Аудит сайта — 20 проверок для попадания сайта в ТОП
Здравствуйте, уважаемые читатели блога KtoNaNovenkogo.ru. Как я уже не раз говорил, да и вы сами знаете, что главное в сайте — это контент (его наполнение, содержимое). Все остальное является второстепенным и неважным. Стоп. Второстепенным да, но все равно очень важным.
То как оформлен контент, во что он завернут, как подается и как все это выглядит с точки зрения поисковых систем — очень важно. Это не даст вам какую-то немыслимую фору относительно конкурентов (при условии, что они аудит сайта проводят регулярно), но позволит встать с ними на одну ступень (сравняться с голодными).
SEO сейчас включает в себя целый ряд факторов разной степени важности (об этом еще отдельно поговорим). Например, для Яндекса на первом месте тексты, а для Гугла по-прежнему в приоритете ссылки (без них рост трафика маловероятен). Но если на сайте имеются ошибки технического или структурного типа, хромает юзабилити и тянет вниз поведенческие факторы, то добра от этого не жди.

Сайтам, продвигающимся по коммерческим запросам следуете в аудит добавлять еще и инвентаризацию наличия всех коммерческих факторов (а их немало), без которых сейчас в этой области вообще делать нечего. В общем, много за чем нужно следить, а вот за чем именно будет детально рассмотрено ниже по тексту. На самом деле — все очень и очень просто.
С чего начать аудит сайта?
Сначала пару слов о том, кому и зачем это может быть нужно. Если говорить коротко, то всем у кого есть сайты и кто хочет, чтобы росту их популярности (посещаемости) ничто не мешало. Это может быть только что созданный сайт или проект, который существует давно.
Аудит показан и одностраничникам и монстрам в миллионы страниц (последние, кстати, отдачу от проверки почувствуют в большей мере). Аудит нужен всем. Другое дело, что проводить его могут профи с приличными ценниками, а можете сделать и вы сами, сформировав в конце список задач для вашего программиста (если такового нет, то биржи фрилансеров ждут ваших предложений с нетерпением).
В принципе, ничего сложного в этом нет. Посидите часок-другой за компьютером, составите по моим лекалам задания на доработку, поищите на биржах исполнителей (правда, это не так просто, ибо там много посредников) и все. При желании можете и сами все это править, но тут уже парой часов не обойдетесь, хотя я ссылочки все же оставлю для особо пытливых умов.
В принципе, с чего начинать аудит не так уж и важно, ибо все пункты чек-листа необходимо выполнить, а уже в каком порядке роли не играет. Отсутствие на сайте ошибок, мешающих продвижению — это комплексная величина и она достигается только комплексной и всеобъемлющей проверкой. Поехали.
Стоп, еще пару слов отступления надо сказать. Дело в том, что есть сайты, которые продвигаются только по информационным запросам (мой блог тому яркий пример). Им по жизни проще, ибо конкуренция в выдаче не столь высока и поисковики некоторые огрехи прощают, а на что-то вообще внимания не обращают.
Но есть сайты, на которых продвигаются еще и (или в основном) коммерческие запросы, а вот тут в выдаче идет настоящая рубка. Для таких сайтов продвижение — это хождение по минному полю. Здесь важно все: и объемы текста, и вхождение ключей, и расположение элементов сайта, и структура разделов и так называемые коммерческие факторы (телефон нужного формата, контакты как у других и т.п.).
Зачем я это говорю? А затем, что аудит будет универсальный, подходящий для коммерческих и информационных сайтов. Если запросы, продвигаемые на вашем сайте информационные, то вы просто опустите те пункты, которые необходимы для продвижения запросов коммерческих. Для вас это будет лишнее. Ну а продающим сайтам нужно будет проходить все пункты этого чек-листа неукоснительно.
Вот, а теперь уж точно поехали...
Проверка на блокировку регуляторами интернета (Роскомнадзор)
В современных реалиях это очень важно. Под блокировку может попасть как ваш сайт (целиком или только отдельные страницы), так и сайт сидящий с вами на одном IP (виртуального хостинга или CDN).
Проверить сайт на наличие в базах Роскомнадзора довольно просто:
Если обнаружили, что таки да, и ваш ресурс в этом списке найден, то надо будет немедленно начинать переписку с Роскомнадзором (hotlinerkn@rkn.gov.ru) для выяснения причин и скорейшего выполнения условий для того, чтобы из этого списка вас вычеркнули.
