All in One SEO Pack и внутренняя поисковая оптимизация блога на WordPress (метатеги Canonical, Description и Title)
Здравствуйте, уважаемые читатели блога KtoNaNovenkogo.ru. Пользователям WordPress очень повезло, т.к. для этого движка имеется масса замечательных плагинов, с помощью которых осуществляется поисковая оптимизация сайта или же, другими словами, SEO.
Рассмотренный нами ранее WP плагин Google XML Sitemaps позволяет существенно ускорить индексацию материалов вашего блога Яндексом и Гуглом, а сегодняшний наш герой плагин All in One SEO Pack, о котором я и собираюсь рассказать в этой статье, поможет нам увеличить трафик (количество посетителей) с этих самых поисковиков (ну, по крайней мере не уменьшить, особливо если имеющиеся у него косяки поправите, о коих читайте ниже).

А поисковый трафик является самым желанным для любого проекта, ибо он стабилен (если под фильтр не влетите) и для его поддержания не надо будет постоянно анонсировать свои материалы в различных социальных сетях и сервисах, как это происходит при SMO (Social Media Optimization — привлечение посетителей с социальных медиа). Но для того, чтобы получить на свой сайт постоянный и высокий поисковый трафик, вам придется заняться внутренней оптимизацией контента на вашем проекте.
Внутренняя поисковая оптимизация сайта
Кто бы что не говорил, но трафик с поисковиков является главным источником посетителей для любого ресурса (что такое трафик и как его мерить?), и стоит постараться сделать его как можно большим. Если рассматривать такое понятие, как внутренняя поисковая оптимизация (то, что мы можем настроить на самом проекте), то самым весомым аргументом, учитываемым поисковиками в вашу пользу, может служить заголовок вебстраницы — Title .

Если он составлен грамотно и в него включены ключевые слова, по которым вы хотите занять высокую позицию в поисковой выдаче, то и количество посетителей с поисковиков будет выше, чем при неграмотном составлении заголовка. Правда тут следует учесть, что метатег Title хоть и является самым весомым аргументом при оценке релевантности странички вашего вебсайта поисковому запросу, но далеко не единственным.
Для успешного продвижения в поисковых системах нужно учитывать все нюансы, на которые обращают внимание Гугл и Яндекс, а именно, по мере убывания важности:
Прописать в HTML коде оптимизируемых вебстраниц нужные метатеги
- заголовок TITLE — самый важный метатег, в который следует включать одно или несколько (но не перегибать палку) ключевых слов, по которым вы хотите продвинуть данный документ
- DESCRIPTION — не влияет на ранжирование вашей странички в поисковиках напрямую, но на первых порах может ими использоваться в качестве сниппета , который находится под ссылкой вашего ресурса в поисковой выдаче и представляет из себя кусочек текста, выбранный поисковиком (как правило, с выделенным запросом пользователя), как отражающий суть вебстраницы, на которую ведет ссылка
- KEYWORDS — на данный момент не учитывается поисковиками, но возможно, что им может не понравиться, если слова, прописанные в keywords, не будут найдены ими в документе. Поэтому, если вы будете добавлять этот метатег, то позаботьтесь о корректности прописываемых в нем слов
- Тэги акцентирования
- Внутренние заголовки (Html теги Н1, H2), в которых опять же должны присутствовать ключевые слова (без фанатизма в плане ключей и в плане количества внутренних заголовков).
- Крайне осторожно подходите к выделению тех же ключевых слов и словосочетаний жирным или курсивом в тексте документа (теги STRONG и EM). Старайтесь, чтобы эти выделения были удобны читателям и их было бы не много. Ключи достаточно выделить один раз, и то можно в разбавленном виде.
- Атрибуты ALT и Title для тэга картинок IMG — обязательно прописывайте ALT, но включайте в него ключевые слова очень аккуратно, ибо можно переборщить.
Правильная внутренняя перелинковка документов — поисковики, при определении статического веса (PageRank) той или иной вебстраницы вашего ресурса, учитывают не только внешние ссылки на них (с других ресурсов), но и внутренние ссылки (со страниц вашего же ресурса).
Стоит очень серьезно подойти к написанию текста ссылок (здесь читайте про анкоры в SEO). Следует отразить в этих ссылках ключевые слова, по которым вы хотите продвинуть ту вебстраницу, на которую эта ссылка ведет. Опять же без фанатизма. И обязательно прочитайте приведенную статью про анкоры.
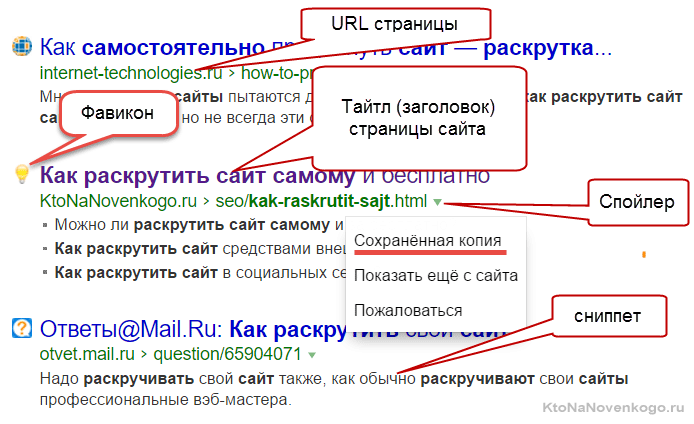
Мета-теги — специальные команды, прописываемые в начале каждой странички вебсайта. Вариантов метатегов достаточно много, но все они прописываются в области между открывающим и закрывающим тегом HEAD. Посмотреть их можно, щелкнув правой кнопкой мыши в окне браузера и выбрав пункт контекстного меню «Исходный код» в Опере, либо «Исходный код страницы» в старом добром Firefox, либо «Просмотр кода страницы» в новом Google Chrome, либо «Просмотр HTML-кода» в старичке IE.
В верхней части окна исходного кода любой страницы вашего сайта ищите нужные вам метатеги. Выглядеть все это безобразие может, например, так:

На моем блоге формирования заголовка Title происходит по следующему принципу: сначала в нем идет название материала, а затем, через знак «|», идет название ресурса. Наоборот делать, скорее всего, не стоит, но вот без названия ресурса вполне можно обойтись, хотя... Естественно, в названии материала вы должны использовать ключевые слова для продвижения именно этого документа, а в название всего проекта включить ключевое слово для продвижения всего проекта.
Теперь пора переходить к тому, как, собственно, реализовать внутреннюю поисковую оптимизацию применительно к WordPress (у меня есть также статья про организацию правильной внутренней перелинковки в WordPress, и в этом нам поможет упомянутый выше плагин All in One SEO Pack.
All in One SEO Pack — оптимизируем блог на WordPress
Пару общих слов про сам плагин. Он хорош, но вовсе не уникален и не идеален. Есть вполне себе замечательные аналоги и, наверняка, вы мне про них напомните в комментариях. К тому же, All in One SEO Pack может «подложить свинью», если не отнестись внимательно к его настройке и доработке описанной чуть ниже. Но при все при этом он стоит у меня с момента основания блога (почти семь лет) и я не собираюсь его менять. Возможно, что для кого-то это будет аргументом в пользу его использования.
Для начала плагин нужно скачать и установить на Вордпресс. Скачать All in One SEO Pack можно отсюда. Хотя, можно просто набрать All in One SEO Pack на странице поиска плагинов в админке Вордпресса, но это уж кто как привык (более подробно читайте в статье про установка и настройка плагинов для WordPress, решение возможных проблем.
Если скачали архив с плагином, то метод его установки зависит от вашего позиционирования себя :
- Метод для «девочек» — загрузить его из админки WordPress на вкладке «Плагины» — «Добавить новый» — «Загрузить файл». После установки жмете на кнопку «Активировать».
- Метод для «брутальных пацанов»:
- распаковываем архив с WP плагином all-in-one-seo-pack.zip
- полученную в результате распаковки папку с файлами all-in-one-seo-pack закидываем в директорию, предназначенную для установки плагинов wp-content/plugins/ на сервере хостинга. Для этого нужно подключиться к серверу по протоколу FTP, например, с помощью программы Файлзила (или другого FTP-клиента).
- далее входим в админку WordPress (в моем случае — https://ktonanovenkogo.ru/wp-admin/) и выбираем вкладку «Плагины»- «Установленные»
- находим строку с нашим расширением и жмем на «Активировать»
- Теперь останется только осознать серьезность проделанных шагов и свою «крутость».
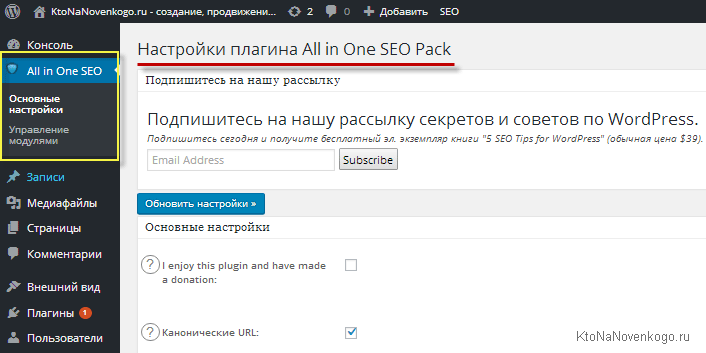
В обоих случаях далее переходим в админке в окно настроек сего плагина. Раньше оно располагалось по следующему адресу: Настройки -> All...Pack. Но в последних версиях этого расширения разработчики учли его значимость и настройки были вынесены в отдельный пункт «All in One SEO», который скромно расположили в самом верху левого меню:
Чуток прокрутите страницу с настройками, чтобы уже задать мета-теги для главной страницы блога (Title, а также Description). Это актуально, если главная у вас динамическая (на ней выводятся все материалы блога по мере их устаревания).
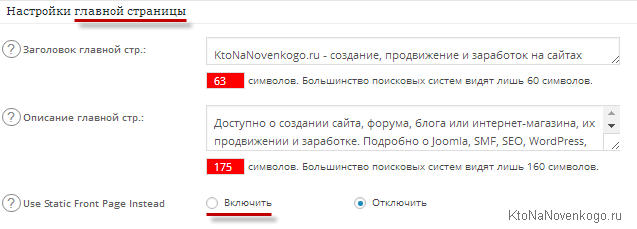
Если она статическая (подробности читайте в статье про вид главной страницы и рубрик в WordPress), то смысл этих настроек теряется (в редакторе самой странички тоже самое можно прописать), посему можно будет переместить галочку в поле «Use Static Front Page Instead»
Мета-тэг Canonical и его настройка в All in One SEO Pack
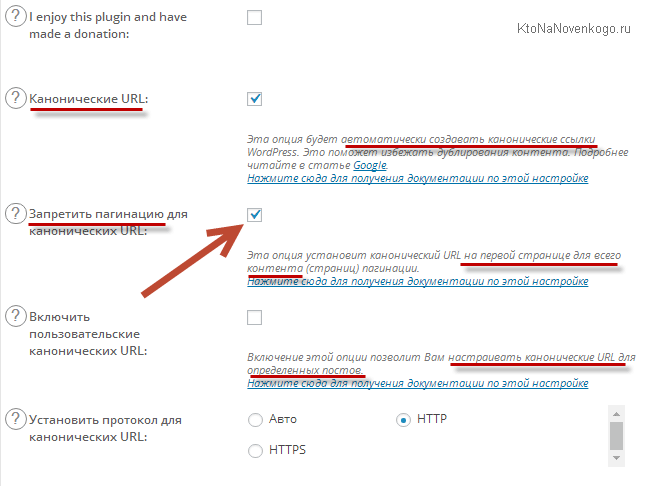
Галочка в поле «Канонические URL» в окне настроек All in One SEO Pack позволяет избежать дублирования контента в WordPress (содержимого материалов вашего проекта) в индексе некоторых поисковиков.
Давайте сначала рассмотрим, откуда может появиться дублирование контента в Вордпрессе. А появиться оно может в том случае, если один и тот же материал будет доступен по разным адресам (URL). Например, если вы используете тег MORE для разделения текста материала на вступительную часть, публикуемую на главной, и полную версию, открываемую либо по нажатию на заголовок материала, либо по нажатию на ссылку, формируемую с помощью тега MORE (например, Читать далее...).
Так вот, при щелчке в WP блоге по заголовку материала, полная его версия откроется по одному адресу, а при щелчке по ссылке «Читать далее» — по другому (отличаться они будут только надписью типа #more-2788 в конце URL адреса). Во втором случае документ откроется на том месте, где он закончился на главной странице блога (где стоял тег more).
В принципе, можно применить хак и убрать в настройках движка WordPress добавление #more-2788 к Урлу, но тогда вебстраница будет открываться сначала, что мне кажется не очень удобным для читателя (придется искать то место, где он закончил чтение на главной).
Но есть альтернативный вариант решения проблемы дублирования контента в WordPress, при котором и волки будут сыты, и овцы останутся целы. Выход из создавшейся ситуации придумала компания Google, анонсировав в начале этого года новый метатег Canonical, о поддержке которого сразу же заявили Яху и Microsoft.
Таким образом, если ваш ресурс имеет идентичный или очень похожий контент, доступный по разным URL, то новый тег Canonical позволит указать тот URL , который должен возвращаться к поисковой системе. При этом все характеристики, такие как ссылочный вес и тому подобное, передадутся на нужную (каноническую) версию адреса.
С точки зрения Html синтаксиса, мета-тег Canonical добавляется между открывающим и закрывающим тегами HEAD в HTML коде вебстраниц с дублированным контентом. В результате Google, Yahoo, Bing, а с недавних пор и Яндекс, поймут, что все дубликаты ссылаются на канонический URL, указанный в Canonical. Дополнительные свойства вебстраницы, такие как PageRank, также перенесутся с дублирующих вебстраниц на указанную.
В качестве примера приведу вид этого Canonical для странички с материалом моего WP блога, на которую я перешел по ссылке «Читать далее». В адресной строке я при этом вижу адрес:
https://ktonanovenkogo.ru/vokrug-da-okolo/hosting/fajl-hosts-gde-on-naxoditsya-v-windows-chto-delat-kak-udalit-virus.html#more-6188
Но в исходном коде, сформированном движком WordPress, (в верхней его части) можно найти строчку:
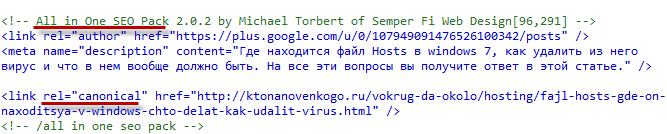
Она говорит поисковым системам, понимающим Canonical, какой именно адрес данной статьи считать каноническим. По-моему, отличное нововведение, которое, пожалуй, омрачает лишь тот факт, что этот тег Canonical какое-то время не поддерживался Яндексом, но сейчас все благополучно разрешилось.
