Файл robots.txt и мета-тег robots — настройка индексации сайта Яндексом и Гуглом, правильный роботс и его проверка
При самостоятельном продвижении и раскрутке сайта важно не только создание уникального контента или подбор запросов в статистике Яндекса, но и так же следует уделять должное внимание такому показателю, как индексация ресурса поисковиками, ибо от этого тоже зависит весь дальнейший успех продвижения.
У нас с вами имеются в распоряжении два набора инструментов, с помощью которых мы можем управлять этим процессом как бы с двух сторон. Во-первых, существует такой важный инструмент как карта сайта (Sitemap xml). Она говорит поисковикам о том, какие страницы сайта подлежат индексации и как давно они обновлялись.

А, во-вторых, это, конечно же, файл robots.txt и похожий на него по названию мета-тег роботс, которые помогают нам запретить индексирование на сайте того, что не содержит основного контента (исключить файлы движка, запретить индексацию дублей контента), и именно о них и пойдет речь в этой статье...
Индексация сайта
Упомянутые выше инструменты очень важны для успешного развития вашего проекта, и это вовсе не голословное утверждение. В статье про Sitemap xml (см. ссылку выше) я приводил в пример результаты очень важного исследования по наиболее частым техническим ошибкам начинающих вебмастеров, там на втором и третьем месте (после не уникального контента) находятся как раз отсутствие этих файлов роботс и сайтмап, либо их неправильное составление и использование.
Почему так важно управлять индексацией сайта
Надо очень четко понимать, что при использовании CMS (движка) не все содержимое сайта должно быть доступно роботам поисковых систем. Почему?
- Ну, хотя бы потому, что, потратив время на индексацию файлов движка вашего сайта (а их может быть тысячи), робот поисковика до основного контента сможет добраться только спустя много времени. Дело в том, что он не будет сидеть на вашем ресурсе до тех пор, пока его полностью не занесет в индекс. Есть лимиты на число страниц и исчерпав их он уйдет на другой сайт. Адьес.
- Если не прописать определенные правила поведения в роботсе для этих ботов, то в индекс поисковиков попадет множество страниц, не имеющих отношения к значимому содержимому ресурса, а также может произойти многократное дублирование контента (по разным ссылкам будет доступен один и тот же, либо сильно пересекающийся контент), что поисковики не любят.
Хорошим решением будет запрет всего лишнего в robots.txt (все буквы в названии должны быть в нижнем регистре — без заглавных букв). С его помощью мы сможем влиять на процесс индексации сайта Яндексом и Google. Представляет он из себя обычный текстовый файл, который вы сможете создать и в дальнейшем редактировать в любом текстовом редакторе (например, Notepad++).
Поисковый бот будет искать этот файл в корневом каталоге вашего ресурса и если не найдет, то будет загонять в индекс все, до чего сможет дотянуться. Поэтому после написания требуемого роботса, его нужно сохранить в корневую папку, например, с помощью Ftp клиента Filezilla так, чтобы он был доступен к примеру по такому адресу:
https://ktonanovenkogo.ru/robots.txt
Кстати, если вы хотите узнать как выглядит этот файл у того или иного проекта в сети, то достаточно будет дописать к Урлу его главной страницы окончание вида /robots.txt. Это может быть полезно для понимания того, что в нем должно быть.
Однако, при этом надо учитывать, что для разных движков этот файл будет выглядеть по-разному (папки движка, которые нужно запрещать индексировать, будут называться по-разному в разных CMS). Поэтому, если вы хотите определиться с лучшим вариантом роботса, допустим для Вордпресса, то и изучать нужно только блоги, построенные на этом движке (и желательно имеющие приличный поисковый трафик).
Как можно запретить индексацию отдельных частей сайта и контента?
Прежде чем углубляться в детали написания правильного файла robots.txt для вашего сайта, забегу чуть вперед и скажу, что это лишь один из способов запрета индексации тех или иных страниц или разделов вебсайта. Вообще их три:
- Роботс.тхт — самый высокоуровневый способ, ибо позволяет задать правила индексации для всего сайта целиком (как его отдельный страниц, так и целых каталогов). Он является полностью валидным методом, поддерживаемым всеми поисковиками и другими ботами живущими в сети. Но его директивы вовсе не являются обязательными для исполнения. Например, Гугл не шибко смотрит на запреты в robots.tx — для него авторитетнее одноименный мета-тег рассмотренный ниже.
- Мета-тег robots — имеет влияние только на страницу, где он прописан. В нем можно запретить индексацию и переход робота по находящимся в этом документе ссылкам (подробнее смотрите ниже). Он тоже является полностью валидным и поисковики будут стараться учитывать указанные в нем значения. Для Гугла, как я уже упоминал, этот метод имеет больший вес, чем файлик роботса в корне сайта.
- Тег Noindex и атрибут rel="nofollow" — самый низкоуровневый способ влияния на индексацию. Они позволяют закрыть от индексации отдельные фрагменты текста (noindex) и не учитывать вес передаваемый по ссылке. Они не валидны (их нет в стандартах). Как именно их учитывают поисковики и учитывают ли вообще — большой вопрос и предмет долгих споров (кто знает наверняка — тот молчит и пользуется).
Важно понимать, что даже «стандарт» (валидные директивы robots.txt и одноименного мета-тега) являются необязательным к исполнению. Если робот «вежливый», то он будет следовать заданным вами правилам. Но вряд ли вы сможете при помощи такого метода запретить доступ к части сайта роботам, ворующим у вас контент или сканирующим сайт по другим причинам.
Вообще, роботов (ботов, пауков, краулеров) существует множество. Какие-то из них индексируют контент (как например, боты поисковых систем или воришек). Есть боты проверяющие ссылки, обновления, зеркалирование, проверяющие микроразметку и т.д.
Большинство роботов хорошо спроектированы и не создают каких-либо проблем для владельцев сайтов. Но если бот написан дилетантом или «что-то пошло не так», то он может создавать существенную нагрузку на сайт, который он обходит. Кстати, пауки вовсе на заходят на сервер подобно вирусам — они просто запрашивают нужные им страницы удаленно (по сути это аналоги браузеров, но без функции просмотра страниц).
Robots.txt — директива user-agent и боты поисковых систем
Роботс.тхт имеет совсем не сложный синтаксис, который очень подробно описан, например, в хелпе яндекса и хелпе Гугла. Обычно в нем указывается, для какого поискового бота предназначены описанные ниже директивы: имя бота ('User-agent'), разрешающие ('Allow') и запрещающие ('Disallow'), а также еще активно используется 'Sitemap' для указания поисковикам, где именно находится файл карты.
Стандарт создавался довольно давно и что-то было добавлено уже позже. Есть директивы и правила оформления, которые будут понятны только роботами определенных поисковых систем. В рунете интерес представляют в основном только Яндекс и Гугл, а значит именно с их хелпами по составлению robots.txt следует ознакомиться особо детально (ссылки я привел в предыдущем абзаце).
Например, раньше для поисковой системы Яндекс было полезным указать, какое из зеркал вашего вебпроекта является главным в специальной директиве 'Host', которую понимает только этот поисковик (ну, еще и Майл.ру, ибо у них поиск от Яндекса). Правда, в начале 2018 Яндекс все же отменил Host и теперь ее функции как и у других поисковиков выполняет 301-редирект.
Если даже у вашего ресурса нет зеркал, то полезно будет указать, какой из вариантов написания является главным - с www или без него.
Теперь поговорим немного о синтаксисе этого файла. Директивы в robots.txt имеют следующий вид:
<поле>:<пробел><значение><пробел> <поле>:<пробел><значение><пробел>
Правильный код должен содержать хотя бы одну директиву «Disallow» после каждой записи «User-agent». Пустой файл предполагает разрешение на индексирование всего сайта.
User-agent
Директива «User-agent» должна содержать название поискового бота. При помощи нее можно настроить правила поведения для каждого конкретного поисковика (например, создать запрет индексации отдельной папки только для Яндекса). Пример написания «User-agent», адресованной всем ботам зашедшим на ваш ресурс, выглядит так:
User-agent: *
Если вы хотите в «User-agent» задать определенные условия только для какого-то одного бота, например, Яндекса, то нужно написать так:
User-agent: Yandex
Название роботов поисковых систем и их роль в файле robots.txt
Бот каждой поисковой системы имеет своё название (например, для рамблера это StackRambler). Здесь я приведу список самых известных из них:
Google http://www.google.com Googlebot Яндекс http://www.ya.ru Yandex Бинг http://www.bing.com/ bingbot
У крупных поисковых систем иногда, кроме основных ботов, имеются также отдельные экземпляры для индексации блогов, новостей, изображений и т.д. Много информации по разновидностям ботов вы можете почерпнуть тут (для Google).
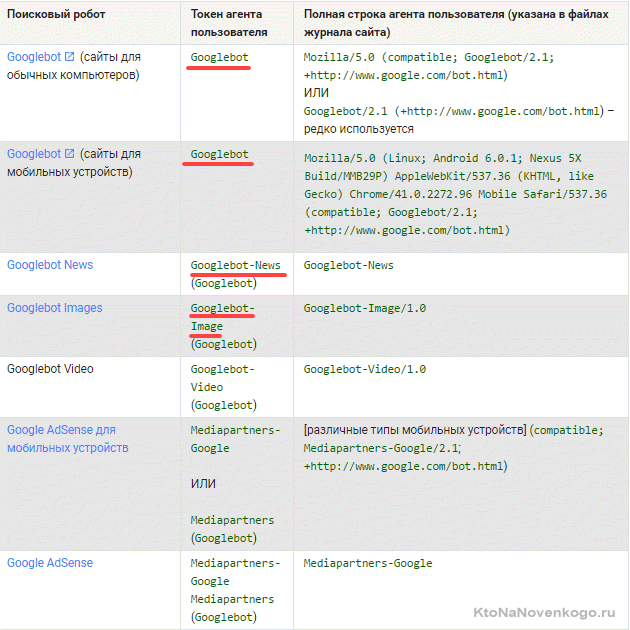
Как быть в этом случае? Если нужно написать правило запрета индексации, которое должны выполнить все типы роботов Гугла, то используйте название Googlebot и все остальные пауки этого поисковика тоже послушаются. Однако, можно запрет давать только, например, на индексацию картинок, указав в качестве User-agent бота Googlebot-Image. Сейчас это не очень понятно, но на примерах, я думаю, будет проще.
Примеры использования директив Disallow и Allow в роботс.тхт
Приведу несколько простых примеров использования директив с объяснением его действий.
- Приведенный ниже код разрешает всем ботам (на это указывает звездочка в User-agent) проводить индексацию всего содержимого без каких-либо исключений. Это задается пустой директивой Disallow.