Даже если под санкции РКН попала только одна страница вашего сайта, вовсе нет гарантии, что только она и будет заблокирована. Часть интернет-провайдеров просто не заморачиваться и блокируют весь сайт.
Если своего сайта в этих списках вы не нашли, то это вовсе не означает, что он блокировки не подвергается. Если у вас виртуальный хостинг без выделенного IP или вы используете CDN (особенно если это что-то бесплатное на манер КлоудФлера), то высока вероятность быть заблокированным не за свои грехи.
Поэтому во избежание такой участи лучше отказаться от использования бесплатных CDN (да и платных тоже) и потратиться на получение выделенного IP для вашего сайта.
Проверка кроссбраузерности сайта
Как вы понимаете, пользователи на ваш сайт могут заходить с совершенно разных обозревателей (только основных браузеров вот сколько). К тому же сейчас очень большая доля трафика идет с мобильных устройств (уже более половины от всего потока посетителей). Естественно, что вам нужно точно знать, что с отображением вашего сайта в этих браузерах тоже все в порядке.
Как это проверить? Ну, можно скачать себе Хром, Мазилу, Оперу, Яндекс Браузер, Сафари, IE и другие. Смотреть в них нужно не только отображение главной страницы, но и другие показательные для вашего сайта страницы (со статьями, с карточками товара, с листингом товара, с контактами). То же самое и для браузеров на популярных мобильных устройствах (Андроиде и iOs).
Есть и более универсальный вариант — онлайн-сервис BrowserShots. Он бесплатный, но вполне себе функциональный. Поддерживает большое число браузеров, а на выходе выдает скриншоты вашего сайта сделанные в выбранных вами обозревателях. Работает не быстро, но вполне сносно.
Если что-то где-то пойдет не так (поедет дизайн, не подключатся стили, что-то перекосится), то пишите первым пунктом в задание программисту: добиться правильного отображения сайта в таких-то браузерах.
Валидация Html и CSS
Этот этап аудита чем-то сродни предыдущему. Валидация кода и CSS стилей нужна не сама по себе (для галочки), а именно для того, чтобы избежать возможных проблем с отображением сайта, которые зачастую визуальными методами выявить бывает совсем непросто.
Тем более что мудрить тут особо не нужно. Есть официальные валидаторы от консорциума W3C (он отвечает за формирование стандартов современно языка разметки), в которые просто нужно будет добавить адрес страницы вашего сайта:
Опять же, вы должны понимать, что через валидаторы нужно прогонять не только главную страницу, но и другие «показательные». Например, страницы со статьями, страницы с товарами, со списком товаров (или статей) и т.д. На каждой из них могут быть свои ошибки и замечания.
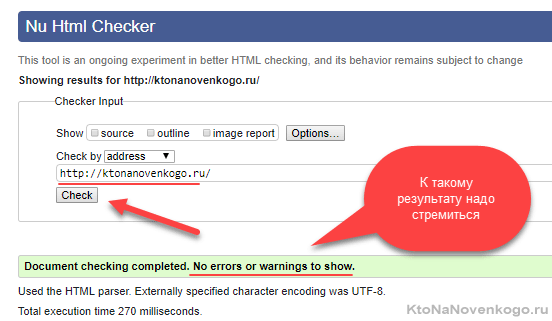
Что делать с найденными ошибками? Ну, не паниковать, это точно. Если сами понимаете где нужно поправить, то в путь. Но зачастую для исправления ошибок в коде разметки придется копать глубоко и лезть в код движка или плагинов (расширений). В этом случае даете задание программисту: убрать по возможности все ошибки, выдаваемые валидаторами для «показательных» страниц вашего сайта.
Проверка адаптивности сайта
Как я уже говорил, более половины трафика в рунете уже идет с мобильных устройств. Поэтому хотим мы этого или не хотим, но наши сайты должны уметь «красиво сжиматься» (адаптироваться) к экранам гаджетов с низким разрешением. В противном случае вы просто убьете на корню поведенческие факторы вашего замечательного сайта, которому для показа на экране мобильника потребует горизонтальная прокрутка.
Какими же способами на этом этапе аудита выявить проблему или убедиться, что ее нет? В принципе, вы можете просто открыть ваш сайт на своем мобильнике и все увидеть воочию. Есть отличный сервис IloveaDaptive (рекомендую). Или еще проще — прямо на компьютере уменьшайте размер окна браузера схватив его мышью за угол. Появляется горизонтальная прокрутка? Картинки вписываются в новые размеры?