Благодаря плагину All in One SEO Pack в WordPress, проблема дублирования контента в индексе Yandex, Google, Яхоо и поисковика Bing решается простой установкой галочки «Канонические URL'ы», которая, кстати, по умолчанию уже включена. Но теперь вы знаете, что такое тег Canonical и зачем нужен.
Возможные проблемы с Canonical при использовании All in One SEO
Если вы внимательно посмотрите на приведенный чуть выше скриншот, то увидите, что у меня сейчас стоит галочка в поле «Запретить пагинацию для канонических URL». Не знаю, стоит ли она по умолчанию при активации плагина, но после обновления со старых версий (где ее в помине не было) она находится в сброшенном состоянии, что может привести к печальным последствиям. Смотрите сами (просьба отвести детей от экранов ваших мониторов, ибо это зрелище не для слабонервных...).
Прошлым летом я совершенно случайно глянул на количество страниц этого блога, которые находятся в индексе, и был шокирован — их там аж 8000 тысяч. В Google чуть более 1500 тысяч, что тоже несколько больше обычного.

Перешел по ссылке из окна РДС бара (именно им и смотрел) на Яндекс со списком страниц моего сайта в его индексе. Полистал его смальца и слегка «удивился» (ранее стоящее тут слово было удалено цензурой), ибо нашел там кучу дублей, которые вели на одни и те же посты (статьи, т.е. записи в терминологии WordPress), но Урлы у них были различные (а содержание одинаковое). Крайне неприятная ситуация, которую нужно было срочно решать, пока карающий меч не...
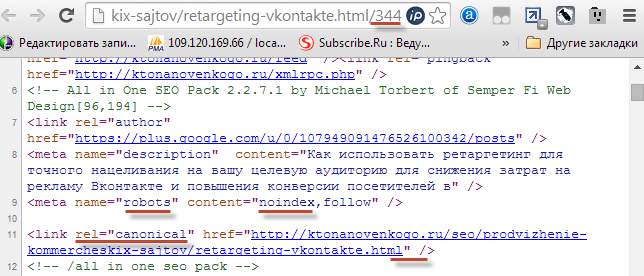
Дубли в индексе Яндекса я нашел примерно такие:
/seo/prodvizhenie-kommercheskix-sajtov/retargeting-vkontakte.html/122 /seo/prodvizhenie-kommercheskix-sajtov/retargeting-vkontakte.html/123 /seo/prodvizhenie-kommercheskix-sajtov/retargeting-vkontakte.html/124
Пару минут я пытался сформулировать запрос для поиска ответа в Яндексе на сложившуюся ситуацию. Ничего не придумал и полез посмотреть в исходном коде, а какой, собственно, там rel="canonical" прописан. Если основной страницы (без слеша и цифирек на конце), то все ОК.
Однако канонический Урл меня крайне разочаровал. На блоге https://ktonanovenkogo.ru я это дело уже поправил, поэтому приведу скрин с другого блога на WordPress, где наблюдается та же картина, что и была тут какое-то время назад:
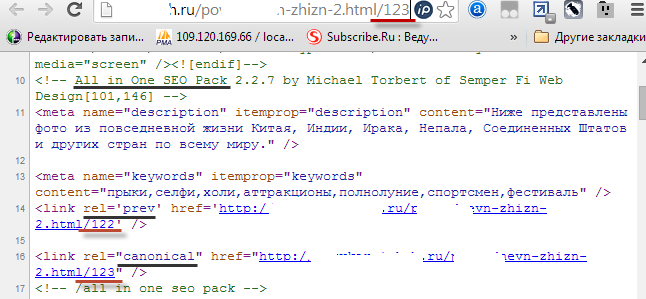
Абзац, причем полный. Поисковик в этом случае был совершенно прав, что загнал эти дубли в индекс, ибо rel="canonical" не указывает на основную страницу.
Да и к тому же чуть выше в коде стоит rel="prev", который содержит ссылку на страницу с номером на единицу меньше той, для которой мы просматриваем исходный код. Поисковик по этой служебной link ссылке перейдет (ведь именно для него она тут и проставлена), в результате чего в индекс попадет еще один дубль и так до бесконечности.
Если внимательно приглядеться к скриншоту, то виновника этого безобразия вычислить не сложно — это тот самый плагин All in One SEO Pack, который до сих пор меня не подводил. Однако, все в жизни когда-то бывает в первый раз. Что приятно — эта ситуация сейчас практически полностью успешно разрешается через настройки данного плагина. Все просто и логично, но лучше это сделать до попадания кучи дублей в индекс, чем как я делать настройки уже после.
Настройки плагина сейчас вынесены в отдельный пункт «All in One SEO, который расположен в вверху левого меню админки WordPress. В самом верху окна настроек следует поставить галочку в поле «Запретить пагинацию для канонических URL».
Это уберет злосчастные слеш и цифирьки после Урла основной страницы в теге rel=»canonical", который будет прописываться для таких страничек. Забыл сказать, что эти цифирьки (на вроде .html/124) есть ни что иное как пагинация, т.е. разбиение поста на страницы (про пагинацию можете почитать в статье про плагин WP-PageNavi).
Хотя у запичей (постов) на моем блоге никакой пагинации в помине нет и не было, но WordPress (а точнее наш любимый Ол ин Ван Сео) их виртуализировал. После установки указанной галочки, сохранения изменений и сброса кеша исходный код проблемных страниц с Урлами стал уже выглядеть иначе, что меня порадовало, ибо в rel="canonical" был указан действительно канонический Урл, а не страница псевдо-пагинации с цифрами на конце. Уф, одной проблемой меньше.
Однако, в индексе Яндексе уже имеется куча дублей, от которых надо избавиться. Поэтому я прокрутил страницу с настройками All in One SEO практически до самого низа и поставил галочку в поле «Использовать noindex для страниц/записей с пагинацией».
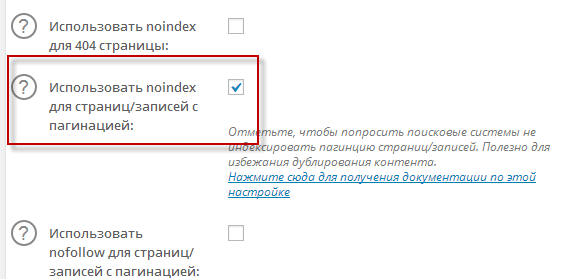
Удаляем rel='prev' из исходного кода блога на WordPress
В итоге, код формируемый этим плагинов в «шапке» стал примерно таким:
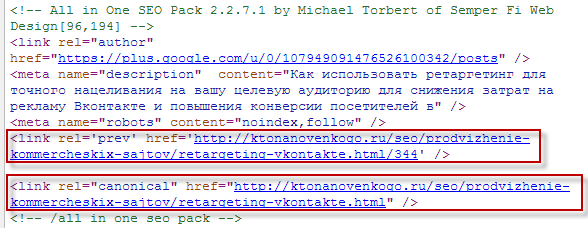
Однако, в коде по-прежнему имеется совершенно бестолковый и даже вредный в данном случае тег rel='prev', в котором указана ссылка на предыдущую страницу пагинации. Но, как я уже упоминал, никакой «разбивки на страницы» в статьях у меня нет и этот тег только вводит в заблуждение поисковики, а значит его надо убрать (порвать, изничтожить, растоптать...).
Для этого нужно будет открыть на редактирование (советую использовать связку Файлзила+Нотепад, а не встроенный редактор файлов в WordPress) файлик functions.php из папки с используемой вами темой оформления (wp-content/themes/название) и добавить в него после ‹?php следующие строчки кода:
function mayak_remove_prev_link( $data ) {
return false;
}
add_filter( 'aioseop_prev_link', 'mayak_remove_prev_link' );
add_filter( 'aioseop_next_link', 'mayak_remove_prev_link' );Собственно, все. Теперь проблемный участок исходного кода, формируемый плагином All in One SEO Pack для страниц с дурацкой погинаций, у меня выглядит вполне себе благопристойно (на мой взгляд):
Примерно через три недели после проведенных махинаций манипуляций в индексе Яндекса осталось уже только около 1000 страниц, что примерно соответствует их реальному количеству на этом блоге. Что и требовалось доказать.
Настройка Title для всех типов страниц в WordPress
Продолжим разбираться с настройками плагина — All in One SEO Pack. Если вы установите галочку «Перезаписывать заголовки», то сможете настраивать для различных типов вебстраниц в WordPress вид их Тайтлов в соответствии с правилами, описанными в приведенных ниже полях.
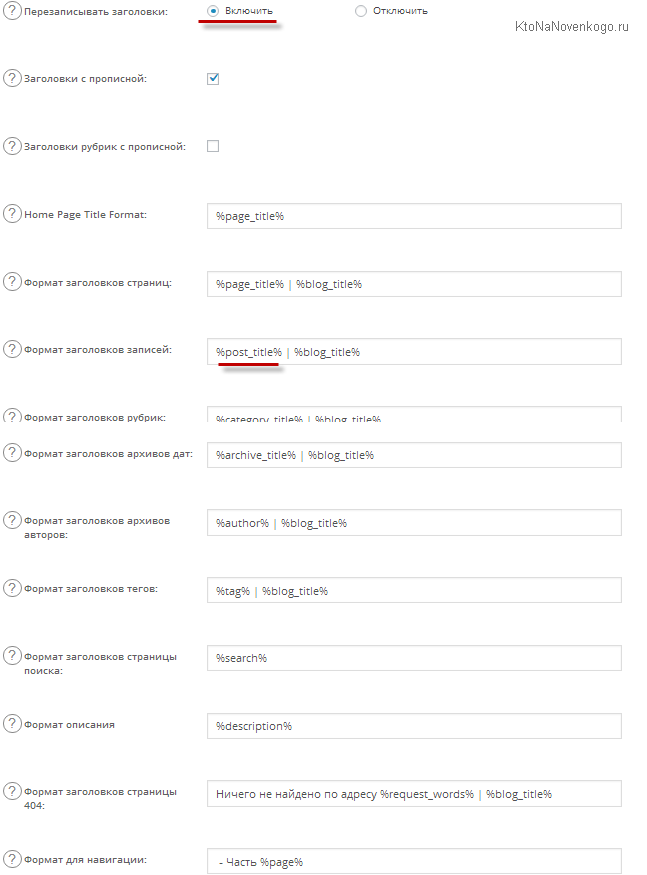
Вся прелесть данного плагина в том, что вам практически ничего не надо менять в его настройках по умолчанию, чтобы получить максимальный эффект. Я ничего пока и не менял в приведенных на рисунке полях, но вы можете вносить изменения по своему разумению и видению лучшего варианта (пользуясь случаем, хочу спросить у вас: есть мнение, что Яндекс не учитывает слова в тайтле после символа «|» — так ли это на самом деле?)
Немного поясню надпись:
%post_title% | %blog_title%
Сие означает, что Тайтл будет формироваться из заголовка данной публикации, плюс (вертикальная черта, если быть точным) название блога. Точно так же обстоит дело и с категориями (%category_title% | %blog_title%), статическими страницами (%page_title% | %blog_title%), архивами и другими типами записей, формируемыми нашим любимым движком.
Запрет индексации архивов или категорий в All in One SEO Pack
Область «Настройки индексирования (noindex)» в настройках All in One SEO Pack — позволяют бороться с дублированием контента в индексе поисковых машин. Дело в том, что в рубриках, тегах и архивах, которые создает Вордпресс, могут повторяться анонсы одних и тех же публикаций.
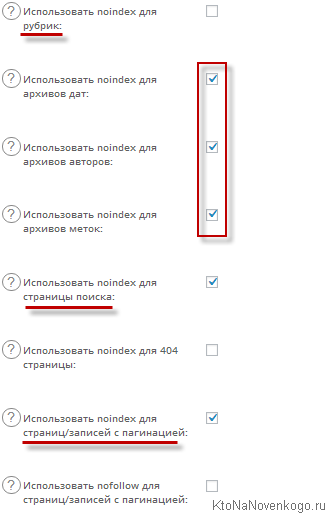
Вы можете запретить индексацию категорий WP, архивов, тегов, страниц внутреннего поиска, страниц с пагинацией и т.п... Индексация запрещается автоматически, при помощи добавления между тегами HEAD исходного HTML кода мета-тега ROBOTS следующего содержания:
<meta name="robots" content="noindex,follow" />
Снимать галочки со всех трех пунктов я бы не советовал, т.к. в результате, в индекс поисковиков может попасть много похожих по содержанию вебстраниц. Лично я пока что разрешил индексацию только категорий в WordPress, а индексацию архивов тегов и временных архивов запретил (см. скриншот расположены выше).
В связи с тем, что я запретил индексацию поисковыми системами архивов тегов, пришлось убрать со всех страниц блога ссылки на вебстраницы этих тегов. В противном случае, статический вес (PageRank) утекал бы безвозвратно на эти не индексируемые поисковиками вебстраницы. Обратите на это внимание.
Почему именно я запретил индексацию страниц с пагинацией — объяснил чуть выше, а страницы с результатами внутреннего поиска по сайту (средствами WordPress) тоже желательно запретить, ибо поисковики сильно не любят, когда их индексную базу забиваю тонны «результатов поиска».
Генерация описания страниц и подтверждение авторства
Галочки в начале области «Расширенные настройки» активируют автоматическую генерацию мета-тэга Description, если вы не задали их вручную при написании статьи в админке.
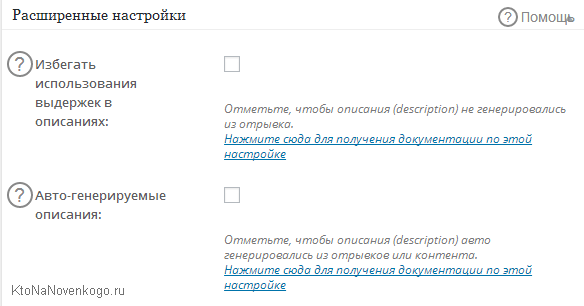
Содержимое берется из поля «Цитата», если оно было заполнено, или из начальной части текста. Я бы не советовал включать эту опцию в настройках. Лучше создавать каждый раз вручную отдельное описание (Description) для материала при его написании.
C недавних пор в функционал этого плагина добавили еще и возможность подтверждения авторства ваших материалов в выдаче Гугла с помощью своего аккаунта в социальной сети Google+.
