Гугл — история создания и особенности продвижения под поисковую систему Google.ru
Здравствуйте, уважаемые читатели блога KtoNaNovenkogo.ru. Пару месяцев назад я написал статью про историю Яндекса и особенности продвижения именно под эту поисковую систему, аргументируя это тем, что не могу не отплатить той же монетой компании, которая приводит на мой блог более половины всех посетителей. Как вы думаете, что произошло с тех пор?

Правильно, все перевернулось с ног на голову и теперь уже Google приводит на мой блог более половины всех посетителей. Немного опасаюсь, что после этой статьи и лидер мирового поиска тоже повернется ко мне задом, но все же рискну. Хотя он этого стоит, ибо сейчас это одна из самых дорогих и перспективных компаний в мире.
Да и само качество поиска Гугла во многом превосходит аналог от зеркала рунета (читайте про то, как правильно гуглить), но большинство по-прежнему сидят в Яндексе в основном в силу привычки (как и я, собственно).
История поисковой системы Google.com
Итак, историю развития этой компании можно начинать отсчитывать с 1996 года, хотя официально поисковая система начала работать только с осени 1998 года (получается Гугловцы на год отстали от Яндекса, но тем не менее успели все наверстать).
Именно начиная с 1996 года прообраз сегодняшнего поисковика начал работать на территорию кампуса Стэнфордского университета, в котором в то время учились в аспирантуре (доктаратуре) не безызвестные сейчас в мире Сергей Брин и Ларри Пейдж.
Оба этих джентльмена были 1973 года рождения (практически мои ровесники) и оба являлись выходцами из профессорских семей с еврейскими корнями. Мамы и папы обоих основателей Гугла занимались математикой (преподавали) и компьютерными технологиями, что, собственно, и сподвигло интерес их чад к этим областям науки. И Сергей Брин, и Ларри Пейдж во главу угла всегда ставили получение высококлассного профильного образования (молодцы, чего сказать).
Была у них, однако, разница в происхождении. Сергей Брин родился в Советском Союзе в славном городе Москве и был вывезен родителями в 1979 году в штаты по программе эмиграции еврейских семей. А Ларри Пейдж уже изначально был урожденным американцем, хотя, по сути, это не так уж и важно, ибо Сергею было всего шесть лет, когда он перестал быть нашим с вами соотечественником. Что примечательно, Брин до сих пор очень не плохо говорит по русски.
Если вы читали историю Яндекса, то, наверное, заметили, что по сути он появился как развитие той темы, которой занимались его создатели в бытность свою научными работниками. То же самое можно сказать и про Google.com. Брин и Пейдж, будучи аспирантами Стэнфорда, занимались решением проблемы поиска по неструктурированным огромным массивам данных. Изначально они это хотели прикрутить к чему-то там связанному с определением самых востребованных товаров, но им вовремя подвернулась под руку проблема поиска по интернету.
Имеющиеся в то время поисковики с трудом справлялись со своей задачей. Результаты поисковой выдачи имели очень низкую корреляцию с тем, что хотел увидеть в ответ на свой запрос пользователь. Дело в том, что тогда основным маркером (фактором), по которому осуществлялось определение релевантности и ранжирование документов в выдаче, была частота использования слов из запроса пользователя в документе.
Понятно, что такой критерий отбора очень легко поддается накрутке со стороны вебмастеров простым увеличением тошноты текстов. Представляете, сколько времени уже прошло с тех пор, как появился текстовый спам, с которым поисковики только сейчас начали всерьез бороться и искоренять (ибо появились другие факторы, позволяющие существенно снизить важность частоты вхождения ключей в тексте при ранжировании).
Ну, вот. Ларри Пейдж с детства на примере своих родителей, вращавшихся в научных кругах, видел и понимал, что авторитет того или иного ученого во многом зависит от того, в скольких научных работах на него ссылаются, как на первоисточник или как на авторитетного специалиста. Чем больше ссылок, тем авторитетнее имя ученого. Логично?
Конечно же, логично, но причем тут Google? Дело в том, что у Пейджа возникла идея перенести эту систему ранжирования на поиск в интернете. Ученых он ассоциировал с отдельными документами (не сайтами, а именно отдельными вебстраницами), а ссылки в интернете существовали аж с момента изобретения всемирной паутины WWW Тимом Бернерсом-Ли в далеком 1989 году (кстати, спустя пару лет, именно Тим основал консорциум W3C и разработал язык Html).
Ну, и в результате появился всем вам известный фактор ранжирования, который учитывается поисковиками до сих пор — PageRank. Термин этот составной. Rank — означает ранжирование, а вот Page может означать либо веб страницу в английской вариации написания, либо то, что данный параметр ранжирования придумал никто иной как Пейдж (который Ларри).
Но это не суть важно, ибо PageRank совершил революцию и позволил поднять качество поиска будущего на недосягаемую высоту. Вообще, для общего развития можете почитать статью про PR и Тиц, в которой я пытался на пальцах объяснить их суть, ну или посмотреть по диагонали мое самое большое творение на этом блоге, которое целиком и полностью посвящено именно показателю PageRank.
ПР позволял учитывать при ранжировании документов не только количество, но и качество ведущих на ту или иную вебстраницу ссылок. Ну, а качество ссылки, соответственно, зависело от количества входящих бэклинков на страницу-донора (донором в SEO принято называть того, с кого ведет линк, а акцептором — того, на кого он проставлен).
Т.е. тут появляется понятие статического веса страниц в интернете, в соответствии с которым и оценивается качество ведущих с них ссылок. Все это безобразие рассчитывалось Гуглом в несколько проходов (итераций) и являлось (по крайней мере на то время) отличным фактором ранжирования. Вообще, тема PageRank не такая очевидная, поэтому для детального знакомства придется прочитать упомянутые чуть выше статьи.