User-agent: * Disallow:
- Следующий код, напротив, полностью запрещает всем поисковикам добавлять в индекс страницы этого ресурса. Устанавливает это
Disallowс «/» в поле значения.User-agent: * Disallow: /
- В этом случае будет запрещаться всем ботам просматривать содержимое каталога /image/ (http://mysite.ru/image/ — абсолютный путь к этому каталогу)
User-agent: * Disallow: /image/
- Чтобы заблокировать один файл, достаточно будет прописать его абсолютный путь до него (читайте про абсолютные и относительные пути по ссылке):
User-agent: * Disallow: /katalog1//katalog2/private_file.html
Забегая чуть вперед скажу, что проще использовать символ звездочки (*), чтобы не писать полный путь:
Disallow: /*private_file.html
- В приведенном ниже примере будут запрещены директория «image», а также все файлы и директории, начинающиеся с символов «image», т. е. файлы: «image.htm», «images.htm», каталоги: «image», «images1», «image34» и т. д.):
User-agent: * Disallow: /image
Дело в том, что по умолчанию в конце записи подразумевается звездочка, которая заменяет любые символы, в том числе и их отсутствие. Читайте об этом ниже. - С помощью директивы Allow мы разрешаем доступ. Хорошо дополняет Disallow. Например, таким вот условием поисковому роботу Яндекса мы запрещаем выкачивать (индексировать) все, кроме вебстраниц, адрес которых начинается с /cgi-bin:
User-agent: Yandex Allow: /cgi-bin Disallow: /
Ну, или такой вот очевидный пример использования связки Allow и Disallow:
User-agent: * Disallow: /catalog Allow: /catalog/auto
- При описании путей для директив
Allow-Disallowможно использовать символы '*' и '$', задавая, таким образом, определенные логические выражения.- Символ '*'(звездочка) означает любую (в том числе пустую) последовательность символов. Следующий пример запрещает всем поисковикам индексацию файлов с расширение «.php»:
User-agent: * Disallow: *.php$
- Зачем нужен на конце знак $ (доллара)? Дело в том, что по логике составления файла robots.txt, в конце каждой директивы как бы дописывается умолчательная звездочка (ее нет, но она как бы есть). Например мы пишем:
Disallow: /images
Подразумевая, что это то же самое, что:
Disallow: /images*
Т.е. это правило запрещает индексацию всех файлов (вебстраниц, картинок и других типов файлов) адрес которых начинается с /images, а дальше следует все что угодно (см. пример выше). Так вот, символ $ просто отменяет эту умолчательную (непроставляемую) звездочку на конце. Например:
Disallow: /images$
Запрещает только индексацию файла /images, но не /images.html или /images/primer.html. Ну, а в первом примере мы запретили индексацию только файлов оканчивающихся на .php (имеющих такое расширение), чтобы ничего лишнего не зацепить:
Disallow: *.php$
- Символ '*'(звездочка) означает любую (в том числе пустую) последовательность символов. Следующий пример запрещает всем поисковикам индексацию файлов с расширение «.php»:
- Во многих движках пользователи настраивают так называемые ЧПУ (человеко-понятные Урлы), в то время как Урлы, генерируемые системой, имеют знак вопроса '?' в адресе. Этим можно воспользоваться и написать такое правило в robots.txt:
User-agent: * Disallow: /*?
Звездочка после вопросительного знака напрашивается, но она, как мы с вами выяснили чуть выше, уже подразумевается на конце. Таким образом мы запретим индексацию страниц поиска и прочих служебных страниц создаваемых движком, до которых может дотянуться поисковый робот. Лишним не будет, ибо знак вопроса чаще всего CMS используют как идентификатор сеанса, что может приводить к попаданию в индекс дублей страниц.
Директивы Sitemap и Host (для Яндекса) в Robots.txt
Во избежании возникновения неприятных проблем с зеркалами сайта, раньше рекомендовалось добавлять в robots.txt директиву Host, которая указывал боту Yandex на главное зеркало.
Однако, в начале 2018 год это было отменено и и теперь функции Host выполняет 301-редирект.
Директива Host — указывает главное зеркало сайта для Яндекса
Например, раньше, если вы еще не перешли на защищенный протокол, указывать в Host нужно было не полный Урл, а доменное имя (без http://, т.е. ktonanovenkogo.ru, а не https://ktonanovenkogo.ru). Если же уже перешли на https, то указывать нужно будет полный Урл (типа https://myhost.ru).
Сейчас переезд сайта после отказа от директивы Host очень сильно упростился, ибо теперь не нужно ждать пока произойдет склейка зеркал по директиве Host для Яндекса, а можно сразу после настройки Https на сайте делать постраничный редирект с Http на Https.
Напомню в качестве исторического экскурса, что по стандарту написания роботс.тхт за любой директивой User-agent должна сразу следовать хотя бы одна директива Disallow (пусть даже и пустая, ничего не запрещающая). Так же, наверное, имеется смысл прописывать Host для отдельного блока «User-agent: Yandex», а не для общего «User-agent: *», чтобы не сбивать с толку роботов других поисковиков, которые эту директиву не поддерживают:
User-agent: Yandex Disallow: Host: www.site.ru
либо
User-agent: Yandex Disallow: Host: site.ru
либо
User-agent: Yandex Disallow: Host: https://site.ru
либо
User-agent: Yandex Disallow: Host: https://www.site.ru
в зависимости от того, что для вас оптимальнее (с www или без), а так же в зависимости от протокола.
Указываем или скрываем путь до карты сайта sitemap.xml в файле robots
Директива Sitemap указывает на местоположение файла карты сайта (обычно он называется Sitemap.xml, но не всегда). В качестве параметра указывается путь к этому файлу, включая http:// (т.е. его Урл).Благодаря этому поисковый робот сможете без труда его найти. Например:
Sitemap: http://site.ru/sitemap.xml
Раньше файл карты сайта хранили в корне сайта, но сейчас многие его прячут внутри других директорий, чтобы ворам контента не давать удобный инструмент в руки. В этом случае путь до карты сайта лучше в роботс.тхт не указывать. Дело в том, что это можно с тем же успехом сделать через панели поисковых систем (Я.Вебмастер, Google.Вебмастер, панель Майл.ру), тем самым «не паля» его местонахождение.
Местоположение директивы Sitemap в файле robots.txt не регламентируется, ибо она не обязана относиться к какому-то юзер-агенту. Обычно ее прописывают в самом конце, либо вообще не прописывают по приведенным выше причинам.
Проверка robots.txt в Яндекс и Гугл вебмастере
Как я уже упоминал, разные поисковые системы некоторые директивы могут интерпритировать по разному. Поэтому имеет смысл проверять написанный вами файл роботс.тхт в панелях для вебмастеров обоих систем. Как проверять?
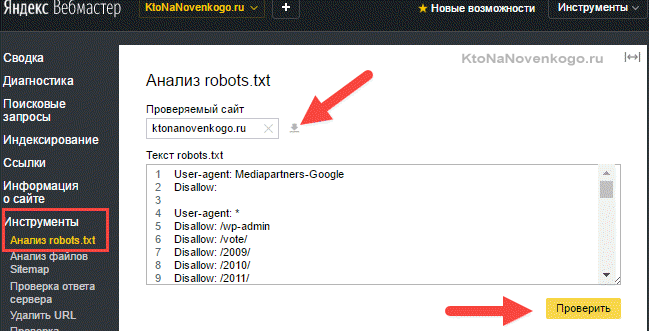
- Зайти в инструменты проверки Яндекса и Гугла.
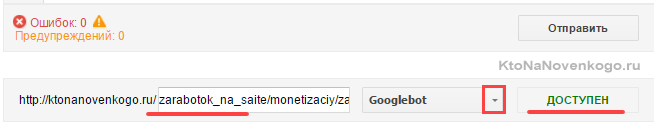
Убедиться, что в панель вебмастера загружена версия файла с внесенными вами изменениями. В Яндекс вебмастере загрузить измененный файл можно с помощью показанной на скриншоте иконки:

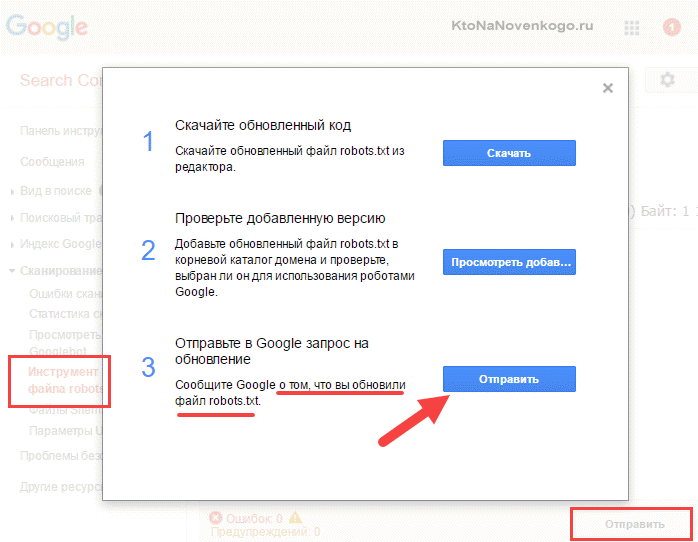
В Гугл Вебмастере нужно нажать кнопку «Отправить» (справа под списком директив роботса), а затем в открывшемся окне выбрать последний вариант нажатием опять же на кнопку «Отправить»:
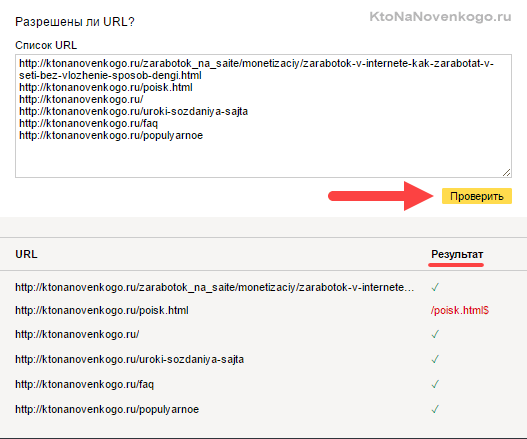
- Набрать список адресов страниц своего сайта (по Урлу в строке), которые должны индексироваться, и вставить их скопом (в Яндексе) или по одному (в Гугле) в расположенную снизу форму. После чего нажать на кнопку «Проверить».
Если возникли нестыковки, то выяснить причины, внести изменения в robots.txt, загрузить обновленный файл в панель вебмастеров и повторить проверку. Все ОК?
Тогда составляйте список страниц, которые не должны индексироваться, и проводите их проверку. При необходимости вносите изменения и проверку повторяйте. Естественно, что проверять следует не все страницы сайта, а ярких представителей своего класса (страницы статей, рубрики, служебные страницы, файлы картинок, файлы шаблона, файлы движка и т.д.)
Причины ошибок выявляемых при проверке файла роботс.тхт
- Файл должен находиться в корне сайта, а не в какой-то папке (это не .htaccess, и его действия распространяются на весь сайт, а не на каталог, в котором его поместили), ибо поисковый робот его там искать не будет.
- Название и расширение файла robots.txt должно быть набрано в нижнем регистре (маленькими) латинскими буквами.
- В названии файла должна быть буква S на конце (не robot.txt, как многие пишут)
- Часто в User-agent вместо звездочки (означает, что этот блок robots.txt адресован всем ботам) оставляют пустое поле. Это не правильно и * в этом случае обязательна
User-agent: * Disallow: /
- В одной директиве Disallow или Allow можно прописывать только одно условие на запрет индексации директории или файла. Так нельзя:
Disallow: /feed/ /tag/ /trackback/
Для каждого условия нужно добавить свое Disallow:
Disallow: /feed/ Disallow: /tag/ Disallow: /trackback/
- Довольно часто путают значения для директив и пишут:
User-agent: / Disallow: Yandex
вместо
User-agent: Yandex Disallow: /
- Порядок следования Disallow (Allow) не важен — главное, чтобы была четкая логическая цепь
- Пустая директива Disallow означает то же, что «Allow: /»
- Нет смысла прописывать директиву sitemap под каждым User-agent, если будете указывать путь до карты сайта (читайте об этом ниже), то делайте это один раз, например, в самом конце.
- Директиву Host лучше писать под отдельным «User-agent: Yandex», чтобы не смущать ботов ее не поддерживающих
Мета-тег Robots — помогает закрыть дубли контента при индексации сайта
Существует еще один способ настроить (разрешить или запретить) индексацию отдельных страниц вебсайта, как для Яндекса, так и для Гугл. Причем для Google этот метод гораздо приоритетнее описанного выше. Поэтому, если нужно наверняка закрыть страницу от индексации этой поисковой системой, то данный мета-тег нужно будет прописывать в обязательном порядке.
Для этого внутри тега «HEAD» нужной вебстраницы дописывается МЕТА-тег Robots с нужными параметрами, и так повторяется для всех документов, к которым нужно применить то или иное правило (запрет или разрешение). Выглядеть это может, например, так:
<html> <head> <meta name="robots" content="noindex,nofollow"> <meta name="description" content="Эта страница ...."> <title>...</title> </head> <body> ...