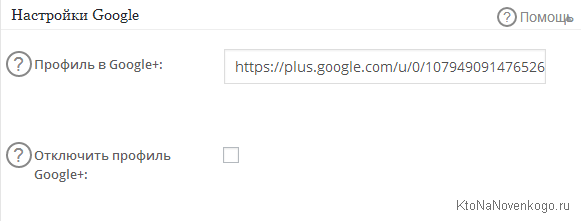
После в подтверждении авторства в поисковой выдачи, рядом со ссылкой на ваш блог, появится ваше фото взятое из Гугл+. Получится что-то вроде этого:
Честно говоря, не экспериментировал с полями в самом конце настроек этого плагина. Судя по всему, в первое поле нужно ввести через запятую вебстраницы, на которые не должно распространяться действие этого WP плагина, а четыре последующих позволяют что-то добавить в шапку соответствующих страниц Вордпресс блога.
В настройках можно также активировать показ дополнительных полей для Сео настроек при редактировании записей в админке, а еще добавить пункты настроек этого плагина в верхнюю панель администратора:
В новых версиях плагина появилась возможность активировать дополнительные модули, например, «Производительность», но для меня главное не создавать слишком большой нагрузки на сервер и этот модуль я отключил:
Прописываем Title и Description для каждой страницы блога
Кроме, собственно, настроек. Теперь, благодаря All in One SEO Pack, при написании или редактировании статьи у вас будет возможность, при желании (а оно у вас обязательно должно возникать), указать для нее уникальное (обязательно, и это очень важно) содержимое мета-тегов «Title», «Description».
Это можно будет сделать в админке WordPress в окне редактирования любой страницы или записи. Область для ввода мета-тегов называется «All in One SEO Pack», которое вы можете найти в окне редактирования материала (при желании вы можете его перетащить за верхнюю полосу в любое удобное для вас место в окне редактирования).
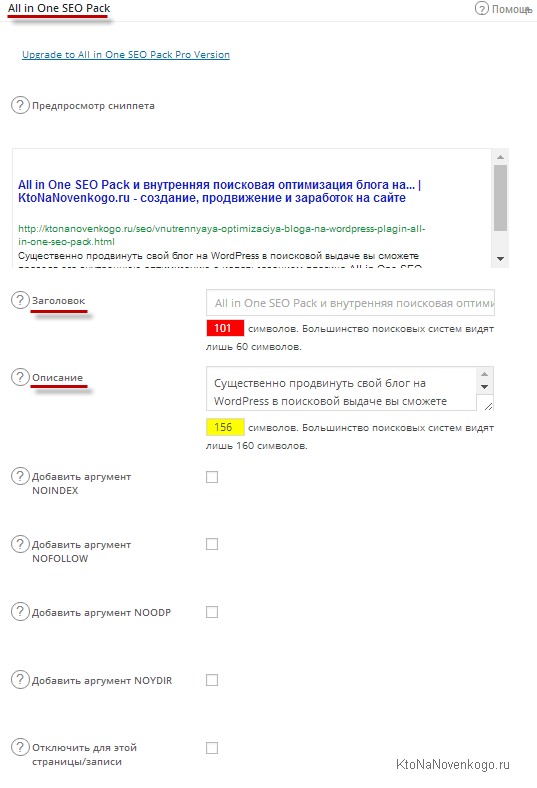
Я обычно заполняю только поле мета-тега «Description», т.к тот тайтл, который формируется из заголовка публикации, меня вполне устраивает.
Если вдруг под окном редактирования статьи вы этого блока не нашли, то прокрутите страницу вверх и кликните по расположенной справа вкладке «Настройка экрана», а в выпавшей панели поставьте галочку в поле «All in One SEO»:
Проблема с All in One SEO Pack и ее решение — убираем rel=prev и исправляем rel=canonical, чтобы убрать из индекса дубли
Случайно сегодня глянул на количество страницы этого блога, которые находятся в индексе, и был шокирован — их там аж 8000 тысяч. В Google чуть более 1500 тысяч, что тоже несколько больше обычного.
Перешел по ссылке из окна РДС бара (именно им и смотрел) на Яндекс со списком страниц моего сайта в его индексе. Полистал его смальца и слегка прифигел, ибо нашел там кучу дублей, которые вели на одни и те же посты (статьи, т.е. записи в терминологии WordPress), но Урлы у них были различные. Крайне неприятная ситуация, которую нужно было срочно решать.
Дубли страниц блога на WordPress в индексе поисковиков
Дубли в индексе Яндекса я нашел примерно такие:
/seo/prodvizhenie-kommercheskix-sajtov/retargeting-vkontakte.html/122 /seo/prodvizhenie-kommercheskix-sajtov/retargeting-vkontakte.html/123 /seo/prodvizhenie-kommercheskix-sajtov/retargeting-vkontakte.html/124
Пару минут я пытался сформулировать запрос для поиска ответа на сложившуюся ситуацию. Ничего не придумал и полез посмотреть в исходном коде, а какой, собственно, там rel="canonical" прописан. Если основной страницы (без слеша и цифирек на конце), то все ОК. Однако канонический Урл меня крайне разочаровал. На блоге https://ktonanovenkogo.ru я это дело уже поправил, поэтому приведу скрин с другого блога на WordPress, где наблюдается та же картина, что и была тут какое-то время назад:
Полная лажа. Поисковик в этом случае был совершенно прав, что загнал эти дубли в индекс, ибо rel="canonical" не указывает на основную страницу. Да и к тому же чуть выше в коде стоит rel="prev", который содержит ссылку на страницу с номером на единицу меньше той, для которой мы просматриваем исходный код. Поисковик по этой ссылке перейдет (ведь именно для него она тут и проставлена), в результате чего в индекс попадет еще один дубль и так до бесконечности.
Если внимательно приглядеться к скриншоту, то виновника этого безобразия вычислить не сложно — это тот самый плагин All in One SEO Pack, о котором я писал лет пять назад (надо бы тот пост обновить, да руки все не доходят) и который до сих пор меня не подводил. Однако, все в жизни когда-то бывает в первый раз.
Проблема эта не нова и ее уже не раз обсуждали. Но все это прошло мимо и вскользь, а вот теперь вернулось бумерангом и вдарило по темечку. Что приятно — эта ситуация сейчас практически полностью успешно разрешается через настройки данного плагина. Все просто и логично, но лучше это сделать до попадания кучи дублей в индекс, чем как я делать настройки уже после.
Правда, я там не нашел вариант удаления мета-тега с rel='prev', но эта проблема легко решилась с помощью добавления нескольких строк кода в замечательный файлик функшионс.пхп. Но обо всем по порядку.
Настройка тега rel="canonical" в All in One SEO для устранения дублей
Настройки плагина сейчас вынесены в отдельный пункт "All in One SEO, который расположен в вверху левого меню админки WordPress. В самом верху окна настроек следует поставить галочку в поле «Запретить пагинацию для канонических URL».
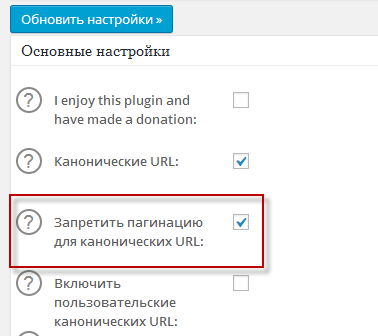
Это уберет злосчастные слеш и цифирьки после Урла основной страницы в теге rel="canonical", который будет прописываться для таких страничек. Забыл сказать, что эти цифирьки (на вроде .html/124) есть ни что иное как пагинация, т.е. разбиение поста на страницы.
Лично я свои посты никогда не разбиваю, да и любую другую пагинацию (главной страницы или рубрик) закрываю от индексации в файлике роботс.тхт. А тут получается вообще какая-то псевдо-пагинация постов, которой вроде как и нет, но WordPress на страницы с цифрами, написанными через слеш после Урла, не выдает 404 ошибки, а считает, что это пагинация. Бред какой-то, но факт остается фактом. Если вместо цифр написать через слеш буквы, то выдает 404 ошибка.
После сохранения изменения исходный код проблемных страниц с Урлами вида:
https://ktonanovenkogo.ru/seo/prodvizhenie-kommercheskix-sajtov/retargeting-vkontakte.html/344
Стал уже выглядеть иначе, что меня порадовало, ибо в rel="canonical" был указан действительно канонический Урл, а не страница псевдо-пагинации с цифрами на конце:
Однако, в индексе Яндексе уже имеется куча дублей, от которых надо избавиться. Поэтому я прокрутил страницу с настройками All in One SEO практически до самого низа и поставил галочку в поле «Использовать noindex для страниц/записей с пагинацией».
В результате этого на страницах пагинации (с цифирьками на конце) в исходном коде теперь добавляется запрет на их индексацию через мета-тег name="robots" со значением "noindex,follow" (что означает инструкцию роботам поисковых систем — не индексировать, но по ссылкам переходить):
<meta name="robots" content="noindex,follow" />
Удаляем мета-тег rel='prev' из исходного кода страницы блога на WordPress
Как видно из второго отсюда скрнишота (выше по тексту), то там обведен в рамочку не только правильный тег rel="canonical", но и совершенно бестолковый и даже вредный в данном случае тег rel='prev', в котором указана ссылка на предыдущую страницу пагинации. Но, как я уже упоминал, никакой пагинации в статьях у меня нет и этот тег вводит в заблуждение поисковики, а значит его надо убрать.
Сделать это несложно. Достаточно будет открыть на редактирование (советую использовать связку Файлзила+Нотепад, а не встроенный редактор файлов в WordPress) файлик functions.php из папки с используемой вами темой оформления (wp-content/themes/название) и добавить в него после <?php следующие строчки кода:
function mayak_remove_prev_link( $data ) {
return false;
}
add_filter( 'aioseop_prev_link', 'mayak_remove_prev_link' );
add_filter( 'aioseop_next_link', 'mayak_remove_prev_link' );Если что-то пошло не так (блог не открывается), то откатите изменения в Нотепаде++ и посмотрите внимательно, куда именно вы пихаете приведенный код. Если чуток подумаете, то все обязательно получится.
Собственно, все. Теперь проблемный участок исходного кода, формируемый плагином All in One SEO Pack для страниц с дурацкой погинаций, у меня выглядит вполне себе благопристойно (на мой взгляд):
Что и требовалось реализовать. Ура...
P.S. Примерно через три недели опосля написания этого поста после очередного апа Яндекса в его индексе осталось уже только около 1000 страниц, что примерно соответствует их реальному количеству на этом блоге.
Комментарии и отзывы (239)
Спасибо, хорошо написано. Но по поводу постоянного повторения названия проекта в title сомневаюсь. Не думаю что такой «вредине» как google понравится одинаковая концовка всех Тайтл .
Otto, не знаю точно, что Google подумает (все таки поисковики это вещь в себе), но большинство веб-проектов все же используют такую схему организации мета-тега Title (включая популярные проекты с большим трафиком с поисковиков, включая Google).
Такой вариант организации мета-тега Title так же советуют и авторы многих книг по Joomla. А там, кто его знает, может вы окажетесь и правы. =)
Спасибо за интереснейший блог, обязательно поставлю на вас ссылку когда сделаю свой. Но вопрос от чайника: где в плагине прописать мета-теги для отдельной странички? Не главной, или статьи, а именно для странички?? Спасибо.
xtra, ваш вопрос вовсе не вопрос чайника. Я только могу сказать, что не так то просто это сделать. Мета-теги вы можете прописать в файле header.php своей темы WordPress. Но для того, чтобы эти мета-теги выводились только на статических страницах нужно задать соответствующее условие. В качестве примера могу привести условие формирования title для разных страничек блога (задается в том же header.php):
<title> <?php if (is_home () ) { bloginfo('name'); } elseif ( is_category() ) { single_cat_title(); echo ' - ' ; bloginfo('name'); } elseif (is_single() ) { single_post_title();} elseif (is_page() ) { single_post_title();} else { wp_title('',true); } ?> </title>Вам нужно будет написать что-нибудь подобное, но уже для нужного мета-тега. Возможно что будет проще поискать плагин делающий все это в автомате.
xtra, как раз встретился мне плагин для вордпресс, решающий эту задачу. Называется он Robots Meta (wordpress.org/extend/plugins/robots-meta/screenshots/) и позволяет управлять индексацией каждой страницы блога поисковиками, добавляя META теги. Плагин очень полезен для борьбы с дублирующим контентом.
Особенности плагина Robots Meta:
• Управление .htaccess и robots.txt из админ панели
• Управление мета-тегами : результатами поиска, администраторских , авторских архивов, авторизационных и регистрационных т.д.
Спасибо, хоть кто-то все по полочкам разложил, а то не силен я в англицком. Одно плохо, Яше это все по барабану.
«тот тайтл, что генерирует этот плагин для WordPress, меня вполне устраивает.» Подскажите,где можно посмотреть, какой тайтл генерит плагин? У меня поле title пустое при создании новой записи.
Владимир: Значение Title вы можете увидеть в самом верху любого окна браузера. Так же его можно посмотреть в исходном HTML коде. Для просмотра исходного кода, щелкаете правой кнопкой мыши в окне любого браузере и выбираете из контекстного меню что-то вроде «Исходный код». Он располагается вверху окна с исходным кодом и выглядит, например, так:
<title>Содержимое Title</title>Понял, спасибо. Я думал есть возможность заранее увидеть еще на стадии формирования поста в вордпресс, какие тайтлы All in One предлагает
Здравствуйте. После настройки и запуска плагина All in One SEO Pack в шапке WordPress исчезла картинка, а иногда видно только ее часть. Что посоветуете?
Отличная статья... две недели криво сматрел на этот Плагин, пытаясь панят, что же он там такого оптимизирует в вордпресс... будем пробовать... будем как говорится — раскручивать (смайлик)... пошерстим что нить ещё на вашем WP блоге)))))
Спасибо, очень вовремя попалась Ваша статья. Добавил в избранное, помогли настроить оптимизатора.
Спасибо, оч. полезный пост, настроил свой WP блог так как вы описали.
У меня блог на wordpress, когда поисковая система например яндекс индексирует мои статьи, в выдаче появляется название заголовка проекта, а только потом идёт заголовок статьи, мне кажется, что такой факт портит моё место в выдаче так происходит с каждым заголовком, прав я на этот счёт или нет?
так вот я хотел бы узнать как сделать так, чтобы заголовки постов в поиске шли отдельно от заголовка ресурса и вот ещё я из этой публикации не до конца понял мета тэги надо прописывать при написании каждой публикации или они прописываются один раз с помощью плагина можете подробней объяснить, СПАСИБО!
sasha: Title будет формироваться автоматически для всего блога в соответствии с настройками, сделанными вами в All in One. В тексте, примерно в середине, на рисунке приведены настройки по умолчанию, которые позволяют выводить в всех TITLE — сначала название материала, а затем название проекта. Точно так же, как это реализовано на данном блоге.