Если вы сузили экран в десятки раз, а текст, картинки, кнопки и прочее оформление успешно адаптируется к такому размеру (перестраивается), то это уже замечательно. Но даже если там вам покажется все хорошо — это еще не значит, что все будет хорошо и для поисковых систем. Лучше подстраховаться и посмотреть на сайт глазами поисковых систем.
У Гугла есть специальный тест, проверяющий оптимизацию любого сайта под мобильные устройства:
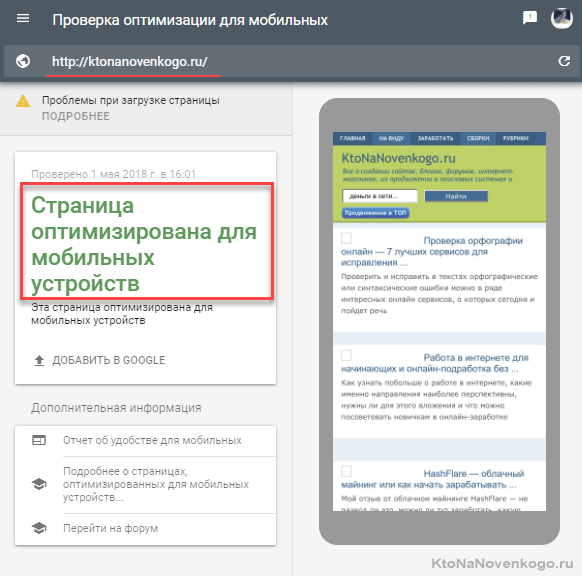
Тут тоже лучше будет проверить все «показательные» страницы, чтобы убедиться в полном отсутствии проблем с адаптивностью на всем вашем сайте.
У Яндекса тоже есть подобный инструмент, но доступен он только из панели для вебмастеров на вкладке «Инструменты» — «Проверка мобильных страниц»:
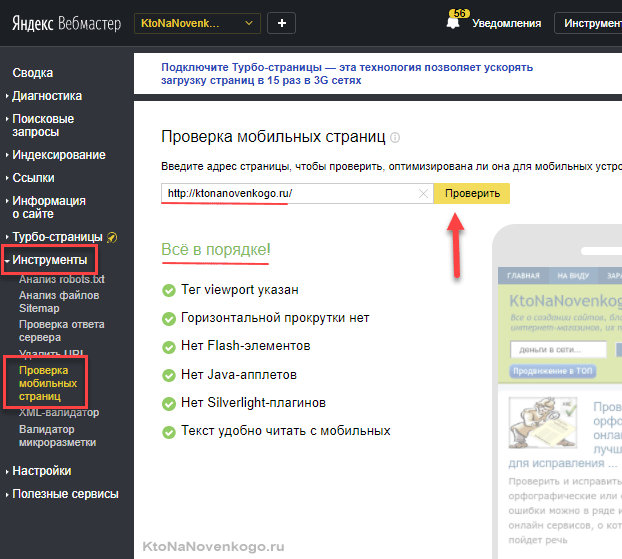
Что делать, если ваш сайт в ходе аудита не прошел тест на адаптивность? Не паниковать, но брать ноги в руки и искать решение. Лично я сделал свой сайт адаптивным самостоятельно и даже подробно описал сей процесс.
Но это вовсе не обязательно делать самому. Адаптация под мобильные устройства не такая уж и сложная задача для программиста (верстальщика), так что просто добавьте еще один пункт в свое техзадание сформулированное по результатам этого аудита. Я бы рекомендовал делать именно адаптацию, а не отдельную мобильную версию сайта.
Аудит микроразметки
Микроразметка — это необходимый атрибут оптимизации сайта при продвижении по коммерческим запросам. Размечаются карточки товаров, контакты, телефоны и все такое прочее. Она скрыта от глаз обычных пользователей и добавляется программно в Html-код в виде дополнительных атрибутов.
Зачем она нужна? Ну, чтобы поисковики четко и безошибочно понимали, что тут что. Микроразметкой вы буквально тыкаете пальцем поисковику — вот цена, а вот фотография товара, а вот контакты продавца, а вот его телефон.
Зачем это нужно поисковым системам? Ну, как же, по этим признакам они оценивают коммерческие факторы сайта (об этом будет отдельная статья) и решают — брать его в «обойму» доверенных продавцов или это фуфел (дорвей, например) маскирующийся под коммерческий сайт.
Данные из микроразметки могут попадать в сниппет (описание вашего сайта в выдаче поисковиков) и быть дополнительным привлекающим элементом. В общем, для коммерческих сайтов микроразметка обязательна, но далеко не факт, что она у вас выполнена безошибочно.
