами гиперссылки
- Ссылки с разбавкой — в этом случае в качестве анкора используется текст запроса, плюс к нему добавляется какое-то разбавочное слово. Слова для разбавки зачастую берутся просто из семантического ядра, либо используется что-то универсальное, подходящее в большинстве случаев (дешево, недорого, город и т.п.).
- Безанкорные ссылки — текст в таких ссылках присутствует, но осуществлять по нему ранжирование поисковым системам крайне затруднительно, ибо этот текст представляет из себя какие-нибудь распространенные слова типа наречий «тут», «здесь», «там» или других общих слов (например, «этот сайт»).
- С околоссылочным текстом — они довольно часто используются при закупке в Сапе и ей подобных биржах, либо в ссылочных агрегаторах (таких, как, например, Мегаиндекс, Сеопульт и им подобных). По сути, они из себя представляют законченное предложение, похожее на заголовок рекламного объявления, но тегами ссылки окружается только нужный ключевой запрос (не обязательно в прямом вхождении).
Чтобы получить ссылочный профиль максимально близкий к естественному, нужно использовать все эти варианты, плюс еще и естественные ссылки, которые появляются без вашего активного участия. Как узнать пропорцию, которая приведет к естетственности профиля? Очевидно, что спрашивать об этом лучше всего сами поисковые системы.
Просто посмотрите на ваших успешных конкурентов на предмет их анкор-листов и старайтесь соблюдаться те же самые пропорции, ибо их уже высоко оценили поисковики (вводите интересующий вас запрос и внимательно изучаете сайты из Топ 10). Для этого можно использовать сервисы типа Ахрефс или Open Site Explorer, либо программы подобные описанному мною недавно SEO SpyGlass.
Пропорции в анкор-листе по какому-либо поисковому запросу зависят еще и от его частотности (сколько раз в месяц его запрашивают пользователи поисковых систем). Узнать частотность можно из Вордстата, различают низко, средне и высокочастотные запросы.
- Низкочастотка — для попадания в Топ зачастую ссылок и вообще не требуется, ну, а если они и закупаются, то по одной-две на каждый запрос, и это, как правило, будут бэклинки с прямым вхождением (они дают наибольший эффект, а возможность их склейки исключается, ибо они закупаются практически в единичных экземплярах). Ну, максимум одним словом можно разбавить запрос.
- Среднечестотка — прямых вхождений процентов пятьдесят-шестьдесят, плюс десять-двадцать процентов — фразы запроса в другой словоформе, а еще процентов десять разбавленных одним словом и процентов пять разбавленных двумя и более словам. Кстати, тут про безанкорные ссылки забывать не стоит (процентов пятнадцать на них отвести) и даже синонимы использовать (чуток, процентов на пять, не более).
- Высокочастотка — прямое вхождение не более половины, плюс пять-десять процентов словоформ; столько же разбавлений двумя и более словами, а разбавлений одним словом — около десяти-пятнадцати процентов. Безанкорных ссылок и синонимов тут понадобится чуток больше (до двадцати процентов первых и до десяти вторых).
Также для разных типов и возрастов сайтов различается и скорость закупки ссылок. Точную скорость вы вряд ли каким-то образом сможете узнать, но примерно можно ориентировать на такие вот значения:
- Для молодых сайтов (до года) — первый месяц идет закупка в день по ссылке, второй месяц — по полторы (в среднем), третий — по две, четвертый — по три, ну и далее еще большими темпами, но не наглея.
- Сайты от года до трех — в первый месяц уже можно по сорок пять штук в месяц, во второй — по семьдесят, в третий — по сто, в пятый и далее — по сто пятьдесят и более бэклинков в месяц.
- Свыше трех лет — все то же самое, что и в предыдущем случае, но процентов на десять можно увеличить интенсивность закупки в каждый из месяцев после того, как вы решили заняться закупкой ссылок.
- Возрастной сайт без ссылочной массы в скорости наращивания ссылок ничем не должен опережать сайт молодой.
Работа с вечными ссылками и донорами вне бирж
Кроме закупки арендных ссылок (с помесячной оплатой) сейчас SEO-оптимизаторы уделяют довольно-таки большое значение работе с так называемыми вечными ссылками. За них платят только один раз, и по идее они должны оставаться висеть на сайте-доноре вечно, что, конечно же, не всегда получается (часть всегда отваливается, но это допустимые риски, к тому же во многих биржах есть возможность страховки от снятия бэклинков).
Кстати, стоит сразу упомянуть и основных игроков рынка вечных ссылок:
- Раз мы тут так много говорили про Сапу, то стоит упомянуть, что у них есть сервис для работы и с вечными ссылками — Pr.Sape. Примерно год назад я написал обзорную статью по работе с этим инструментом (можете ознакомиться с ней по приведенной ссылке).
- ГоГетЛинкс — одна из самых популярных бирж с большим числом доноров. Подробности работы с ней я описывал в статье «GoGetLinks — вечные ссылки для продвижения сайта»
- ГоГетТоп — этот сервис позволяет автоматизировать закупку ссылок с Миралинкска и Гогетлинкса, что позволяет существенно упростить и ускорить процесс продвижения для людей занятых, но состоятельных. Если этот сервис вам потенциально интересен, то читайте обзорную статью «GoGetTop — как продвигать сайт вечными ссылками на полном автомате»
- ГетГудЛинкс — ответвление от ГГЛ, ориентированное на покупку ссылок со страницы, которые имеют нужное вам значение ПР (пейдж ранка). Такие ссылки, по идее, должны передавать довольно-таки большой статический вес (читайте подробности в первой статье цикла — ссылка на нее приведена в начале этой публикации).
- РотаПост — более демократичная биржа вечных ссылок, куда принимают практически все блоги на любых движках и бесплатных блог-платформах, а также твиттер-аккаунты. Там можно при большом усердии найти дешевых и довольно-таки приличных доноров, но и ГС там предостаточно. Читайте мой обзор этого сервиса под названием «Ротапост — продажа и покупка ссылок с блогов»
- WebArtex — относительно новая биржа статей, похожая, по своей сути, на Миралинкс, но имеющая существенные отличия в логике работы и функционале. В свое время я и по ней обзорную статью успел написать — «WebArtex — новая возможность продвижения сайтов за счет размещения статей»
Фильтры по отбору доноров в случае вечных ссылок будут похожи на используемые в Сапе. Прежде чем их перечислить, хочу сказать, что в ссылочном профиле должны быть разные ссылки, включая бэки с социальных сетей и блогов. Пусть они и не оказывают прямого и существенного влияния на ранжирование, но они входят в упомянутый выше «обязательный пакет», что помогает вашему сайту лучше выглядеть в глазах поисковиков.
Теперича о фильтрах при отборе доноров вечных ссылок:
- Донор не должен участвовать в биржах типа упомянутой выше Сапы (в противном случае будет велика вероятность его сильной заспамленности)
- В упомянутых чуть выше биржах вечных ссылок и статей имеются довольно развернутые системы фильтров (читайте про их использование в приведенных обзорах), которые обязательно нужно использовать для сужения круга претендентов. Критерии отбора используются примерно такие же, как и в Сапе (см. выше). Есть несколько специализированных решений по поиску оптимальных доноров, например, описанный мною онлайн-сервис от SEObuilding.
- Оставшиеся сайты после «грубых» фильтров обязательно следует оценивать вручную посредством визуального осмотра. В биржах вечных ссылок количество доноров не такое большое как в Сапе, поэтому сделать это будет не трудно. Опять же, нужно обращать внимание в первую очередь на «живость» сайта-донора и предназначенность его для людей (не ГС).
- Указывайте в комментариях к заданиям вебмастерам требование (просьбу) о размещении вашей ссылки в кликабельной области (ближе к началу текста статьи, например) и запрещайте ее размещать где-нибудь в самом низу. Причины были довольно подробно описаны выше.
- Статья, в которой будет размещен ваш беклинк, должна быть тематической. Опять же, указывайте это обстоятельство в комментарии к заданию вебмастерам, чтобы потом не вступать с ними в полемику.
- Считается, что вечные ссылки хороши прежде всего тем, что они добавляются в индекс поисковых систем вместе с текстом страницы, что является наиболее естественным вариантом. В случае бирж статей ( WebArtex) это условие будет выполняться всегда, а вот в биржах типа ГГЛ нужно обговаривать это либо в комментариях к заданию, либо выбирать покупку только такого вида ссылок.
- Также можно попробовать сначала закупаться ссылками с сайтов, которые были добавлены в биржу за последний месяц (задается в фильтрах), ибо это повышает вероятность того, что такой ресурс еще не будет заспамлен бэклинками.
Биржи ссылок — это очень удобно, и в то же время большинство добавленных в них доноров либо ГС, либо уже чрезмерно заспамлены. Однако, использовать их, скорее всего, все равно придется, и при должном подходе можно получить довольно-таки неплохой результат в увеличении целевого трафика на ваш коммерческий сайт.
Правда, не по всем тематикам вы найдете доноров в биржах, поэтому будет не лишним попытаться получить бэклинки с ресурсов, которые ни в каких биржах не состоят и не состояли. Найти их и договорится с владельцами бывает довольно-таки утомительно. Если есть возможность кому-то это перепоручить (работа не требует квалификации), то можно получить тематические ссылки с незаспамленных ресурсов, которые наверняка учтутся в вашу пользу поисковыми системами.