Попробовала я автоматический формат заголовков, в результате все заголовки в WordPress вообще исчезли, только на главной название блога, а на всех остальных URL... Пришлось отключить эту опцию и использовать по умолчанию вариант WP.
Да и еще момент, если вы используете sape, то не советую что-либо отправлять в noindex
Создаю блог, наткнулся на подборки плагинов для вордпресс с настройками. Попал к вам, спасибо за грамотно изложенную статью.
Derzky говорит, что:
да все просто и лаконично. Спасибо!
Подскажите пожалуйста, установил Robots Meta на WP (закачал на сервер, распаковал, поставил галочку активен)и ничего не произошло, никаких настроек не появилось. Не знаю что делать, активировал акисмент, его настройки появились, может нужно что-то дополнительно сделать, я новичек и возможно не сделал что-то важное?
Мало, кто WP блоги оптимизирует под поисковые системы:(
здравствуйте! Подскажите, в поисковике статья находится вот так:
Название блога — Название поста
Если установить All in One SEO, то будет вот так:
Название поста | Название блога
После установки плагина на WordPress, ничего не изменилось...с чем это может быть связано? Спасибо!
Ирина: только хотел предложить посмотреть этот пункт в настройках как вариант решения, а потом прочитал, что вы уже все сами нашли.
Наталья: поисковики довольно инерционы и индекс вашего проекта обновится не сразу.
Было много непонятных пунктов у плагина — с английским беда, но теперь все настроил в вордпресс как надо...
Благодухе не границ.
Спасибо! Ваша статья мне очень помогла в настройке плагина для поисковой оптимизации WordPress. Разобрался в момент!
великолепно описано! и главное, для меня, как полного профана в SEO очень понятно и поучительно.
определенно блог в закладки! =)
У меня стоит это WP плагин и в выдаче поисковых систем выводит дату! перед описанием.
Выдача такая:
Как убрать дату?
Спасибо. Давно искал такой подробный материал.
Спасибо за отличную подборку статей.
Я как начинающий блоггер Вам очень признателен.
Спасибо, а то когда впервые все эти слова видишь после установки Ол Ин Ван СЕО на вордпресс, то первая мысль «да ну его на, потом разберусь»...)
Спасибо за статью, благодаря вам наконец-то разобрался с этим плагином!
WP плагин хороший, печалит только то, что Яндекс к нему равнодушен.
А печатную версию можно предоставить? 🙂
Отличная и очень полезная статья! Но много рекламы.
Спасибо, может подскажите как подобрать ключевые слова для этого WP плагина 🙂 Или статью хорошую посоветуйте, а то везде не очень понятно.
Отличная и очень полезная статья! Но много рекламы.
Привет отличная статья и блог у вас просто супер классный и всё подробно описано, хотя некоторые моменты мне не понятны. А скажите если я в этом плагине закрою индексацию и категорий, и тэгов и архивов как это по-вашему будет выглядеть?Ну чтоб только контент индексировался это будет нормально?Или же всё таки категории хотя бы оставить открытыми к индексации?Что посоветуете?И ещё вопрос.Я когда смотрю свои результаты в Яндекс вебмастер всё равно вижу , что и теги и архивы индексируются,хотя они в плагине стояли закрытими от индексирования?Что посоветуете??7
Аня: советую категории в WordPress оставить открытыми для индексации, во всяком случае, я так сделал. Если теги закрываете от индексации поисковиками, то не забудьте убрать все ссылки на эти теги (например, облако тегов). Иначе у вас суммарный статический вес сайта будет утекать в никуда (в черную дыру). Яндекс довольно медлителен, потому и наблюдаются в индексе страницы, запрещенные для индексации. Когда Яндекс решит их переиндексировать, то потихоньку начнет их удалять из своей коллекции.
Спасибо за совет. Так и сделаю.
Добрый день, Дмитрий! Отличная статья, наконец-то стало понятно как нужно писать заголовки, почему вижу индексированные теги и как надо правильно настраивать этот плагин. Спасибо, пошла исправлять.
Дмитрий, здравствуйте!
Большое спасибо за статью, все настроил!
Однако возникла такая проблема:
При оставлении поля Keywords (comma separated) пустым, плагин так и не генерирует ключевые слова.
Хотя галочка Dynamically Generate Keywords for Posts Page стоит.
Никак не могу понять в чем дело (приходится самому их «генерировать»)
Надеюсь на Ваше мудрое решение! =)
Atamovich: я всегда ключевые слова в Keywords прописываю вручную, ибо так оно всегда будет лучше и надежнее. А по сему затрудняюсь ответить на ваш вопрос про автоматическое заполнение мета тега Keywords.
Все хорошо, все верно, для Гугла отлично работает! Но Яше глубоко по барабану этот плагин — он по поисковой фразе продолжает выдавать все кроме того что ищешь...Как бы хорошо, если кто- нибудь и для него (Яндекса) сварганил что-либо подобное. Дмитрий, то еще не дошел до этого (делать плагины)?
Очень познавательно... Нашёл вас на маулнете, с вашей книгой, тоже понравилась)
Доброго времени суток Дмитрий. Я Вас много читаю, много у Вас взял. Но у Вас есть некоторые ошибки! Сейчас, если позволите, поясню:
На главной — в тайтлах не надо ставить так " KtoNaNovenkogo.ru — все для начинающих вебмастеров | Создание и продвижение сайтов,...
Врядли Вас будут в поиске набирать ктонановенького? А тайтлы читают и учитывают поисковики обрезанно! тобишь столько, сколько позволяет браузер, и не более. Поэтому лучше просто накидать ключи, касательно главной страницы. Точки не в тайтлах( у Вас нет) не дискрипшин не ставят, а равно как и в категориях. В описаниях, тоже лучше перечислить ключи, а в конце добавить позновательно или что-то такое.
У Вас на главной, я не вижу кеев? Их плагин не генерирует. поэтому лучше прописывать ручками. В статьях тоже, всё ручками. Я после определённых манипуляций, только за счёт этого, вывел много вопросов в топ, сч и даже сч-вк, без единого пинка по яше, который без него мало двигает.
Мой блог здох, из-за одной, но фатальной ошибки, перелинковки анонсов в одни сетки с разных блогов, поэтому переедет, только вёрстку доделаю, там буду всё по правилам делать. Я знаю точно, написать статью быстро, но найти ключи, оптимизировать и подогнать под поиск, много времени уходит. Алгоритмы у поисковиков меняются, согласен, 1к знаков мало но 10000 к слов много, особенно если они переливают с пустого в порожнее. Буду рад продолжить дискусию, мне интересно, надеюсь и вам. Удачи и Спасибо.
Olega: здравствуйте, все верно, в общем-то, но главную я не продвигаю, ибо контент на ней постоянно меняется. Title на главной полностью ориентирован на посетителей, а не на поисковые системы. Запрещать ее к индексированию тоже не хочу, т.к. на нее ведет большинство внешних ссылок, вес с которых, я надеюсь, перетекает на вебстраницы со статьями, которые уже оптимизируются под конкретные низкочастотные запросы.
Хотя, пока писал этот комментарий, возникла мысль сделать главную страницу в WordPress статичной, наполненной постоянным контентом (все же главная — самая прокачанная) и помогающей в навигации по блогу. Вы не знаете примеры блогов со статичными главными вебстаницами? Позаимствовать опыт хотелось бы, так сказать.
Длину текстов я подбираю в диапазоне от 1000 до 2000 слов (не знаков, а именно слов). Воды в статьях, наверное, много, но в основном это из-за того, что мне хочется быть понятным даже для совершенно не подготовленной аудитории. В связи с чем, приходится писать обо всем довольно (иногда даже излишне) подробно, зачастую повторяя то, о чем уже упоминал в других своих статьях.
За то люблю WordPress, что там есть этот плагин. Он работает. Кстати, гугл его любит больше, чем яндекс. Яндекс вытаскивает обычно заголовки и описания из самого текста, а вот Гугл берет так, как есть. Я записала про этот плагин видео урок, если админ не против, можете смотреть http://goo.gl/EhQnF.
Класс, спасибо что объяснили что к чему с этим чудесным плагином. Мне он очень понравился, особенно тем, что можно быстро и без проблем заполнить все теги:)
У меня вопрос. Все статьи у меня на блоге уникальные. Пишу сам. Файл robots настроен в частности закрыта индексация TAG и Category но вот в Гугле почему-то появились дубликаты статей. Я там понимаю это произошло еще до того как я настроил блог. В общем 90% статей под Supplemental фильтром. В яндексе все ок. Как вытащить статьи или как исправить ситуацию.
SolanD: у меня пару месяцев назад Google проиндексировал львиную долю страниц запрещенных в robots.txt. Пришлось их вручную удалять из индекса (https://ktonanovenkogo.ru/vokrug-da-okolo/programs/skorost-zagruzki-sajta-prodvizhenie-kak-uskorit-sajt-page-speed.html). Все это сопровождалось проседание трафика с этой поисковой системы. Сейчас, вроде бы, все потихоньку выправляется, но очень медленно и неуверенно.
Здравствуйте скажите а у меня такой вопрос — этот плагин ссылки, что в статьях закрывает от индексации или нет, а то что-то понять не могу. Мне просто нужно чтоб некоторые ссылки в постах были открытыми для поисковиков.
Kuzuxa: All in One SEO Pack закрывает целые страницы от поисковых систем, а ссылки можно закрыть от индексации этим WordPress плагином — Плагин WP-NoRef
Дмитрий ,то что плагин закрывает страницы это понятно, а вопрос был про посты ?Мне нужно чтоб там были ссылки открытые,т.е. в постах. Он их не закрывает от индексации???
Kuzuxa: ну, я как раз и говорю, что ссылки плагин All in One SEO Pack никаким боком не затрагивает — для этого служит приведенный выше плагин.
WorldVentures: Да, плагин отличный.
Кстати, есть еще all in one seo pack Importer — интересно, чем отличается?
Спасибо Дмитрий это и хотела узнать.
Да, классная статья! Спасибо большое автору за понятное разъяснение! Буду работать!
Дмитрий: «пользуясь случаем, хочу спросить у вас: есть мнение, что Яндекс не учитывает слова в тайтле после символа „|“ — так ли это на самом деле?»
Подозреваю, что Яндексу нет никакого дела до «|». По крайней мере на одном из своих проектов я использую для названий статей под низкочастотники для улучшения восприятия статьи структуру следующего вида: «Первая часть статьи | Вторая часть статьи...», или «Первая часть статьи / Вторая часть статьи...». И все отлично индексируется без всяких там плагинов.
Но Вы, Дмитрий, верно обратили внимание на проблему индексации после «|». Дело все в том, что Яндекс выхватывает для сниппета наиболее адекватные моменты из тела статьи, связанные с заголовком.
Например, я пришел на Ваш блог по запросу: «настройка плагин all seo wordpress». И получил следующий вид в Яше:
Отображаемый заголовок статьи: «... блога на WordPress, установка и настройка плагина All in One SEO...» (кстати, налицо опровержение заблуждения, что поисковики не индексируют более 60-70 символов в заголовке)
А вот сниппет: «Внутренняя поисковая оптимизация блога на WordPress, установка и настройка плагина All in One SEO Pack (теги Canonical, Description и Title в WP) … Спасибо, что помогли разобраться с этим SEO плагином для вордпресс. Хорошая статья, все подробно...». Как видим, тут нет инфы после «|», и это правильно. А на кой она тут нужна? Вывод: ЕСЛИ НАЗВАНИЕ БЛОГА ПОСЛЕ СИМВОЛА «|» НЕ СВЯЗАНО ИЛИ СЛАБО СВЯЗАНО С НАЗВАНИЕМ ПОСТА, ТО ОНО И НЕ ОТОБРАЖАЕТСЯ. ЗАЧЕМ ВВОДИТЬ ПОСЕТИТЕЛЕЙ В ЗАБЛУЖДЕНИЕ НЕ РЕЛЕВАНТНОЙ ЕГО ЗАПРОСУ ИНФОРМАЦИЕЙ?
Кстати, я на одном моем проекте вообще нет никаких плагинов оптимизации и прочего, но в Яндексе он по большей части целевых запросов занимает позицию с 1-3 (Я его создавал, когда еще не имел никаких представлений о СЕО, работал по наитию так сказать). ЗАТО, КАК Я ЗАМЕТИЛ НА ДРУГОМ СВОЕМ ПРОЕКТЕ, У ЯНДЕКСА ЕСТЬ АЛГОРИТМ АНАЛИЗА ЗАСЕОШЕННОСТИ СТАТЕЙ. ЕСЛИ ИСПОЛЬЗУЕШЬ МНОГО СЕО, ОСОБЕННО В ТЕЛЕ СТАТЬИ (я никогда не перегибал палку с ключами статье свыше 3-5 процентов, но если делаешь все слишком грамотно, т.е. выделяешь несколько раз болдами и курсивами ключевые запросы, ставишь грамотные H1-H3, располагаешь их ближе к началу, включаешь СЕО плагины и т.д. , Яндекс это просекает, и позиция по запросу ниже).
Дмитрий, я так и не дождался Вашего совета по плагину перелинковки в текстах статьи... 🙁
Валерий: спасибо за столь развернутый комментарий и наблюдения, интересно было почитать. По поводу перилинковки — внутри статей исключительно ручной способ, а в конце статей — плагин WordPress Related Postsj. Ну, еще к перелинковке можно отнести хлебные крошки, реализованные на плагине Breadcrumb NavXT .
Исключительно ручной способ? Признаюсь, Дмитрий, Вы меня удивили! Я конечно подозревал, что Вы это делаете в ручную, но все же в тайне надеялся, что быть может Вы автоматизировали процесс. Уж больно это хлопотно в ручную делать. Плагины конечно есть, но почему-то они мне не внушают доверия при создании длинных ссылок, которые, как мне кажется, нравятся Гуглу. С Яндексом все просто: хороший качественный контент — это ключ к успеху. А вот в Гугле все как-то не по-русски (у меня посещаемость в процентном отношении на 2-х проектах: 80% — Яша, и только 10 — Гоша). Я этот Гугл вообще понять не могу. Что ему надо? Сколько не пыжился, нашел пока что один прием, который часто наблюдается на сайтах, попадающих в ТОП 10 — это активная перелинковка именно в текстах статей. Я такого еще не реализовывал раньше. Может этого «приворотного зелья» хватит, чтобы «соблазнить» Гугл...