Как проверить микроразметку? Опять же довольно просто ибо и в Гугле, и в Яндексе для этой цели предусмотрены валидаторы микроразметки:
Аудит вашего сайта по этому пункту чек-листа будет заключаться лишь в подстановке Урлов страниц, где требуется проверить микроразметку на ошибки.
Главное тут, как мне кажется, это страница с контактами. Обязательно должны быть размечены название компании, почтовый адрес, индекс, контактный телефон, факс, электронная почта. Если там чего-то не хватаете или есть ошибки в микроразметке, то КФ (коммерческие факторы) вашего сайта могут быть занижены Яндексом со всеми вытекающими.
Проверка кодировки
Браузеры сейчас очень умные и умеют автоматически различать кодировки русского языка, коих очень много. Но самым верным вариантом будет указать тип используемой кодировки в самом начале Html кода всех страниц сайта. Так вы на 100% защититесь от кракозябров (нечитаемых символов, отображаемых вместо букв русского языка).
Аудит по этому пункту чек-листа будет довольно простым. Открываете любую страницу сайта в любом браузере и кликаете по пустому месту на странице правой кнопкой мыши. Выбираете из контекстного меню пункт вида «Посмотреть код страницы» (либо нажмите Ctrl+U на клавиатуре) и в открывшемся окне ищите в самом верху сразу после директивы DOCTYPE конструкцию (называется метатег) задающую кодировку:
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
У меня в коде это именно так и выглядит:
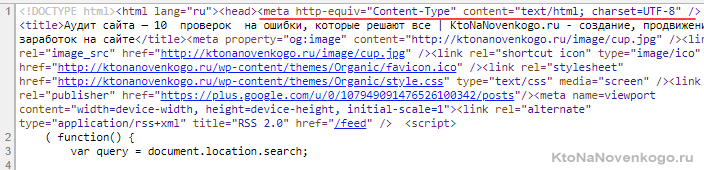
Вместо UTF-8 у вас может стоять windows-1251 — не суть важно, хотя все же юникод (UTF) сейчас считается признанным стандартом (для нового сайта лучшие его использовать).
Если такой строки в исходном коде страниц вы не нашли (можно воспользоваться поиском по странице «Ctrl»+F), то нужно будет его туда добавить. В большинстве используемых движков сделать это совсем несложно. В Вордпресс, например, этот код можно дописать в файл header.php из папки с используемой вами темой оформления. Ну а для программиста — это вообще минутное дело (просто добавьте это в составляемое по результатам аудита ТЗ).
Аудит скорости загрузки сайта
Скорость загрузки страниц уже давно стала фактором, влияющим на продвижение сайта. Особенно это актуально сейчас, когда большая часть трафика идет с сотовых телефонов, а мобильный интернет ведь далеко не всегда «хорошо ловит». А посему именно у мобильных пользователей косяки в настройках сайта выливаются в очень долгую загрузку страниц.
Реально более 4 секунд ждать никто не будет. Поисковики это дело фиксируют и принимают меры. Но сначала проблему надо диагностировать.
Понятно, что вы может измерить скорость загрузки сайта десятком различных способов вплоть до того, что называется «на глазок», открывая новые страницы сайта в браузере, где вы его еще не открывали до этого или после того, как почистили кеш браузера. Но это все не то, ибо требуется взглянуть на проблему со стороны поисковиков.
В этом плане отличным инструментом аудита может послужить сервис Гугла по оценке скорости загрузки сайта под названием PageSpeed Insights:
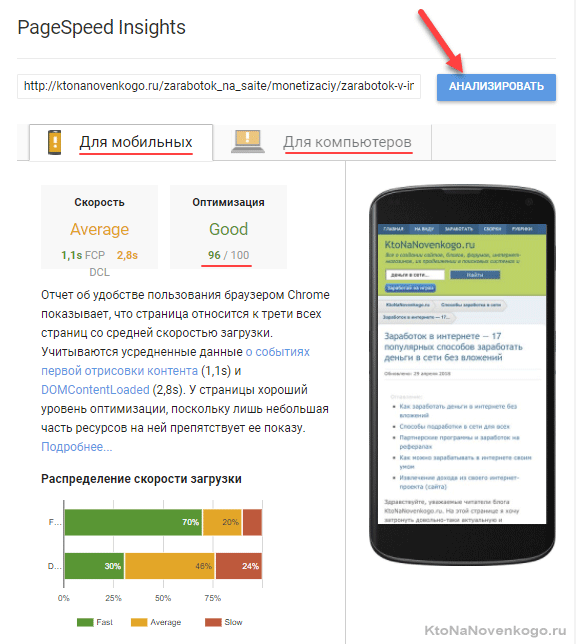
Как и ранее не устаю повторять — проверять нужно не только главную страницу, но и все другие «показательные» (созданные по разным шаблонам) страницы. Результаты теста должны быть хотя бы хорошими, а в идеале — отличными. Я шел к таким результатам лет пять, наверное. Так долго, что теперь уже и радости никакой нет от достижения отличного результата.