Ну, а мы вернемся к истории Google и посмотрим, как же двум талантливым джентльменам из оплота демократии удалось воплотить идею ранжирования документов глобальной сети в жизнь и мимоходом заработать на этом по двадцать миллиардов зеленью (хотя для них это не было самоцелью, а просто стало результатом их работы, от которого глупо отказываться).
В первую очередь для проверки работоспособности программы расчета Page Rank нужно было получить огромный массив данных. Ларри Пейдж решил, что он сможет для этой цели скачать к себе на компьютер весь интернет, чем поверг в недоумении своих руководителей.
Однако на средства Стэнфордского университета Ларри и Сергей сумели собрать из комплектующих (это позволило за те же деньги получить в трое больше железной составляющей, чем при покупке уже собранных серверов) необходимое число компьютеров и запустить своего паука (программу, копирующую найденные ею вебстраницы в интернете).
Кстати, отмечу, что Ларри и Сергей остались верны своей идее — Гугл сейчас является сборщиком компьютеров номер один в мире (существенно опережая Dell и HP) при этом ни одного сервера не продавая, а используя их все для своих дата-центров, в которых по приблизительным данным насчитывается по всему миру уже более миллиона единиц. Это позволяет им при тех же расходах получать существенно большую производительность и не экономить на резервировании, что делает его абсолютным лидером в скорости и надежности работы.
Но вернемся опять к истории. Итак, в результате детище Брина и Пейджа стало служить средством поиска для всех пользователей Стэнфордского университета. Сергей и Ларри просили своих первых пользователей высказывать свои впечатления и замечания по работе поиска, пытались их учесть и доработать (фактически это был этап альфа тестирования). Поиск стал доступен в 1997 году по адресу google.stanford.edu. Из Стэндфорда была подана заявка на лицензирование технологии поиска с использованием PageRank.
Как вы можете видеть, в URL адресе уже используется слово Google (хотя было время, когда алгоритм поиска имел название BackRub, ибо строился на учете обратных ссылок), которое было придумано накануне в качестве одного из возможных названий поисковой системы. Происхождение этого слова связано с неправильным написанием термина Googol, который обозначает хитрое число, состоящее из единицы и ста нулей стоящих после нее.
В общем-то, поначалу было предложение назвать поиск GooglePlex (в правильном написании Googolplex — десятка в степени гугол), но оно показалось слишком длинным и остановились на упомянутом термине (почему-то написанном в результате не правильно, но менять уже не стали, т.к. был почти сразу же приобретен домен Google.com). Этим названием создатели, наверное, хотели подчеркнуть или предугадать грандиозность индексной базы будущего мирового лидера поиска.
Гугл и Яндекс — общие моменты в развитии и становлении
Отличительной чертой главной страницы Гугла в то время стал полный ее аскетизм, который остался и до сих пор. Сравните главную страницу Яндекса (там иногда под строкой поиска можно увидеть баннер, стоимость размещения которого на неделю равняется стоимости квартиры в Москве):
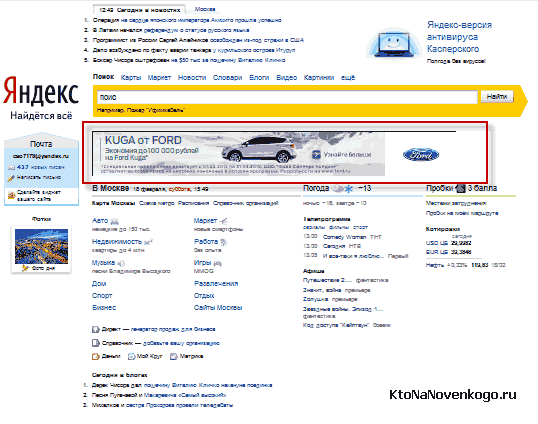
И посмотрите на главную страницу Google.ru:
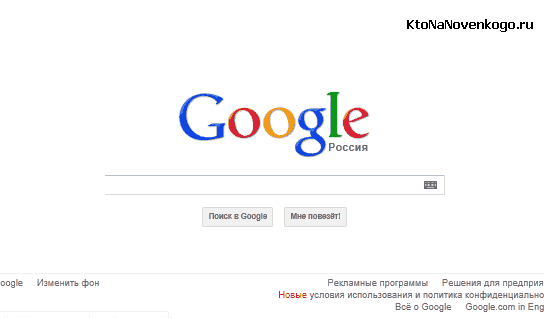
Как говорится, почувствуйте разницу. В далеких девяностых все сайты и порталы пестрели разноцветными баннерами и надписями (аля сегодняшний Терехофф, да и я тоже не без грешка), что вызывало неподдельное раздражение у Ларри и Сергея. Поэтому, работая над дизайном главной страницы своего поиска, Сергей Брин использовал принцип минимализма, позволив себе лишь разрисовать буквы логотипа Гоогле в разные цвета.
Получилось хорошо, но был курьезный случай, когда тестовая группа, которой была поставлена задача что-то там найти через Google.com, несколько минут сидела перед экраном компьютера с довольно озадаченным видом. Оказывается, что они ждали когда же главная страница загрузится полностью (не было в интернете тогда сайтов в стиле минимализма).
Поэтому разработчикам пришлось увеличить шрифт копирайта внизу главной, чтобы он стал для пользователей своеобразным маркером окончания загрузки страницы.
А знаете что самое интересное в истории Гугла? То, что она могла бы закончиться примерно на этом месте. Как я уже упоминал ранее, для Сергея и Ларри главным было получение качественно образования, а работа над поисковой системой занимала все время и не оставляла его на учебу. Как вы думаете, что они придумали?
Ну, конечно же, продать все права на использование технологии PageRank и поставить крест на развитии проекта Google. Что примечательно, они предлагали свой продукт за сравнительно небольшую сумму в один лимон зеленью таким известным в то время титанам, как AltaVista, Yahoo.com и другим, сейчас уже не пребывающим на слуху, компаниям. Что примечательно, AltaVista даже сумела сбить цену на четверть, но в итоге все равно не купила его.