Здравствуйте!
У меня вопрос возник такой. В настройках плагина Алл-ин-оне-сео-пак я не ставил галочку в поле Автогенерация дескрипшена. Дескрипшен прописываю вручную для каждой публикации. Дескрипшен на сколько я понял это сниппет . Просматривая свой пост в выдаче поисковика вижу, что сниппет совсем не совпадает с введенным мной вручную дескрипшеном. В исходном же коде вебстраницы дескрипшен указан именно тот, что я прописал. В чем может быть ошибка и почему поисковая система отображает не то что я прописал в дескрипшен. Мой блог http://www.harum.ru/
Заранее спасибо за внимание. Даже если вы не знаете что это за ошибка.
Иван: Просмотрел для вашей данной записи. Снипет тоже отличается от дескрипшена. Может я что не так понимаю и снипет это не дискрипшен...
Иван: Сниппет — это не дескрипшен. Дескрипшен — это то, что Вы, Иван, прописываете в плагине. Сниппет — это то, что выдает поисковая система. А она чего хочет — то и выдает. Если Вы погадаете на кофейной гуще, проконсультируетесь у астрологов ... и т.д... и т.п..., то возможно и сумеете написать дескрипшен, который так понравится поисковикам, что они станут выдавать его в качестве снипетта. Но это маловероятно на 99,9%, поскольку одна статья может участвовать в поиске по целому отчасти схожих, но весьма разных поисковых запросов, и под каждый из них поисковая система будет формировать свой сниппет, осовываясь на тексте статьи. А как Вы планируете реализовать сей момент в одном дескрипшене?
Валерий: Это будет сложно, но я что-нибудь придумаю :))) Ситуация понятна. Почитал инфо и Ваш ответ подтвердил то что есть. Дескрипшен стал не актуален и прописывать его нет смысла.
Иван: А вот это, как мне кажется, всеобщее заблуждение! Я насчет того, что дескрипшен не имеет никакого смысла. Как мне кажется и дескрипшен очень даже полезен, и кейворды тоже. Я решил замутить полностью коммерческий блог в одной очень высоко конкурентной тематике. Все топовые СЕО конторы Москвы (да и не только) и лучшие оптимизаторские умы бьются в этой лакомой нише, продвигая сайты крупных компаний. Так я специально проанализировал около 300 сайтов по большей части конкурентных запросов. И что? Дескрипшен с кейвордами очень даже актуальны! Надо только уметь ими пользоваться. В противном случае, они могут принести больше вреда, чем пользы.
Валерий: Ого! Секретные исследования дискрипшен и кейвордов ведете)) Полагаю статью об этом обычным читателям не увидеть... Ну да ничего)) Удачи с исследованиями
u miinea esti vapros pro tag ... Esli ya delayu sait na 3 yazika, kak mne napisati tag , description...?
Замечательный ты парень и замечательные статьи пишешь, но все же позволь высказать пару пожеланий:
— рекламу от яндекса выделяй чуток или отделяй, ибо портит она текст страшно
— не ну пошире колонку надо сделать, такие простыни перематывать офигеешь! И смотрится не очень.
«Если теги закрываете от индексации поисковиками, то не забудьте убрать все ссылки на эти теги (например, облако тегов). Иначе у вас суммарный статический вес сайта будет утекать в никуда (в черную дыру)» Поясните пожалуйста, для чайников, как это сделать (облака тегов у меня нет). Благодарю заранее за помощь.
Здравствуйте уважаемые, для меня все это пока темный лес , но потихоньку вникаю, есть у меня блог о линукс и ни как яша не хочет его индексировать, может подскажет кто почему так, ведь блогу более 5 месяцев, может я что не так делаю.
Огромное спасибо! Я у Вас тут живу уже. Сначала начинаешь читать, блин, думаешь, зануда какой с этой оптимизацией, читать невозможно)))
А потом думаешь, вот ведь как помог-то!!!
Спасибо 🙂
А Вы не подскажете, где можно заработать на блогах на платформе я.ру? Обидно, высокий рейтинг, куча друзей, а предлагают копейки какие-то на постовых. Хорошие нужные компании можно было и за нормальные деньги.
Здравствуйте! Подскажите, пожалуйста, почему настройки этого плагина могут сбрасываться? Я заполняю все поля, отмечаю галочки, но после сохранения все настройки сбрасываются и в полях вместо текста появляются нолики. Не пойму, в чем дело 🙁
И кстати, как и у Ирины, у меня вверху красная надпись есть Аll in One SEO Pack must be configured. Go to the admin page to enable and configure the plugin.
All in One SEO Pack now supports Custom Post Types.
Только в моем случае она не убирается даже после того, как в настройках изменяю на Enabled.
Может вы знаете, как решить эту проблему?
Доброго времени суток Дмитрий! вот с помощью проверки исходника, смотрю все сайты которые находяться в топе, у них в хейдере, и у Вас, прописаны теги и титл, т.е. сразу там, а не ссылки.
Что Вы скажете по этому поводу, если Вы поняли что я имел ввиду?
Большое спасибо за статью!
Очень помогла в настройке WordPress. Я немного знакома с языками программирования, но вот настройка готовых продуктов мне дается сложно. Этот плагин — именно то, что мне было нужно.
Спасибо, Дмитрий!
Все как всегда содержательно.
У меня, извиняюсь за назойливость, всего два вопроса:
Для меня это важно, да и Вам новая тема для исследования.
1.Сервис проверки валидности HTML выдает следующее (перевод):
«К сожалению, я не могу подтвердить эту документа, потому что на линии 33 он содержит один или несколько байт, что я не могу интерпретировать как UTF-8 (другими словами, байт найдено не допустимые значения в указанной кодировки символов). Пожалуйста, проверьте как содержание файла и кодировки указанием характера.
Ошибка: utf8 „\ XeF“ не отображает в Юникод»
Как моэно поправить это?
2.Если я начинал сайт со статических, а потом сделал главную из записей по мотивам , что нужно запретить к индексации — записи или страницы?
Заранее большое спасибо!
Ух много комментариев, но надеюсь мой не затеряется. Раз можно спрашивать, то спрашиваю)))). Не встречали ли вы такую проблему с этим плагином. При обновлении старой уже опубликованной записи (например нашел грамматическую ошибку), страница админки не рефрешиться, а просто появляется белый экран с названием статьи в правом верхнем углу. При чем статья-то все-таки обновляется, просто нужно все время после нажатия кнопки «обновить» нажимать назад и рефреш. Вроде бы на работу блога не влияет, но просто вымораживает. Не люблю когда что-то работает не так как надо. При выключенном плагине проблема исчезает. Спасибо! А, и еще. Проблема возникла после перехода на вордпресс 3-ей версии.
Здравствуйте. Скажите почему у меня ни аглицкая ни русская версия не устанавливается — все время пишет «фатальная ошибка»?
Обращаюсь к админу, в своей статье вы упоминали про то, что желательно ставить description (описание статьи) к каждой статье вручную, буду благодарен если вы более подробно объясните, где именно надо ставить, перед текстом статьи(в самом начале) или где то в другом месте? Заранее спасибо за ответ.
Александр: не совсем так. Этот плагин добавить в окно редактирование статьи дополнительное поле, в которое вы и будете прописывать этот мета тег (самый последний скриншот посмотрите).
Дмитрий большое спасибо, вы написали, что заполняете только description? а как вы относитесь к заполнению keywords, ведь это тоже достаточно важный элемент.
Здравствуйте! Никак не могу решить мою проблему. Я меняла название блога и теперь в title выдает . Если плагин отключить, все нормально. Из header удалила строку php bloginfo ('description'). не помогает( Что еще можно сделать?
Дмитрий, при правильной работе плагина должно в коде быть примерно так как у вас "All in One SEO Pack 1.6.13.2 by Michael Torbert of Semper Fi Web Design[276,498]"
Если в коде "All in One SEO Pack 1.6.13.2 by Michael Torbert of Semper Fi Web Designob_start_detected [-1,-1]" в чем может быть проблема? Плагины все отключал и включал, никак не повлияло.
У меня почему-то description не отображается. Задаю его в плагине, но на страницах все равно отображается то, что в изначальных настройках блога
Отличный плагин — компактный и функциональный, и разжевано досконально — спасибо разобрался очень быстро.
Много тонкостей в плагинах описано, буду чаще к Вам заглядывать. (начинающий чайник)
Много тонкостей плагинов описано. Буду чаще к Вам заглядывать (начинающий чайник)
Здравствуйте, у меня такая же проблема: в коде страницы ни keywords, ни description не отображаются, что делать где что исправить , подскажите
Вы меня осчастливили этим дивным описанием!
Сделала! Ура! А то болтался без дела у меня этот плагин и поглядывала на него с опаской, не зная, как и подступиться! В благодарность(между нами, понажимаю рекламки).
Я тут недавно радовалась успешной настройке плагина.
У меня потом вверху, на сайте высветились буквы анг. — ошибку выдало и проблема не проходила. Обратилась в тех. поддержку своего хостинга. Там все исправили. Сказали, что мне не нужно было ставить галочку внизу самом.
Вот, такая вот, получилась ситуация. Может быть, кому — то пригодится мой опыт.
Добрый день. Тоже столкнулся с такой проблемой. Установил данный плагин, по началу все работало отлично. Но через какое-то время — перестал. Все, что я указываю в полях записи (заголовок, ключевые слова, описание) ничего не выводится. Помогите, пожалуйста
Здравствуйте плагин All in One SEO Pack очень хорош, но несколько дней назад Яндекс перестал показывать в поиске все страницы моего блога. Я стал разбираться, что за ерунда. Яндекс пишет:
«В коде документа содержится мета-тэг „Noindex“, запрещающий поисковым роботам его индексировать. Чтобы документ проиндексировался, удалите мета-тэг.»
Открываю Исходный код страницы, да действительно,
плагин All in One SEO Pack написал:
Хотя в настройках у меня только на архивы должен был прописываться noindex.
Хорошо, а как убрать эту строчку я не пойму, где в каком файле искать, непонятно. Я просмотрел все файле в редакторе WordPress и header.php и footer.php да вообще все, но там такой строки нет.
И на сервере просматривал файлы и так же ни чего не нашел.
Пришлось удалить плагин и после этого строка кода
исчезла. И не понятно как она там оказалась, в плагине все по умолчанию было выставлено.
Если снова устанавливаю плагин строка с noindex опять возвращается.
Подскажите, где и какой файл мне нужно смотреть, что бы убрать этот код. И еще,а не пропишет плагин, этот код обратно после того как я удалю код?
Спасибо.
Спасибо! Доходчиво и конкретно,очень помогло.
Спасибо. Статья очень полезная.
То, что у Вас указано по поводу «Capitalize Category Titles» — так это же просто «фишка» в английском языке. Англичане считают, что все слова в Заголовке Должны Быть С Большой Буквы. 🙂
А нам эта функция — действительно ни к чему.
Ну наконец-то номальное объяснение...
У меня с английским проблемы!
Спасибо большое!
Здравствуйте.
Подскажите,пожалуйста, как вы спрятали свой движок от определения сервисами?
У меня joomla я тоже хочу спрятать от всех!
RDS плагин на mozilla не обнаруживает!
Пора поправить инфу: 23 мая 2011 г. Яндекс включил поддержку атрибута rel=”canonical”.
Вы пишете, что пришлось убрать со всех страниц блога ссылки на вебстраницы тегов для предотвращения утечки PageRank. То есть Вы фактически отказались от тегов? Нет ссылки — нет тега, так?
А как быть, если товар на сайте для удобства поиска входит сразу в несколько подкатегорий (используютя как теги, так и подрубрики)?
Может, достаточно прописать «nofollow» в этих ссылках на подкатегории и теги?
Спасибо за статью! Установил плагин, разбираюсь. Особенно порадовала функция каноникал.
Dmitriy: пожалуйста. Особенно приятно, что Canonical, наконец то, стал поддерживать и Яндекс.
Спасибо огромное за такую подробную и содержательную статью! Сто лет уже, как скачала этот плагин, а все никак не могла собраться и настроить. Сегодня, наконец то, справилась. =)
Совсем недавно на WordPress, приходится всё делать на лету, спасибо за инфу, доступно и понятно!!!
Добрый день! Скажите, пожалуйста, если все статьи публикуются на главной странице, и при этом категории открыты для индексации, не приведет ли это к дублированию контента?
В принципе, ответ на предыдущий вопрос очевиден — если вы так поступаете, и в день на сайт приходит больше 8000, значит все нормально. Прошу, если можно, прокомментировать мой вывод: теги и архивы использовать нельзя. Если мы открываем их для индексации — дублируется контент. Если закрываем — ТИЦ и PR уходят в никуда, потому что мы ссылаемся на неиндексируемые страницы через облако тегов и меню архива с главной страницы.
Константин: ну, я тоже задумывался над этой проблемой и сделал так, чтобы материалы в категориях WordPress отличались от анонсов на главной (вывод WP рубрик (категорий) функцией the excerpt).
Константин: да, все так. Только пожалуй, Тиц не утекает — у него другая природа образования, в вот Виц и Пр утекать будут. Я решил это просто убрав все ссылки на теги и временные архивы.
Большое спасибо за ответ и ссылку на статью. Полезная функция the expert. Я тут параллельно озадачился вопросом, можно ли для удобства посетителей добавлять статью сразу в несколько категорий и при этом не дублировать контент. Насколько я понял, функция the expert помогает решить и эту проблему — выбираем минимальное количество выводимых после заголовка слов и таким образом практически исключаем дубль в категориях, даже если статья попадает одновременно в 2-3 рубрики.
Здравствуйте!
я установила all in one seo и все работало, оптимизировала одну статью и потом он пропал куда то(( переустановила уже несколько раз. Но все равно, когда пишешь новый пост, плагин так и не появляется внизу. в чем может быть проблема?
Здравствуйте, Дмитрий!
Спасибо за статью!
У меня проблема с плагином,может Вы поможете разобраться...
Заполняю Title, Description, Keywords, все как сказано.
В итоге Description получаю начало своей статью аж до 250 символов, а вовсе не то,что я лично прописывала в Description. При этом Title и Keywords работают отлично и показывают то,что я хочу... Проверяла разными сервисамии смотрела,что гугл выдаёт...
Вобщем, я в раздумьях и не знаю,как такое может быть. Может у Вас будут идеи по поводу? Буду благодарна. Спасибо 🙂
Даша: здравствуйте. Возможно, что Вы свернули вкладку плагина в админке WordPress и он теперь представляет из себя просто полоску с названием All in one seo (щелкните по этой полоске). Если это не так, то щелкните по вкладке «Настройки экрана», расположенной в верху справа. Поставьте галочку напротив этого seo плагина и он немедленно проявится.