В этом случае, боты всех поисковых систем должны будут забыть об индексации этой вебстраницы (об этом говорит присутствие noindex в данном мета-теге) и анализе размещенных на ней ссылок (об этом говорит присутствие nofollow — боту запрещается переходить по ссылкам, которые он найдет в этом документе).
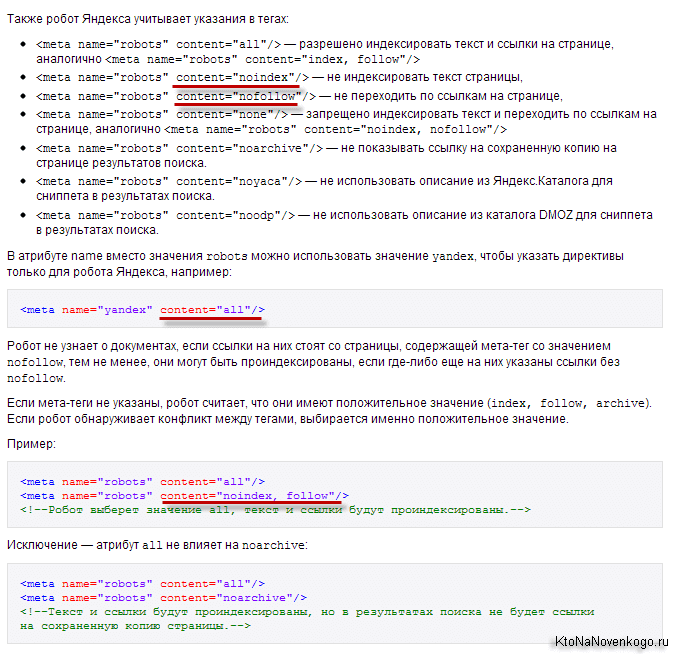
Существуют только две пары параметров у метатега robots: [no]index и [no]follow:
- Index — указывают, может ли робот проводить индексацию данного документа
- Follow — может ли он следовать по ссылкам, найденным в этом документе
Значения по умолчанию (когда этот мета-тег для страницы вообще не прописан) – «index» и «follow». Есть также укороченный вариант написания с использованием «all» и «none», которые обозначают активность обоих параметров или, соответственно, наоборот: all=index,follow и none=noindex,nofollow.
Более подробные объяснения можно найти, например, в хелпе Яндекса:
Для блога на WordPress вы сможете настроить мета-тег Robots, например, с помощью плагина All in One SEO Pack. Если используете другие плагины или другие движки сайта, то гуглите на тему прописывания для нужных страниц meta name="robots".
Как создать правильный роботс.тхт?
Ну все, с теорией покончено и пора переходить к практике, а именно к составлению оптимальных robots.txt. Как известно, у проектов, созданных на основе какого-либо движка (Joomla, WordPress и др), имеется множество вспомогательных объектов не несущих никакой информативной нагрузки.
Если не запретить индексацию всего этого мусора, то время, отведенное поисковиками на индексацию вашего сайта, будет тратиться на перебор файлов движка (на предмет поиска в них информационной составляющей, т.е. контента). Но фишка в том, что в большинстве CMS контент хранится не в файликах, а в базе данных, к которой поисковым ботам никак не добраться. Полазив по мусорным объектам движка, бот исчерпает отпущенное ему время и уйдет не солоно хлебавши.
Кроме того, следует стремиться к уникальности контента на своем проекте и не следует допускать полного или даже частичного дублирования контента (информационного содержимого). Дублирование может возникнуть в том случае, если один и тот же материал будет доступен по разным адресам (URL).
Яндекс и Гугл, проводя индексацию, обнаружат дубли и, возможно, примут меры к некоторой пессимизации вашего ресурса при их большом количестве (машинные ресурсы стоят дорого, а посему затраты нужно минимизировать). Да, есть еще такая штука, как мета-тэг Canonical.
Замечательный инструмент для борьбы с дублями контента — поисковик просто не будет индексировать страницу, если в Canonical прописан другой урл. Например, для такой страницы https://ktonanovenkogo.ru/page/2 моего блога (страницы с пагинацией) Canonical указывает на https://ktonanovenkogo.ru и никаких проблем с дублированием тайтлов возникнуть не должно.
<link rel="canonical" href="https://ktonanovenkogo.ru/" />
Но это я отвлекся...
Если ваш проект создан на основе какого-либо движка, то дублирование контента будет иметь место с высокой вероятностью, а значит нужно с ним бороться, в том числе и с помощью запрета в robots.txt, а особенно в мета-теге, ибо в первом случае Google запрет может и проигнорировать, а вот на метатег наплевать он уже не сможет (так воспитан).
Например, в WordPress страницы с очень похожим содержимым могут попасть в индекс поисковиков, если разрешена индексация и содержимого рубрик, и содержимого архива тегов, и содержимого временных архивов. Но если с помощью описанного выше мета-тега Robots создать запрет для архива тегов и временного архива (можно теги оставить, а запретить индексацию содержимого рубрик), то дублирования контента не возникнет. Как это сделать описано по ссылке приведенной чуть выше (на плагин ОлИнСеоПак)
Подводя итог скажу, что файл Роботс предназначен для задания глобальных правил запрета доступа в целые директории сайта, либо в файлы и папки, в названии которых присутствуют заданные символы (по маске). Примеры задания таких запретов вы можете посмотреть чуть выше.
Теперь давайте рассмотрим конкретные примеры роботса, предназначенного для разных движков — Joomla, WordPress и SMF. Естественно, что все три варианта, созданные для разных CMS, будут существенно (если не сказать кардинально) отличаться друг от друга. Правда, у всех у них будет один общий момент, и момент этот связан с поисковой системой Яндекс.
Т.к. в рунете Яндекс имеет достаточно большой вес, то нужно учитывать все нюансы его работы, и тут нам поможет директива Host. Она в явной форме укажет этому поисковику главное зеркало вашего сайта.
Для нее советуют использовать отдельный блог User-agent, предназначенный только для Яндекса (User-agent: Yandex). Это связано с тем, что остальные поисковые системы могут не понимать Host и, соответственно, ее включение в запись User-agent, предназначенную для всех поисковиков (User-agent: *), может привести к негативным последствиям и неправильной индексации.
Как обстоит дело на самом деле — сказать трудно, ибо алгоритмы работы поиска — это вещь в себе, поэтому лучше сделать так, как советуют. Но в этом случае придется продублировать в директиве User-agent: Yandex все те правила, что мы задали User-agent: *. Если вы оставите User-agent: Yandex с пустым Disallow:, то таким образом вы разрешите Яндексу заходить куда угодно и тащить все подряд в индекс.
Robots для WordPress
Не буду приводить пример файла, который рекомендуют разработчики. Вы и сами можете его посмотреть. Многие блогеры вообще не ограничивают ботов Яндекса и Гугла в их прогулках по содержимому движка WordPress. Чаще всего в блогах можно встретить роботс, автоматически заполненный плагином Google XML Sitemaps.
Но, по-моему, все-таки следует помочь поиску в нелегком деле отсеивания зерен от плевел. Во-первых, на индексацию этого мусора уйдет много времени у ботов Яндекса и Гугла, и может совсем не остаться времени для добавления в индекс вебстраниц с вашими новыми статьями. Во-вторых, боты, лазящие по мусорным файлам движка, будут создавать дополнительную нагрузку на сервер вашего хоста, что не есть хорошо.
Мой вариант этого файла вы можете сами посмотреть. Он старый, давно не менялся, но я стараюсь следовать принципу «не чини то, что не ломалось», а вам уже решать: использовать его, сделать свой или еще у кого-то подсмотреть. У меня там еще запрет индексации страниц с пагинацией был прописан до недавнего времени (Disallow: */page/), но недавно я его убрал, понадеясь на Canonical, о котором писал выше.
А вообще, единственно правильного файла для WordPress, наверное, не существует. Можно, кончено же, реализовать в нем любые предпосылки, но кто сказал, что они будут правильными. Вариантов идеальных robots.txt в сети много.
Приведу две крайности:
- Тут можно найти мегафайлище с подробными пояснениями (символом # отделяются комментарии, которые в реальном файле лучше будет удалить):
User-agent: * # общие правила для роботов, кроме Яндекса и Google, # т.к. для них правила ниже Disallow: /cgi-bin # папка на хостинге Disallow: /? # все параметры запроса на главной Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins Disallow: /wp/ # если есть подкаталог /wp/, где установлена CMS (если нет, # правило можно удалить) Disallow: *?s= # поиск Disallow: *&s= # поиск Disallow: /search/ # поиск Disallow: /author/ # архив автора Disallow: /users/ # архив авторов Disallow: */trackback # трекбеки, уведомления в комментариях о появлении открытой # ссылки на статью Disallow: */feed # все фиды Disallow: */rss # rss фид Disallow: */embed # все встраивания Disallow: */wlwmanifest.xml # xml-файл манифеста Windows Live Writer (если не используете, # правило можно удалить) Disallow: /xmlrpc.php # файл WordPress API Disallow: *utm= # ссылки с utm-метками Disallow: *openstat= # ссылки с метками openstat Allow: */uploads # открываем папку с файлами uploads User-agent: GoogleBot # правила для Google (комментарии не дублирую) Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: /wp/ Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */rss Disallow: */embed Disallow: */wlwmanifest.xml Disallow: /xmlrpc.php Disallow: *utm= Disallow: *openstat= Allow: */uploads Allow: /*/*.js # открываем js-скрипты внутри /wp- (/*/ - для приоритета) Allow: /*/*.css # открываем css-файлы внутри /wp- (/*/ - для приоритета) Allow: /wp-*.png # картинки в плагинах, cache папке и т.д. Allow: /wp-*.jpg # картинки в плагинах, cache папке и т.д. Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д. Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д. Allow: /wp-admin/admin-ajax.php # используется плагинами, чтобы не блокировать JS и CSS User-agent: Yandex # правила для Яндекса (комментарии не дублирую) Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: /wp/ Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */rss Disallow: */embed Disallow: */wlwmanifest.xml Disallow: /xmlrpc.php Allow: */uploads Allow: /*/*.js Allow: /*/*.css Allow: /wp-*.png Allow: /wp-*.jpg Allow: /wp-*.jpeg Allow: /wp-*.gif Allow: /wp-admin/admin-ajax.php Clean-Param: utm_source&utm_medium&utm_campaign # Яндекс рекомендует не закрывать # от индексирования, а удалять параметры меток, # Google такие правила не поддерживает Clean-Param: openstat # аналогично # Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent # не нужно). Google XML Sitemap создает 2 карты сайта, как в примере ниже. Sitemap: http://site.ru/sitemap.xml Sitemap: http://site.ru/sitemap.xml.gz # Укажите главное зеркало сайта, как в примере ниже (с WWW / без WWW, если HTTPS # то пишем протокол, если нужно указать порт, указываем). Команду Host понимает # Яндекс и Mail.RU, Google не учитывает. Host: www.site.ru
- А вот тут можно взять на вооружение пример минимализма:
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php Host: https://site.ru Sitemap: https://site.ru/sitemap.xml
Истина, наверное, лежит где-то посредине. Еще не забудьте прописать мета-тег Robots для «лишних» страниц, например, с помощью чудесного плагина — All in One SEO Pack. Он же поможет и Canonical настроить.
Правильный robots.txt для Joomla
Рекомендованный файл для Джумлы 3 выглядит так (живет он в файле robots.txt.dist корневой папки движка):
User-agent: * Disallow: /administrator/ Disallow: /bin/ Disallow: /cache/ Disallow: /cli/ Disallow: /components/ Disallow: /includes/ Disallow: /installation/ Disallow: /language/ Disallow: /layouts/ Disallow: /libraries/ Disallow: /logs/ Disallow: /modules/ Disallow: /plugins/ Disallow: /tmp/
В принципе, здесь практически все учтено и работает он хорошо. Единственное, в него следует добавить отдельное правило User-agent: Yandex для вставки директивы Host, определяющей главное зеркало для Яндекса, а так же указать путь к файлу Sitemap.