После этого Ларри Пейдж и Сергей приняли решение забить все-таки на учебу (многие из нас принимали такое же решение даже в виду гораздо менее весомых причин) и заняться вплотную доработкой и продвижением в жизнь новаторской, по тому времени, поисковой системы с никому неизвестным названием Гоогле.
Все упиралось в то, что для развития нужны были деньги на покупку серверов. Без этого двигаться дальше было бы невозможно, ибо даже при сравнительно малой на тот момент популярности Гугла он требовал уже довольно больших ресурсов для хранения и обработки на лету многочисленных запросов пользователей.
Итак, напомню, что домен был зарегистрирован в сентябре 1997 года, а ровно через год была уже зарегистрирована компания Google Inc. За несколько дней до этого Сергею Брину и Ларри Пейджу удалось получить свой первый чек на развитие от грамотного дядьки из Sun Microsystems. Говорят, что при выписке чека, компании как таковой еще не существовало, поэтому, указав в чеке название, уже при официальной регистрации компании пришлось ориентироваться именно на это название (иначе возникла бы проблема с обналичиванием денег).
Данная сумма была потрачена на покупку комплектующих и сборку новых серверов, которые были призваны обрабатывать постоянно возрастающее число запросов к Google.com, ибо популярность поисковика росла. Хотя даже несмотря на то, что в конце 1998 года на их главной странице по-прежнему красовалась надпись Beta, ведущие СМИ, пишущие про IT технологии, уже обратили внимание на молодую поисковую систему и высказали свои положительные отзывы о ее работе.
Популярность Гугола росла и полученные сто тысяч зелени очень быстро были истрачены на комплектующие. Ребята опять уперлись в стену, но им опять-таки удалось совершить невероятное — получить двадцать пять лямов зелени на развитие от двух венчурных контор, при этом не загнав себя в кабалу (оставив за собой полное право управления компанией и решения всех вопросов по своему собственному усмотрению). Молодцы, чего уж говорить.
Я опять не устаю проводить параллели между развитием буржуйского и российского поиска. Аркадий Волож и Илья Сегалович точно так же вынуждены были искать деньги на развитие у инвесторов, и точно так же сумели отстоять свое право управлять компанией по своему собственному усмотрению.
Вообще, между идеологами Яндекса и Гугла очень много общего (умные, образованные и интеллигентные люди) и главное, что их объединяет — желание в первую очередь развивать свои проекты (и ловить от этого кайф), а не тупо заколачивать бабло (хотя, и не без этого):

Понятно, что бесконечно так продолжаться не могло. Проект должен приносить доход или хотя бы находиться на уровне самоокупаемости. Правда есть примеры крупных интернет проектов, не зарабатывающих на своем детище. Это прежде всего Википедия. Однако ей помогают держаться на плаву другие состоятельные компании, владельцы которых понимают значимость Вики для интернета.
Такой понимающей компанией и является Google, пожертвовавшая несколько лямов на Вики. Кстати, владелец социальной сети «В контакте» тоже грозился недавно передать Википедии около ляма зелени, что делает ему честь и ставит в один ряд с Великими.
Но Гоогл (равно как и Яндекс) не решился пойти по пути бессребреников. Сергею Брину и Ларри Пейджу пришлось немного поступиться принципами неприятия размещения рекламы на страницах своего детища. Но сделали они это очень элегантно и их способ предоставления рекламы несет гораздо больше позитива пользователям, чем повсеместно используемые тогда баннеры.
Я говорю про контекстную рекламу Гугл АдВордс, которая представляет из себя текстовые строки со ссылкой на сайт рекламодателя. Причем объявления показываются в строгом соответствии с тем, какой именно запрос ввел пользователь в поисковой строке. Такая реклама не создает дискомфорта для пользователей, но зато приносит ей поистине фантастические доходы:
Кстати, Гоогл не жадный и позволяет зарабатывать на контекстной рекламе любым желающим вебмастерам показывая ее на своих сайтах. Правда за это он оставляет себе около половины суммы, которую выплачивает рекламодатель, но это вполне логичная плата за использование базы рекламодателей. Многие вебмастера живут одним лишь желанием пройти регистрацию и модерацию в Adsense.
Раз уж мы тут сравниваем периодически Google и Яндекс, то скажу, что у зеркала рунета способ заработать на жизнь ничем не отличается от лидера мирового поиска — все тот же контекст, но называется все это уже Яндекс.Директ. Ну, и вебмастерам он тоже позволяет зарабатывать на своем контексте (за половину маржи) и для этого была создана Рекламная Сеть (РСЯ), с которой можно работать как напрямую, так и через центры обслуживания партнеров (я работаю через Профит Партнер).
Гугл свой контекст запустил в 2000 году, а Яндекс — в 2002. Вопрос о первоисточнике идеи, наверное, не возникает. Хотя, родоначальник не сразу стал использовать схему оплаты только за клики, совершенные пользователями по объявлениям рекламодателей, а шел к этому несколько лет.
Ну, а идея организации непрерывного аукциона по продаже тех или иных поисковых запросов (при вводе которых будут показываться объявления рекламодателей) вообще является гениальным решением, позволяющим существенно увеличить доходы и максимально упростить и облегчить схему ценообразования. Как говорится, попали в яблочко.
За 2001 год Google.com оказался в плюсе аж на семь лямов зелени, а сейчас прибыль лидера мирового поиска исчисляется миллиардами. Кроме американской аудитории он уже давно ориентирован на весь мир. Поиск можно осуществлять на 200 языках на различных региональных сайтах. Кроме, собственно, технологий поиска, данная компания за время своего существования открыла массу сопутствующих сервисов, начиная с Гугл картинок и Ю-туба, а заканчивая самым популярным браузером в мире.
Он уже даже посягнул на царствование самой популярной в мире социальной сети Facebook, противопоставив ей свое детище под названием Google+. Даже на главенство Мелкософта на рынке операционных систем он готов замахнуться, разрабатывая свою Ос на основе Хрома. Ну, а на рынке мобильных операционных систем он уже совершил переворот своим Андроидом, который сейчас установлен на большинстве планшетов и смартфонов.