Ника: здравствуйте. Возможно, что в настройках плагина вы поставили галочку об автоматическом заполнении мета тега Description.
Здравствуйте.
Подскажите, а как быть с мета тегом description, который по умолчанию прописан в теме WordPress. Непонятно, как от него избавиться. Он в коде находится выше мета тегов All in One SEO Pack и при анализе страницы выводится именно этот, первый тег. Причем состоит он не из описания, а из текста последнего поста.
Получается что на странице home целых два тега description.
Cкажите, пожалуйста, будьте любезны, люди добрые,Дмитрий, помогите Христа ради, после написания статьи в записях консоли, мы пишем ключевые слова для плагина All in One Seo Pack.Я с дуру поставила галочку в чикбокс Disable on this page post.Теперь мне пришли какие то уведомления, которые я должна подтвердить или одобрить.В уведомлениях(комментариях) огромные тексты html всяких, (это робот что ли ?:)) В общем, что делать? Или где посмотреть, что делать? Я сама себе отключила ключевые слова??? Пробовала полазить по настройкам плагина All in One Seo Pack, вроде как негде восстановить то...ну, наверно, где то можно, но , очень хотелось бы узнать, как мне восстановить работу плагина, зачем я этот Disable нажала то, экспериментатор несчастный...
Леонид, у меня тоже возникла подобная проблема... толкьо мне яндекс выдет:
Внимание! Главная страница сайта исключена из индекса: Документ содержит мета-тег noindex
...
хотя у меня нет мета-тега такого... во тне могу понять что к чему, может кто подскажет?
Здравствуйте! Подскажите пожалуйста. У меня wp 3.0.1, стоял SEO, и тут я решил SEO обновить. Теперь сверху он пишет: Your database meta needs to be updated. 84 old fields remaining (Back up your database before updating.)
и
Your database options need to be updated.(Back up your database before updating.), ну и кнопочки чтобы провернуть эти обновления. Так вот стоит мне их нажимать?
Не слетит ли у меня весь бог из за конфликта версий?
СПАСИБО!
«Яндекс не учитывает слова в тайтле после символа «|» — так ли это на самом деле?)»
Только сегодня читал об этом в блоге Webeffector. Там предписывается использовать именно символ «|» чтобы ключевые слова после него также учитывались.
Добрый день, подскажите, пожалуйста, плагин сначала работал прекрасно, но вдруг начал косячить — прописываю все метатэги, обновляю запись, а там стоят теги совершенно другого старого поста! Или открываю старый пост — а в режиме редактирования тоже стоят совершенно другие теги, хотя в коде страницы вроде все нормально. Я в шоке и непонимании, как жить дальше
Здравствуйте. Объясните пожалуйста, как оптимизируется главная страница блога на WP, ведь на ней отражаются последние записи. Какие ключи прописывать и т.д.?
Уже неделю бьюсь с этим плагином. В поисковике набираю этот плагин — никаких вменяемых объяснений по его установке нет.Только сегодня нашла этот сайт и всё настроилось. А тут ещё и про «ротапост» смотрю есть. Я тут думаю надолго. Спасибо.Большое!
у меня почему в исходном коде не отображаются мета теги с ключевыми словами, хотя плагин включен и ключевые слова к кааждой статье прописаны, в чем может быть дело?
Подскажите, пожалуйста, что можно сделать с плагином , если он не выводит меню для каждой статьи, чтобы прописывать название, описание и ключевые статьи??Раньше всё работало хорошо, каждую статью оптимизировала, а потом просто пропал этот плагин, хотя его смотришь всё активно, и где в статьях раньше указывала ключ.слова, сейчас тоже всё пропало...может плагин перестал работать???
Илья.
На странице параметры, панели администратора, откройте плагин и там впишите ключевые слова. Обновите настройки плагина и посмотрите код.
Марина.
На странице записи, адм. панели, откройте настройки экрана и поставьте галочку у этого плагина.
Спасибо, очень важная и полезная информация. Сам бы долго разбирался!
Спасибо за подробный пост. Но есть баг в работе плагина — keywords автоматически не прописывается при установленной галочке, это видно даже на вашей странице с данным постом:
Спасибо, поставил себе этот плагин. Появились дескрипшены, только какие-то усеченные. Все работает, успехов!
Установил и активировал плагин Google XML Sitemaps. При построении карты появляется белый экран и далее никуда не переходит. На хосте создается нулевой sitemap/ Как это исправить ?
спасибо
А Вы, случайно, не пробовали плагин WordPress SEO. Там намного больше функций, правда не совсем понятных.
Если что либо знаете — расскажите пожалуйста.
Спасибо, за статью. Не зря вас Владимир Беляев рекомендует! Хотела вопрос задать, но посмотрела, что вы на них отвечаете изредка. Жаль. Придется еще где-нибудь узнавать.
Вообщем, я так и не поняла, если у меня установлен этот плагин. настройки все по умолчанию...надо ли прописывать ключевые слова в HTML- коде, геги акцентирования, атрибуты и пр. про что написано в статье???..я еще больше запуталась!!!
Дмитрий, изменилось ли Ваше мнение по поводу установки галочки в пункте Use noindex for Categories. Устанавливать ее или нет.
P.S. Смотрю и диву даюсь. Недавно заходил, посещаемость была 17000. Сейчас уже больше 21000. Вы что поисковики приворожили? 🙂
А вдруг Дмитрий ненароком забредет сюда и ответит на вопрос, который я не нашел. Данный плагин позволяет избегать индексации дублирования информации. А нужно ли закрывать от индексации дублирование .../page/№? И если нужно, то где это делать? В Robots.txt этого у Дмитрия нет, в плагине вроде бы тоже негде галочку ставить на запрет.
Здравствуйте.Я новичок. Подскажите пожалуйста, что можно сделать. У меня на сайте не работают SEO плагин в настройках для отдельных записей, то есть для каждой страницы прописываю ключевики, обновляю и они исчезают. Плагины все отключала,но и без них SEO не работает для каждой записи. Помогите!
Есть вопрос на счет этого плагина. Несмотря на то, что я уже держу выосокопосещаемые проекты, подстраховаться все же хочется.
У меня есть энциклопедия по медицине и назрел вопрос сортировки болезней. Но дело в том, что некоторые тайлы выглядят например так «Лечение ангины». Для сортировки, мне нужно, чтобы статья называлась Ангина, но тайтл не изменился. Как я понял, с этим плагином можно это сделать (то есть я пропишу «Лечение ангины», а статью назову «Ангина»). Вроде бы ничего не должно случится верно?
Но возникает еще один вопрос. Например пользователь по запросу «Лечение ангины» пришел читать статью, но она у нас же называется Ангина. Вот и вопрос, может ли вырасти показатель отказа или нет? Как вы думаете?
Спасибо заранее за ответ.
Здравствуйте!У меня на сайте http://agape-love.ru случилась беда.Пропал плагин All in One SEO Pack на WordPress.Пропал с главной страницы,в записях,а вот на страницах остался.Я обновила базу данных,он вернулся и я написала 2 записи,как он опять пропал.Как можно его восстановить?Я раньше давала пароль своего сайта одному человеку,обращалась за помощью.У меня подозрение на вредительство.Реально ли повредить этот плагин в редакторе на самом сайте?
Как сделать так чтобы тег title не ограничивался 60 символами? Бывает что нужно чтобы %post_title% занял всю строчку в выдаче, а он ограничивается 60 символами дальше идет %blog_title%
У меня не работает плагин, скачан с офиц. сайта, загружен, активирован, включён, слова введены, но он не работает, ни одна программа сканер его не видит, и в коде страниц он не отображается, и это только у меня у всех остальных все работает и процедуры мы с плагином делали те же, но вот у меня он работать отказывается, у него что ИИ есть и он может испытывать личную неприязнь? 🙂
Установил все класс, но после того как заполнил описание и ключики главной странице после сохранения нажал CTRL+U посмотреть на код страницы, так вот описания и ключей я там не нашел!!! Почему кто знает,подскажите?!
Спасибо грамодное за статью! Очень помогла, много времени потратил, пока ответ искал.
Если ещё актуален вопрос Виктора, то хотел бы ответить по этому поводу следующее. Возможно вы прописываете все эти мета-описания непосредственно в разделе добавления страницы, а для главной страницы нужно в настройках самого плагина.
Геннадий, если разрешит Дмитрий, отвечу на ваш вопрос. Существует такой плагин называется Wp Page navi. Подробно вы можете почитать по ссылке.
Дмитрий, интересно Ваше мнение. На странице 12 картинок, например, с ежами. Сайт продвигается по запросам, связанным с ними же (ежами:) ). Соответственно, не получу ли я переспам, прописав в alt к каждой картинке разные, но включающие в себя «ежей», описания?
Нашел описание другого плагина — Platinum Seo Pack.
Автор описания пишет что он получше будет и поновее.
Не подскажите, в чём разница? И что всё таки лучше поставить?
Доброго времени Дмитрий!
Прежде всего большое спасибо за этот пост.
Совместно с All in One Seo Pack я начал оптимизировать посты с помощью плагина SEOPressor (он не адекватен к русским текстам, но у меня сайт англоязычный). Добился — 96% видимости и 4% наполнения.
Но. При использовании тегов Н1, H2, H3, которые Вы также рекомендуете — получался очень ужасный контент постов. Слова получались огромными. Я начал делать слова невидимыми для посетителя, под фон поста — белыми, располагая их в конце предложений, под картинками и т.д. Но в переписке с разработчиком SEOPressor (Даниил Тан)он мне написал, что этого делать нельзя. Гугл Пингвин, который вызвал огромное недовольство блоггеров начиная с конца апреля (миллионы сайтов опустились вниз), за это наказывает, то есть опускает сайт.Есть также и другие позиции, за что Пингвин опускает сайт. Их достаточно много.
Пока я оптимизацию с помощью Н1, H2, H3 убрал. Думаю что если Пингвин один раз опустит сайт — поднимать будет долго, если вообще поднимет.
Как можно применить Н1, H2, H3 не испортив при этом контент поста? Есть ли какие-нибудь рекомендации?
С уважением,
Геннадий
Доброго времени Дмитрий!
Я нашел выход как использовать Н1, H2, H3 не испортив при этом контент поста.
Для этого нужно атрибут () заменить на (). Далее — все зависит от вебмастера — где и какого цвета, расположить эта слова (предложения).
Но все неудобство в том, что в админ-панели моего WP-3.4 нет кнопки выбора жирного/среднего/малого параметра текста. По умолчанию текст получается жирный. Приходится вручную в HTML менять атрибуты на малый.
Я когда то слышал о плагинах, при установке которых в админ-панели появляется такая функция. Я попробовал, выборочно, устанавливать некоторые BlogRoll (ы) но пока безрезультатно.
Очень прошу, если Вы знаете такой плагин опубликуйте ссылку на скачку такого плагина.
С уважением,
Геннадий
P.S
Также, в последних версиях WP пропали и другие функции. К примеру возможность устанавливать атрибут rel=nowfollow для ссылок(очень важный для поисковиков). Также приходится вручную добавлять в HTML. Возможно у кого-то это все есть, но у меня (WP-3.4) пока так.
Пожалуйста напишите ответ на мой вопрос.
Почему-то на мой майл не было оповещения о публикации предыдущего комментария. Даже в ящике со спамом.
Для ясности предыдущего комментария.
Не опубликовалось в комментарии: Какие именно атрибуты менять.
Нужно поменять атрибут strong на small, и соответственно /strong на /small.
Также мой вопрос в прошлом комментарии — это вопрос о плагине, при установке которого, в админ-панели появляется кнопка выбора параметров текста (жирный/средний/малый). Пожалуйста ответьте.
P.S
Насчет rel=nowfollow.
Такого плагина не существует. Есть только хак. Но он имеет недостаток который меня не устраивает.
Yoast WordPress SEO:General — как насчет этого плагина? Использую его, подсказки дает, более расширенный в работе. Ваше мнение?
Спасибо за статью! В чём может быть дело? — на двух моих сайтах этот плагин работает отлично, а на этом же не в какую. Вместо «описания» когда анонсировать пробую в соц. сетях пишет «YOUR SITE DESCRIPTION HERE», а миниатюру подхватывает. Как этот косяк победить на моей теме (ColdStone от Elegant Themes)? Кто нить встречал?
у меня сразу возник вопрос — страницы блога нужно сводить в один canonical url? я имею ввиду на страницах site.ru site.ru/page/2/ site.ru/page/3/ везде должен быть ????
Вот спасибо! Как раз искал такой плагин. Установил всё нормально.
Здравствуйте, Дмитрий.
Подскажите, пожалуйста, Вы написали что следует закрывать от индексации архивы статей, чтобы не дублировать контент.
Тоже про архивы тэгов. А сами теги нужно индексировать?
P.S. Вы не планируете написать пост про плагин Platinum SEO Pack?
С Уважением.
Дмитрий: Здравствуйте!
Ну, я когда закрыл архив тегов, то вынужден был убрать ссылки на эти теги из статей, ибо они уже переносили вес в пустоту, что не желательно.
Хорошая новость Дмитрий!
Мой друг Даниэль Тан (Малайзия) — создатель плагина SEOPressor сообщил мне, что скоро дополнит плагин для работы с русскими текстами.
Если интересна эта тема — сообщите мне на мой майл.
С уважением,
Геннадий Синцерус, Туапсе
P.S
Также мы можем общаться в соц.сети ВКонтакте.
Здравствуйте.
«В связи с тем, что я запретил индексацию поисковыми системами архивов тегов в WordPress, пришлось убрать со всех страниц WP блога ссылки на вебстраницы этих тегов. В противном случае, статический вес (PageRank) утекал бы безвозвратно на эти не индексируемые поисковиками страницы WP тегов.»
Скажите пожалуйста, а как убрать ссылки с них? У меня закрыты от индексации рубрики и архив, а вес на них передается большой. Как исправить это? Заранее благодарен!
У меня уже стоит этот плагин и все было нормально, я решил передвинуть окно плагина выше над комментариями и оно у меня пропало, не подскажите как сделать так, чтобы этот плагин отображался под статьями, когда находишься в режиме реактирования статьи!?
Владислав: вверху админки WordPress (справа) при написании или редактировании статьи откройте щелчком вкладку «Настройки экрана» и поставьте галочку напротив «Пакет SEO все в одном».
Дмитрий, спасибо за статью. Очень интересно и полезно.