Поэтому в окончательном виде правильный robots для Joomla, по-моему мнению, должен выглядеть так:
User-agent: Yandex Disallow: /administrator/ Disallow: /cache/ Disallow: /includes/ Disallow: /installation/ Disallow: /language/ Disallow: /libraries/ Disallow: /modules/ Disallow: /plugins/ Disallow: /tmp/ Disallow: /layouts/ Disallow: /cli/ Disallow: /bin/ Disallow: /logs/ Disallow: /components/ Disallow: /component/ Disallow: /component/tags* Disallow: /*mailto/ Disallow: /*.pdf Disallow: /*% Disallow: /index.php Host: vash_sait.ru (или www.vash_sait.ru) User-agent: * Allow: /*.css?*$ Allow: /*.js?*$ Allow: /*.jpg?*$ Allow: /*.png?*$ Disallow: /administrator/ Disallow: /cache/ Disallow: /includes/ Disallow: /installation/ Disallow: /language/ Disallow: /libraries/ Disallow: /modules/ Disallow: /plugins/ Disallow: /tmp/ Disallow: /layouts/ Disallow: /cli/ Disallow: /bin/ Disallow: /logs/ Disallow: /components/ Disallow: /component/ Disallow: /*mailto/ Disallow: /*.pdf Disallow: /*% Disallow: /index.php Sitemap: http://путь к вашей карте XML формата
Да, еще обратите внимание, что во втором варианте есть директивы Allow, разрешающие индексацию стилей, скриптов и картинок. Написано это специально для Гугла, ибо его Googlebot иногда ругается, что в роботсе запрещена индексация этих файлов, например, из папки с используемой темой оформления. Даже грозится за это понижать в ранжировании.
Поэтому заранее все это дело разрешаем индексировать с помощью Allow. То же самое, кстати, и в примере файла для Вордпресс было.
Комментарии и отзывы (226)
а вот я не пойму правильно ли я robots.txt составил. у меня яндекс карту сайта не хочет принимать вот ошибка : Некорректный URL (не соответствует местоположению файла Sitemap) ничего не понимаю правильно всё. Без Sitemap замедлится индексация
Alex, простите, вы когда этот урл в адресную строку браузера вставляете, у вас карта сайта открывается?
да всё в порядке кажется я понял в чём дело,я неправильно файл robots заполнил щас обновил карту тоже посмотри что будет в Яндексе
Блогу на WordPress около 3х недель — google проиндексировал 59 страниц, остальные поисковики по одной, кто нибудь может подсказать в чем может быть проблема? Хотя судя по панели вебмастеров того же Яндекса робот регулярно на блог заходит.
test, есть определенные способы ускорить индексацию блога Яндексом, но не стопроцентные. Например, можно создать блог в Я.ру и написать текст со ссылкой на ваш блог WordPress. Тоже самое можно сделать на любом бесплатном блогохостинге (livejournal.com, blog.ru, liveinternet.ru и др.).
Иногда срабатывает способ создания ресурса на народе Яндекса с ссылкой в тексте на ваш блог. Можно попробовать добавить блог в яндекс закладки.
В joomla не правильно закрывать от индексации в robots.txt папку images. Закрыв ее от индексации вы не будете участвовать в поиске по картинкам Яндекса и Google. А если у вас еще и фото уникальные так будете терять еще один весомый аргумент, для показа поисковикам что ваш ресурс интересный .
ах в предудыщем коменте ошибся, по умолчанию в роботс от joomla images закрыт, в вашем примере его нет.
Alex, спасибо большое за напоминание. Я действительно открыл индексацию картинок, но забыл об этом упомянуть в статье. Сейчас добавлю. =)
обновил robots, но всё равно та же ошибка при попытке принять карту сайта в Яндекс. Некорректный URL (не соответствует местоположению файла Sitemap)
и вот ещё не только в Яндексе, но и в Google не принимает Sitemap, возможно, что тоже из-за неправильно созданного robots
Пути не совпадают
Мы обнаружили, что Вы передали Карта сайта используя путь, который не включает WWW префикс (например, http://example.com/sitemap.xml). Однако, URL, перечисляются внутри файла Sitemap делают использование WWW префикс (например, http://www.example.com/myfile.htm).
Уважаемый автор и уважаемый Alex! Огромное спасибо вам за замечание о том, что нужно разрешить индексацию картинок в robots.txt! У меня ресурс с открытками, и я всё не мог понять, почему их нет при поиске картинок Яндекса и Google. Как же я рад!!(наверное всем знакомо чувство,когда ищешь какую-то ошибку и потом ее находишь).
и у меня еще вопрос. На моем проекте ра Joomla (указан на нике) стоит virtuemart (в качестве каталога). Пользуюсь sh404sef для создания уникальных title. Проблема в том, что у меня создаются странички типа www.имя проекта/имя страницы.html?pop=0.
Над каждым товаром сверху у меня две ссылки с названиями, как я понимаю, двух ближайших товаров. Нажимая на эту ссылку, я перехожу по адресу нужной открытки, но в конце стоит эта приставка ?pop=0. Проблема в том, что Яндекс осуществил индексацию, почему-то именно этих адресов,а на их title не оптимизирован.Тоже получается дублирование контента. Как мне убрать эти адреса из индекса поисковиков и появятся ли потом адреса без приставки в поиске?
Ага, порадовался, что разрешил индексировать папку images в robots.txt, а потом понял, что картинки у меня хранятся в /components/com_virtuemart/shop_image. Что мне теперь делать? Разрешать индексировать /components/или внести запреты на все папки в /components/ кроме /com_virtuemart/?
Дмитрий, посмотрел в хелпе Яндекса, но ничего такого не понял 🙁
Здравствуйте, уважаемые эксперты! Вопрос об улучшении и ускорении индексации поисковиками картинок. У меня стоит virtuemart, картинки выводятся там java-скриптом. И после скрипта альтернативный вывод картинки в тегах .
Проблема: картинки не индексируются поисковыми системами!
Получается то, что заключено между тегами , поисковики не видят. Подскажите, пожалуйста, что можно сделать для индексации картинок в robots.txt?
извиняюсь, имелся ввиду тег noscript
Дмитрий:
Спасибо за ответ! Папка открытка для индексации поисковыми системами (научился благодаря вашему блогу). Думаю, проблема в самом выводе картинки.Она выводится через java-скрипт, а он не индексируется поисковиками. И, как видно, содержимое тегов noscript тоже. Как бы сделать так, чтобы сохранялось предназначение тегов noscript, и в то же время, картинка между этими тегами индексировалась? Кто знает, подскажите.
medvedev говорит, что:
Подскажи, пожалуйста как какую именно строчку в robots.txt надо вписать, чтобы товары в вирте индексировались поисковыми системами. С уважением.
Алексей: для решения проблем й убираете из стандартного файла для Joomla правило
Disallow: /components/Но в замен него добавляете в disallow на все папки внутри каталога components, кроме com_virtuemart, например:
Disallow: /components/com_banners/ Disallow: /components/com_contact/ и т.д.а есть ли какие-нибудь другие похожие расширения? или это только одно такого рода? (ARTIO JoomSEF.)
Спасибо! отредактировал
А то такое ощущение роботами мой сайт вообще не индексируется.
Яндекс определил главную, как закрытую . Но на сайте вообще нет этого файла! Не подскажите в чём может быть проблема?
Может мне сможете тоже помочь!? Проблема вот какого плана, в Яндекс Вебмастере мне выдаются предупреждения следующего вида:
— для главной
/index.php?format=feed&type=rss
/index.php?format=feed&type=atom
— и для страниц разделов тоже самое
/index.php/razdel?format=feed&type=rss
/index.php/razdel?format=feed&type=atom
Я так понимаю их можно запретить к индексации в robots.txt? А можно что то сделать с Joomla, чтобы эти страницы не генерировались?
Заранее спасибо!
Дмитрий у меня текст на главной странице не индексируется поисковиками, выдает ошибку:"Сервер не указывает тип документа, указывает неправильно или указанный тип не поддерживается Яндексом. " что это может быть и как это можно исправить?
Ой меня тоже очень волнует вопрос по поводу строчек rss в панели яндекс-вебмастера. И еще — как запретить к индексации страницы — ре6зультаты поиска (модуль Joomla стандартный)?
Ваш robot.txt запрещает индексацию всех страниц. Ошибка здесь:
Disallow: */trackback
Disallow: */*/trackback
Disallow: */*/feed/*/
Disallow: */feed
т.к. Disallow: */ — означает запрет индексации всех без исключения страниц.
Директиву Host с www надо указывать в robots.txt для Яндекса или без WWW?
не подскажите в чем может быть проблема, Яндекс произвел индексацию сайт, новые странички добавляет, но все странички видны только ТАЙТЛАМИ, под ссылкой нет текста. Как будто текст не про индексировался яндексом
MFT: этот текст под ссылкой в поисковой выдаче, если не ошибаюсь, называется сниппет. Так вот, на первых порах поисковики в качестве сниппета используют содержимое мета-тега DESCRIPTION. Возможно, что этот мета-тег у вас пустой. Подробнее об этом можете почитать здесь — Внутренняя оптимизация сайта
Подскажите пожалуйста. Создал блог на Joomla, Вроде все основные поисковики провели индексацию сайта нормально. Но я заметил что в Яндексе индексация страницы разбиения главной страницы (http://мой проект.ru/index.php, http://мой проект/index.php?start=10, http://мой проект/index.php?start=20 и т.д.) на будет ли это дублированием контента. Может мне в robots.txt запретить индексацию index.php.
Извиняюсь, ещё вопрос. В панели инструментов Googlе на те же страницы которые я приводил в предыдущем вопросе выдаёт «Повторяющиеся заголовки (теги title)» на повредит ли это индексации сайта. Заранее спасибо.
tschkh: вопрос конечно интересный, у меню точно такая же ситуация с индексацией, как и у вас. Никаких мер не предпринимал, пока полет, вроде, нормальный. Думаю, что не стоит заморачиваться с этим, а пока оставить так, как есть.
Здравствуйте!В статье приведен пример...у Вас перед строкой User-agent: * вставлен еще дополнительный код
User-agent:* Crawl-delay: 2 User-agent: Unknown robot Disallow: /его тоже лучше добавить? Спасибо!!!
Ирина: директиву Crawl-delay вы можете использовать в том случае, если на сервер вашего хостинга идет серьезная нагрузка (например, при большой посещаемости). Директива Crawl-delay (во всяком случае пытается) поисковому роботу минимальный период времени (в секундах) между концом закачки одной страницы и началом закачки следующей.
Т.е она определяет интенсивность индексации сайта поисковом роботом. Тем самым вы несколько снизите нагрузку, создаваемую поисковыми роботами. Если проблем с нагрузкой на сервер хостера нет, то директиву Crawl-delay можно не добавлять.
Всё понятно... спасибо за разъяснения по robots.txt... Удачи Вам и Вашему замечательному блоку 🙂
Кто может помочь ? Закачиваю robots.txt на хостинг (случайно удалил) в ответ получаю 553 Disk full — please upload later .А места на диске 14 гб.У кого какие мысли на счет этого ?
Добрый день! Подскажите кто понимает проблему. Sitemap Generator генерит много таких ссылок: http://mysite.com.ua/index2.php?vmcchk=1&option=com_virtuemart&category_id=6&page=shop.browse&Itemid=2&pop=1&tmpl=component
Вставил в Robot.txt правило: Disallow: /index2.php?vmcchk=1&
по примеру Disallow: /index2.php?page=shop которое рекомендоал Дмитрий, но все равно генерит... Что я сделал криво?