Варианты получения бэклинков вне бирж
- Можно попробовать поискать доноров, вводя в Яндекс поисковый запрос, по которому вы пытаетесь продвинуться. Найти владельца сайта, который согласится за приемлемые деньги разместить ваш бэклин, не просто (хорошо, если один из ста согласится), но можно. Покупая одну ссылку с донора, обычно договариваются о единоразовой плате за размещение навсегда.
- В принципе, можно даже и обменяться небольшим количеством бэклинков с сайтами вашей же тематики, не участвующими в каких-либо биржах, но тут надо знать меру, ибо можно и не добиться желаемого результата. Обычно, варианты для обмена найти бывает проще, чем для покупки. Однако, ни в коем случае не создавайте страницу для размещения «линков по обмену», ибо за это могут однозначно поисковики наказать. Думаю, что и «сквозняками» меняться не стоит (из блока, который выводится на всех страницах). Лучше проставлять ссылку из текста какой-то тематичной страницы и требовать того же самого от партнера по обмену.
- Если у вас огромный портал или интернет-магазин на десятки тысяч страниц, то можно будет попытаться найти донора, с которого вы купите тысячу и более ссылок за раз (с разных страниц донора на разные страницы вашего сайта). В этом случае можно договариваться о ежемесячной оплате (своеобразная гарантия их неудаления), ибо даже при цене в рубль или полрубля общая сумма получаемая вебмастером будет ощутимой и он вполне может заинтересоваться.
- Некоторые оптимизаторы (в основном крупные агенства) имеют собственную сетку сайтов, которую используют для продвижения клиентов. Как правило, они заспамлены ниже, чем доноры из бирж, поэтому, если предоставится возможность в такую сетку (особливо тематичную вашему ресурсу) добавить свои бэклинки, то это будет неплохим дополнением к ссылочному профилю.
- В первой статье мы говорили, что кликабельные ссылки будут тем или иным образом обязательно учитываться поисковыми системами. Поэтому имеет смысл поискать такие варианты размещения среди тематичных вашему сайтов. То, что ссылка будет кликабельна, можно косвенно судить по высокой посещаемости потенциального донора, ну, и она должна размещаться в видимой области статьи. Стоить, правда, такой бэклинк будет весьма и весьма внушительно (тысячи или даже десятки тысяч рублей единоразово).
- Есть еще и не совсем белые способы получения бэклинков с довольно жирных (трастовых) сайтов, которые не подразумевают контактов с их владельцами. Используются обычно какие-то особенности движка, которые позволяют добавить на сайт ссылку (или даже целую статью с ссылками) без ведома его владельца. Это спам, но многие этим не брезгуют. Если интересно, то у меня имеется несколько относительно новых баз таких сайтов (в начале этого года купленных) — обменяю их на ваши расшаривания страниц моего блога в раскрученных акаунтах соцсетей или на тематических сайтах (контакты смотрите выше).
- Всех потенциальных доноров нужно опять же тщательнейшим образом проверять по упомянутым выше показателям (не добавлен в биржи, тематичен, число исходящих и входящих ссылок и т.п.) и просматривать визуально (дизайн, посещаемость и т.п.). Тут цена ошибки, как правило, будет намного более высокой, чем в биржах (в прямом смысле — семь раз проверь, а один заплати).
Рейтинг сайтов для автоматического продвижения
Про то, как создать опрос на сайте с помощью инструментов Гугл Диска, практически в то же время я написал небольшой очерк.

Сегодня же хочу подвести итоги опроса и голосования. Если вам интересно, то присоединяйтесь, и узнаете, пользуются ли доверием агрегаторы у читателей моего блога, а если пользуются, то какие именно системы автоматического продвижения они предпочитают и по каким причинам. Опрос не был платным, хотя многие готовы за это платить деньги.
На данный момент в опросе приняло участие более полутора сотен человек. Собственно, результаты опроса вы можете посмотреть на этой странице. Я пробегусь быстренько по тем вопросам, что были заданы.
- Подавляющее большинство читателей знакомы с агрегаторами и часть из них данными системами пользовалась:
- Половина участвовавших в опросе продвигаются только вручную, но треть из них хотела бы все же попробовать агрегаторы:
- На следующие три вопроса читатели отвечали, видимо, в соответствии со своим представлением лучшего агрегатора. В явные лидеры вышли PromoPult и Wizard.Sape. Что примечательно, новичок (Wizard.Sape) все же немного опередил родоначальника движения систем автоматического продвижения:


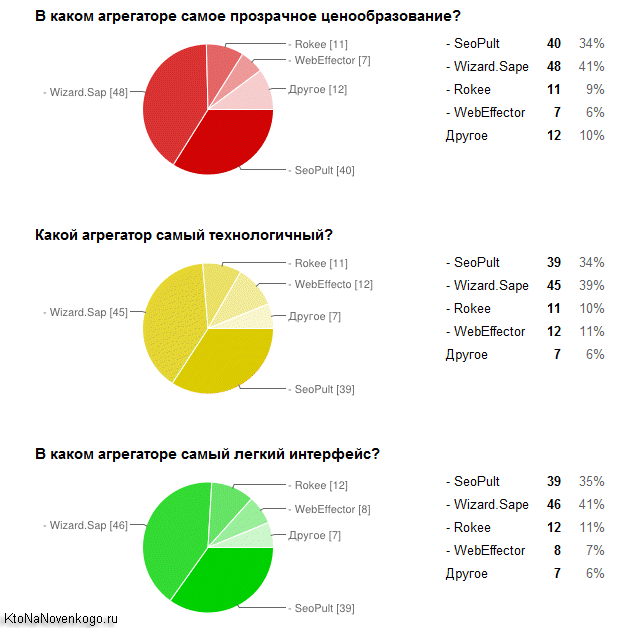
Если же посмотреть на результаты голосования, то тут мы видим схожую картину (за исключением того, что PromoPult проиграл сервису Rokee), правда число проголосовавших оказалось существенно меньше, чем тех, кто решил принять участие в опросе.
Выстроим агрегаторы по ранжиру
Ну и на основании результатов голосования и опроса можно, наверное, будет построить своеобразный Топ предпочтений (правда без награждения победителей ценными призами):
- Wizard.Sape — появился не так давно, однако, обладает одним неоспоримым преимуществом — он встроен в интерфейс самой большой биржи ссылок Сапе. Все остальные системы в основном покупают ссылки там же, но этот агрегатор является «своим» для этой биржи. Читайте про возможности Wizard.Sape подробнее.
- PromoPult — появился одним из самых первых на рынке. Предлагает стандартный набор возможностей.
- Rokee — имеет достаточно много возможностей ручных настроек, что может понравиться профессионалам рынка Сео продвижения.
- WebEffector — еще одни игрок на рынке автоматического продвижения. Имеет стандартный набор возможностей.
Способы оптимизации контента
Оптимизация TITLE — залог успешного продвижения
Внутренняя оптимизация сайта включает в себя работу с текстами, а так же внутренней структурой (перелинковка), таким образом, чтобы вес, передаваемый по внешним ссылкам, равномерно перетекал на все страницы проекта. Т.о. статический вес будет накачиваться и на тех страницах, которые не имеют внешнего ссылочного.
Сначала рассмотрим оптимизацию текста. Есть несколько несложных правил, которым нужно при этом следовать. В принципе, все эти правила по своему важны, и для достижения успеха желательно все их в той или иной степени выполнять.
Основное правило гласит, что частота использования ключевиков должна находиться в пределах 1-2 процентов от общего числа слов в тексте. При превышении этого процента вы уже не сможете подняться выше в выдаче, но зато сможете запросто попасть под фильтр за спамность.
Второе правило гласит, что часть ключевых слов иногда может быть заключена в определенные HTML теги. Самым важным и значимым для поисковиков является, конечно же, TITLE.
Важно не только то, что поисковая система по содержанию этого заголовка судит о контенте данной вебстраницы и о тех словах, к которым она относится. Но так же важно и то, что содержимое Тайтла отображается в поисковой выдаче и может влиять на решение пользователей – перейдут ли они на ваш сайт или нет.
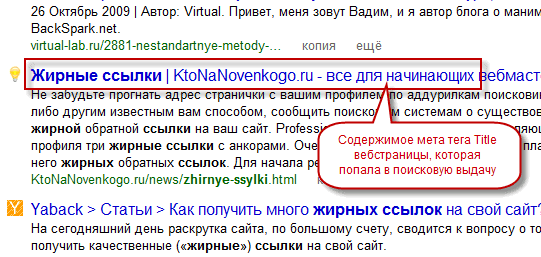
Там отображаются только определенное количество знаков из заголовка страницы TITLE (около 65 знаков). При этом остальные символы все равно учитываются при ранжировании. Вот пример из выдачи Яндекса, где моя статья стоит на первом месте, но при этом все ключевые слова запроса расположены в самом конце длинного заголовка:

Google не сдвигает TITLE в выдаче (показывает только первые 65 знаков из него), но все равно учитывает те ключи, которые были употреблены в не поместившейся части. Это я веду к тому, что длинные заголовки для статей имеют такое же право на жизнь, как и короткие. Тому примером может послужить мой блог, где они очень длинные.