Но вы, естественно, не обязаны сами мучиться над повышением скорости работы сайта, ибо это реально сложное дело требующее познаний не только в программировании, но и в тонкой настойке веб-сервера. Просто добавьте в ваше ТЗ программисту пункт о том, что такой-то перечень страниц должен выдавать при их аудите в PageSpeed Insights отличный или хотя бы хороший результат.
Проверка фавикона
Фавикону уже много лет и тот формат, в котором он изначально задавался (ico) уже давно морально устарел (его полностью вытеснил PNG). Однако favicon.ico живее всех живых.
На большинстве сайтов для этой цели используется графический файл-иконка, сохраненная именно в устаревшем формате ico. Размер его обычно равен 16 на 16 пикселей (у меня именно так), но можно сделать и больше (32 на 32, например, использует Авито). Яндекс же для этой цели использует файл в формате png размера 64 на 64. У Гула ico размера 32 на 32. В общем, кто в лес, кто по дрова.
Что такое фавикон, как его создать и как подключить я уже довольно подробно писал. Если кратко, то он отображается в выдаче Яндекса рядом с названием вашего сайта и на вкладках\закладках браузера. Задать его можно просто добавив строку кода туда же, где мы только что кодировку смотрели:
<link rel="shortcut icon" type="image/ico" href="https://ktonanovenkogo.ru/wp-content/themes/Organic/favicon.ico" />
У Яндекса это выглядит чуть по-другому (но он может, по идее, нарушать все мыслимые правила):
<link rel="shortcut icon" href="//yastatic.net/iconostasis/_/8lFaTHLDzmsEZz-5XaQg9iTWZGE.png">
Но это не все. Вы еще не слышали про Apple Touch Icon? Нет? Я вот тоже недавно об этом услышал. И знаете в чем тут дело? Это оказывается специальная иконка, которая будет отображаться на мобильном устройстве, если ваш сайт вытянули на «хом скрин» (аналог рабочего стола в iOs).
Проблема еще и в том, что на разных устройствах от Эпл этот файлик требуется разного размера (от 57 на 57 пикселей до 180 на 180). Кроме iOs иконки формата «Apple Touch Icon» несмотря на название поддерживают и устройства на Андроиде. Какие там размеры нужны вообще непонятно.
На официальной странице для Эпл-разработчиков на данный момент предлагается два варианта указания мест хранения Apple Touch Icon — задать общую для всех иконку или несколько для каждого размера. Мне второй вариант кажется слишком громоздким (четыре записи добавлять), поэтому я выбрал первый вариант с указанием пути до иконки (она должна быть в формате PNG) размером 180 на 180 пискселей:
<link rel="apple-touch-icon" href="https://ktonanovenkogo.ru/apple-touch-icon.png">
Если ничего из вышесказанного про фавикон и Apple Touch Icon вы не поняли, а в исходном коде сайта (Ctrl+U) поиском по странице (Ctrl+F) ничего подобного («shortcut icon» и «apple-touch-icon») не нашли, то просто скопируйте этот текст вашему программисту и скажите ему: «чтоб было».
Есть, кстати, отличный сервис "Генератор иконок Favicon«, который из одной загруженной вами картинки сделает весь необходимый набор изображений, которые вы сможете скачать одним архивом.
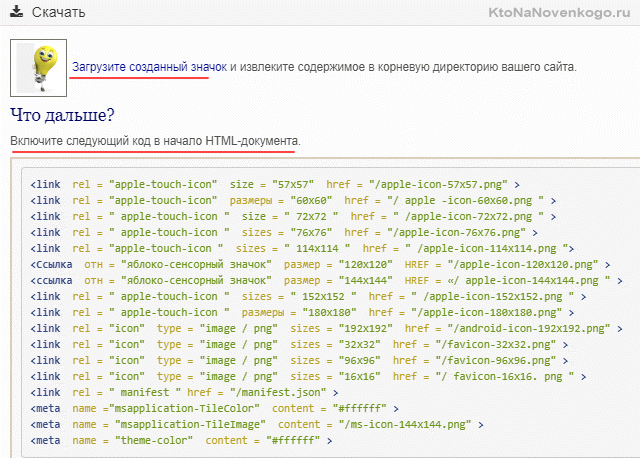
Мало того, он вам даже код для подключения всех этих красивостей к сайту предоставит. Правда, их там уже очень много получается, но вы всегда вольны чем-то пожертвовать ряда компактности исходного кода страниц вашего сайта.