Prado: не знаю, к хостеру попробовать обратиться надо, наверное.
Андрей: вроде все должно работать.
У меня имя файла Site Map http://enioway.ru/index.php?option=com_xmap&sitemap=1&view=xml содержит знак «?», а такие файлы, т.е. дубли контента, запрещены к индексации. Чё делать? Может как то еще по другому дубли запретить индексировать?
А то бедный Гугл никак не может посмотреть мой Sitemap
Подскажите, как правильно запретить страницы к индексации с суфиксом html.
Сайт на Joomla.
К примеру, надо запретить индексировать страницу _https://ktonanovenkogo.ru/new а страница вида _https://ktonanovenkogo.ru/new.html нужна для индексации.
Спасибо огромное, надеюсь получить ответ.
Ольга говорит, что:
alan:Ольга, попробуйте вариант Disallow: /index.php?option=com_content* у меня такая же проблемма была, вродебы работает этот вариант.
Спасибо за интересный материал.
Спасибо за интересную статью! Практически все из нее уже давно применяю, но есть одно большое НО.
Яндекс очень долго не индексирует новые публикации на сайте (в день их добавляется около 4-5 штук, все эксклюзив). Новые статьи попадают в индекс только лишь спустя 2-3 недели!!! Google добавляет в поиск новые посту спустя 2-3 часа!!! Как так? Запарился уже — не знаю что делать, подскажите пожалуйста как ускорить индексацию Яндексом.
Здраствуйте, тоже вопрос по robot.txt Почему в Вашем варианте для Joomla нет запрета — Disallow: /components/, его открывать надо?
Может не в тему, у меня не индексируются картинки, хоть и убрал Disallow: /images/. Возможно криво работает галерея Ignite Gallery 2.1 ,не смог там прописать title 🙁
Подскажите пожалуйста
Добрый день, хочу запретить к индексированию один из разделов сайта. Все страницы этого раздела имеют адресацию index.php/razdel/*
Будет ли правильно выставить запрет так:
Disallow: /razdel/*
Спасибо за статью. Она помогла мне понять зачем и как создать файл robots.txt, поскольку с помощью другого плагина WordPress я заметил что Гугл индексирует таки не нужные страницы, надеюсь это исправить. Еще раз спасибо.
Подскажите как можно запрерить индексацию тегов.Использую компонент Joomla Tags
Disallow: /templates/
Для яндекса в джумле тоже надо убрать.
У меня там логотип сайта. Сижу и думаю почему в яндекс картинки никак не может попасть.
подскажите что прописать в роботс для Joomla, что бы запретить яндексу видеть старые названия категорий (менял название и плюс яндекс стал видеть id вместо названия итого три варианта одной статьи но по разным путям). Общий вид сайта после названия раздел потом категория и потом статья
Mosets Tree сохраняет картинки каталога внутри /components. Пока открыл директивой для индексаци — потом посмотрю как будет индексировать
milanox: весь процесс поискового продвижения состоит сплошь из таких мелочей, которые вы можете посчитать не существенными.
Но дело в том, что успех придет только при соблюдении всех этих мелочей и нюансов, ибо у поисковиком любой момент может стать ключевым для вашего ресурса.
ИМХО по собственному опыту. robots.txt желателен именно в таком виде, иначе возможны проблемы, которые вам вряд ли нужны.
Дмитрий подскажите пож.
Или кто понимает в этом вопросе.
Так получилось что я блог создал( на вордпресс) и закинул в инет.
Позавачера смотрел в яндекс вебмастере — яша нашёл был до этого одну страницу и то не главную.
Начал разбираться почему так , и узнал о файле этом, для чего нужен.
Я сегодня со смены пришёл и в срочном порядке создал как у вас на блоге и закинул в корневую папку.
Но недолго радость моя продолжалась — яша меня опередил. Сегодня зашёл в вебмастер, яша загрузил 43 стр и в поиске 27.
В общем проиндексировал всё что только можно. У меня страниц столько нет.
Теперь вопрос — какие последствия от такой «подробной» индексации будут ?
И теперь получается что хоть .есть у меня, яша запомнил весь тот мусор и будет помнить до конца ?
Не может быть такого что в следующий раз, увидя что файл показывает куда не надо заходить индексировать , яша о тех страницах забудет?
Извините за глупый вопрос. Хотя 1 и не глупый ( о последствиях такой инд.)
Виктор: у меня Google пару месяцев назад вообще по боку оставил robots.txt и насосал в индекс очень много запрещенных в этом файле страниц. Но в Google есть инструмент удаления ненужных страниц из индекса, а вот в Яндексе я такого инструмента не видел. Возможно, что со временем, мусор сам удалится из индекса.
Буду на это надеятся. Что остаётся , будет для меня урок на будущее.
В ответах маил один гуру написал- не забивай голову — Яндекс ненужное выкинет, нужное — оставит. Самое главное — чтобы контент уникальный был.
Здравствуйте,
у меня яндекс нашел 1 главную страницу тока,
связано ли это с disallow:/moduls/
так как ссылки с главной страницы на другие это же модуль меню?
Хотя на всех остальных страницах в мета теге стоит index, follow
Александр: нет, скорее всего это никак не связано, ибо disallow:/moduls/ запрещает индексировать поисковым системам содержимое каталога moduls (там лежат php, css и js файлы установленных у вас модулей — технический материал, который совсем не нужен и не интересен поисковикам), а ссылки из модулей меню к этому каталогу отношения не имеют.
Статья понравилась но я думаю что нужно для джумлы прописывать еще пару строчек :
Disallow: /index.php?
Allow: /index.php?option=com_xmap&sitemap=1
благодаря этому мы избавимся от лишнего мусора (дублей страниц) что как на меня уже хорошо , как думаете ?
Здравствуйте, после редактирования роботс, из Яндекса вылетели все страницы кроме главной, хотя сделал так, чтобы робот их видел. Но до этого часов 5 случайно поставил запрет их к индексации. Начнет ли Яндекс нормально сам индексировать вскоре сайт? Или писать платону?
Дмитрий, спасибо большое за такой оперативный ответ! и позвольте спросить вдогонку: туда имя сата писать с www или без?
Юлия: нужно использовать тот вариант, на который вы сделаете 301 редирект, ибо в случае ошибки вы полностью закроете ваш сайт от индексации Яндексом. У меня, например, не было необходимости прописывать 301 редирект с www.ktonanovenkogo.ru на ktonanovenkogo.ru, ибо это можно было настроить в панели моего хостера (Инфобокс), указав в качестве главного зеркала вариант ktonanovenkogo.ru. В robots.txt у меня, соответственно, прописано:
Host: ktonanovenkogo.ruпочему в robots у joomla не закрывается Disallow: /cgi-bin/
Дмитрий скажите пожалуйста, в вашей сборке robots.txt для ВП указанной в статье запрещена индексация архивов и меток? И разрешена индексация новостей?
Извините за тупой вопрос, но я ноль пока что.
Евгений говорит, что:
а действительно, эту папку нужно закрывать?
Спасибо автору!
Спасибо большое, замечательный материал.
Дмитрий, а как быть с .pdf,.doc их нужно закрывать от индексации? Потому что они вроде бы вес на себя забирают. Что скажете?
Подскажите пожалуйста, что нужно прописать для запрета на индексацию страниц типа /atom.html , /atom-2.html и так далее
а также для запрета /rss.html , /rss-2.html и т.д.
Как лучше удержать фотки в индексе ?!
Выводить их в статьи или в фотогалерее расположить ?
Автор пишет : "...для запрета индексации версий страниц для печати в VirtueMart, я добавил в файл robots.txt для Joomla следующее правило:
Disallow: /index2.php?page=shop "
Вопрос такой, конкретно куда его вставить, в верхнюю часть(которая для всех поисковиков) или для Яндекса которая.
И в конце ли аль в начале.
Я поставил в верхней части в самом низу (который для всех поисковиков), если я ошибся то исправте пожалуйста кто знает истину.
Спасибо за информацию! У меня есть один вопрос, если делать все правильно, то как делать настройки под robots WordPress плагина Platinum SEO Pack
Спасибо, как всегда очень информативно. Скопировал ваш robots.
Карточка товара в «Виртуемарте» отображается в двух категориях, например фотоаппарат отображается в категории «АКЦИИ» и в категории «Фототехника», соответственно адреса страниц двух категорий разные:
1). www.sait.ru/akcii.html?page=shop.product_details&flypage=flypage.tpl&product_id=25&category_id=6
2). www.sait.ru/akcii/bench.html?page=shop.product_details&flypage=flypage.tpl&product_id=44&category_id=17
Дмитрий подскажите пожалуйста как запретить к индексации определённую категорию, так как карточка товара одна и та же!
Не могу найти ответ.
Очень нужно. Спасибо!
Здравствуйте!
Я собираю блог на Денвере, учусь, читая Ваши материалы, за что огромное спасибо...
Подскажите пожалуйста, Вы написали в начале статьи — «(все буквы в названии должны быть в нижнем регистре — без заглавных букв)»
А в Вашем же примере:
«User-agent: *
Disallow: /administrator/
Disallow: /cache/»
итд...
строки начинаются с заглавных букв...
Как же правильно написать robots.txt писать?
Заранее спасибо
Здравствуйте, как закрыть от индексации роботом Яндекса страницы вида http://www.xxxxxxx.ru/tarifs_print.html (вариант для печати)
Я так понимаю, что вы сами еще ищете пути для избавления от дублей
Я смог только приостановить количество дублированных страниц на своем сайте( запрет на индексацию страниц в robots.txt не помогает ). В принципе это становится довольно актуальной проблемой для тех у кого сайт на wordpress, может кто нибудь поделится своим мнением насчет этого
Тут уже давно никто не отвечал, только вопросы.
Здравствуйте!
Подскажите пожалуйста, если я удалил проиндексированную страницу и на ее место поместил страницу с другим названием( т.е. поменял название). Есть необходимость прописывать в robots запрет на индексацию старой страницы или нет. Если да, то это сделать так — Disallow: /stranica.html?
Дмитрий, большое спасибо за отличный пост. Да и вообще ОГРОМНОЕ спасибо за разжеванную информацию по коду. До знакомства с Вашим блогом это для меня был темный лес, а теперь после прочтения нескольких постов, въезжать начал что к чему. Теперь программиста можно будет проверить, если он чего упустил, да и на сайты конкурентов теперь по другому смотришь 🙂 ! Еще раз спасиБО.
Андрей! Странный вопрос. Если был запрещён каталог то ничего менять не надо. Если страница, то да ваш вариант.
Здравствуйте!
Такой вопрос: У меня интернет магазин на Joomla, VirtueMart. Клиенты при регистрации вводят свои личные данные, включаю номера счетов. Что нужно прописать в robots, чтобы эти данные не попали в поисковики?
Спасибо.
не совсем понимаю как написать робота для этого сайта 2art.at.ua
если можно подскажите,буду благодарен можно на мыло maliyai1@ukr.net
если бы еще гугл банил за флуд...за тупой, накручивающий «сленг»...
тут 70% слов можно выкинуть...
я только хотел узнать о конкретных строках роботс.тхт в джумле...
а понять или нет — ето уже мое дело...либо интуиция поможет...либо в конце концов есть справочники...
Скажите пожалуйста, а сколько вам нужно заплатить, чтобы вы создали для моего сайта правильный роботс файл? не могу в этом разобраться, хоть стреляйся! некоторые люди утверждают, что мой роботс файл катастрофически не правильно составлен.
И теперь у меня возникла проблема: при размещении ссылки на сайте система биржи их не находит!Я в отчаянии! И спросить некого! Хоть плачь! На днях обновляла некоторые плагины, может быть из — за них такая проблема.
В правильном варианте robots.txt для joomla вы пропустили строку Disallow: /components/
Здравствуйте. Дмитрий, посоветуйте, в чем дело.