Очень важно, чтобы для всех страниц вашего проекта тайтлы были бы уникальными. Ключевые слова, заключенные в них, будут иметь наибольший вес по сравнению со всеми другим способами их выделения в контенте. Поэтому к содержимому TITLE нужно относиться со всей серьезностью, если вы хотите удачно продвинуть статью.
Разные движки систем управления контентом (Joomla, WordPress и т.д.) по разному формируют содержимое тега TITLE. Но по умолчанию, как правило, в качестве него должен использоваться заголовок статьи, расположенный на этой странице.
В большинстве случаев у вас будет возможность заполнять содержимое Тайтла вручную при работе над статьей. Но все же проще будет настроить его автоматическое формирование в том виде, в котором вы захотите. Сделать это можно с помощью каких-либо настроек или расширении для используемого вами движка.
Считается правильным, когда сначала выводится название статьи, а уже затем название сайта. О том, как настроить правильное формирование TITLE в Joomla читайте тут и тут, а в WordPress за это дело у меня отвечает плагин All in One SEO Pack, описанный здесь.
Посмотреть содержимое заголовка страницы вы можете прямо в браузере в его самом верхнем поле:
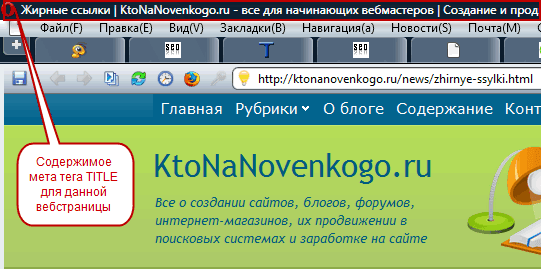
Так же увидеть его содержимое в самом верху исходного кода вебстраницы, который можно будет посмотреть в браузере, щелкнув правой кнопкой мыши по любому месту и выбрав из контекстного меню пункт «Исходный код» (Opera) или «Исходный код страницы» (FireFox):
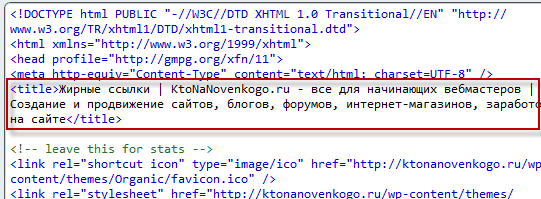
Еще раз обращаю ваше внимание на то, что Тайтл отображается в поисковой выдаче и количество посетителей, перешедших к вам, будет напрямую зависеть от притягательности ваших заголовков. Можно, при удачно составленном Тайтле, получить посетителей больше даже, чем вышестоящие в топе поисковой выдачи сайты. Про то, как сделать TITLE привлекательным, читайте тут.
Description и другие способы оптимизации контента
Есть еще один мета тег, который следует отдельно заполнять для каждой страницы — это Description, в котором задается описание страницы. Почему он так важен? Ведь все знают, что влияние на ранжирование документов Description и Keywords в последнее время вообще никакого не оказывают.
Тем не менее заполнять дескрипшн следует, и при этом нужно будет употреблять ключевые слова, по которым продвигается данная статья. Поисковые системы, обычно, учитывают в нем первые 160 символов.
Все дело в том, что его содержимое иногда может быть использовано поисковиками (особенно Google) в качестве так называемого сниппета, о котором читайте здесь. По сути, это текст, отображаемый в выдаче и характеризующий содержание статьи:
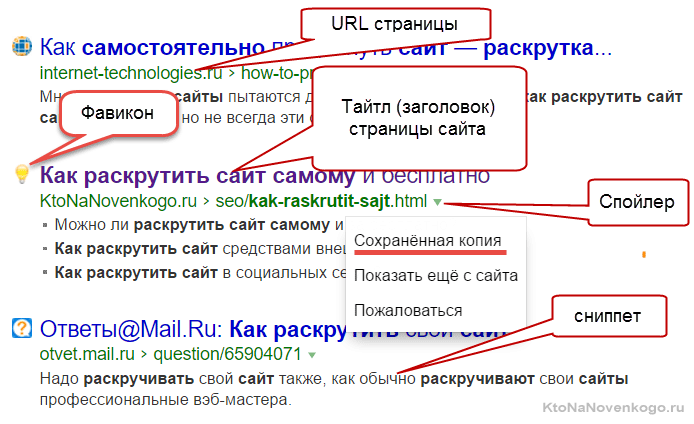
Конечно же, содержимое сниппета будет зависеть от того запроса, в выдаче которого он показывается. Но содержимое Description может выводиться в сниппете в некоторых случаях, когда поисковая систем сама еще не нашла в статье более лучшего фрагмента.
Поэтому не ленимся и заполняем содержимое этого метатега для каждой статьи вашего ресурса. В WordPress это можно сделать, если вы используете уже упомянутый выше плагин All in One SEO Pack (а его использовать я вам настоятельно рекомендую).
Если вы работаете с Joomla, то можете воспользоваться этим, где говорится про настройку мета-данных (DESCRIPTION, KEYWORDS, TITLE и ROBOTS).
Помните, что Дескрипшн (равно как и Тайтл) — это, фактически, бесплатная реклама вашего сайта в поисковой выдаче Яндекса или Google. Используйте эту возможность по максимуму.
Еще обратите внимание на то, что вы должны использовать в Description ключевые слова, т.к. они будут выделяться жирным шрифтом в выдаче. Это поможет еще больше привлечь внимание пользователей к вашему ресурсу.
Увидеть содержимое этого метатега можно, просмотрев исходный код в браузере:

H1 — H6 — структурирование текста и усиление ключевых слов
Теги заголовков H1 — H6 можете использовать при написании текста статьи. Вы вольны сами задавать для заголовков всех уровней в таблице каскадных стилей нужные размеры с помощью соответствующих CSS свойств Font, описанных здесь.
Но, по-прежнему, осталась неизменой несколько более высокая важность текста, заключенного в теги заголовков H1 — H6. Ключевые слова в них использовать нужно, но осторожно и без повторов, а так же без переспама. Главное соблюдать максимальную естественность.
Следует придерживаться правила, что один заголовок должен приходиться на текст не менее 1000 знаков и не чаще, иначе перестанут учитываться и вы лишитесь дополнительного бонуса при ранжировании.
Если текста на странице мало, то будет достаточно одного H1, а использование дополнительных заголовков H2-H6 будет излишним.
Многие советуют использовать тег H1 на вебстранице всего один раз, т.к. в этом случае он будет сто процентов работать. В моем блоге H1 вообще одинаков для всех страниц, а заголовки статей заключены уже в тег H2. В самом же тексте статей я использую уровни H3-H5.
H1 — H6, сами по себе, даже без учета усиления влияния заключенных в них ключевиков позволяют улучшить восприятие статьи посетителями, а так же тексты, имеющие развернутую структуру заголовков, больше нравятся поисковикам, в особенности Google.
STRONG и EM — используем осторожно увеличение значимости ключевиков
Кроме тегов заголовков можно, но очень осторожно, использовать для выделения ключей и словосочетаний такие теги как STRONG (выделение жирным) и EM (выделение курсивом). В этом случае ключи будут иметь больший вес в глазах поисковиков, чем аналогичные, никак не выделенные. Но из-за их частого использования спамерами нужно быть с этим делом поосторожнее.
Тегами STRONG и EM не следует злоупотреблять, иначе они перестанут работать. На 1000 знаков будет достаточно по одному STRONG или EM. Ни в коем случае не выделяйте чистые ключи дважды — это явный спам. Лучше в разбавленном виде или просто по смыслу, без учета ключей.
Если вам нужно будет выделить жирным или курсивом в тексте фразы, не являющиеся ключевыми (привлечь к этим слова внимание посетителей), то можете использовать альтернативные теги — B и I. Слова, заключенные в них, не будут иметь какого-то особого значения для поисковых систем.
Так же для привлечения посетителей с поиска по картинкам Яндекса и Google, о котором речь шла здесь, вам следует соответствующим образом добавлять описания для изображений. Я уже подробно писал в этой статье про оптимизацию картинок.
Т.к. бот, производящий индексацию, считывает информацию из HTML кода вебстраниц, то не лишним будет употребление ключевых слов во всех возможных тегах и атрибутах этих тегов, а не только в тексте страницы. Тот же атрибут ALT тега IMG или Title тега ссылки A будут прочитаны ботом и ключи в них будут учтены. Но с эти надо быть поосторожнее, ибо попасть под фильтр можно запросто, как это вышло у меня.
Хотя, например, вы можете с помощью атрибута Title тега ссылки «A» добавить ключи в ссылки, ведущие с картинок. Тогда содержимое этого атрибута будет учтено в качестве анкора. Но опять же, анкоры нужно использовать разнообразные, поэтому обязательно ознакомьтесь с этой статьей, где говорится про составление анкор-листов.
Так же важным фактором, влияющим на отношение Яндекса и Гугла к вам, является то, на какие ресурсы у вас проставлены гиперссылки. Если вы ссылаетесь на плохие в их понимании сайты, то на вас могут быть наложены санкции. Чтобы этого избежать, следует использовать атрибут REL="NOFOLLOW" для закрытия от индексации внешних ссылок со страниц своего ресурса.
Особенно это касается комментариев, где любой может оставить ссылку на какой-нибудь спамный или содержащий непотребщину ресурс. Для блога на WordPress закрыть все внешние ссылки от индексации поисковыми системами можно с помощью плагина WP-NoRef, установка и работа с которыми описана в этом материале.