Аудит карты сайта в формате sitemap.xml
Поисковые системы безусловно умнеют из года в год, но тем не менее нелишним будет им однозначно „показать пальцем“ на те страницы вашего сайта, которые необходимо проиндексировать. Для этого предусмотрен файл так называемой карты сайта, который обычно называют sitemap.xml и размещают в корне сайта (именно там его в первую очередь будут искать боты Яндекса и Гугла).
Файл sitemap.xml в идеале должен обновляться с появлением новых страниц на сайте (в указанной чуть выше статье я упоминал про плагин для Вордпресс, который оперативно создает карту блога). В этом файле должны содержаться страницы, которые подлежат индексации поисковыми системами.
Могу поделиться с вами несколькими лайфхаками по sitemap.xml, которые можно использовать:
- Не стоит тупо помещать sitemap.xml в корень сайта и указывать путь до него в файле роботс.тхт (о нем мы еще ниже поговорим). Почему? Ну, зачем упрощать жизнь тем, кто ворует ваш контент (а такие всегда найдутся).
Лучше спрятать этот файл поглубже и назвать по-другому (jfhfhdk.xtml, например). После этого просто идете в панель Гугла и Яндекс Вебмастер, чтобы указать там путь до этого файла. Все. Поисковики в курсе, а остальные пусть утрутся.
- Если у вас огромный сайт с большим числом страниц и большой их вложенностью, то, наверняка, имеются проблемы с его индексацией. Есть масса способов как загнать страницу в индекс (все те же IndexGator или GetBot) и удержать ее там (сквозной блок со случайным списком страниц), но можно и sitemap.xml для этой цели использовать.
Дайте задание вашему программисту, чтобы в файл карты сайта добавлялись только страницы, на данный момент не попавшие в индекс или выпавшие из него. Это ускорит доступ к ним ботов поисковиков, ибо они не будут отвлекаться на уже проиндексированные странички.

В общем, данный этап аудита заключает в том, чтобы убедиться в наличии на сайте в любой момент времени актуального файла карты всех страниц подлежащих индексации. Если его нет, вы его не нашли или вам он не понравился — пишите очередной пункт в ТЗ программисту. Для него все это как два пальца...
Проверка ответа на ошибку 404
Никто не идеален и уж тем более те, кто будет ставить ссылки на ваш сайт на блогах, форумах, в соцсетах и других местах. Людям свойственно ошибаться. А одна ошибка в URL-адресе страницы ведет к тому, что ваш сервер (где живет сайт) ответит на такой запрос (переход по битой ссылке) кодом 404. Обычное дело, но...
Очень плохо, если эту ошибку будет обрабатывать браузер и выдаст пользователю белый лист с мелкой надписью „404 not found“. В этом случае этот посетитель будет для вас потерян. Такие ошибки должен обрабатывать сам сервер и выдавать страницу 404 ошибки в дизайне вашего сайта, что сильно повысит вероятность того, что пользователь этот все же найдет у вас что-то интересное (на вашу радость). Понятно?
Как проверить? Просто добавьте к адресу вашего сайта через слеш любую белиберду типа „https://ktonanovenkogo.ru/fdfdfsf“ в адресной строке браузера и смотрите на результат. Видите белый лист с мелкой надписью? Пишите очередной пункт ТЗ для программиста или настраивайте 404 страницу сами, например, опираясь на приведенную выше статью.
Второй важный момент. Нужно убедиться, что ваш веб-сервер (это не тот сервер, что в стойке хостера стоит, а программа веб-сервер) выдает в ответ на запрос несуществующих страниц именно код 404. Если он выдает на них код 200, то беда. Будет много непонятных и ненужных проблем.