В панели Гугл Инструменты для Вебмастеров — Диагностика-Ошибки сканирования, Гуглебот в пункте «не найдено(404 не найдено)» — url страниц блога видит без рубрик. Идут: домен/название статьи.
Что необходимо изменить в robots.txt или дело в плагине All in One SEO Pack ( блог WordPress).
Спасибо.
Спасибо Дмитрий, за ответ.
Были некоторые сомнения насчет плагина XML Sitemaps. Попробую проследить такой вариант.
Дмитрий, думаю была в нем загвоздка.
Зашел по вашей ссылке на онлайн генератор(рус.) — пишут, что для сайтов на WordPress не делают!!!
А вот на англояз. сделали. В файле от плагина ссылок было 77, и без рубрик, а в новом 109 ссылок.
между директивами не должно быть пустых строк. Это будет означать начала нового правила.
Здравствуйте. У меня есть сайт, ему чуть больше полугода, но дело в том, что до сих пор проиндексировано только одна страница. Не могу понять по какой причине это происходит. Подскажите пожалуйста.
Спасибо.
Подскажите, а в каких случаях нужно ставить зарывающий слэш у правила? когда так Disallow: /category а в каком случае надо так
Disallow: /category/ Спасибо!
Подскажите, а в каких случаях нужно ставить зарывающий слэш у правила? когда так Disallow: /category а в каком случае надо так
Disallow: /category/ Спасибо!
Здравствуйте!
есть основной раздел и в нем есть страницы типа http://сайт.ru/раздел/?action=show&itemid=17
а есть еще подраздел... и из него идут такиеже страницы только с другими тайтлами и заголовками (там еще указывается название подраздела). Пишется как: http://сайт.ru/раздел/подраздел/?action=show&itemid=17. Так устроен движок да и удобно впринципе.
Но вот незадача... контент получается таким же. Поэтому требуется страницы подраздела закрыть в роботсе, но что бы сам подраздел http://сайт.ru/раздел/подраздел/ индексировался...
если сделать так :
Disallow: /подраздел/?action=show&itemid=*
так можно? не запретится ли тогда сам раздел? если да то как правильно сделать всетки?
Скажите пожалуйста, нужно ли дублировать для User-agent: Yandex правило Crawl-delay: 10 ,которое хостер накинул?
Дмитрий, добрый день!
Присоединяесь к вопросу Klivadenko33. У Вас на сайте не закрыта папка /category/. Получается частичное дублирование контента. Можно оставить так или лучше ее закрыть?
Заранее спасибо за ответ и за тот материал, который Вы абсолютно безвозмездно выкладываете на своем сайте.
VoVanMen: здравствуйте. Вывод в категориях у меня отличается от главной (the excerpt), а временные и теговые архивы я закрыл от индексации в All in One SEO Pack. ИМХО.
Дмитрий, а как на счёт того, что всё равно остаётся частичное дублирование текста на главной странице сайт и в самой статье? Вы ведь на главную страницу выносите первые несколько абзацев из самой статьи, а этот текст и получается небольшим дублем. Или поисковики не берут это во внимание?
Заранее спасибо за ответ!
Klivadenko33: это обычная структура для блога и поисковикам, очевидно, об этом известно. Ну, как бы, при борьбе с дублями они до абсурда не доходят. Ведь все обвязка сайта (шапка, футер, сайдбар) тоже дублируется на всех страницах и ее через robots.txt от индексации не закроешь.
Ну да, я с Вами полностью согласен!
Огромное Вам спасибо за ответ и за те статьи, которые Вы пишите для людей. Очень много нового узнаю именно из Вашего блога.
Всем добрый день.
П У меня сайт на джумле и все доки, картинки и т.д. я кидал в папку по умолчанию /images/stories/ В папке с images помимо папки stories еще полно других папок с хламом. Как мне используя роботс закрыть все папки в папке images помимо папки stories? У меня сейчас сделано так:
Allow: /images/stories/about-us/
Allow: /images/stories/base/
Disallow: /images/
Т.е. весь хлам помимо нужных папок about-us и base блокируется, правильно?
и второй вопрос: папки вложенные к примеру в /images/stories/base/ будут индексироваться? не нужно для них прописывать отдельное разрешение?
Дмитрий,каким образом внутри тега «HEAD» нужной страницы прописывается МЕТА-тег Robots? Как туда залезть?
Парни выручайте у меня магазин загружено роботами 10 000 (yandex) 15 000 (google), но в основной выдачи только по 100 страниц, думаю дело как раз в этих файлах, кто может детально посмотреть, отзовитесь
Доброго дня,
Сегодня решил проверить статью на уникальность и advego выдал мне что есть дубль. Получается, что сайт мой дублируется на дополнительный домен. Как запретить индексацию этого домена в robots.txt, если ненужный домен находиться по адресу: turdv.com/основной домен/
User-agent: *
Disallow: /turdv.com/основной домен/
Вот так?
Большущее спасибо за статью! Очень помогла!
Насчет Вашего правильного robots (a) для Вашего блога. У Вас же feed (ы) все в индексе Google. Я вот понять не могу, почему Google все равно индексирует feed (ы). Я уже с этим robots.txt что только не делал, а он все равно их индексирует.
Дмитрий, подскажите, пожалуйста, что значит Crawl-delay: 4 . Дело в том, что у меня есть такая строчка, в остальном он не отличается от приведенного в Вашей статье правильного для Вордпресс. Может ли это быть причиной того, что в Яндексе не индексируются страницы моего сайта?
Спасибо.
А какой правильный роботс для сайтов на динамическом HTML???
Подскажите пожалуйста, а то я уже собирался пихать туда роботс для джумлы
прошу прощения
в вашем robots.txt
есть и
User-agent: *
и тоже самое продублировано с
User-agent: Yandex
зачем?
я это к тому, что я вроде запретил файлы и директории
через User-agent: *
, а они все равно в индексе
Очевидно, для слурпа надо тоже дублировать все дерективы, как и для яндекса, а не ограничиваться двумя строчками
User-agent: Slurp Crawl-delay: 100Дмитрий, подскажите, пожалуйста. Ввожу название сайта и robots.txt выдает следующее:
User-agent: *
Disallow: /wp-admin/
Disallow: /wp-includes/
Пишу в Notepad++ файл как у Вас, загружаю в корневой каталог сайта. Результат тот же. Вроде бы с корневым каталогом не ошибся. Подскажите.
Сергей: возможно, что кеш браузера. Попробуйте в другом посмотреть.
Спасибо, Дмитрий, за ответ. Но, к сожалению, при просмотре в другом браузере результат тот же.
Добрый день. Периодически обращаюсь к Вашему блогу, очень интересно даже просто почитать.
Возможно подскажите. Правда сайт на dle. В robot.txt прописал следующую строчку: Disallow: /2011/
Эта строчка закрывает страницы по календарю, т.е. публикации по дате (в dle это дубли). После того как robot.txt посетил Яша кол-во посетителей упало на «200». Не совсем понятно, почему? Повторюсь это дубли и по этим страницам захода в принципе не было.
Заранее спасибо!
Если в meta-теге robots я пропишу index,nofollow. Будут ли индексироватья внутрение ссылки или nofollow закроет внутрение и внешние?
Не надо выдумывать, смотрю (*) ставят где им вздумается, как кто считает нужным, вот как нужно писать без «я придумал» яндекс пишет — http://help.yandex.ru/webmaster/?id=996567
В рекомендованном роботе для joomla у вас прописано
Disallow: /components/
в том, что вы считаете правильным роботс уже нет запрета для индексации Disallow: /components/
Отсутствие запрета для индексации папки components может привести к дублированию страниц в поисковиках
Статья хорошая, а комменты — «детский сад, штаны на лямках». Не хотите платить оптимизаторам, учите матчасть.
как правильно прописать в robots.txt
что бы сайт индексировался всеми поисковиками?
Не кайф читать статью и коменты полностью, может мой вопрос где нибудь уже оговаривался, но ПРОШУ КОНСУЛЬТАЦИИ!
У меня есть рубрика и к ней подрубрики " А Б В Г Д " в виде алфавита, как прописать в роботе чтоб эти подрубрики поисковики не индексировали (не нужны...), а главную рубрику индексировали конечно! ????
Пример урл такой /-/-/-/.ru›category/name/x/
Дмитрий, а если я вообще через robots.txt запрещу все кроме моих записей, страниц, главной, ну и карты сайта. Это нормально будет?)
Здравствуйте! Подскажите, пожалуйста, как запретить индексацию только одной определенной рубрики и всех страниц в ней?
Большое спасибо за ваш блог и эту статью!
Подскажите, пожалуйста, как мне быть. У меня на сайте (CMS Joomla) есть рубрики, созданные как шаблоны блога категории. Так вот яндекс проиндексировал только сами рубрики, а не статьи в них. Я запретила к индексации рубрики в надежде на то, что робот удалит из индекса их, но проиндексирует статьи. Рубрики есть в карте сайта. Я правильно сделала, или нет?
Данный роботс для вордпресс не закрывает ссылки комментариев
Сайт у вас очень интересный. У меня вопрос: я проверяю страницы своего сайта на плотность ключевых слов. И на страницах разделов я вижу, что ключевыми словами с большой плотностью являеются «Подробнее» и «Добавить коментарии». Как сделать так, чтобы эти слова не индексировались. Спасибо.
Всем доброго времени суток. Ребят а какой правельный robots.txt для DLE сайта на движке 9,4 ? Сколько читаю все пишут по разному.
Забыла добавить, сайт на wordpress
Здравствуйте. Скажите,у меня такая проблема. Поставил блог на вордпресс, роботс тхт не настраивал. Ну как поставил блог на вордпресс был на 4 месте в нужном мне регионе по необходимому запросу. Через неделю после очередного индексирования яндекса ушёл вообще с 1 страницы яндекса, и там 79 или какое то такое места занял. Робот.тхт поправил но поизции не изменились, прошло уже 2 недели с изхменения файла роботс.хтх.
Скажите, в чём может бытьб дело.
Спасибо.
Для Joomla роботс лучше писать так:
User-agent: *
Disallow: /administrator/
Disallow: /cache/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /libraries/
Disallow: /media/
Disallow: /modules/
Disallow: /plugins/
Disallow: /templates/
Disallow: /tmp/
Disallow: /xmlrpc/
Host: site.ru
Sitemap: httр://site.ru/index.php?option=com_xmap&sitemap=1&view=xml&no_html=1
Дмитрий, приветствую!
Ситуация. Сначала в блоге были УРЛы вида: myblog.ru/2012/postname
Потом я поменял на myblog.ru/postname
Теперь в индексе есть некоторые страницы как постарому, так и поновому. Но это распространяется не на все статьи.
Если заходишь на старый адрес — происходит переадресация на новый.
Нужно ли что-то делать, например закрывать путь /2012/* ?
Я смотрю, Дмитрий тут очень давно не отвечал (. А меж тем есть пара вопросов ((.
Дмитрий. Очень надеюсь на вашу помощь в понимании мною некоторых моментов.
1. На счет зеркал. Я оставляю бесплатную платформу и создаю блог на WP. Могу ли я в роботсе бесплатной платформы прописать диркторию Host с указанием нового сайта чтобы Яндекс не считал это дублями??
Есть ли аналог этой директории для Гугла и других поисковиков? и если нет, то как поступать с зеркалами в их отношении??
2. Поскольку есть Директива Disallow и Allow, а в случае конфликта отдается предпочтение второй, то — Могу ли я просто запретить индексацию всего командой Disallow, а при добавлении статей в блог просто вносить их статичный URL в роботс под директиву Allow?
Очень надеюсь на Ваш ответ.
Спасибо.
Здравствуйте Дмитрий! Возникла такая проблема, наткнулся в поисковике на то, что мой сайт еще проиндексирован с приставкой xsph.ru, т.е выглядит как site.ru.xsph.ru ? подскажите пожалуйста как мне в файле robots.txt запретить к индексированию данный сайт??