Я уже писал, что Яндекс в 2011 вышел на IPO и очень успешно стал ОАО с довольно большой маржой для себя. В 2004 году аналогично на IPO вышел и Гугол, хотя и не столь успешно, как оно могло бы быть. Однако в обоих случаях идеологи компаний по-прежнему остались у руля и могут выбирать самостоятельно пути развития и не идти ни у кого на поводу. В принципе, это хорошо, ибо энтузиазма обеим командам не занимать.
Google.ru — особенности продвижения и Seo оптимизации
Теперь давайте немного поговорим о продвижении сайтов под Гугл и чем оно отличается от аналогичного действа под Яндекс. Конечно же, по большому счету, делать особые различия при Seo оптимизации под эти поисковые системы не стоит, но они имеют свои особенности и разные факторы ранжирования по разному в них учитываются.
Ну и, думаю, понятно, что речь пойдет о русскоязычном Google.ru, ибо .com осуществляет ранжирование по другой формуле и там учитываются несколько другие факторы (отсталые мы, что ни говори). Про доли на рынке поиска рунета я уже писал:
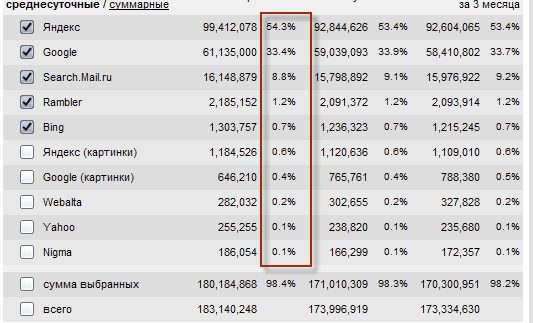
Но стоит учитывать тот факт, что продающие запросы гораздо более часто задаются в Яндексе (может быть даже в разы чаще), а вот доля информационных запросов выше в буржуйском аналоге. Поэтому блоги вроде моего могут иметь долю переходов с Гугола даже выше, чем с зеркала рунета.
Все это связано с таргетингом аудитории этих поисковых систем. Пусть на меня никто не обижается, но в Яндексе превалируют обыватели, желающие что-то купить или развлечься, а в детище Пейджа и Брина сидят интеллектуалы (ну, типа того), которые желают что-то узнать. Лично я по привычке пользуюсь отечественным продуктом, а вот если он мне не дает исчерпывающего ответа, то обращаюсь уже к буржуину, и он меня, как правило, не разочаровывает.
Наверное, все вы уже прочувствовали на себе то, что Google не только быстрее работает, быстрее индексирует новые страницы, но и то, что в нем можно гораздо быстрее вылезти в Топ.
Основным фактором тут является, скорее всего, то, что Яндекс некоторое время назад ввел лаг (от нескольких месяцев до года, в зависимости от тематики поискового запроса), по истечении которого начинают учитываться проставленные (купленные) на документ обратные ссылки (таким образом он повысил свои доходы, ибо в период, необходимый на продвижение в Топ, владелец сайта будет вынужден привлекать пользователей через Яндекс Директ).
У Гоогле же этот лаг значительно меньше (если вообще есть) и в Топ можно выйти довольно быстро, имея хороший и не заспамленный текст на приличном сайте, а также определенное количество внешних ссылок.
- Немного второстепенный факт, но мне вспомнилось, что буржуйский поиск будет учитывать анкоры всех ссылок (из одной и той же статьи) ведущих на одну и ту же страницу, только если это будут хеш-ссылки.
Ну, и опять же, как мне кажется, Гугл больше Яндекса любит тексты подобные тем, что вы можете встретить на этом блоге — большие по объему и структурированные (заголовки с помощью тегов H1-H6, списки OL или UL, ну и еще можно было бы таблицы использовать для разнообразия).
По любому структурированные тексты дадут вам преимущество. Поисковики учитывают плотность ключей в пассажах, а списки, таблицы и заголовки позволяют создать большее количество пассажей, а значит можно будет использовать большее число вхождений ключей без риска попадания под фильтр за переоптимизацию текстов.
- В Google регионы представляют из себя страны, а не отдельные субъекты России или Украины, как в Яндексе. Поэтому следует это учитывать, а так же учитывать те факторы, по которым он может отнести ваш сайт к тому или иному региону (подробнее читайте чуть ниже).
Еще у него есть одна особенность — он большее внимание при ранжировании уделяет показателям конкретной вебстраницы (релевантность которой рассчитывает) и меньшее внимание уделяет показателям всего сайта целиком. Имеется в виду в сравнении с Яндексом, для продвижения в котором очень важно иметь трастовый ресурс.
Что это нам дает? Получается, что молодому проекту не имеющему достаточной трастовости гораздо проще пробиться в Топ Гугла, чем в Топ зеркала рунета, при условии, что статья будет качественной, оптимизированной и хорошо прокачанной ссылками с качественных доноров (например, из биржи вечных ссылок gogetlinks или из биржи статей miralinks) и с внутренних страниц этого же сайта (внутренняя перелинковка в полной мере и наравне с внешними ссылками способствует наращиванию статического и динамического веса страницы).
Например, мой блог по многим частотным запросам находится в Топе Гоогла, но не в Топе зеркала рунета. Получается, что либо общей трастовости ресурса для этого еще не хватает, либо обратные ссылки еще не начали работать из-за используемого лага, либо эти документы находятся под фильтром за переоптимизацию текстов (что тоже возможно).
- Поисковая система придает большое значение наличию и количеству входящих ссылок (внешних и внутренних) на документ и больше уважает прямые вхождения поискового запроса. В Яндексе же ссылочный фактор имеет несколько меньшее значение и там очень важно будет не переборщить с прямыми вхождениями, побольше использовать словоформы и разбавления. Но, опять же, поисковые алгоритмы развиваются и со временем они будут приближаться к тому, что мы сейчас имеем в мировом поиске с расширением.com.