В любом случае, для любой внутренней оптимизации сайтов необходимы хорошие читабельные статьи. Можно, конечно, писать их самим. Но если быть честными перед самими собой, то это прерогатива мастеров слова. Textsale.ru например, имеет огромную базу уже готовых качественных статей, а если среди них не найдется нужной вам, то есть возможность оставить заказ.
Описано хорошо и подробн.Но!
Мой плагин говорит по-русски,а тут описан англоязычный вариант,поэтому мало что понятно.Пожалуйста, к английским пунктам меню в скобках напишите то же самое по-русски,или наоборот...
У меня проблема с плагином All in One SEO pack, гугл выдаёт результаты не с описанием моих постов, а с первыми словами из поста. Мета теги в в header прописаны, плагин включён. Не знаю что и делать, может кто встречался с такой проблемой?
У меня, почему-то, плагин не прописывает title и description для главной страницы. Т.е. я их в настройках плагина прописал, а они на сайте не отображаются. Для других страниц все работает. В чем может быть причина? Спасибо!
почему то у вас после заголовка страниц все таки идет название блога и вы не изменяли видимо этот пункт %page_title% | %blog_title%
и еще вопрос как сделать так что бы страницы преобразовывались в
vnutrennyaya-optimizaciya-bloga-na-wordpress-plagin-all-in-one-seo-pac
а не в такой вид
?p=373
Здравствуйте
Извините, если дублирую вопрос. Не уверена, что отправилось.
Подскажите, пожалуйста по этому абзацу:
«В связи с тем, что я запретил индексацию поисковыми системами архивов тегов в WordPress, пришлось убрать со всех страниц WP блога ссылки на вебстраницы этих тегов. В противном случае, статический вес (PageRank) утекал бы безвозвратно на эти не индексируемые поисковиками страницы WP тегов. Обратите на это внимание»
Это значит, что все теги, которые добавляются к постам, нужно удалить?
Я добавила robots.txt как у Вас здесь https://ktonanovenkogo.ru/seo/uluchshaem-indeksaciyu-sajta-poiskovikami-robots-txt-dlya-joomla-smf-wordpress-chast-2.html#robot-txt) и запретила теги в all in seo pack
И еще один вопрос. Title, description,keywords к каждому посту заполняются по желанию? Можно их заполнять выборочно, только к некоторым постам?
Спасибо
помогите плз.
Код любой страницы блога при выключенном и при включённом плагине не изменяется, тэги <meta... не появляются; из чего делаю вывод, что All In One SEO Pack не работает.
Плагин включен, в файле header.php активной темы есть функция
<?php wp_head(); ?>.Плагин работал отлично но вот после смены хостинга появилась эта проблема.
Здравствуйте. Поле плагина под редактором статей исчезло у меня на глазах! Я вообще не производила никаких действий, кроме редактирования статьи. Переустановила его — такая же картина. Никогда никаких проблем с ним не было, и на тебе! В суппорт написала — молчат. Что делать, подскажите
Здравствуйте, Дима.
У меня случилась такая же беда, как у Светланы: пропало поле плагина под статьями...ни подправить имеющееся, ни новые статьи не написать теперь...
Может, вы уже сталкивались или кто-нибудь из читателей. Ребята, подскажите?!
У меня стоит all in one seo pack Версия 1.6.15.2 и WordPress 3.4.1.
Здравствуйте.
Буду благодарен за помощь,
дело в том, что установил All in One SEO Pack, но при анализе главной страници на pr-cy.ru в Description выводит Description последней размещенной статьи.
Спасибо, если подскажете в чем бок.
Плагин стоит, раньше все работало, но сейчас почему-то не работает этот плагин, хотя активен, в админке для редактирования поста есть окна для прописи тайтла и мета тегов. .подскажите пож. в чем может быть причина?
Можно ли при написании статей добавлять статью сразу в несколько рубрик? Или это тоже приведет к дублированию информации с точки зрения поискового робота?
Спасибо большое, уже который раз получаю очень ценную информацию с Вашего ресурса! Вопрос по теме поста. У меня интернет-магазин, и я дублирую карточки товара (зачем — долго объяснять...). Но мне хочется назначать только одну из копий карточки товара канонической. Достаточно ли для этого будет поставить галочку в поле «канонические адреса» плагина?
Здравствуйте! Благодарю Вас за помощь и подробные разъяснения! Пожалуйста, помогите разобраться: я установила русифицированный плагин, настроила как написано, задала для каждой страницы Title, keywords,description и смотрю html код страницы, там вроде появились эти теги, но поисковики, я поняла, их почему-то не учитывают:
Подскажите, пожалуйста, как все таки точно узнать учитывают эти параметры поисковики или нет, в моем случае вроде не учитывают? Может это связано с защитой от копирования на сайте, сейчас я временно этот плагин деактивировала, но потом хотелось бы активировать. Спасибо!
Добрый день!
Несколько раз уже задавали этот вопрос, но пока без ответа.
Попробую тоже продублировать, может обратите внимание на крики о помощи начинающих.
Вы писали : «В связи с тем, что я запретил индексацию поисковыми системами архивов тегов в WordPress, пришлось убрать со всех страниц WP блога ссылки на вебстраницы этих тегов.»
Как это сделать? Расскажите, пожалуйста.
Заранее благодарен за ответ
🙂 странно видеть капчу после статьи, где (в видео) рекомендуют акисмет установить 🙂 Но я не об этом. Статья отличная, хотя немного устарела. Сегодняшние версии плагина уже немного отличаются уже тем, что они русифицированы (что не облегчает понимания). Хотелось бы обновления статьи с «веянием времени», так сказать...
И предыдущий коммент про запрет индексации в WP... — ждём ответа. Заранее спасибо!
Статью реально пора переписывать. В плагине все на русском. Только мой отличный английский позволил соотнести описание на сайте с тем, что было у меня перед глазами. Но там еще несколько функций, о которых в статье ни слова ((
Здравствуйте!
Я совсем запуталась в этих кейвордах! замучилась менять названия рубрик, меток, ключевые слова! Помогите разобраться , пожалуйста!
seonuf.com мне выдает:
*Title:*Релевантность: 0 %*Keywords:*Релевантность: 19 %. Некоторые
ключевые слова отсутствуют на странице!
Куда же они подевались ? если у меня на сайте
мета тэги титле = ВЧ ключ. слова
рубрики — СЧ ключ. слова
статьи — НЧключ. слова
Может быть мне поменять названия меток и рубрик?
Потому что метки видны под каждым названием статьи, а рубрики — один раз на главной странице.
Или я неправильно настроила плагин?
И еще слова в названии сайта igolo4ka1.ru ВСЕ О ПОШИВЕ ОДЕЖДЫ ни разу не встречаются ни в рубриках ни в метках ни в названиях статьи. Менять название сайта? Это влияет на индексацию сайта?
Здравствуйте. Подскажите пожалуйста ответ на вопрос; «Как вывести мета-данные генерируемые с помощью All in One, в самом верху кода страницы?» У меня этот плагин выводится где-то на 30 строке. Есть подозрение, что ПС не совсем четко его видит, а следовательно, не особо принимает во внимание. Здесь, на ktonanovenkogo.ru, плагин в коде страницы воводится так как надо. Повторюсь, и как его так «поднять»? Ответов нигде не нашел...
Здравствуйте. У меня проблема такая, что плагин Seo всё в одном установлен, прописываюются заголовки и ключевые слова, а описание страницы берется из первых слов поста, хотя в настройках плагина отключена возможность автоматического формирования описания. Подскажите, пожалуйста что делать?
Ребята, значит ктивировав этот плагин, не нужно добавлять сайты в поисковики вручную?
Большое спасибо за весьма полезный пост! Автору +++
дравствуйте. Такая же проблемам. Поле плагина под редактором статей исчезло! Переустановила его — такая же картина. Никогда никаких проблем с ним не было. Может кто сталкивался, помогите(
Здравствуйте!
у меня к вам вопрос значит. Вот в чем разница между title и названием статьи. Вот по seo основной ключ должен участвовать в title, а потом обозначить его в тексте тегом , но заголовок статьи это уже является или, потом в тексте уже отдельно выделять?
Дмитрий, хочу вас поблагодарить за столь «разжёванную» статью. У меня вопрос следующий. У многих пытающихся оптимизировать страницы, посты вылазит одна проблема с Н1 и Н2. Дело в том, что в посте к примеру, я применяю эти заголовки. Но в исходнике до начала статьи уже стоят заголовки Н1 — название сайта и Н2 — название поста. Посмотрел исходник вашей страницы и увидел, что у вас в принципе такой проблемы нет. Как вы это сделали?
Сильно настрадался с All-IN Seo Pack. Он в каких-то случаях создает неимоверную нагрузку на сервер.
Это я выяснил, когда начали приходить письма об избыточной нагрузке от хостинг-провайдера. Чего я только не перепробовал, выполнил все рекомендации об оптимизации и увеличении скорости блога — не помогало.
Потом нашел отзывы, что у многих проблема решилась с отключением этого плагина. Отрубил его и нагрузка снизилась раз 20! Такая проблема с плагином происходит почему-то не у всех, но у кого-то она есть.
Вместо него поставил Yoast WordPress SEO — намного лучше! Если бы я сразу узнал о нем, прежде чем вычитал в этой статье об All IN SEO, то поставил бы его. Он не грузит сервер(у меня) и намного лучше в настройках, заменяя не только функционал ALL-IN SEO, но и таких плагинов как XML Sitemap, clean up wp_head. Также убирает дублированный контент, заменяя работу соответствующих плагинов.
В нем куча настроек и полезных функций. Рекомендую всем.
Николай Перов, привет! а как ты проверял уровень нагрузки? Snx
Сергей, здравствуйте
У меня этот функционал есть в админке сайта хостинга. Т.е. это зависит от хостинга — у всех по-разному проверяется. Но я не смотрел до тех пор, пока не стали приходить письма с предупреждениями.
Хорошо что я не последовал уверениям поддержки провайдера на том, чтобы перейти на более дорогой тариф (это была их первая реакция на возросшую нагрузку), а настоял на том, чтобы разобраться в проблеме.
Здравствуйте, Дмитрий. Заполняю «Home title» в плагине «All in one SEO pack» и столкнулся с проблемой: у меня блог о форексе и после названия сайта (после «|», как у Вас) хочу написать основные запросы из wordstat со словом форекс, например, форекс советники, форекс индикаторы и т.д. Как часто можно употреблять ключевое слово в заголовке? (у меня выходит 5 словосочетаний через запятую со словом, это нормально?). Спасибо.
Александр: ох, я сейчас плохой советчик, ибо нахожусь под фильтром Яндекса за переспам. В свете последних событий, я бы воздержался от подобного удлинения и заспамливания тайтлов.
Дмитрий: а как Вы поняли что под фильтром? 🙂
Александр: заметил резкое падение числа посетителей с Яндекса в начале апреля и написал через форму обратной связи Яндекс Вебмастера в техподдержку о сложившейся ситуации и возможных проблемах ее вызвавших. В результате получил следующие ответ:
А какие страницы на дают... вот интересно, сам копайся и ищи )
ps нужно сделать помимо «вверх» также «вниз», а то долго листать стр до формы комеентария
Добрый день! Я правильно понимаю, с каждой страицы в title, надо всё же убрать название блога?
Вы я так понимаю, всё же убрали?
и ещё один вопрос, могу ли я в этом плагине, для каждой рубрики задать свой title?
у меня есть раздел под названием ВЫПЕЧКА, в title я хочу чтобы отображалось, к примеру РЕЦЕПТЫ ВЫПЕЧКИ С ФОТО. в самом вордпрессе рубрику так называть не хочу, так как не красиво, данный плагин это решает? если да то где конкретно это делается, объясните как для чайника и стоит ли вообще это делать? спасибо за суперский сайт!!!
Вопрос умный по поводу Google+
Есть брендовая страница, а есть просто страница
и то и то работает
какую ссылку добавлять?
и почему
"В связи с тем, что я запретил индексацию поисковыми системами архивов тегов, пришлось убрать со всех страниц блога ссылки на вебстраницы этих тегов. "
а если я не запрещал индексацию через этот плагин, а в robots.txt поставил запрет(/tag/), и при этому я не убирал со всех страниц блога ссылки на их вебстраницы? как тогда быть?
будет нормально если на страницах будут теги, а в robots.txt стоит запрет(/tag/)?
Спасибо огромное за статью! По поводу title в статьях через знак «|» конечно, вопрос не для такого новичка, как я... Но мне кажется, что раз плагин имеет прямую интеграцию с сервисами Гугл (тот же google+ и аналитикс), то человек, писавший этот плагин не просто так именно эту форму избрал 😉 не поленился я заглянуть и на его сайт. Было приятно заметить, что у него тоже в блоге именно %post_title% | %blog_title% Поэтому думаю, что это правильный подход.
Дмитрий, добрый день,
у меня в блоге установлен этот плагин. Настраивала по Вашим урокам еще давно. И вот заметила, что при репосте в социальные сети, например, или в соцзакладках не отображается тайтл, который прописан в плагине. Вместо него выводится ссылка на последнюю статью блога. В чем может таиться причина?
Спасибо за статью!
Вопрос от начинающего — установила этот плагин совсем недавно, настроила по вашей статье, вроде всё работает. Но потом оказалось, что не всё — теперь кнопки добавления гиперссылок в записи, которые в визуальном редакторе, не работают. До установки плагина all in one seo pack всё работало как надо.
Может это в последней версии такие изменения? Или что-то не так в настройках? Что посоветуете?
Юлия: извините, но визуальным редактором не пользуюсь — он у меня по какой-то загадочной причине не работает ни на одном из хостингов.
Дима, у меня такая же проблема, как и у ЛАРИСЫ. Плагин настроен так же как описано в Вашей статье.
НО!
Вместо названия статей в поисковой выдаче и перепостах в соц. сети выводится только название блога и ссылка на статью. А название статей не выводится. Как можно решить эту проблему? Может нужно title прописать где-то в кодах?
Юлия Ивановна: когда вы просматриваете исходный код страницы, то что у Вас отображается между тегам title? Если не название статьи, то причина в неправильной настройке данного плагина или конфликте его с чем-то еще.
Так же для социальных сетей можно использовать специальную разметку в коде для того, чтобы они правильно все формировали, но я пока этим вопросом плотно не интересовался. Можете погуглить на эту тему.
Когда просматриваю код:
Имя Блога
А как я понимаю нужно:
Название статьи | Имя блога
Юлия Ивановна: да, надо «Название статьи | Имя блога»
Здравствуйте.