Еще советую вам не пренебрегать таким мощнейшим инструментом для оптимизации контента на сайте, как файл robots.txt, описанный здесь. С помощью этого файла вы сможете управлять индексацией вашего ресурса поисковыми системами, тем самым закрыть все лишнее, сосредоточив внимание ботов только непосредственно на контенте.
Плохие методы продвижения сайтов по мнению Яндекса
В начале ноября представитель Яндекса проводила лекцию из серии «Школа вебмастеров» на тему того, что эта поисковая система считает нормальными методами продвижения, а за что можно будет поплатиться попаданием под фильтр или пессимизаций. Собственно, все остальные лекции из этой серии вы можете посмотреть на приведенной странице, но вот мне лично захотелось написать небольшой пост именно по материалам данной тематики.
Изюминкой стало то, что в этой лекции была подтверждена уже проскакивающая ранее информация от сотрудников Яндекса, что анонсированный в начале 2014 года отказ от учета ссылок (при ранжировании) сейчас уже не актуален. Т.е. сейчас уже во всех тематиках по всем регионам все проставленные на сайт обратные ссылки учитываются точно так же, как это было до момента отказа от них.

Аналитики высказывают предположение, что ранжирование без ссылок (на самом деле скорее с сильным занижением их влияния) велось за счет повышения важности коммерческого фактора ранжирования, который оценивался посредством армии асессоров Яндекса. Но, видимо, дело это оказалось слишком сложным и хлопотным, да и к тому же не столько эффективным, как предполагалось.
Тем более, что после введения в строй Минусинска необходимость отказа от учета всех ссылок подряд уже стала не актуальна, ибо алгоритм начал проводить эффективную и всеобъемлющую фильтрацию сайтов (на манер Пингвина в Гугле) на предмет слишком большого числа коммерческих ссылок в анкор-листах. Кроме этого с начала лета Яндекс по полной программе начал собирать поведенческие факторы для всех потенциальных жителей Топа, что позволило усилить влияние еще одного очень «говорящего» фактора ранжирования.
Немного про плохой и много про хороший контент
Собственно, проанонсировав «изюминку» данной лекции, я, наверное, сильно снизил ваше желание читать продолжение этого поста. Что ж, ваше право. Поэтому сразу приведу видеозапись лекции под названием «Плохие методы продвижения сайта», которую провела представитель Яндекса Екатерина Гладких:
Если смотреть лень или нет пары часов в запасе, то можете пробежаться по моему тезисному ее интерпретированию (постарался быть максимально кратким). Ведущая является представителем команды Яндекса, которая как раз и борется со всеми возможными нарушениями поискового продвижения. Что, собственно, только повышает интерес к предоставляемой информации.
Текстовая оптимизация
- Постраничная пессимизация — за переспамленный ключами текст. Страница (не весь сайт) с таким текстом (не совсем понятно, почему это называют портянкой, но не суть) будет ранжироваться ниже при прочих равных (вполне ожидаемо).
Выход — переписать эту и подобные ей странички. Разбан происходит автоматически по мере захода индексирующего робота.
- И все — остальное посоветовали черпать из двух лекций Екатерины Ерошиной:
Первая из них называлась: Как написать хороший текст для сайта (трансляция начинается примерно с четвертой минуты)
А вторая — Контент для интернет-магазинов (трансляция начинается примерно с пятой минуты)

Сам лекции пока еще не слушал, поэтому буду рад услышать Ваши отзывы в комментариях, чтобы правильно спланировать свое время.
Эффективное размещение SEO-ссылок по версии Яндекса
Представителю Яндекса не откажешь в чувстве юмора, если судить по заглавию раздела. В начале были даны определения для терминов, используемых в лекции.
В частности:
- Прошлись по анкорам и привели примеры анкоров для безанкорных ссылок (ну, прям все про нас знают):
- На пальцах показали, что выдать арендные ссылки за рекламу не получится несмотря на внешнее сходство, на которое, собственно, боту индексатора наплевать.
- Про вечные ссылки тоже поговорили. С ними, по мнению Яндекса, у многих вебмастеров и Сеошников последнее время возникают проблемы, ибо вопрос «где их купить», сменился на более актуальный — «как их снять» (юмор так и сквозит в высказываниях докладчика...).
- Приоткрыли завесу в работе классификатора ссылок. У него есть только два положения — ссылка гул или бед. Анкорная ли она или нет — сути это не меняет.
Классификатор анализирует 105 признаков, которыми ссылка может обладать, и на основании этого делается вывод — гуд (естественная) или бэд (покупная). За основу берется база заблаговременно хороших и заблаговременно плохих ссылок (видимо, собирается база асессорами), с которых снимают мерки по 105 параметрам, которые потом скармливаются матрикснету для обучения. Образно говоря, классификатор может отличать зеленые яблоки от красных будучи слепым, но имея возможность проводить другие измерения, которые в купе помогут сделать правильный вывод.
- Рассказали работают ли сейчас СЕО-ссылки (объяснили методику проверки и полученные результаты, правда за период всего четыре месяца, что явно маловато). Напоминаю, что это лекция от представителя Яндекса, а не ссылочной биржи, поэтому...
- Объяснили, что Яндекс борется с покупными СЕО-ссылками сейчас повсеместно, т.е. и на стороне продавца (для них уже довольно давно работает и постоянно обновляется фильтр АГС) и на стороне покупателя (относительно недавно их стал нещадно косить Минусинск — гарантированно выкидывает за Топ20, где трафиком уже и не пахнет).
- При подозрении на Минусинск советуют спросить Платона «а точно это оно?» (кстати, в новом Яндекс.Вебмастере обещаются сообщать о наложенных на сайт фильтрах). Если да, то покупные ссылки долой и ждем... Фильтр должен сняться автоматически. Обещают, что в этом случае все будет выглядеть в статистике примерно так:
- Говорят, что естественную ссылку купить нельзя. Вопрос, наверное, спорный.

По ссылкам все, если не брать в расчет вопросы, которые задавались уже после лекции (именно там и было сказано, что Яндекс сейчас опять вернулся к полному учету ссылок во всех тематиках и регионах).
Поведенческие метрики глазами Яндекса
- На примере записи сессий пользователей в Вебвизоре (входит в арсенал Яндекс Метрики) показали «странное поведение». Хотя на самом деле накрутку поведенческих, естественно, никто не отсматривает — тут опять же МатриксНет трудится, который на больших массивах накопленных данных видит почти все отклонения от эталонного графа (естественного поведения).
- Наказание за накрутку поведенческих выглядит несколько суровее Минусинска — трафик с Яндекса теряется практически полностью. Срок бана начинает отсчитываться не от момента его наложения, а от момента прекращения накрутки. После этого включается счетчик времени и по прохождении восьми месяцев сайт отправляется на автоматический пересмотр.
- Говорят, что накрутить конкурента не получится — напрасная трата денег, ибо эффект от искусственных посещений нивелируется (не учитывается это все в ранжировании — с этим понятно), а в бан его вогнать почему-то таким образом не получится (утверждают, что в бан попадают сайты, по которым точно знают, что крутил владелец, но как узнают?).
P.S. От себя добавлю. Бан за накрутку поведенческих суров — практически на год лишает органического трафика с Яндекса, что для коммерции смерти подобно. Отсюда возникает вопрос: действительно ли так эффективно различает Яндекс действие конкурента и владельца? Все же дело это (накрутка), по сути, не сильно дорогое и вполне можно заказать полноценную компанию по дискредитации конкурента не сильно страдая финансово, а итоговое поднятие на строчку или две выше в Топе вообще может все многократно окупить.
Суровость наказания также говорит и о том, что поведенческие факторы реально последнее время имеют колоссальное влияние на ранжирование. За ссылки только из Топа выкидывают, а за кручение ПФ — полностью в бан (надолго). Это еще раз говорит от том, что нужно уделять максимум внимания естественному улучшению поведенческих (сниппеты оптимизировать, пользователей удерживать, заинтересовывать, возвращать и т.п.), тем более в свете того шанса, который сейчас Яндекс стал давать новичкам.
- Советуют продвигаться (или заказывать продвижение) за счет улучшения юзабилити, клевого контента, функционала и т.п. вещей важных для посетителей сайта. Но не заниматься имитацией (накруткой) ПФ. От себя добавлю, что первое намного дороже, но это «фундамент», а не «кривые подпорки» в виде имитации удовлетворенных посетителей. Работайте над сайтом, улучшайте, оставляйте посетителей довольными и место в Топе вам будет рано или поздно (это скорее всего) гарантировано.
Другими словами — со своими (реальными — добровольно пришедшими) пользователями делать можно все что угодно (хоть в ладушки с ними играть или за руку держать, чтобы подольше не уходили) — все это только в плюс. Но вот «подставных» посетителей или «ботов» на сайт приводить для улучшения общей картины — это уже моветон, за который могут сурово наказать.
Ответы на вопросы по SEO-ссылкам в Яндексе
- Появится ли Дисавоу Линск в Яндексе? Нет, такого инструмента не будет. А как же быть со снятием вечных ссылок? Минусинск, оказывается, понимает, что это ссылки вечные, и понимает, что снимать их получается не быстро. Если вы стараетесь изо всех сил, то это будет замечено и фильтр снимется. О, как!
