Как из списка URL адресов вычленить домены и убрать их повторы с помощью Notepad++ (готовим список для Disavow links)
Здравствуйте, уважаемые читатели блога KtoNaNovenkogo.ru. Суть задачи какая? У меня есть список URL адресов (обратные ссылки со страниц, ссылающихся на https://ktonanovenkogo.ru), которых более 60 000. Если вы в курсе, то в поисковой системе Гугл сейчас свирепствует злой Пингвин (читайте статью про то, как выйти из под фильтра Гугл Пингвин).
Есть такой инструмент отклонения ссылок в Google, как Disavow links. Когда я писал ту статью, то одни из читателей прислал мне выгрузку из Сео сервиса Ahrefs со всеми Урлами страниц, которые ссылаются на мой блог. Огромное ему за это спасибо.
Как загрузить в Disavow links список всех ссылок на сайт
Я потратил неделю на просмотр этих ссылок и составление списка для добавления в инструмент Гугла Disavow links. Получилось около тысячи доменов. Но через пару месяцев Пингвин меня клюнул еще сильнее (еще половина трафика с Google ушла в небытие).
Поэтому сейчас решился на крайние меры — добавить в этот список вообще все обратные ссылки. Сделать это напрямую не получается, ибо подобный список в формате txt весит около десяти мегабайт, а сервис Disavow links позволяет загружать файлы размером не более двух.
Выход я увидел в том, чтобы выделить из всего списка только доменные имена сайтов, которые на меня ссылаются, и добавить в бан-лист именно их (около трех тысяч доменов).
Данная задача разбивается на несколько этапов. Выделить и оставить в списке из всех Урл адресов только ту часть, где прописано доменное имя. Если помните, то в статье про URL адреса, а так же относительные и абсолютные ссылки, я рассказывал про их устройство. Например, ссылка на эту страницу (ее Урл — универсальный идентификатор ресурса) выглядит так:
В моем случае это был подобный список:
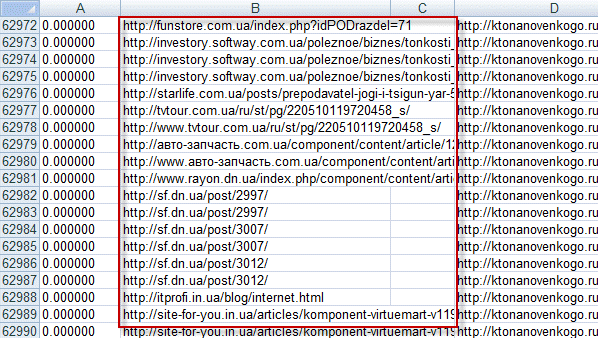
Мне же нужно оставить от этого URL адреса только домен:
ktonanovenkogo.ru
Т.к. в списке много ссылок с одного и того же домена, то потом нужно будет удалить все дублирующие строки. Ну и в строке с каждым доменом, в самом ее начале, нужно добавить «domain:», чтобы получилось так:
domain:ktonanovenkogo.ru
Список для Disavow links получился в таком виде:
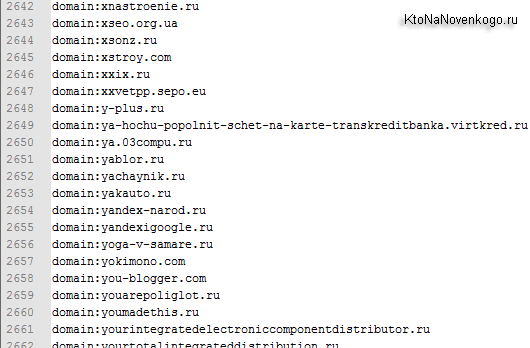
Для тех кто дружит с Excel задача решается с помощью написания соответствующих формул. Лично я хорошо знаю только Ворд, а вот на изучение Экселя в свое время терпения уже не хватило, да и не было тогда в этом особой необходимости.
Поэтому я решал данную задачу исключительно с помощью возможностей текстового редактора Notepad++ с его богатейшим функционалом и кучей полезнейших плагинов.
Как в Notepad++ удалить http:// и символы после определенного знака
Итак, сначала я выделил столбец с Урлами доноров в файле Excel и скопировал их в буфер обмена (кстати, на копирование ушли минуты, а не секунды, ибо объем был очень большой). После чего вставил его на новую страницу в Notepad++.
Сначала я избавился от http:// и https:// во всех строках. Для этого открываете в Нотепаде из верхнего меню пункты «Правка» — «Заменить» (можно просто нажать на Ctrl+H). В верхнее поле вставляете http://, а нижнее оставляете пустым.