- Сам не проверял и не прочувствовал, но считается, что сквозные ссылки (проставленные со всех страниц ресурса, например, в сайдбаре донора) хорошо работают именно в Гугле, т.к. для него важным является именно количественное соотношение ссылочной массы. Yandex же попросту склеивает сквозняки и вряд ли их суммарный вес превышает вес обычной внешней ссылки с одной единственной страницы этого же самого донора.
Поисковый трафик — это манна небесная для любого владельца веб-ресурса, самый стабильный и, как правило, основной источник притока посетителей на сайт. Например, у меня он составляет порядка трех четвертей от общей посещаемости. Поэтому я не устаю повторять почти в каждой статье — отнеситесь со всей серьезностью ко всем малейшим нюансам поисковой оптимизации. То, что вам может показаться пустяком или же излишеством, может стать ключевым моментом в успешности вашего проекта.
Правда в соблюдении всех требований есть тоже не мало нюансов, главный из которых — это быстрое изменение правил игры поисковиками. Конечно же, основные базовые и основополагающие приемы оптимизации остаются неизменными (во всяком случае в течении продолжительного времени), но тем не менее Яндекс характерен именно резкой сменой отношений к тем или иным способам накрутки.
Раньше с Гуглом можно было чувствовать себя более спокойным, ибо ее так не лихорадило. Но пришла весна 2012 года и вместе с ней пришел и зоопарк: Пингвин и Панда. Они пришли сразу в мировом масштабе и затронули все страны. После этого поисковую выдачу начало постоянно трясти и практически каждый второй сайт в мире в той или иной степени пострадал от этих фильтров.
Это было как гром среди ясного неба. Все дружно ругали Яндекс, а потом резко переключились на его буржуйского конкурента. Пингвин стал наказывать на плохое качество входящей ссылочной массы на сайт, а Панда — за переоптимизацию контента. Складывается такое ощущение, что разработчики поставили перед собой задачу — сделать продвижение под этот поисковик максимально непредсказуемым (сегодня ты в Топе, а завтра в...). Зачем им это нужно?
Скорее всего причиной являются деньги. Если SEO не будет давать хоть каких-нибудь гарантий и стабильности, то все начнут еще более активно использовать альтернативный метод, а именно покупать контекстную рекламу. Собственно, так сейчас и происходит. Пока существует монополия поисковиков ситуация будет все больше и больше ухудшаться.
Вебмастерам нужно объединяться в профсоюзы с возможностью бойкотировать действия монополий, а все остальное — «разговоры в пользу бедных». Без сайтов не будет и поиска, ибо они фактически на нас паразитируют. Ситуация полностью соответствует положению владельца бизнеса и армии рабочих в нем задействованных. Последние полностью бесправны без объединения в профсоюзы . Но на осознание и организацию требуется время...
Но тем не менее, поисковый трафик формируется именно с Яндекса и Google, причем во многих случаях эти две поисковые системы будут давать примерно одинаковое количество посетителей. А значит нужно будет учитывать нюансы оптимизации под обеих.
Глобальный (Google.com) и региональный поиск (.ru, .ua)
Начнем с того, что Гугол позиционирует себя как система поиска по всему мировому интернету. В связи с этим у него имеется как глобальная поисковая система .com , которая работает с англоязычными пользователями со всего мира, так и региональные поисковики (например, .ru или .com.ua, относящиеся к России и Украине).
В общемировом google.com, кроме огромного количества посетителей, имеет место быть и огромное количество проиндексированных сайтов в базе (там собрана огромная коллекция), а отсюда следует вывод о том, что там будет очень сложно попасть в топ выдачи. Кроме этого, в мировом поисковике практически невозможно будет за короткое время занять место в топе по высокочастотным запросам.
Это связано в первую очередь с большим количеством фильтров, которые используются. Глобальный поисковик .com использует пессимизацию, осуществляя тем самым жесткий контроль за качеством доноров (сайтов, с которых будут проставлены ссылки на ваш ресурс), за развитием вашего проекта, за скоростью наращивания ссылочной массы и т.п. вещами.
В результате этого в топе по высококонкурентным запросам будут находиться только ресурсы, существующие и развивающиеся довольно продолжительное время (достаточное, чтобы поиск убедился в их состоятельности).
В то же время, в региональных поисковиках (например, google.ru или .com.ua) вполне возможно попасть в топ по высокочастотному запросу уже через один-два месяца после создания проекта. Связано это с тем, что там не работают многие из фильтров, используемые в .com, или же работают не по полной программе.
Но он постепенно переносит и усиливает фильтры своих региональных поисковиков, поэтому с этой проблемой тоже придется столкнуться в ближайшее время при продвижении. Собственно, это уже произошло. После прихода Панды и Пингвина все стали равны.
При всей своей навороченности и совершенстве, поисковая система не может гарантировать стопроцентно правильного определения региона, к которому принадлежит ваш ресурс. В результате этого может сложиться довольно неприятная ситуация, заключающаяся в отсутствии вашего сайта в поисковой выдаче желаемого регионального поисковика Гугла (продвигались, допустим, под Англию, а поиск решил, что ваш сайт принадлежит Австралии, в результате чего, в английской выдаче вашего проекта не будет).
Даже язык контента вашего ресурса не может служить гарантом правильности определения региона. Увы и ах, даже то, что ваш сайт на албанском, вовсе не означает, что он появится в албанской выдаче. Каким же образом он определяет регион, к которому принадлежит тот или иной проект, и как мы можем со своей стороны помочь ему сделать правильный выбор?
Тут все довольно просто. В первую очередь, при попытке отнести ресурс к тому или иному региону, поисковик смотрит на доменную зону, к которой относится этот интернет-проект. Если домен явно указывает на региональную принадлежность (например: зона .RU — Россия, .DE -Германия или .US — штаты), то поисковая машина выберет регион для сайта именно полагаясь на это.