- Срок выхода из-под Минусинска зависит от двух вещей — как быстро вы снимите ссылки и как быстро об этом узнает Яндекс. Даже если ссылки вы снимите мгновенно (например, в Сапе), то в виду того, что робот-индексатор Яндекса не все страницы посещает одинаково часто (а странички всяких ГС и вовсе редко), то скорость выхода будет зависеть от качества сайтов, с которых вы покупали ссылки. Чем они были лучше, тем быстрее пройдет на них переиндексация и тем быстрее выйдите из-под Минусинска. В худшем случае и полгода можете выходить... Два месяца под Минусинском — это был рекорд.
- Из под Агс выйти можно быстрее, ибо индексируется только один сайт, и как только порог снятия (число размещенных ссылок) будет достигнут...
- По навигационным запросам сайты не вылетают из Топа при наложении Минусинска. Сделали, чтобы не сильно портить выдачу.
- Апдейты Минусинска проходят примерно пару раз за один месяц
- Нельзя выйти из под Минусинска с помощью улучшения дизайна, юзабилити или добавления клевого контента. Лечить нужно то, что болит — а именно снимать покупные ссылки. Все же указанное выше может повлиять в положительную сторону, но уже только после выхода из-под фильтра.
- Что делать, если часть купленных ссылок сейчас уже снять не представляется возможным? Снимать то, что возможно. Яндекс должен оценить сложность ситуации (алгоритмом) и понять, что вы сделали все, что было в ваших силах.
- Одна из самых дорогих покупных ссылок (из Яндекс Каталога) не будет Яндексом считаться покупной. На лицо политика двойных стандартов 🙂
- Сами по себе «плохие ссылки» (помеченные классификатором как бэд) никак на ранжирование сайта не влияют (ни в плюс, ни в минус — просто не учитываются), но при их большом количестве возможно попадание под Минусинск.
- Точность работы классификатора ссылок в Яндексе сейчас 94% (при 99% полноте)
- Работают ли ссылки для коммерческого ранжирования по московскому региону, учет которых отменили в 2014 году? Работают, ибо ожидаемого эффекта от их не учета Яндекс не увидел. Сейчас ссылки работают для всех тематик и всех регионов ровно так, как это было до 2014 года. О, как!
- Внутренняя перелинковка на сайте с прямым вхождением ключей ни в коем разе не будет расцениваться как неестественные ссылки (СЕО). Внутренние анкорные ссылки под фильтр не загонят. Так говорят...
- Платон Щукин не имеет право говорить неправду. Наложение санкций всегда подтверждается (для совсем УГ, правда, могут не конкретизировать). Могут что-то не досказать (подробности, детали). Интересное замечании.
- Переходы по ссылке на решение классификатора (плохая она или хорошая) не влияют. Как-то сомневаюсь...
- Расшаривание страницы в соцсетях с помощью кнопки «Поделиться» (даже с одинаковыми текстами) Сео-ссылками считаться не будут. Как-то странно, что этот вопрос возник, но ответ тем не менее прозвучал.
- По крауд-маркетингу... Оказывается Яндекс и тут «зуб дает», что умеет запросто отличать «липу» (оплаченные отзывы и упоминания) от возникших естественным образом (ценными для учета в ранжировании).
- Длинное прокручивание (большие тексты или страницы с другим видом контента), с точки зрения команды атиспама Яндекса (к которой относится и лектор), никак на ранжирование не виляет. От себя: если поведенческие нормальные (юзабилити), то и проблем не будет. Другое дело, что удержать внимание еще нужно суметь при таком количестве букв... Да, и еще не путайте «портянки» с просто длинными текстами. Первое — это синоним переспама, а второе — может быть продиктовано объективной необходимостью (ну, типа, как у меня на блоге — много букв требуется для доступного новичкам изложения).
- Яндекс не знает что такое траст сайта... Но улучшать его стоит...
- Возможна ли покупка обычных ссылок? Науке (Яндексу) это не известно... Однако утверждается, что продвинуть сайт в Топ без покупки вообще каких-либо ссылок можно... А что вы хотели еще услышать... Нельзя!? Ну, так-то, наверное, все же можно (раньше сложнее было с этим). ИМХО.
- Могут ли безграмотные комментарии на сайте, оставленные посетителями, повлиять на отношение Яндекса к сайту? Только опосредованно (прямых пессимизаций за грамматику не предусмотрено) за счет ухудшения поведенческих характеристик?
- Оптимальный процент вхождения ключей на странице вебмастер сегодня рассчитать не сможет (только Матрикснет с учетом еще сотен параметров, характерных для этой страницы и других подобных, которые есть в его базе).
- С недавних пор Сео-ссылки перестали учитывать при расчете Тиц, и его значение больше стало похоже на реальное положение дел с тематическим цитированием. О, как!
- Хорошим сайтам имеет смысл ставить Метрику, ибо это позволит им быстрее достичь успеха. Все просто — Метрика является идеальным инструментом для сбора ПФ. Если у вас с этим все ОК, то и ранжирование пойдет веселее. В принципе, об этом я уже писал.
- Ссылки с Твиттера, например, могут быть оценены классификатором и как бэд (покупные), и как гуд (естественные). Сам факт их проставления с соцсети влияния не оказывает на решение. О, как!
Seo форумы, блоги и социальные сети
Сегодня я хочу просто привести примеры тех форумов, блогов и социальных сетей, которые мне помогают черпать информацию по теме Seo продвижения и оптимизации.
Какими-то из этих ресурсов я пользуюсь регулярно, а какие-то посещаю время от времени, ну или вообще не посещаю. Но от этого упомянутые в этой статье проекты не становятся хуже или лучше — в любом случае выбирать вам самим, что читать, а что игнорировать.

Понятно, что часть полезных Seo форумов и блогов (а также социалок) окажется не упомянуто, поэтому огромная просьба поделиться вашими «настольными книгами» в комментариях. Если, на мой взгляд, они окажутся стоящими, то будут добавлены в общий список. Иногда бывает очень трудно отыскать и заметить бриллиант в куче посредственностей, да и общепринятые лидеры информационного поля в области продвижения иногда просто исписываются и многие новички начинают их превосходить по актуальности информации.
Seo форумы, которые стоит посетить
На самом деле очень трудно ранжировать Сео форумы, ибо все это очень субъективно и для каждого отдельно взятого вебмастера или оптимизатора данный список будет свой. Но тем не менее я попробую. Кстати, ранжирование блогов по этой же тематике, наверное, может оказаться еще более проблематичным, ибо там можно запросто обидеть кого-либо из авторов, но я все же попробую. А пока разговор пойдет именно про конференции.
SearchEngines — наверное, это первый форум по тематике Seo, который приходит на ум. Читаю я его практические ежедневно, но в основном это ветки по апдейтам Яндекса (поисковой выдачи, ну и апдейтам Тиц, которые случаются значительно реже) и нюансам продвижения под Google.ru.
Помню, читал как-то про то, сколько зарабатывает владелец этой самой посещаемой конференции в сегменте Сео (более 50 000 посетителей ежедневно). Как вы думаете, сколько насчитали? 1 000 000 рублей в месяц. Впечатляет, не правда ли? Хотя, наверняка, данная сумма впечатлила и самого владельца, ибо реальность всегда не так радостна.
MaulTalk — сразу оговорюсь, что на все остальные ресурсы, кроме SearchEngines, я захожу эпизодически и чаще всего с поисковой выдачи, когда что-то ищу по теме продвижения. Но это нисколько не умоляет их значимость. Данный Сео форум (MaulTalk) был несколько лет назад приобретен известным блоггером Маулом и теперь успешно существует и развивается под его собственным брендом.
Когда-то давно, MaulTalk жил на поддомене блога Маула (Talk.MaulNet), но потом был все же вынесен на отдельное доменное имя. Видимо для этого были свои причины (можете так же почитать статью Как я продвинул MaulTalk от «великого и ужасного» Маула).
- MasterTalk — название похоже на детище Маула, однако он является, по моему мнению, ближайшим конкурентом SearchEngines, хотя и уступает лидеру по количеству зарегистрированных пользователей и по посещаемости. В общем, MasterTalk — ресурс авторитетный и обязателен для ознакомления.
- Armada Board — данный форум примечателен тем, что там присутствуют разделы из области темно-серого Seo (адалт, фарма, гемблинг и т.д.), хотя и традиционные разделы по продвижению и оптимизации имеют место быть. На главной странице (в самом низу) приведена информация, которую предоставили в качестве своей рекламы десять самых активных участников, что является дополнительным стимулом к наполнению форума материалами.
Webmasters — форум довольно широкой тематики (почти как Нулед, но без хулиганства), включая и Seo продвижения с оптимизацией тоже. Опять же, там идет очень серьезная стимуляция пользователей к активному участию в жизни проекта. А в качестве платы за активность предлагаются довольно ценные призы.
Форум относительно молодой и поэтому использует все возможные способы привлечения и удержания аудитории (все же на серче сидят и фиг их оттуда вытащишь, ведь привычка — вторая натура). Отличительной особенностью является то, что денег на организацию конкурсов они действительно не жалеют.
- Форум Сапы — кроме самой Сапе там имеется раздел по Сео оптимизации, ну и также сопутствующие разделы. В общем-то, при желании, там можно найти много полезной информации.
- SeoCafe — привожу его для галочки, ибо никогда на нем не регистрировался и не общался. Но с поиска иногда попадал на его страницы, да и количество зарегистрированных на этом форуме пользователей вызывает уважение.