Подскажите в чем может быть проблема... При просмотре кода страницы, в позиции выводятся ключевые слова и метки. То есть как бы дублируются ключевые слова. Например так: как приготовить хаш, хаш рецепт, хаш,как приготовить хаш,хаш,хаш рецепт
Этот сеопак проставил канонический урл для нескольких страниц с коментами к статье. Получается, что поисковик в тупо проигнорил коментарии и не проиндексил их, так как канонический урл ссылается на сам пост с небольшим кол-вом первых коментов.
Доброго времени суток!
Поставил плагин, но почему в заголовках не отображается %blog_title% на страницах и записях?
Отображается заголовок, который прописан в общих настройках блога.
Здравствуйте.
Спасибо за статью. У меня появился вопрос, есть мультиязычный сайт на 3 языках (http://site.com/, http://site.com/en и http://site.com/ru) и мне необходимо для каждой главной страницы сайта прописать свой title, как я могу это сделать с помощью данного плагина? И можно ли, чтобы главная страница брала title с материала, который на ней размещен? Мультиязычность сделана с помощью WMPL.
Здравствуйте!
Вчера обновил плагин all in one seo pack до версии 2.2.4
И там появились три новых пункта:
1) Enable Custom Canonical URLs (Здесь просто надо выбрать ставить галочку или нет)
2) Set Protocol For Canonical URLs (Здесь нужно выбрать один из вариантов:
1.Auto
2.HTTP
3.HTTPS)
3) Display Sitelinks Search Box (Здесь тоже нужно выбрать, ставить галочку или нет)
Подскажите пожалуйста, как поступить в этих пунктах?
Доброго времени. А если я удалю данный плагин и поставлю другой аналогичный этому. Ключевые слова надо будет перезаписывать вновь к статьям?
Здравствуйте!
А как можно сделать что бы мета теги прописывались на странице, в коде сразу после тега ?
А то почему то после только , а остальные мета теги идут где то внизу перед
Здравствуйте! В этой статье я узнал очень важную информацию, спасибо! Вы написали что лучше вообще не ставить на странице тех ссылок, которые закрыты от индексации (теги). На моем сайте теги закрыты от индексации, но в футере было облако тегов, и получается все публикации отдавали свой вес, закрытым от индексации тегам? Я убрал все теги с футера сайта и жду улучшения позиций и хоть и небольшого но роста посещаемости. Прошло 10 дней, но пока роста посещаемости не наблюдаю, буду ждать. Но вопрос не в этом. Вопрос в том что в каждой публикации у меня есть теги и они не отображаются на страницах, потому что я закрыл их в файле Single.php вот так (другому я не умею). Получается каждая публикация продолжает отдавать свой вес на закрытые от индексации метки (в некуда)? Как можно сделать так что бы поисковики не читали метки к каждой публикации? За ранее спасибо большое за ответ!!!
Здравствуйте, вижу что у вас сейчас стоит плагин all in one seo pack. Народ иногда пишет, что там уязвимости есть серьезные. Вы не видите в этом ничего страшного? Многие сейчас перешли на WordPress SEO by yoast. Что скажите об этом плагине? Какой seo плагин сейчас считаете лучшим?
Для подобных целей я использую https://wordpress.org/plugins/tidekey/ все куда более проще и понятней.
Подскажите пожалуйста, у меня на сайте стоит плагин all in one seo pack когда я размещаю запись у меня есть возможность указать канонический урл. специфика моего сайта это стихи. и многие стихи подходят под несколько рубрик. каноническая ссылка должна ссылаться на запись или можно на рубрику. могу ли я в качестве канонической ссылки указать корневую рубрику? и под каждый стих вписать в качестве канонического урл корневую рубрику? Или же в каноническом урл должна быть ссылка на одну из записей? Как правильно будет поступить. А то я уже много статей прочитал, но ни как не могу разобраться. Помогите пожалуйста.
Дмитрий, приходилось ли Вам сталкиваться с такой проблемой — ни один seo-плагин не отображается в исходном коде сайта на WP? Т. е. в редакторе прописываешь всё, что нужно, заполняя поля title и description, но в исходном коде ничего из этого не отображается, как и сам плагин (любой)?
Если да, в чём может быть дело, и как с этим справиться?
Инга: я б предположил, что в кеше проблема: либо самого WordPress (надоть сбросить кеш в настройках плагина за это отвечающего), либо браузера (обновите страницу удерживая Шифт на клавиатуре, а уже после этого смотрите исходный код).
Здравствуйте, Дмитрий! Хочу вам сказать огромное спасибо за очень полезный и подробный материал по такому важному seo плагину, как All in One SEO Pack. Я очень долго стоял перед выбором, какой сео плагин использовать у себя на блоге, но выбрал все-таки yoast seo, а не All in One SEO Pack. Но если бы Вы написали эту статью чуть раньше, то я бы наверное все таки склонился бы к All in One SEO Pack. Весь интернет перерыл в поисках правильной настройке этого плагина, но Вы все расставили на свои места по полочкам. Спасибо еще раз. С уважением, Валерий!
Инга: ну, тогда, может быть другой плагин блокирует (сам задает эти параметры). Попробуйте подозрительные деактивировать на время проверки.
Валерий: спасибо.
Дмитрий, я хочу к вам повторно обратиться! Я уже у Вас спрашивал по поводу интервью с вами, но Вы мне не ответили, может не увидели просто мой коммент? Если это возможно, то пожалуйста напишите мне ваш ответ. Я могу вам выслать вопросы на е-майл. Вот мой блог pribylwm.ru. Буду вам безмерно благодарен, если Вы согласитесь. Спасибо!
Валерий: Здравствуйте! Извините, но я не даю интервью. Спасибо.
Очень жаль Дмитрий! А очень хотелось бы вам задать несколько вопросов, как столь успешному блоггеру. Извините Дмитрий, но если Вы вдруг измените свое решение, то поставьте меня в известность. Буду вам признателен. С уважением, Валерий!
Многие блогеры жалуются на работу All in One Seo Pack. Есть его аналог Platinum Seo Pack. Очень схож по настройкам. Я сейчас тоже использую его. Нареканий пока никаких.
Дмитрий, спасибо за статью!
Из статьи я поняла, что, если мы ставим галочку no index для тегов, то с сайта надо убрать облако тегов. У меня англоязыяный сайт, и я оптимизирую его для гугла, т е для гугла будет то же правило и облако тегов надо убрать?
Спасибо
Не слушайте его, я имею ввиду создателя сайта. Все, что он или они говорят — это лишь заработок на Вас — посетителях. Создатели этого блога ни когда не расскажут об основных фишках в продвижении блогов, известных только им. Это их хлеб. Они знают, что делают и вся их работа заключается только в привлечении посетителей. Они дают лишь поверхностную информацию, коей напичкан интернет. Это так называемое — крысятничество. Разводилово, в своём роде. Удачи всем!
Прохор Игнатич: да, Вы правы! Мы (создатели сайта) просто волшебники и знаем «верное слово», которое никому и ни при каких обстоятельствах не откроем (иначе оно «затрется» и магия получится либо слабая, либо вообще никакая).
И таки да! Наша работа (и здесь никакой иронии нет) заключается в привлечении посетителей. А так же в их удержании и удовлетворении тех запросов, по которым они пришли. Как видите, все просто. Реализуется путем повышения приоритета работы над сайтом по отношению к остальным жизненным аспектам.
Ну, не знаю про крысячтничество (это вроде воровство у своих, если я правильно понимаю блатной жаргон). Видимо, для яркости добавлено...
Надеюсь, что Вы удовлетворены тем, что так удачно вывели «нас» (не хочу вносить сумятицу тем, что я один — пусть будет «коллектив авторов») на чистую воду. Тем более, что мы сами все сказанное подтвердили. Желаю и впредь так же ясно глядеть в суть вещей... Это не всем дано (Вы единственный из многих тысяч обнажили «неудобную правду»).
Здравствуйте. Очень полезный у Вас сайт! Дмитрий, если найдется минутка, а вопросов куча к Вам судя по трафику сайта, то буду очень благодарен, если ответите на пару вопросов:
1. Я только начинаю составлять сайт, собрал СЯ и долго думал над структурой, но пришел к тому, что мне на первом этапе будет достаточно одной рубрики, в которой можно написать достаточно много статей. Т.е тематика узкая и вся суть сайта бьет в одну точку. Отсюда вывод, что делать структуру на основе СЯ нет смысла. У меня просто каждая статья будет заканчиваться под НЧ запросы. А вот если я созрею для темы, требующие еще рубрику, тогда ее и сделаю. Т.е заранее не буду писать
100.500 рубрик и писать в каждой по 3 статьи. Статьи в рубрике я свяжу метками для удобного поиска и в каждой статье буду делать анкор на следующую статью с употреблением ключевого запроса того материала, на который и ведет ссылка.
Вывод по этому пункту: Сайт у меня не коммерческой тематики, он касается инвестиций, но ничего не продает, а дают людям полезные статьи. Ввиду этого не стал городить рубрики по ключам, а решил, что буду каждый материал оптимизировать под ключи походу. Верно сделал вывод?
2. Собственно об All in One SEO VS Yoast.
Какой из них выбрать сегодня? Понимаю, что дело вкуса, но все же от профессионала послушал бы. Очень заморочился с ними. Сайт только начал формировать и настраивать.
Заранее Вам благодарен!!!
Если она статическая (подробности читайте в статье про вид главной страницы и рубрик в WordPress), то смысл этих настроек теряется (в редакторе самой странички тоже самое можно прописать), посему можно будет переместить галочку в поле «Use Static Front Page Instead»
Прочитайте и исправьте, если не трудно
Добрый день!
Во-первых, спасибо за статью.
Я не сразу «просекла», что нет дискрипшн в вордпрессе.
Когда «просекла», стала искать выход и вот нашла вашу статью.
Установила этот плагин, настроила все именно так, как у вас здесь описано.
Яндекс после этого не быстро, но неумолимо стал убирать количество страниц из поиска — видимо это были страницы-дубли, которые родились от использования кнопочки «далее».
У вас в статье написано, что это хорошо, т.к. дублирование контента снижает сео-выдачу сайта. А вот у меня почему-то получилось по-другому — сайт после этого стал просаживаться в поисковой выдаче и примерно на 40-50 % упало количество посетителей сайта.
Отсюда вопросы:
1) может быть я все-таки что-то не так сделала.
2) может это быть временной «турбулентностью» Яндекса по причине того, что он еще не все страницу так прошерстил и почистил. Может быть после этого он все пересчитает заново и моя выдача и посещаемость станут лучше прежнего. Если так, то когда примерно ждать этого улучшения?
Спасибо за ответ!
Я установил плагин all in one seo pack, но карты сайта нет. Иду по ссылке — http://live4travel.com.ua/sitemap.xml а там вместо нее выдает ошибку «This page contains the following errors: error on line 2 at column 6: XML declaration allowed only at the start of the document
Below is a rendering of the page up to the first error.».
Такая же проблема была на плагине seo by yoast.
Огромная просьба к автору, дать коммент сложившейся ситуации!
Случайно обнаружил, что на ВСЕМ сайте пропали ключи... катастрофа просто для нас
При изучении настроек плагина оказалось, что внизу самом есть галочки по этой теме.
В общем плагин 5 лет работал обновлялся и тд, все было гуд! И тут вдруг сюрприз.
Сидим голову ломаем как так, обновление ли виновато или что-то другое...
Как восстановить можно все ключи, не подскажете? Через базу данных или в плагине есть история всего этого?
Спасибо!
Доброго времени суток. Подскажите пожалуйста какую версию плагина вы используете?
У меня плагин «all in one seo pack» версии 2.3.11.1 В закладке «настройка заголовков» не работает галочка напротив «Капитализировать метки и поисковые заголовки» и скорее всего из-за этого плагин делает заглавной первую букву всех слов, встречающихся в заголовке не только тегов но и рубрик
У данного плагина есть один недостаток — он не выводит мета-теги для страниц категорий и страниц тегов. Для этого можно использовать дополнительный плагин https://wordpress.org/plugins/seo-custom-fields/
Здравствуйте! Вы писали что убрали теги, так как ссылки ведут на страницы с архивом ссылки. У меня музпроект и теги это необходимая часть функциональности сайта. Можно ли как-то сделать чтобы статический вес не перетекал по этим тегам? Можно ли их как-то закрыть nofollow? Или другим способом?
Буду благодарен вам за ответ!
Установил плагин all in one seo pack.Не может создать карту сайта. Пишет:
Внимание: чтобы карта сайта была динамической, нужно включить постоянные ссылки.
Лазил по настройкам плагина, никак не пойму, где их включить
Как быстро должно обновиться в поисковой выдаче изменение титла и дескрипшн? Изменение титла не работает для Яндекса (пишут), есть ли какой-то выход?
Спасибо за статью!!
Как быстро должно обновиться в поисковой выдаче изменение титла и дескрипшн? Изменение титла не работает для Яндекса (пишут), есть ли какой-то выход?
Здравствуйте. Мы проводим внутреннюю оптимизацию сайта. Вебмастер нашел у нас ошибку: непрописанные Title и description. Сейчас мы это все прописываем. В связи с этим возник вопрос. Раньше Title формировался из названия товара, например, «Весенняя Швейцария», такой же лирический получался и URL карточки товара. Сейчас мы меняем большинство тайтлов под основной запрос. Вопрос: «Надо ли менять одновременно и URL карточек товаров, если эти „лирические“ URL уже проиндексированы. Есть ли смысл поменять разом все некорректные URL (их будет порядка 2/3 сайта) и отправить все на индексацию. Как лучше поступить в этой ситуации?»
Здравствуйте.
На маем странице поиска по сайту не отображается мета тег description с описанием страницы!
Пример ссылки на страницу поиска по сайту, Запрос «games» https://nexpro.ru/?s=games
Как сделать так чтобы мета тег description выводился на страницах поиска по сайту ?
Использую для SEO плагин All in One SEO Pack
Добрый день!
Правильно ли я понимаю, что после обновления (март 2021) плагин в бесплатной версии не выводит meta description в рубриках? Толькодля платной?
Если так, то как обойти этот недуг?
Спасибо!
Алексей: я не обновлялся в марте. На локальном сервере это обновление у меня крайне некорректно заработало и я решил воздержаться.
Дмитрий, спасибо за ответ!
Здравствуйте. Данный плагин выдает ошибку: External links No outbound links were found. Link out to external resources.
Может подскажите как убрать? Я вставил ссылку на второстепенную страницу, но не помогло.
Пробовал вставить 2 шт... тоже не помогло.
В статье версия плагина старая, сейчас он уже изменился до неузнаваемости... (
совершенно неактуально (
Ваш комментарий или отзыв