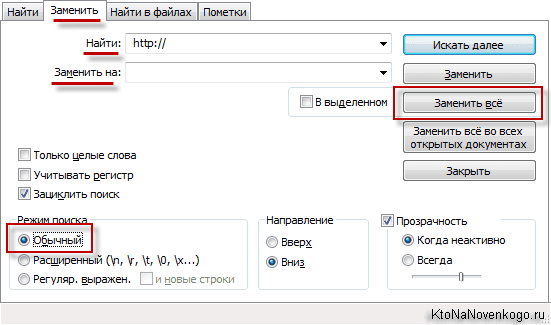
Жмете на кнопку «Заменить все». Потом в верхнее поле вместо http:// вставляете https:// и опять жмете на эту же кнопку. Получилось примерно так:
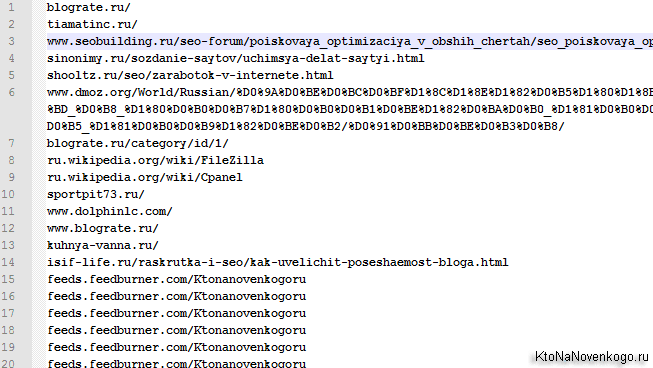
Следующей нашей задачей будет удалить в Notepad++ после определенного символа (первого слеша (/)) все, что там будет стоять. Для этого опять же жмете на Ctrl+H. Переходим в режим «Регулярные выражения» (внизу окна), вставляем в первое поле (/.+)$ (если вам нужно будет после другого символа все удалить, то вставьте его вместо слеша), второе поле «Заменить на» оставьте пустым и жмакайте на кнопочку «Заменить все».
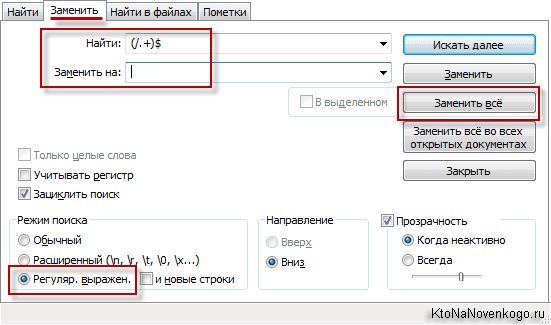
В результате наш список Урлов (а сейчас уже доменов) примет такой вид:
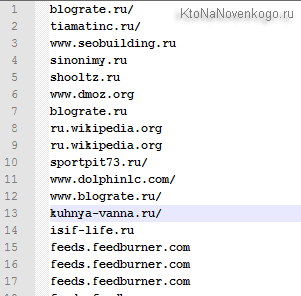
Кое-где в конце остались слеши, поэтому опять клацнете по Ctrl+H, перейдите в обычный режим и вставьте в верхнее поле слеш, а в нижние — ничего. Ну и на кнопочку «Заменить все» нажмите.
Теперь нам нужно удалить дублирующиеся строки в Notepad++ (одинаковые домены оставшиеся после их вычленения из URL адресов). Для этого нужно воспользоваться плагином для Нотепада под названием Text FX Caracters.
Как в Notepad++ удалить дублирующиеся строки и добавить символы в начало всех строк
Если он у вас еще не установлен, то выберите из верхнего меню текстового редактора «Плагины» — «Plagin Manager» — «Show Plagin Manager».
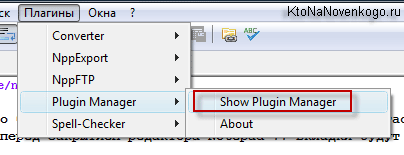
В открывшемся окне найдите Text FX Caracters, поставьте напротив него галочку и нажмите на расположенную внизу кнопку «Install».