- Master-x.com — форум про нетрадиционное Seo, где в основном общаются люди, занимающиеся созданием и продвижением сайтов с адалтом, фармой, ну и интересующиеся другими способами слива и получения трафика.


Буду признателен за добавление ваших «настольных» конференций по тематике Сео с небольшим описание тех плюшек, которые вас привлекают на данном проекте.
Seo блоги — что почитать, на кого подписаться
При ранжировании Сео блогов проблема «как бы кого ненароком не обидеть» встает еще острее, ибо это продукт чьего-то творчества, и, как правило, одного человека, а он, как и любой творец, очень раним.
Будем надеяться, что пронесет.
- Маулнет — личный блог «великого и ужасного» Маула — довольно одиозной и загадочной личности в рунете. У Даниила, как и у любого талантливого человека, есть свои тараканы, о которых вы без сомнения узнаете, став читателем его Seo блога. Пишет он редко, но интересно. Особенно у него удаются интервью, ибо он не сюсюкается с оппонентом, а пытает выжать из него интересующую информацию, и даже если оппоненту удается уйти от ответа, по контексту ответа все равно угадывается. Рекомендую подписаться.
- Блог Сосновского — в принципе, на этом месте мог бы быть и Девака, ибо, по моему личному рейтингу, они занимают примерно одинаковую позицию, но с Сергеем Сосновским (не знаю, псевдоним это или нет) я заочно знаком, поэтому и поставил его выше. Он пишет «по делу», раскладывает все по полочкам и в реальном времени отвечает на все комментарии (в отличии от меня). В общем, я подписан на его ленту, чего и вам советую.
- Devaka — Сео блог в апогее, который существует уже довольно давно и до сих пор автор не исписался и не ушел в сторону от тематики продвижения (в отличии от меня, опять же). Ведет сей блог Сергей Кокшаров, который в последнее время стал писать гораздо чаще и все сплошь на актуальные темы. Наверное, только Сергеи (Сосновский и Кокшаров) описывают результаты своих реальных Seo экспериментов, несмотря на то, что это реально сложно и зачастую просто не рентабельно, за что им отдельный респект и уважение. Подписываемся, однозначно.
- Tods-blog — читаю этот блог уже довольно давно и нахожу его весьма полезным для тех, кто хочет получить дополнительную информацию по оптимизации и продвижению. Автор (Александр Тодосийчук) пишет не часто и иногда там встречаются рекламные посты, но в общей массе можно найти очень даже ценную и хорошо поданную информацию.
- Seom.info — блог довольно известного специалиста в области Сео технологий Александра Люстика, который является автором знаменитого Key Collector (программы для облегчения составления семантического ядра и подбора ключевых слов). На этом блоге вы встретите довольно много материалов как от самого Александра (он пишет о реально важных вещах, правда вот изложение не всегда облегчает задачу понимания), так и хорошо переведенные статьи западных Seo-блоггеров (что просто бесценно для таких, как я — не знающих англицкий).
- Altblog — недавно открыл для себя этот Seo аналитический блог от Алтайского блогера. Ничего пока особенного сказать не могу, но несколько фишек, почерпнутых там, я с успехом применил у себя. В общем, очень даже полезно и не заезжено.
- Блог Александра Борисова — почему-то у этого ресурса для начинающих вебмастеров и оптимизаторов довольно странное доменное имя. Автор пишет на тему Сео очень подробно и языком понятным всем, включая даже абсолютных новичков. Единственное, что мне не импонирует на этом блоге, так это несколько необычная манера подачи материала. Я не могу придумать для этого термин, но очень похоже на то, как пастыри ведут проповедь в американских фильмах. Еще поражает энергичность Александра — просто так и пышет от него и его текстов жаром.
Михаил Шакин — для многих из тех, кто сейчас ведет свой сайт, этот блог стал одной из первых настольных книг по продвижению (включая и меня). За это я особо признателен и благодарен Михаилу. Другое дело, что сейчас материалов по Сео выходит мало и этим прежде всего обусловлено такое непривычное для Михаила место.
А в остальном только положительные эмоции. Очень много интересных материалов, особенно про жизнь в Америке (отдельную книжку можно издавать), а также интервью и опросы блогеров. Мне импонирует личность Михаила — очень приятный во всех планах человек.
- Pervushin.com (Блог Сергея Первушина) — на мой взгляд очень полезный и доступный для понимания ресурс. Имеются материалы не только на Сео тематику, но и на общие вопросы вебмастеринга. Автор хорошо и подробно излагает информацию, за что ему отдельное спасибо. Однозначно, подписываемся.
- MarkinTalk — возможно не очень известный блог про «Seo без воды», но очень толковый и, на мой взгляд, полезный. Правда автор не так часто радует нас новыми материалами, но в это время можно спокойно заняться чтением уже опубликованных.


Заранее прошу не обижаться всех тех владельцев блогов, кого я не упомянул. Никакого злого умысла тут не прослеживается. Буду очень признателен, если вы приведете в комментариях ресурсы тех вебмастеров, которые вполне достойны размещения в этом списке. Спасибо.
На самом деле, хороших Seo блогов (да и Сдл сайтов любого другого направления) могло бы быть гораздо больше (не в плане этого списка, а вообще в рунете). Вся проблема заключается в монетизации, ибо реально рабочих способов заработка в интернете для владельцев контентных проектов не так уж и много — либо ссылки продавать и ухудшать свою карму для поисковиков, либо показывать рекламу Яндекса на своем сайте или размещать контекстную рекламу Гугл Адсенса.
Но контекст не дает возможности достойно зарабатывать белым и пушистым сайтам, у которых очень много нужной и полезной пользователям информации. На контексте хорошо зарабатывают только MFA (сделанные под Адсенс или Директ). Обычно, на MFA присутствует только полноценная навигация, но практически совсем нет контента.
Пользователь попадает на страницу, где будут только красиво размещены рекламные блоки, и чтобы не уходить «не солоно хлебавши», он переходит по одной их рекламных ссылок. В результате CTR на MFA достигает 10 процентов, а на хороших CДЛ не всегда даже удается перешагнуть планку в пол процента (слишком высокая у них доля контента по сравнению с долей рекламных объявлений).
Вот так вот. Поэтому среди Seo блогов выживают (не консервируются) только те, у которых авторы твердолобые и сильно упорные (любой энтузиазм имеет очень даже ограниченные сроки жизни, ну, а амбиции на голодный желудок просто не катят). Возможно, что остаются только подобные мне — не шибко умного старого дядьки, но зато способного биться головой о стену на протяжение целого ряда лет. Ну, а талантливые и умные просто уходят искать способ заработка на жизнь в другом месте. Увы и ах.
Социальные сети по тематике Seo и не только
Как бы это даже и не полноценные социальные сети, как то Facebook, Гугл+, Twitter или В контакте, а сборники анонсов с различных Сео блогов. Конечно же, хотелось бы видеть среди них ярко выраженного лидера, который бы аккумулировал в себе все новости со всех интересных ресурсов тематики продвижения, но, к сожалению, такового пока что нет. Возможно, что опять же это происходит из-за пресловутой проблемы с доходностью данного вида бизнеса.
На данный момент в рунете контентные проекты не имеют явно выраженной бизнес перспективы — нужно предлагать продукт, за который люди будут платить деньги (например, делать различные биржи аля Gogetlinks, ну, или хотя бы как Ротапост от Димка, который, кстати, тоже имел предварительно опыт создания контентных проектов, но перешел к продаже посреднических услуг).
Поэтому здесь я приведу ссылки на то, что имеется в наличии и что хоть как-то отвечает понятию «социальные сети тематики Сео»:
- SeoMinds — очень приятно оформленный и интересный ресурс, где можно найти для себя что-то новенькое. Интерфейс немного напоминает пресловутый ХабраХабр
- Группа в Subscribe — можно войти в эту группу и получать на почту огромное количество писем с анонсами новых статей на множестве ресурсов с уклоном в вебмастеринг. Теперь, как видите, Subscribe — это не только почтовые рассылки для продвижения сайта, но и группы, которые можно использовать для той же цели. Вот Сео мастера их и используют.
- Ну, и как бы не совсем в масть, но очень много интересной информации по тематике продвижения можно почерпнуть из рассылки Ашманова.
Возможно, что это буржуйское видение успешной раскрутки блога вам пригодится (выступает автор самого популярного блога по тематике SEO в буржунете):
Комментарии и отзывы (57)
Уф... Сколько интересной и полезной информации в одном месте! Спасибо!
Большое спаисбо, много интересного и полезного для себя нашла! И написано очень внятно!
Спасибо за статью. А про Ротапост зря так рассуждать, мой сайт и там и в ГГЛ продает ссылки, только на Ротапосте цена пониже, и думаю я не один такой.
Как всегда бьете в точку. Спасибо. Много полезного для себя почерпнул.
очень очень интересная статья советую всем
Дмитрий, как всегда грамотный и обширный обзор. Большое спасибо за статью.
«Обмен ссылками с другими ресурсами тоже может принести вам какую-то пользу в Seo продвижении, но тут нужно быть осторожным, ибо поисковики обмены не одобряют.»
Дмитрий, а как не перейти ту черту обмена ссылками (постовыми)? Поисковики как то вычисляют ссылки по обмену?