Как проверить код ответа? Есть масса сервисов. Например, в составе Яндекс Вебмастера или этот вот. Вставляете в него адрес страницы, которой точно нет на сайте (типа „https://ktonanovenkogo.ru/fdfdfsf“) и смотрите на код ответа вашего сервака:
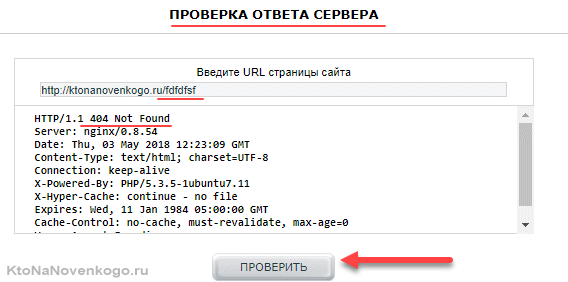
Если там не 404, то прям срочно связываетесь с программистом и просите в экстренном порядке все поправить. На самом деле, этот пункт аудита очень важен, ибо чреват очень неприятными последствиями.
Аудит файла Robots
Испокон компьютерных веков поисковые роботы прежде чем начать обход сайта ищут сначала в его корне файл robots.txt. В нем обычно указывают директивы для поисковых ботов, которые либо запрещают индексирование каких-то страниц и разделов (например, тех, где лежат файлы движка), либо разрешают индексацию, например, поддиректории в запрещенной для индексации директории.
Подробнее про robots.txt и мета-тег роботс читайте в приведенной по ссылке статье. В принципе, этот файл может быть пустой либо его может не быть вовсе. Поисковики, конечно же, сумеют со временем (с годами) разобраться в том, что у вас мусор, а что „ценный контент“. Но как и с файлом sitemap.xml — лучше, если поисковому боту „показать пальцем“.
Robots.txt служит в основном для указания — туда ходи, сюда не ходи (а тут рыбу заворачивали). Это не значит, что бот туда действительно не пойдет (гуглобот вообще везде ходит), но вы свою задачу выполнили и технические файлы (движка, темы оформления, скриптов) в индекс лезть не будут и время на их индексацию бот, скорее всего, тратить не будет.
Тезисно по проверке robots.txt:
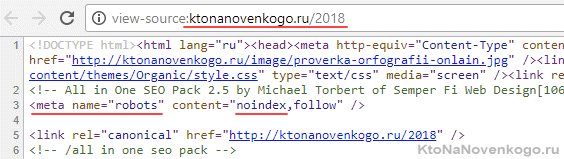
- Аудит имеющегося у вас файла нужно проводить в панели Гугла и Вебмастере Яндекса.
Вводите адреса „показательных“ страниц и убеждаетесь, что они доступны для индексации. Потом вводите адреса технических файлов (папок) и убеждаетесь, что они закрыты для индексации. Главное правильно подобрать страницы и ничего не упустить из важного. Если что-то не так, как надо, то добавляйте пункт в ТЗ программисту. - Раньше в robots.txt требовалось добавлять в отдельном блоке для Яндекса главное зеркало сайта с помощью директивы Hosts. Недавно Яндекс это дело отменил, но директиву многие по-прежнему прописывают.
- Также многие добавляют в Роботс путь до карты сайта в формате xml. Но чуть выше мы с вами пришли к выводу, что лучше не палиться и не облегчать жизнь копипастерам.
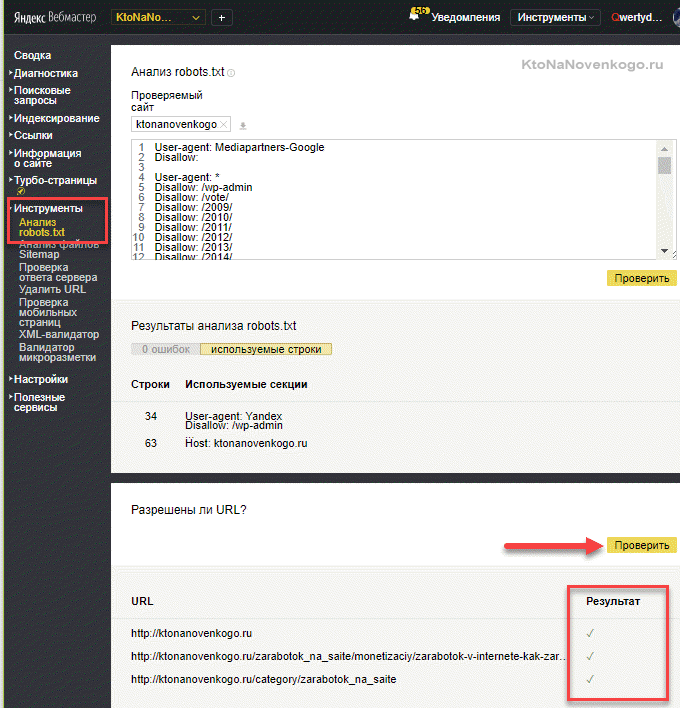
- Директивы, запрещающие индексацию в файле Роботс.тхт не означают того, что бот не перейдет на эти страницы и не проиндексирует их. Особенно наплевательски к таким директивам относится Гугл.