Заранее благодарен за ответ!
Здравствуйте Дмитрий!
Скажите, стоит ли добавить такие строки в роботс:
Disallow: /search
Disallow: /page
Нельзя в WordPress рекомендовать в robots.txt писать строку Disallow: /*?*, т.к. у многих страница имеет адрес вида http://*sitename*/?m=201208. Получается, все страницы с «?» будут запрещены к индексации.
Sitemap: https://ktonanovenkogo.ru/sitemap.xml.gz
Sitemap: https://ktonanovenkogo.ru/sitemap.xml -
— А зачем в robots указывать сразу два? Разве одного этого:
Sitemap: https://ktonanovenkogo.ru/sitemap.xml — недостаточна?
Как правильно в robots для wordpress скрыть вот такие архивы:
/2012/08/24
/2012/09
и т.д.
Кто-нибудь знает?
А почему в правильный robots.txt для WordPress не закрыты индексация комментариев???
Существует ли ограничение по символам для файла robots.txt?
Иван Евгеньевич: в общем то, это лишнее. Предназначено для бота Гугл Адсенса.
Help!
Как грамотно запретить к индексации весь сайт полностью (и главную страницу и все статьи)
за исключением одного раздела (и статей в нем)?
Примерно
User-agent: *
Disallow: /
Allow: /dadada (и все статьи начинающиесяна dadada)
Помогите, а то никак не пойму.
Скажите, а как закрыть от индексации главную страницу? Но чтобы остальные индексировались?
Привет всем.
Ребят срочно нужна ваша помощь, сколько не искал, то брет какой то, то еще что-то.
Не подскажете какой robots.txt лучше всего использовать для «osCommerce».
Привет!
А какое время требуется боту Яндекса проиндексировать новый robot.txt ?
подскажите, в моём роботс.тхт присутствуют ещё запреты на некоторые папки, это правильно или запрет лучше снять для более качественной и полной индексации? вот эти строки:
Disallow: /cli/
Disallow: /components/
Disallow: /logs/
Вам следовало бы написать «Правильный robots.txt для joomla без дополнительных компонентов» — как то так, потому что с такими директивами индексация многих не нужных страниц всё равно будет производиться.
User:* — для любого поискового робота (для всех т.е Yandex Google можно не указывать)
Что бы индексировались товары в virtuemart достаточно при заполнении во вкладке описания товара в строке для meta robots внести index, follow
не могу найти ваших контактов
Здравствуйте у меня сайт на укоз, что означает когда после директивы dissallow стоит index/1 таких директив несколько и разные цифры
Сергей, самый оптимальный вариант — это запретить отображение названия категории в URL. И ссылка в каждой твоей категории будет одинаковой: сайт.ру/салат
Вот это интересно, никогда не слышал о таком способе. А как это сделать? И как к этому отнесутся поисковики? Такой вариант был бы вообще самым шикарным. И страницы будут все второго уровня тогда?
Это делается просто. В админке заходишь в меню материалы, там выбираешь параметры. Название категории — скрыть.
Да уж...вы тут сейчас насоветуете ))))
Причем тут название категории? Название категории отображается на странице материала, когда вы зашли на страницу уже и читаете материал, а я говорю про урлы страниц этих самых материалов. Когда каждый материал доступен по разным адресам.
В роботсе для Джумлы можно добавить запрет директории components/
Здравствуйте! я только создаю сайт визитку страниц на 5 не более, страницы не большие 1000—2000 символов, движок свой, есть анимация, стараюсь без всякой явыскрипт, а по старому по html для кроссброузерности и у меня вопрос: нужно ли мне все эти robots.txt, Sitemap.xml ставить (потому как везде в сети «если много текста, страниц...» понятие растяжимое) много ли пользы будет от этого в моём случае?
Доброе время суток! Не могу составить robots.txt. Т.е могу, но боюсь ошибиться. Есть страница, которую надо запретить от индексации mysite.ru/view_news.php?id=1 для всех роботов. Подскажите как это сделать правильно.? Если ее запретить от индексации, то получается все страницы начинающие с view_ тоже будут недоступны? А у меня они все начинаются с view_. К примеру:mysite.ru/view_gde_zarabotat_deneg.php?id=1 и она должна быть доступна. Или я чего-то не понимаю.? Заранее благодарен. Жду скорейшего ответа.
Здравствуйте, Дмитрий!
При анализе работы моего сайта (htpp:\\kavent.ru) Гугл индексирует намного больше страниц, чем их и меня физически.
Из Вашей статьи я понял, что это не очень хорошо, но как это устранить не понял.
Сайт сделан на движке Joomla.
Буду очень признателен за подсказку.
С уважением, Андрей.
Каким образом, возможно, удалить старую отдельную страницу через файл robots? Заранее весьма Вам буду благодарен за ответ.
здравствуйте!
Так, что написать в роботе, если я хочу иметь дело только яндексом, гуглем и маил ру
Disallow: /*? — что означает эта запись?
И как мне запретить к индексации страницы, имеющие в урле запись: .../?controller=default&task=callelement&format=raw&eleme...
Присоединяюсь к вопросу:
Как правильно в robots для wordpress скрыть вот такие архивы:
/2012/08/24
/2012/09
и т.д.
Кто-нибудь знает?
Поделитесь, пожалуйста, актуальным шаблоном robots.txt для blogspot!
Отличный пост, доходчиво. Большое спасибо!
Хотел поблагодарить вас за вашу статью и за книгу в целом! вот сейчас осваиваюсь очень познавательно! Хоть начал понимать что такое СЕО и с чем его едят =))) еще раз спасибо!
А что это значит
User-agent: Mediapartners-Google
Disallow:
Закрыть Гуглу все ?
Здравствуйте,
Очень интересный материал.
Подскажите пожалуйста, :
User-agent: *
Disallow: /wp-admin/
Disallow: /wp-includes/
Что это значит? особенно 3-я строка «Disallow: /wp-includes/»
В панели веб мастер выходит — Документ запрещен следующего вида:
сайт.ru/wp-includes/wlwmanifest.xml — за что отвечает данная страница?
Заранее благодарен.
Дмитрий, Вы разбиваете файл robots.txt на две части, для роботов всех поисковиков (*) и для яндекса (yandex) отдельно. Все правильно, но почему Вы не указываете карту сайта для всех поисковых роботов?
Допустим гул не нуждается в директиве host — это понятно, она нужна яндексу, но от подсказки адреса карты сайта гугл не откажется=)
Александр: ну, наверное, да. Можно было бы его под общие правила подпихнуть, но, как я понимаю, он сам по себе. К тому же, есть мнение, что, например, молодому ресурсу или какому-либо другому лучше всего эту запись из роботса убрать.
Зачем палить все свои странички всяким редискам. При этом реальный файл карты сайта назвать yieieffdfs.xml и закопать в папочку десятого уровня вложенности. Ну, а потом быстренько пробежаться по панелям вебмастеров и сообщить кому надо (Яндексу, Гуглу, Бингу, Майл.ру), где это чудо лежит. Такие вот советы сейчас дают.
Дмитрий, «но, как я понимаю, он сам по себе» — это я так понимаю Вы о сайтмапе? Не уверен, но склоняюсь к мысли, что поисковики не учтут его если он будет в директиве для яндекса. Не знаю, но всегда прописываю его в обеих частях.
Насчет второй части — полностью согласен=)
Дмитрий, спасибо за статью! В Вашем роботсе есть вот такая запись:
Disallow: /?feed=
Disallow: /*?*
Disallow: /?s=
Вопрос:
Разве вот эта строчка Disallow: /*?* не запрещает доступ к урлам в которых есть знак «?»
Обязательно ли прописывать вот эти две строчки:
Disallow: /?feed=
Disallow: /?s=
Вроди как эти две строки дублируют правило Disallow: /*?*
Для меня — начинающего, статья очень интересная. Огромное спасибо за полезную информацию по созданию файла robots.txt. Мой сайт — на Joomla. Подскажите, как прави льно определить главное зеркало сайта, чтобы прописать в этом файле директиву Host?
Платону письмо так и так, у меня такая хрень былая... сайту больше года, а ноль проиндексированных картинок было.
Написали в ответ, проблему исправили, ждите.
Через месяц появилось 49 картинок, жду снова апа картинок.
Огромное спасибо за robots.txt для wordpress!
Добрый день, Дмитрий!
Много полезной информации в Вашей статье. Хотел уточнить один вопрос: что нужно все-таки прописать в robots.txt для сайта на Joomla для закрытия от индексирования страниц — дублей? В комментариях два варианта увидел, но, все-таки, хотелось узнать Ваше мнение.
Спасибо.
Добрый день, Дмитрий.
Подскажите, пожалуйста, это нормально ли что яндексом загружено более 2000 страниц, а в поиске 123?
А че запрещено тут: Disallow: /cgi-bin и как быть с папками js и css ?
Здравствуйте, Дмитрий.
Яндекс проиндексировал страницы сайта без .html и с .html.
Как закрыть индексацию страниц без .html в robots.txt.
Спасибо за Ваш труд.
Я много узнал интересного и полезного на вашем сайте.
Удачи!
Отличная и информативная статья.
Подскажите, если форум smf стоит в корневой папке wordpress, то нужна ли ему отдельная функция построения карты сайта или нет? С условием, что у wp уже есть свой такой плагин.
Везде информация по файлу Robots для сайтов на платформе WordPress. Что делать у кого блог на платформе Blogger. Как этот файл создавать на Blogger? Автор этого замечательного умного и очень интересного сайта — может что-то порекомендовать?
Здравствуйте. Подскажите пожалуйста, как исключить из роботс не админ панель, а именно админ бар?
На моем сайте возникла огромная куча ошибок, которые засели именно в Admin bar Custimaize. Это ссылка, которую я давно не могу удалить потому, что не вижи ее!!
Хочу хотя бы временно заблокировать админ бар пока не исправлю.
У меня Гугл хорошо индексирует сайт, а Яндекс проиндексировал тоько главню, еще 10 попали в список исключений, ответ такой: страницы содержат мета-тег ноиндекс. При этом у Гугла они в индексе после первого апа. Роботс такой-же кстати как у вас в публикации, Вордпрессовский. Я страницы смотрел, нет там мета тегов запрещающих никаких! Я думаю это настройки All in One. У меня и этот плагин настроен как у вас в статье был, кроме того, что стояла галочка напротив запрета индексации архивов рубрик. Снял. Непойму, где ошибка! Сайт filwebs.ru
Егор сайту 22 дня, так что рано панику поднимать на счет яндекса, добавьте в адурили на худой конец, нет никаких ноиндексов в коде.
Здравствуйте.
Никак не могу решить вопрос. Может тут мне помогут. Скажите пожалуйста как запретить пользователям открывать роботс? Например сейчас любой может перейти по ссылке http://имясайта.ru/robots.txt и увидеть какие страницы я прячу
User-agent: *
Disallow: /superzag
И перейдя по адресу http://имясайта.ru/superzag может перейти на страницу которую я разрешаю просматривать только подписавшимся на мой блог пользователям.
Можно как то сделать что бы люди не могли отрывать роботс.тхт? Что бы при попытке открыть
их переадресовывало на другую страницу. Или может даже выдавало ошибку 404. Да что угодно
лишь бы никто не видел этот файл.
Но для поисковых роботов все должно быть как положено, что бы они нормально воспринимали
роботс файл.
Алексей, просто добавьте следующую строчку в конфигурацию Apache или в .htaccess файл:
Options -Indexes
Это не тоже самое, что добавление Disallow: /wp* в файл robots.txt. Это не запретит индексацию директории, а запретит юзерам просмотр.
Егор, добавил строку
Options -Indexes
в .htaccess файл.
Однако по прежнему могу открывать роботс в браузере и видеть что там написано.
Или я не так сделал что-то? Или не так понял?