Ух сильная статья! Особенно для меня, — новичка в блоговедение. Расписано качественно и понятно, все собрано в одну кучу! Спасибо
А у меня наоборот с гулом все отлично, все запросы топ10 или топ20, я яндексом кошмар, очень тяжело даже неконкурентным запросам выползти на свет. Тут недавно непонятка была. Выходит в поисковой выдаче моя стать про любовь, кликаешь, и попадаешь на статью про месть. Прям как насмешка! Робот взял название одной статьи, а перенаправляет на адрес другой...(пришлось им писать, исправили) или индексирует новую статью, а потом из индекса вдруг выкидывает на пару дней, а потом опять индексирует. Раньше такого не было, может у них какой алгоритм изменился. В общем, я обижена на яндекс, не хочу больше под него оптимизировать статьи. Моя плакать.
Действительно, столько всего, устала читать, но для изучения и применения очень много полезностей.
Спасибо Вам Дмитрий! Очень толковая статья, для меня то уж точно) Буду придерживаться Ваших советов, развивать и продвигать свой блог!
Супер статья — живая, оч полезная. Здорово наблюдать изменение настроения от статьи к статье! Но реально оч длинная!
А вообще учусь оптимизации у Вас,Дмитрий, не только по статьям но и по их написанию, содержанию, расположению ссылок, манере написания, расположению рекламы и т.д. огромное вам спасибо!
Отличная статья! Для меня новичка, чёткое руководство для сео-продвижения! Большой труд!
Дима! Очччччень своевременная статья. Мне в аккурат не хватало мотивации. А теперь я мотивированный и информированный! Диме — РЕСПЕКТ!!!
Спасиба! Класс! Мега манул по SEO!
Спасибо) Как всегда просто и со вкусом)
После прочтения этой статьи подписался на рассылку обновлений сайта! Спасибо! Голова кипит, я новенький вебмастер, но как говорится, ктоНаНовенького? 😉
Ну что ж, по-моему, это не статья, а программа к действию, типа "Апрельские тезисы " В.Ульянова — Ленина.которые он на броневике рассказал))))
Придется ее взять и разбить на временные и производственные этапы продвижения блога, как в смысле его SEO-оптимизации, так и его монетизации, дай Бог, что бы в год уложиться...
Друзья, предлагаю вам присоединиться к движению: « ВНИМАНИЕ, ЭКСПЕРИМЕНТ : КАК ЗАРАБОТАТЬ НА МОЛОДОМ САЙТЕ 1000$» http://blog.rabotaposisteme.ru/.
Если Дмитрию удалось за два года достичь таких успехов, сможем ли мы его повторить, или это уникальный случай?
Или это как говорил Аркадий Райкин? « Ребус, кроссворд»)))
Просьба к админу, не расценивать данный комментарий как самопиар, а как призыв к начинающим блоггерам действовать в стиле " а ля Дмитрий КтоНаНовенького "
Благословений всем нам для нашей общей пользы и прибыльности!
С уважением к вам и вашему делу, всегда ваш, Олег Кмета, создатель и руководитель проекта " Работа По Системе "
Хорошая статья, как и все на этом сайте. Все очень популярно и доступно освещено. Но утверждение, что сейчас в топ10 нет хлама относится только к информационным сайтам. Коммерческие (назначение которых продать что-либо) живут своей жизнью. Например по запросу «наружная реклама собственник» вы никогда этих самых собственников не найдете. Хотя возможностей (финансовых) у них в сотни раз выше чем у перекупщиков. А на запрос «печать постеров» вылезает куча организаций вообще такого не делающих. А мы не печатаем широкоформат! А зачем вам тогда в ключевых словах «блюбек»? (спец. материал для постеров)
А без сео слабо продвинуть свой сайт?
Вашим методам всё-равно осталось не долго жить,так как поисковики активно контролируют таких как вы.Почитайте эту статью: http://company.yandex.ru/rules/optimization/
Александр: Seo и продвижение — это совпадающие понятия или, другими словами, синонимы. Поэтому продвижение без Сео не возможно априори. Скорее всего Вы не совсем внимательно прочитали статью. Покупка ссылок сейчас является лишь одним из небольших кирпичиков успеха. Однако, это кирпичик еще по прежнему лежит в основании любой оптимизации сайта и будет лежать там еще очень и очень долго.
То что поисковики хотят убрать спамные факторы влияющие на ранжирование (Seo ссылки и переспам) — это понятно, но без учета ссылок и анализа текста определение релевантность на данном этапе их развития пока еще не возможно. Сейчас рулит именно комплексное продвижение, о котором и идет речь в этой статье.
Ну, а будь я на месте автора публикации, то говорил бы все в точности так, как он — должность обязывает (равно как в том же ключе уже давно высказывается Мэтт Каттс из Гугла). Но жить то и продвигать сайты придется именно Вам, а не им. Поэтому я за честность.
Это для Вас совпадающие понятия.С чего Вы вдруг решили,что продвижение без сео не возможно?Откуда такие бредовые мысли?Мой сайт продвигает фирма,которая вообще сео не использует и всё прекрасно получается и с каждым днем появляется всё больше клиентов,благодаря им.
Александр: Вы просто не в теме и моя «улыбнутость» Вами постепенно переходит в некоторую раздраженность. Попробуйте погуглить на тему продвижения или просто зайти на Википедию с вопросом о SEO. Пишу в основном только о том, что делаю сам и что работает (во всяком случае работало на момент написания статьи). Мне, в отличии от ваших подрядчиков, незачем забивать Вам баки ересью (Вы же мне не платите).
P.S. Надеюсь, что Вы не Тролль, а просто введенный в заблуждение пользователь — Троля кормить, сами понимаете, не рекомендуется.
Ну, а остальным читателям посоветую не верить на слово тем, кто так или иначе заинтересован в том или ином варианте ответа. Особенно тем, кто продвигает без Seo оптимизации — наверное, ГС трафик нагоняют или Яндекс Директ подключили и обозвали это продвижением, прекратив которое Вы останетесь вновь у разбитого корыта, ибо сайт не будет оптимизирован и поискового трафика, скорее всего, не будет, а именно он дает гарантии благополучия на ближайшее будущее.
Seo — это не только обратные ссылки (они второстепенны и удачно сработают только при условии идеального выполнения всего остального), но и работа над правильной внутренней структурой сайта, внутренняя перелинковка, семантическое ядро и удачные посадочные страницы, ну, и наконец правильно и грамотно оптимизированный контент. В Сео конторах такая услуга будет стоить от ляма, а все остальное развод. ИМХО.
Доверяйте, но проверяйте и включайте логику. За мою практику фрилансера я у каждого первого клиента обнаруживал ту или иную предубежденность или явное заблуждение, которое никак не аргументировалось, но и не позволялось подвергаться сомнению. Увы и ах, сцепив зубы приходилось кивать. Но здесь то (на страницах блога) можно и повыеживаться. Лепота.
Согласен с Дариной.Дело говорит.
Успел раньше меня скопипастить книгу SEO: Поисковая Оптимизация от А до Я
Бабай: действительно, в упомянутой Вами книге использованы несколько статей с моего блога. Сделано это было с моего согласия. В списке авторов (http://www.seobuilding.ru/seo-forum/poiskovaya_optimizaciya_v_obshih_chertah/seo_poiskovaya_optimizaciya_ot_a_do_ya) можете найти «Дмитрий KtoNaNovenkogo» , так что... Не понятна ваша фраза.
Хочу у Вас проконсультироваться. Есть у меня блог.
nature-pict-and-sound.com/
Называется «Картинки и звуки живой природы». На этот запрос
Google показывает мой блог и его записи на 2,3,4,5,6,7 местах,
а также на 16,17,18,19,20.
21,22,23,24,25,26,27,28,29 местах.
Но число посещений моего блога не превышает 10 в сутки.
Требования SEO пытаюсь соблюдать. Правильно ли? Не уверен.
Запись «поющий тушканчик» со сплошными несоблюдения этих правил
набрала подавляющее число комментариев. На Ваш блог я подписан и с большим интересом читаю и пытаюсь использовать ваши статьи.
Сергей Гвоздев Дед: чего то не так смотрите — в гугле по этому запросу Вы на 45 месте, а следовательно и трафика по нему нет. Видимо Вы смотрите выдачу Google под своим логином. Выйдите из под него (в правом верхнем углу выберите из меню выпадающего списка своего аватара вариант «Выйти»). Картина выдачи сразу же изменится и в худшую сторону, естественно, и именно так ее видят большинство пользователей интернета.
Дмитрий, в двух словах: — СНИМАЮ ШЛЯПУ! Не стоит обращать своего внимания на тех, кому нечего показать... Мой сайт macrocoin.com еще совсем молодой и похвастаться пока нечем (в плане посещаемости), потому я и нагуглил Ваш САЙТ,а именно эту статью, видно поджало. За что бесконечно Признателен! Вот правда, столько информации, что не знаю с чего ПРАВИЛЬНО начинать, чтобы не терять времени и меньше совершать ошибок... Подскажите Пожалуйста, буду Очень Благодарен!
Здравствуйте, Дмитрий. Ваши статьи производят самое приятное впечатление. Спасибо. Своего блога у меня пока нет, а вот вопрос есть. Скажите пожалуйста, может ли блог работать по следующей схеме:
Существует тема, в которой я способен оказать услуги по решению очень распространенной проблемы, свойственной многим людям. Я хочу предложить заинтересованным лицам рассказывать истории их жизни и задавать вопросы, о том, что делать в этой ситуации?