Поэтому, если вы используете для своего сайта доменное имя, принадлежащее к зоне той или иной страны, то проблем с неправильным выбором региона для вашего ресурса возникнуть не должно.
Но ваш ресурс вполне может иметь домен, принадлежащий к какой-либо общей зоне (вроде .COM или .NET). Чем же руководствуется поиск при выборе региона в этом случае? Оказывается, что он анализирует IP адрес сервера хостинга, на котором расположен данный проект. Какой стране будет принадлежать этот IP адрес, к такому региону и будет отнесен сайт.
Поэтому при создании нового проекта, ориентированного на продвижении в поисковой машине определенного региона (страны), вам следует озаботиться тем, чтобы он сразу и безошибочно определил регион вашего сайта. Для этого вам нужно будет либо выбрать имя в доменной зоне нужного региона, либо использовать хостинг с IP адресами серверов нужной вам страны.
Если для вашего ресурса он не верно определил региональную принадлежность, то вы, в принципе, можете добавить к ключевым словам тех поисковых запросов, по которым вы продвигаетесь, дополнительное слово, уточняющее региональную принадлежность (например, «поисковое продвижение Россия»).
И в этом случае ваш вебсайт будет участвовать в региональной выдаче Гугла для нужной вам страны (Россия), но уже не по высокочастотному запросу («поисковое продвижение»), а по гораздо менее высокочастотному («... Россия»).
Если же вы, наоборот, хотите создать ресурс, ориентированный на множество стран, то обязательно выбирайте доменное имя из общей зоны (вроде .COM или .NET), а хостинг выбирайте с IP адресом той страны, из которой ожидается наибольшее количество посетителей.
Задание региона сайта в поисковой системе Яндекс
Поисковая система Яндекс с недавних пор тоже стала различать сайты по регионам. Но в этом случае, под регионами понимаются не страны, а области России. Региональная принадлежность сайта определяется, основываясь на упоминании региона на его страницах или же опираясь на настройки, которые сделал владелец ресурса в панели вебмастеров Яндекса.
После того, как вы войдете со своего аккаунта в панели вебмастеров, вам нужно будет выбрать из левого меню пункты «География сайта» — «Регион»:
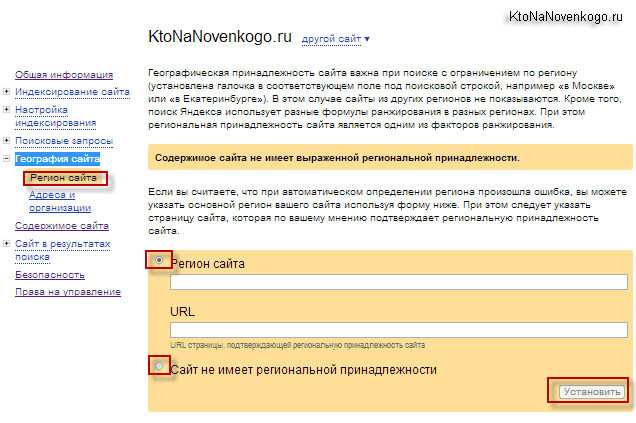
Как вы можете видеть из приведенного выше скриншота, для моего блога Яндекс не определил регион: Содержимое KtoNaNovenkogo.ru не имеет выраженной региональной принадлежности. В противном случае нужно будет ввести в соответствующее поле желаемый регион сайта и указать в расположенном ниже поле URL страницы своего блога, где будет встречаться название этого региона.
Еще раз обращу ваше внимание, что выбирать хостинг следует не только из соображений правильности определения региона (с IP адресом той страны, в выдаче которой вы хотите видеть ваш ресурс), но и по степени его надежности. В плане оптимизации сайта надежная и стабильная работа хостинга очень важна, ибо постоянно повторяющаяся недоступность сайта для ботов поисковых систем, в результате Ddos-атак на сервера или же других сбоях хоста, может привести к понижению позиций сайта в выдачах поисковых систем.
Поэтому подойдите со всей ответственностью к выбору стабильного хостинга для вашего проекта. Лично мне, на данный момент, после ряда экспериментов больше всего импонирует провайдер InfoBox, мои первые впечатления о котором вы можете прочитать в статье по ссылке.
Если говорить кратко, то у InfoBox, на данный момент, очень много бонусов (30 дней халявы плюс бесплатный домен навсегда, в случае оплаты хостинга на три месяца) и великолепная служба техподдержки.
Если вы думаете, что я здесь распинаюсь по поводу данного хостинга лишь в надежде получить дивиденды с рефералов, то спешу вас разуверить, ибо партнерская программа у InfoBox существует только для юридических лиц, а я — лицо физическое. Просто действительно не плохой хостинг и я вам искренне, без всякой выгоды для себя, его советую.
Как работает поисковая система Гугл
В принципе, каких-либо особенных отличий в логике работы Google от работы других поисковиков нет. Я уже писал довольно подробную статью про алгоритмы, используемые поисковыми системами, и практически все это можно будет отнести и к нашему герою. Поэтому, не останавливаясь на деталях, попробую вкратце описать, как работает все это дело с точки зрения определения документов наиболее релевантных тому или иному запросу.
Итак, в Гугле, как впрочем и в других поисковых системах, используются два основных принципа, руководствуясь которыми он определяет позицию того или иного документа (под документом я имею в виду вебстраницу) в выдаче по определенному запросу. Во-первых, он анализирует текстовое содержимое документа, определяя таким образом его тематику и производя подсчет плотности употребления в документе ключевых слов.
Во-вторых, он анализирует обратные ссылки, проставленные на этот документ с других ресурсов на предмет их тематичности, и учитывает те слова, которые были использованы в анкорах (текстах) этих обратных ссылок.
И уже на основании двух этих факторов (содержимого документа и ссылочного ранжирования) он определяет позицию сайта в выдаче по тому или иному поисковому запросу. Google ведет поиск не по реальным сайтам, а по так называемой коллекции, которая представляет собой все проиндексированные поисковиком документы в сети.