Алексей, у вас на хостинге не спящая техподдержка? А если серьезно, то напишите в саппорт (тех.службу) хостинга, думаю, что проблема будет решена.
Здравствуйте!
Подскажите пожалуйста, нужно ли закрывать от индексации страницы авторов сайта?
У меня на сайте у авторов (в данный момент только у меня, как админа) есть отдельные страницы с уникальными урлами, где представлены все статьи с их кратким описанием.
Данная страница у меня попала в индекс.
В связи с чем получились дубли, на сколько я понимаю.
Нужно ли t прописать строку: Disallow: /author/*/* ??
Буду очень признателен за помощь!
Здравствуйте. Первый свой сайт делал по вашим урокам. Спасибо. Подскажите пожалуйста, могут ли роботы гугл заходить на сайт через поисковик или у меня появился поисковый спам?
Здравствуйте.С помощью этой статьи наконец-то научился составлять роботс.
Но появилась одна проблема: Почему-то блогспот не принимает роботс с указанием главного зеркала. Пишет: содержимое robots.txt не соответствует правилам форматирования. Объясните пожалуйста в чем проблема.
На одном из сайтов в примере robots. txt предложено удалить Disallow: /*?* эту позицию.
А у вас она присутствует. Поясните. http://somemoreinfo.ru
Вот как выглядит мой Robots.txt:
User-agent: *
Disallow: /search
User-agent: Mediapartners-Google
Disallow:
Sitemap: http://мой сайт/sitemap.xml
Думаю что в моем случае удалять disallow, не лучший вариант. Потому-что без нее в поиске гугл появляются дубликаты страниц. Может вы знаете как это дело исправить.
здравствуйте, подскажите пожалуйста!! Что означает вот такой роботс:
Disallow: /
Disallow: /users
Disallow: /admin/*
означает это то, что в роботсе запрещено индексировать все директории, адрес которых начинается с Users и admin
Здравствуйте, спасибо за ваши познавательные статьи. В свободное время веду блог на вордпрес и ваши материалы мне очень помогли хотя до сих пор остался двоечником, то ли время не хватает, или чего другого. Год назад я таки нашел место где находиться robots. txt и разместил там ваш немного подправив, не судите строго за «кражу», индексация шла отлично но эксперименты продолжались, и итог индексация начала идти туго. Но это не слишком волновало так как не было время заниматься блогом, но вот пришло время вспомнить, пришел опять к вам за информацией но не могу понять куда вткнуть роботекст для прикрепленного форума SMF. Хотя возможно и остальное всунул не туда куда надо. Не могли бы подсказать так или не так? navro. org / robots . txt
Спасибо
Подскажите пожалуйста а подрубрики нужно закрывать от индексации,если нет могут быть дубли.Вот еще у вас на сайте в поиске главная страница выходит с категориями,как так же мне сделать.чтобы неотдельно а на главной.
Как правильно прописать робот, что бы индексировалась только главная страница сайта?
Скажите пожалуйста хочу копированное описание (да и другие различные файлы-инструкции) закидывать в pdf и размещать на карточках товаров с анкором «Полное описание». А потом закрыть в robots все файлы pdf. По примеру из вашей стать:
User-agent: *
Disallow: *.pdf
Скажите такие действия рациональны? Я так добьюсь того, что в индекс не будут попадать различные файлы, которые я так закрою. Потому что много есть файлов которые попали в индекс: pdf, xls и т.д.
Ребята! Кто-нибудь, кто шарит, может мне настроить этот robots.txt и sitemap? Я заплачу деньги. Я запарился уже, весь интернет изрыл, ничего не понимаю. Ни кто не рассказывает от начала до конца, из чего слепить этот робот, куда и как засунуть. Все рассказывают только как для профессионалов.
Этот Саня Борисов тоже нарисовал там, всё как для себя. А ни кто не думал о том, что есть люди, которые не понимают в этих спицифических значках? И что до недавнего времени не знали, что вообще этот робот существует? Может поможет кто, популярно объяснит? Я уже бешусь. Откликнитесь пожалуйста...
Артем, пиши на почту, помогу настроить
В robots.txt есть сточка Disallow: /*?*
Правильно я понимаю, что станицы , в которых присутствует знак ? не будут индексироваться. Например, http://morena.ru/catalog_content/faq/?CATEGORY_ID=1080 . Мне надо, что бы она индексировалась. Можно, это решить следующим образом
Disallow: /*?*
allow: /*?*faq*/
Добрый вечер.
Мне посоветовали для сайта на вордпресс этот робот тхт
на ваш взгляд он будет рабочий?
User-agent: *
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /xmlrpc.php
Disallow: /template.html
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /?s=
Host: pro-wordpress.ru
Sitemap: http://pro-wordpress.ru/sitemap.xml.gz
Sitemap: http://pro-wordpress.ru/sitemap.xml
User-agent: Googlebot-Image
Allow: /wp-content/uploads/
User-agent: YandexImages
Allow: /wp-content/uploads/
Спасибо за информацию!
Даст ли какой-то плюс указание в роботсе отдельных директив для роботов Майла и Гугла?
Отличная статья.Спасибо!
Возможно напишу не совсем туда куда надо, но вроде бы и туда попал)
Проблема у меня в том, что я хочу закрыть от индексации gallery . Там у меня страницы с уникальными изображениями, но из-за того что движок был написан «гениальными программистами» при добавление галереи в статью она еще доступна в общей галереи и в итоге создается такой неприятный дубль... Я думал над решением проблемы и решил, что мне поможет закрыть от индексации каталог gallery и задался вопросом будут ли у меня индексироваться изображения который находятся в статье, но ссылки на эти изображения: сайт-gallery-images изображение.жпг Еще можно ли решить эту проблему просто запретив индексацию всем кроме бота картинок яндекса и гугла?
Благодарю,
Здравствуйте. Скажите пожалуйста а в строке
Host: ваш_домен.ru
тут должен быть именно «.ru» ? или то что в доменном имени? «.сom» или «.ua» ? Извините за, возможно, тупой вопрос, но я прям чайник чайный, а знать нужно))
Здравствуйте. что этот пунк запрещяет?- Disallow: /search
Андрей: страницы внутреннего поиска по сайту (если ваш движок добавляет к их адресу слово search). Поисковые системы не любят, когда эти странички лезут в их индекс, ибо их может быть бесконечно много и они его попросту засоряют (повышают затраты поисковика на их хранение и обработку).
Здравствуйте, Дмитрий.
Создаю сайт на wp по вашим советам и интересует почему в роботсе блокируется feed,это же вроде rss лента.
Также, Алексей, писал выше пример его роботса, нужны ли там строки:
User-agent: Googlebot-Image
Allow: /wp-content/uploads/
User-agent: YandexImages
Allow: /wp-content/uploads/
Через браузер нахожу свой такой:
Пользователь-агент: *
Запретить: /WP-администратора/
Позволит: /wp-admin/admin-ajax.php
Что он обозначает?
Но в панели TimeWeb не могу найти файл роботс.тхт Все папки просмотрел.
Где его найти?
Здравствуйте! Подскажите почему яндекс мне выдает, что сайт закрыт к индексации? хотя у меня стоит стандартный роботс joomla.
Подскажите а где в админ панели сайта я могу изменить файл robots.txt точнее куда вставлять скорректированный файл?
Добрый день! Не увидел в вашем файле robots.txt строчки «Disallow: /wp-content/themes» вы ее намеренно убрали?
Проверяла robots.txt в гугле. Пишет ошибок 0 предупреждений 0. Но следующая строке, где должно быть написано, что сайт доступен, пустая((( Что это значит???
Здравствуйте!
Спасибо за супер статью.
У меня вопрос по robots.txt для Joomla.
Вот вы запретили:
Disallow: /index.php
А почему не стали запрещать:
Disallow: /home
Там же вроде целая куча страничек может открываться через этот home, включая главную.
Дмитрий, здравствуйте! Спасибо за статью: действительно одна из немногих, где всё так тщательно проанализировано!
Есть один вопрос (а из него — ещё один). На сайте есть рубрика с копипастными текстами (в виде новостной) с активными ссылками на источник. Закрыл индекс в robots.
Есть желание дополнительно закрыть всё метатегом
Условно: URL к рубрике https://mysite.ru/novostimira
Таким образом в functions.php между тегами head вставляем
Верно ли данное решение? Если нет, то очень прошу Вашей помощи!
Здравствуйте!
Яндекс вот чего пишет: «Как мы писали ранее, мы отказываемся от директивы Host. Теперь эту директиву можно удалять из robots.txt, но важно, чтобы на всех не главных зеркалах вашего сайта теперь стоял 301-й постраничный редирект.»
Подскажите, как теперь грамотно этот 301 редирект прописать вместо host?
Посмотрел ваш роботс текст, почему у вас одни запреты только. Что значят правила —
Disallow: /vote/
Disallow: /2009/
И у вас вторая часть для всех роботов, третья для яндекс, а первая совсем короткая
User-agent: Mediapartners-Google
Disallow:
Здравствуйте!
Проблема в следующем. На сайте очень много материла с АВТОРСКИМИ ФОТО, которые почему то практически НЕ РАНЖИРУЮТСЯ в яндекс картинках.
Кроме этого в яндекс вебмастере, без всяких изменений в роботсе появилось множество ошибок со статусом «НЕКАЧЕСТВЕНАЯ СТРАНИЦА». Все урлы, вели именно на адреса старниц самих картинок.
Задала вопрос Яндексам, на что получила ответ, что такие страницы можно закрыть от индексирования основному роботу, что если они находятся в статье, то будут проиндексированны в любом случае, но не как отдельная страница, а в массе. Еще они сказали, что важно чтобы картнки были доступны для индексирующего бота картинок.
Прописала следующий код в роботсе: User-agent: Yandex
Disallow: /wp-content/uploads (как понимаю блокирует индексацию всех загурзок)
После этого ошибки ушли, но картинки по прежнему ооочень плохо ндексируются в яндекс картинках.
Подскажите пожалуйста, как правильно сделать. Смотрю роботс на многих сайтах подобной тематики, у них все открыто, все индексируется.
Здравствуйте, а для joomla 1.5 будет такой же robots.txt ?
Спасибо за ответ.
Здравствуйте, для joomla 1.5 будет такой же robotst.txt как Вы написали во втором варианте? Очень надо открыть картинки для индексации гугла. Оказалось спустя 3 года что они не индексируются. на сайте был такой роботс:
User-agent: *
Allow: /http/images/morfeoshow/
Disallow: /cache/
Disallow: /includes/
Disallow: /components/
Disallow: /components/search/
Disallow: /component/content/
Disallow: /installation/
Disallow: /component/
Disallow: /*?*
Disallow: /language/
Disallow: /libraries/
Disallow: /media/
Disallow: /modules/
Disallow: /templates/
Disallow: /plugins/
Disallow: /tmp/
Disallow: /xmlrpc/
Disallow: /go.php/
Disallow: /home?start
Disallow: /404
Disallow: /index.php?option=com_content&view=article&id=18
Crawl-delay: 10
Спасибо за ответ.
Гугл постоянно находит одну и ту же ошибку но индекс...сайт на ворд пресс в robots.txt Disallow : tag, не может он считать этот запрет не подходящим. Шаблон у меня Гудвиновский, может там Алексей наставил ноиндексов????
Когда Вы уже начнете понимать разницу между сканированием и индексированием? Уже и справку Гугла по robots.txt исправили, а все пишут запрещает индексирование. Директивы файла robots.txt носят рекомендационный характер и только на сканирование.
Капец, ребята, сильно благодарю!
Весьма полезные советы.
Здравствуйте!
Скажите, нужно ли закрывать страницу 404, если она есть. Можно ли прописать так Disallow: /404.php ?
Заранее благодарен.
Александр: 404 закрывать не нужно. Она индексации не подлежит априори.
Ваш комментарий или отзыв