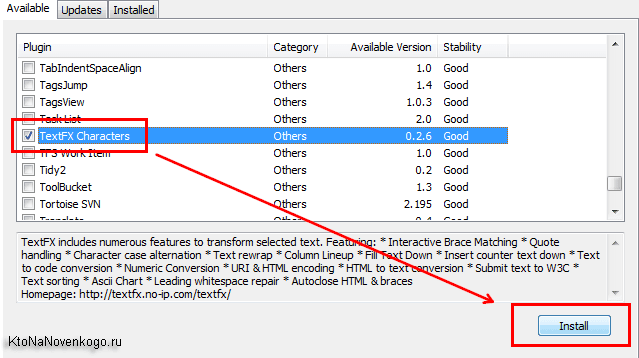
Теперь все строки в нашем документе нужно будет выделить с помощью CTRL+A, после чего выбрать из верхнего меню «TextFX» — «TextFX Tools» и поставить галочку в поле «+Sort outputs only UNIQUE (at column) lines». После чего опять зайти в «TextFX» — «TextFX Tools» и выбрать пункт «Sort Lines case sensitive (at column)».
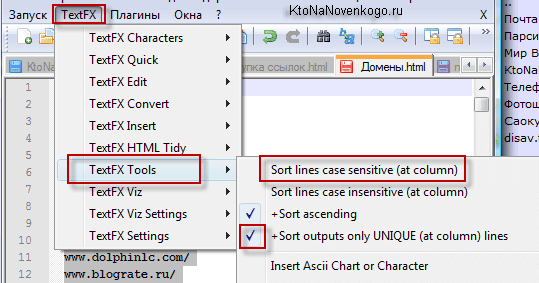
В результате все дубли строк в открытом окне Notepad++ исчезнут и останутся одни лишь уникальные домены.

Но в синтаксисе файла Disavow links для доменов необходимо вначале указывать «domain:». Значит перед нами стоит очередная задача: добавить символы в начале строки в Notepad++. Решается она довольно просто.
Опять же жмакаете по клавишам Ctrl+H и переходите в режим «Регулярные выражения». В верхней строке пишите «\n» (так обозначается символ перевода строки), а в нижней — «\ndomain:»:
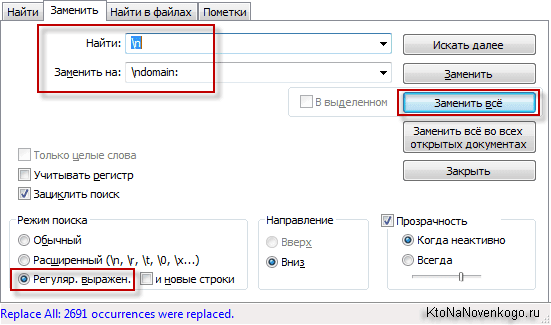
Жмете на кнопку «Заменить все» и получаете то, что нам и было нужно — готовый список, который смело можно будет загружать в Disavow links.
Все, спасибо за внимание.
Комментарии и отзывы (6)
Спасибо большое! Очень актуально для нынешних реалий... а то уже замучался через kvk делать...
Забыл как отсечь все после / Спасибо! Всем лечить пингвина.
Долгий вариант получается, каждый раз надоест делать. А поскольку лень двигатель прогресса, я как продвинутый юзер Эксель создал таки свой вариант обработки в Экселе и делюсь им в вашем блоге, Дмитрий, ибо очень благодарен вам, многие вещи на сайте я сделал по вашим инструкциям.
Итак, код у меня получился такой
=ПСТР(A3;ЕСЛИ(ЛЕВСИМВ(A3;5)="https";9;8);НАЙТИ(«/»;A3;9) -ЕСЛИ(ЛЕВСИМВ(A3;5)="https";9;8))
работает если Урл стоит в ячейке А3, естественно протягивается хоть на 10тыс. ячеек, хоть на миллион, благо Эксель 2010 позволяет. можно было бы сделать попроще, но я решил предусмотреть вариант с https.
смысл формулы следующий — берём Урл, и начиная с 8 позиции, а в случае https с 9 позиции, выделяем из него текст в количестве символов, равным разнице между позицией первого слэша после закрывания домена и 8 (9 в случае https). проще вроде некуда, правда с ходу наверное не очень понятно 🙂
забыл сказать. domain с лёгкостью прикрепляется с помощью функции =СЦЕПИТЬ(«domain:»;ссылка на домен)
а по поводу удаления дублей — меню Данные — кнопка «Удалить дубликаты» для Эксель 2010 и элементарная сводная таблица без каких-либо заморочек в Эксель 2003
а вообще Эксель лучше знать хоть немного, в нём с любыми текстовыми данными можно сотворить практически что угодно, причём как действовать конкретно можно всегда спросить у спецов на форумах, например, планета эксель — сам там пару раз консультировался
А как «точку» и «?» убрать?
а как перед слешем удалить?
Ваш комментарий или отзыв