Индексация представляет из себя считывание содержимого страницы и сохранение всех содержащихся на ней слов в виде обратных индексов, где учитывается расположение данного слова в документе и частота его употребления.
В поисковую базу добавляются также и сохраненные копии документов, на основании которых затем поисковая система будет формировать сниппеты под те или иные запросы. Сканированием сайтов в сети занимаются так называемые поисковые боты, которые переходят от документа к документу по ссылкам, ведущих с этих документов.
Каким образом поисковые боты Гугла смогут найти новые страницы ресурса? Во-первых, задание на посещение того или иного документа поисковый бот может получить после того, как вы добавите адрес той или иной страницы в аддурику. Во-вторых, бот может проиндексировать документ, перейдя на него по ссылке с другого или же с вашего же ресурса.
Отсюда можно сделать вывод, что хорошая и продуманная навигация будет полезна не только вашим посетителям, но и сможет ускорить индексацию сайта поисковыми системами. Одним из способов такого ускорения служит создание карты сайта как в формате HTML (видимую), так и в формате XML, предназначенную именно для ботов.
Обратные ссылки на данный документ собираются поисковой системой при индексации тех документов, на которых они были проставлены. В результате, при вводе пользователем определенного запроса в поисковую строку, он проанализирует и найдет все документы, которые имеют хоть какое-нибудь отношение к данному запросу, а затем уже среди них будет проведена сортировка по релевантности (соответствию) документов данному запросу.
При расчете релевантности учитывается содержание документа, а так же учитывается количество и качество обратных ссылок ведущих на него.
Основной и дополнительный (supplemental) индексы Гугла
Материальные возможности компании Гугл (как денежные, так и аппаратные) позволяют этой поисковой системе индексировать все страницы подряд и хранить их в своей индексной базе (коллекции). Более мелкие поисковики, в том числе и Яндекс, не могут позволить себе такой роскоши и удаляют из индекса дублированный контент (копипаст, например) и прочие не качественные документы.
Но наш герой не такой — он обладает настолько большими мощностями, что способен хранить в своей коллекции все проиндексированные им в сети документы (вебстраницы).
Правда для вебмастеров от этого пользы мало, ибо база Google состоит из двух частей: основного индекса и дополнительного (supplemental, его еще иногда называют сопливым или же попросту соплями). Так вот, он производит поиск только по документам, находящимся в основном индексе, а документы (вебстраницы), которые попали в сопли, в поиске практически не участвуют, разве что только в том случае, если в основном вообще не найдется релевантных запросу ответов. А вероятность такого случая крайне мала.
Я уже писал о специальном онлайн сервисе, позволяющем определить, сколько страниц вашего ресурса находится в основном индексе и, следовательно, косвенно оценить качество вашего веб-проекта. Хотя вы можете сами, без использования каких либо сервисов, посмотреть, сколько страниц вашего сайта находится в основном индексе Гугла.
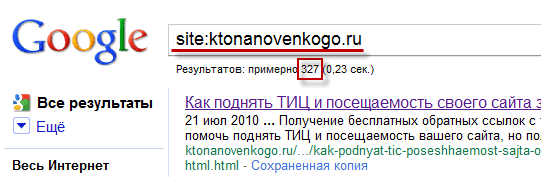
Для начала введите в строку поиска следующий запрос:
site:ktonanovenkogo.ru
заменив доменное имя моего блога на свое. В результате чего откроется страница с выдачей, где будут перечисленные все страницы вашего ресурса находящиеся в индексе. Здесь будут приведены документы не только из основного, но и из дополнительного (supplemental) индекса. Под строкой запроса будет приведено общее количество страниц вашего ресурса, проиндексированных этим поисковиком:
Теперь, запомнив суммарное количество страниц в индексе, видоизмените запрос в поисковой строке Гугла на следующий:
site:ktonanovenkogo.ru/&
заменив доменное имя моего блога на свое. В результате откроется страница с выдачей, где будут перечисленные только те страницы вашего сайта, которые находятся в основном индексе:
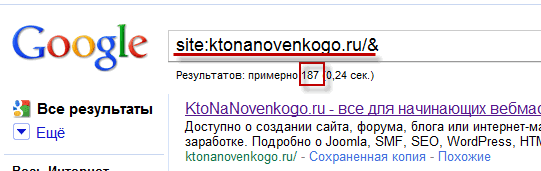
Только по этим документам, находящимся в основном индексе и будет вестись поиск. О том, какие причины могут привести к попаданию страниц в дополнительный, а не основной индекс, я уже писал, но немного повторюсь и, пожалуй, добавлю несколько новых возможных причин, почему страница может оказаться в соплях:
- не уникальность контента страницы (полное или частичное дублирование текста другой страницы вашего же ресурса или же какого-либо другого)
- слишком мало текста на вебстранице (картинки, хотя они и учитываются поиском по изображениям, а так же гиперссылки не в счет). Не могу сказать точно, сколько текста в символах или словах должно быть в документе для вывода его из соплей Google, но вот о том, каков должен быть размер текста для его наилучшей оптимизации под поисковые запросы, я уже писал
- страница может попасть в дополнительный индекс, если вы забыли прописать для нее мега-теги Title или Description
- также сопли грозят страницам, у которых мега-теги Title или Description не уникальны или же состоят из одного слова
Комментарии и отзывы (27)
Дмитрий, поправьте: «увеличить шрифт копипаста внизу главной страницы». Думаю, шрифт копирайта 😉
Да, Яндекс вообще последнее время падает в глазах вебмастеров!
Спасибо.Лаг Яндекса для меня -это открытие.
«Кстати, владелец социальной сети «В контакте» тоже грозился недавно передать Вики около ляма зелени, что делает ему честь и ставит в один ряд с Великими.»
Какую нафиг честь? если ни копейки не отправлено? — «тоже грозился недавно передать Вики около ляма зелени». Грозиться и я могу, что передам завтра миллиард вики, и что? это делает меня наравне с великими?