Я буду давать свои рекомендации, которые в равной степени будут работать для всей аудитории читателей блога. Способна ли такая схема работать и привлекать новых посетителей блога? Как отнесутся поисковики к такого рода контенту?
Заранее благодарю. С большим уважением к Вам. Сергей. Саратов.
Добрый вечер, Дмитрий!
Читаю Ваши статьи и приятно удивляюсь доступностью рассуждений по серьезной теме. Помогите, мне, пожалуйста, решить проблему: почему позиции в Яндексе (тестовый режим) в LiveInternet отражают статистику сайта не соответствующую в действительности. Например, по одному ключевому слову «Яблоко» в тестовом режиме LiveInternet оно стоит на первом месте, а при перепроверке этого слова непосредственно в поисковике Яндексе оно вообще отсутствует.
Заранее благодарен с уважением Владимир.
Скажите, пожалуйста, можно ли страницу переделать в запись (у меня движок Вордпресс)?
И как это повлияет на поисковую оптимизацию?
Дмитрий, добрый день!
Скажите, какова Ваша цена за СЕО-продвижение и раскрутку сайта при наличии текста с ключевиками? что ещё для Вас понадобится и каковы сроки?
Благодарю!
Игорь.
Игорь: я не практикую, спасибо.
Это просто праздник какой-то! Вы мой кумир!
Добрый день! Товарищи профессионалы! Помогите найти добросовестного специалиста для создания сайта и его раскрутки. Заранее благодарю!!!
Очень объемная статья (22 тыс. знаков без пробелов), которая связана ссылками с другими, а те, в свою очередь — с другими. Чтобы прочитать эту статью во всеми ссылками... не знаю, хватит ли недели? Спрашивается – для кого вы старались? Для людей ли? Сами бы стали переходить по каждой ссылке?
На мой взгляд, это очень неудобно, или как говорят в интернете – никакого юзабилити.
Если в этом и заключается SEO в блогах, то я против такого будущего интернета, т.к. разрушается структура последовательной подачи материала пользователям.
Тимур, если Вам знакомо все, на что идут ссылки, то и переходить бессмысленно, а если Вы только начинаете, то это кладезь полезной инфы. Если все это в одну статью впихнуть, то поболе 22 тыс. выйдет. А «структура последовательной подачи материала» — это в ВУЗе, блоги больше для самоучек, которые умеют обрабатывать огромное количество информации по собственному желанию, а не за пятерочку в зачетке)))
Ирина17-03-2013 в 0:11
Когда все знакомо, тогда не то, чтобы не читаешь такую статью, а вообще не заходишь на подобные блоги. Вы правы, тут много полезной информации. Прав я, что тут отсутствует структура – это все же стоит признать и взять на вооружение, иначе… зачем нужны тогда комменты?
Хотя, дело ваше, другие будут учиться на ваших ошибках.
Хотите посоветую? – делайте содержание статьи (как в книге), если статья большая…
Здесь четкая структура — гипертекст.
Добрый день! Спасибо большое за ваши толковые статьи! У меня есть вопрос, может и не по теме, но не могли бы вы посоветовать как быть? Мой сайт и форум взломали, напичкали разными вредностями. Гугл и яндекс сразу же выкинули из индекса. Гугл сейчас вроде вернул, но не так как было раньше. Яндекс оставил одну страницу сайта, а форума в поиске нет вообще. Я все вредоносное вроде удалил, и в поддержку писал, но воз и ныне там. Подскажите есть смысл бороться и дальше, или просто не тратить нервы и закрыть проект? Заранее большое спасибо!
Alex: Здравствуйте! Видимо, срок нахождения Вашего сайта под воздействием вирусов и, следовательно, срок его блокировки в поисковых системах был очень продолжительным. Если в Яндексе осталась одна страница, то, возможно, что Вы попали под АГС уже по какой-то другой причине. Каких-либо действенных способов, кроме обращения к Платону Щукину я не вижу. Разве что только еще раз вирусы поискать и, может быть, проверить возможность индексации вашего сайта поисковиками (запреты в Роботс.тхт, ответы сервера, склейка зеркал, дубли контента и другие технические моменты).
Дмитрий, спасибо большое за ответ! Сайт мучил вирус около двуx месяцев. Под АГС он не попал, поддержка пишет, что претензий у ниx к сайту сейчас нет. Причем страниц загруженныxроботом несколько тысяч, а поиске ноль. Вы не могли бы подсказать где и что посмотреть на предмет запретов. Роботс в порядке, зеркала тоже, теxнические элементы для меня немного сложновато, а вот про дубли я не знаю как посмотреть и главное как исправить. Проверяя через яндексвебмастер, вроде было что у форума есть дубли, но что с ними делать ума не приложу. Может есть какой сервис, который может показать причины не индексации? Еще раз вам большое спасибо!
Здравствуйте! А влияет ли платформа сайта на сео продвижение? Их куча целая, а я по незнанке у ПЕРЕДОВИК.РУ заказал. Потом выяснилось,что у них вообще своя платформа, русская,они ее сами сделали. Надомной теперь знакомые смеются, говорят его продвинуть нельзя. 80 рублей отдал уже, а теперь вроде ещё столько же надо чтоб на битриксе сайт сделать, потому что его двигать легче. Это правда?
Как все просто оказывается, но в то же время так сложно...Как бы мне хотелось иметь столько посетителей как у Вас.Но как конкретно это сделать без особых навыков я даже не представляю. Может Вы чем то сможете мне помочь? Или порекомендуете пройти какие то хорошие, проверенные курсы? Чтоб я все делала самостоятельно (у меня интернет магазин мебели), а не платила деньги за рекламу, продвижение.Спасибо.
было бы хорошо Дмитрий, чтобы термины были по-русски и последовательность подачи материалов была. тут Тимур прав, правда Ирина обидется, что не по-басурмански
Спасибо большое, очень полезная и интересная информация!
Крутая статья! Очень понравилась. Можно давать почитать клиентам, может перестанут задавать глупые вопросы.
умрет ли SEO?
seo загибается почитайте серч, не морочьте людям головы.
Денис: ну, сейчас вообще сложно найти «реальные отзывы», ибо конкуренты друг другу «портят кровь» (сеошники такого сотворили с выдачей, что это уму не постижимо — легко оказывается обмануть машину). Проводя параллели можно сказать, что SEO хорошо работает только если большинство в него верить не будет, ибо иначе в выдаче будет слишком тесно. Мне, наверное, тоже было бы выгодно поддерживать Вашу версию...
P.S. Лирика, лирикой, но СЕО сейчас это не только (и не столько) обман и накрутки, а сколько следование советам самих поисковиков (посмотрите материалы вебмастерской Яндекса). Это технический аудит (типа того, о чем я писал тут и тут), юзабилити, полезные приблуды, качественный контент (опять же оптимизированный под нужные запросы, но не топорно, а по уму — чтобы пользователь получал ответы и не уходил) и т.п. По сути, СЕО — это способ сделать так, чтобы сайт как минимум не вызывал у поисковиков отторжения (по техпричинам) и как максимум нравился настолько, чтобы по нужным запросам попадал в ТОП.
P.S.2. Ну, и по самой расшифровке аббревиатуры (SEO) умереть оно априори не может (разве что только после кончины самих поисковиков). За смерть СЕО уже на протяжении лет пятнадцати ошибочно принимают смену вектора приложения усилий, который с завидной периодичностью (алгоритмы изменяются) существенно смещается и не все хотят за этим следить.
интересны были Ваши ответы. Еще вопрос: почему у вас ссылки все открываются в новой вкладке — это жутко бесит же
Я давно уже хотела написать и поблагодарить за качественную информацию. И отдельное спасибо за трехтомник SEO А до Я. Это классика! Спасибо огромное, ребята!!! Изучала СЕО с книг иностранных авторов и было это аж в 2011 году. На самом деле всё, что было написано там у вас есть и изложено очень доступно. Вы — профессионалы, которых, по моим наблюдениям, на рынке единицы!
Дмитрий,добрый день!
Знаете ли Вы какой-нибудь качественный курс по SEO-оптимизации?
В интернете «море воды» по оптимизации сайтов,но толкового мало.
Я бы посоветовал курс Маркина Антона (блог markintalk.ru). Но это мое ИМХО.
Яндексу нужно качество без ссылочной массы, и Google нужно качество, но здесь ссылочная масса в продвижении только в плюс ресурсу, правда если все оптимизировано, в меру и релевантно. На сегодняшний день поисковики обучаемы разнообразным алгоритмам и интеллектуальное SEO, это фундамент продвижения в целом. Людям же нужно получить качественную информацию. Наверное, среди всего этого изобилия правил нужно искать золотую середину.
seoquick, увы, Яндексу тоже нужна ссылочная масса, но качественная.
Спасибо за тему,для новичков самое то,но для меня как новичка и пытающегося разобраться в основах seo совершенна была непонятно в статье тема про «Внешнею оптимизацию seo»,а если конкретнее про « где набирать ссылочную массу» ,для примера могли бы продемонстрировать как в вашем блоге реализована эта оптимизация,(это какой то линк на строганий сайт или что то другое ?)
Ваш комментарий или отзыв