Абсурд.
Интересная статья. Вместе с тем масса спорных моментов. С google.com картина немного другая. Например, на один и тот же запрос — выдача будет разная даже у пользователей, которые находятся в пределах одного дома. И учет ссылок входящих и выходящих менее важен, чем частота появления новых авторских статей на сайте. С русским Гуглом не знакома.
Все с интересом и удовольствием читаю вот такие успешные истории развития. Спасибо за весьма поучительное повествование.
Было интересно увидеть интервью Брина в Москве.
Историю знать необходимо, а тем паче Гугла!
Спасибо интересная статья. Как то раньше и не задумывался о создании моей любимой ПС, прочитал и статью о истории Яндекса, очень интересно. Побольше пишите на такие темы.
C Google как-то спокойней оптимизаторам работать, хоть и нововведений много, при нормальном ссылочном трафик только растет.
Яндекс же постоянно какие-то выкрутасы придумывает. Кстати странно, что вы еще не в каталоге.
Журналист НТВ насмешил — «интернет может обрушится» и web-3.0 по паспорту:)
Даже не начав толком читать статью — интересная тема.
В яндексе сидят одни домохозяйки и вебмастера. Нормальные люди используют гугл =))
Не поленюсь и поделюсь статьей во всех кнопках =)
Интересная статья! Особенно подтверждение того факта, что как не прискорбно Яндекс теряет свои позиции.
Я пользуюсь гуггловским поисковиком!!! Я интеллектуал ))))
А вообще очень познавательная статья. Я тоже заметил, что гуггл больше опирается на ссылки, тогда как у Яши они не имеют главный приоритет, там, скорее всего на первый план выходят ПФ или скорее всего некий микс различных факторов ПФ + ссылочную + Внутренняя оптимизация
Добрый вечер мне Ваш блог посоветовали как лучший блог по развитию и заработку денег в итернете. Я новичек в этом деле возможно Вы сможете что-то посоветовать мне буду Вам очень признателен.
Спасибо.
Эта статья (впрочем, как и все остальные в этом блоге) была бы ещё интереснее, если бы в ней было меньше грамматических ошибок. Автор пишет серьезные и интересные статьи — и с таким количеством элементарных ошибок. Бедный русский язык, на нем даже в России перестают грамотно писАть.
1). Как человеку, чей сайт занимается продажами, абсолютно не нравится поиск из-за отсутствия региональности. Найти что-то интересное это да, а найти товар на уровне собственного потребления или по работе (купи-продай) невозможно и в 99% случаев не нужно(у вас где-то ранее упоминалось про это).
Хотя есть категория граждан, кто не найдя товара в своем регионе ищут его по всей стране именно как раз при помощи гугла.
2). Замечал «косяки» (или его особенности) , когда по запросу один и тот же сайт занимает, например, 1 и 18 позиции, другой в этом же запросе 11 и 32 место и т.д.
3). В адреса (типа «Результаты поиска на Картах Google по запросу ...») указываются некорректные телефоны т.е. 5 лет назад у нас сменился код города, а поисковик об этом всё еще не знает (вместо 8 (831) 210- ... — ... пишет 8 (8312) 10- ... — ...) и естественно, люди звонят не по тем номерам; кто подогадливее могут методом подбора всё-таки правильно набрать, но не все.
Есть еще один очень неприятный «косяк» результатов поиска. Ресурсы, взявшие текст с какого-то сайта и ссылающиеся на него как на первоисточник, ранжируются более высоко, чем этот самый первоисточник. Этого я никак понять не могу (((
Вот же блин, а я в те годы торговал на рынке женскими труселями, чтобы выжить и семью прокормить, а вот чем надо было заниматься-опередили меня ребята, обскакали! 🙂
Дима, обнаружил, что при отправке этой статьи в твитер (ты там еще пишешь:"очень обяжете, если") — короче! твитер при добавлении пишет в окне отправки:
Ой! Ссылка в вашем твите ведет на страницу, которая представляет опасность или содержит спам.
Ребят, спасибо большое за столь развернутые комментарии на тему вашего отношения к поисковой системе Гугл. Что-то почерпнул для себя, надеюсь, что и еще почерпну.
abaiti: о, спасибо за сигнал. Недавно еще все работало на ура. Видать попал я в их черный список. Попробую решить проблему переговорами с администрацией.
да, их поиск радует начинающих, сразу индексирует и даже выдает в первых позициях, но со временем почему то все кардинально поменялось, теперь в Яндексе первые позиции, а гугл в хвосте, с чем это может быть связанно? Одна и та же статья была в топе, а через полгода далеко от него
Как такое может случиться: в поисковиках в любая чушь сразу попадает в индекс если это ссылка сквозная или одного клика, а все остальные полностью уникальные написаные самостоятельно — нет. Блогу 2 месяца. Причем в гугле страница находящаяся в соплях выдается в топ 1, если задать поиск по точному названию статьи. Хотя само название состоит всего из четырех слов, а в яндексе ее немогу найти вообще.
Отличная статья, много чего узнала. Но вы про минимализм не подчеркнули одно, ведь у Яндекса есть ya.ru где только поиск и нет баннеров разве это не минимализм? а yandex.ru там уже все, и новости и погода и другие сервисы вместе.
Дмитрий,
большое спасибо за столь вразумительные статьи. Очень рад, что нашел ваш ресурс. Очень много действительно полезной информации.
ого, однако история у Гугла — неожиданный объем информации. все не осилила, но в закладки сохранила... 😉
А действительно гугл каким-то образом поощряет сайты, которые отправляют посетителей с Internet Explorer менять браузер?
Я только недавно поставил себе на сайт пользовательский поиск. Очень хочется посмотреть — как и что он выдает именно по моему сайту, но где-то прочитал, что Адсенс банит даже за то, что сам пользуешься этим поиском. так же как и за клики по рекламе. Это правда?
Ваш комментарий или отзыв