Если хотите 100% закрыть страницу от попадания в индекс добавьте в ее html код мета-тег robots (см. скрин). Например, у меня страницы с временными архивами закрыты именно так (через плагин ОлИнСЕоПак).
Проверяем заголовки и альты у картинок
В html предусмотрены уровни заголовков от H1 до H6, которые использовать на странице очень желательно именно в порядке убывания. Главный заголовок — это H1. Не стоит даже ради красоты сначала ставить H3 потом H1, а потом H2. Порядок — есть порядок.
Другое дело, что многие хитрят и делают большие надписи (аля главные заголовки) вообще не заголовками, а обычными блоками (используются, например, теги div вместо H1), размер и вид текста в которых задается просто с помощью CSS.
Дело в том, что в этой надписи (в отличие от H1) не нужно употреблять ключевые слова и ее можно сделать максимально притягательной и не нагруженной ключами. А сам H1 может идти ниже и визуально будет выглядеть как рядовой заголовок или вообще как фрагмент текста.
Уже дальше пойдут H2 (а как их подразделы — H3, если до этого дойдет), которые при продвижении под коммерческие запросы лучше ключами вообще не засорять — LSI фразы для них будут в самый раз. О них подробнее поговорим в отдельной статье, но если кратко, то это фразы употребляемые экспертами в данной области, а не теми, кто в этом ничего не петрит.
Ну, вы поняли? В принципе, это общая практика и хорошо работает особенно на продающих страницах, где главное склонить покупателя к действию крупными и яркими зазывными текстами, а для поисковиков использовать в скромно оформленном H1 (и тайтле) ключевые фразы (надо опять же смотреть на конкурентов из Топа по этому запросу).
Очень часто содержимое H1 совпадает с содержимым Тайтла (что такое тайтл и дескрипшен читайте по ссылке). В принципе, H1 дает возможность вариации использования другой версии ключа, а для информационных запросов, когда кластер ключей для одной страницы огромен, заголовки всех уровней дают возможность использовать как можно больше ключевых слов для увеличения трафика на статью.
На данном же этапе аудита вам главное выяснить — соблюдается ли иерархия заголовков на основных типах страниц (главной, категориях, статьях, карточках товаров) вашего сайта и везде ли есть H1. Для этой цели отлично подойдет плагин для браузеров Веб Девелопер, который наглядно может показать все используемые на странице заголовки. Можно и просто подводить мышь к заголовку и из меню правой кнопки выбирать пункт „Посмотреть код“ (или „Исследовать элемент“), но это будет не так быстро и наглядно.
Очень часто теги H2-H6 могут использоваться разработчиками шаблона в оформлении темы (заголовках меню, например). Лучше это все убрать, чтобы заголовки были только в уникальной части данной конкретной страницы (в ее теле, а не в обвесе).
Касаемо атрибутов Alt и Title у используемых на сайте изображений (в теге Img). Атрибуты Alt должны быть прописаны обязательно (их содержимое будет отображаться вместо картинки, если ее браузеру не удастся подгрузить), а Title — по желанию (его содержимое показывается при подведении мыши к изображению на странице сайта).
Внимание! Сейчас в Альтах категорически нельзя спамить ключевыми словами, уповая на то, что их дескать не видит посетитель, а потому туда пихают неочеловеченные n-граммы типа „холодильник купить Москва“. Множество сайтов за это попали под фильтр.
Зачастую владельцы добавляли ключи даже к изображениям, относящимся к дизайну сайта (логотипам, стрелочкам и тому подобной мишуре). Сейчас Alt должен только описывать то, что изображено на картинке (ну, может еще с использованием LSI фраз — о них напишу отдельную статью).
Как проводить аудит альтов? Чтобы найти страницы, где атрибутов Alt вообще нет, можно использовать уже упомянутый выше Валидатор HTML кода. Он отсутствие альтов отмечает именно как ошибку. Чтобы проверить содержимое тегов Альт отлично подойдет уже упомянутый выше плагин для браузеров Веб Девелопер (он умеет отображать содержимое альтов для всех картинок на странице прямо рядом с изображением).
Естественно, что при нахождении расхождений — правите их сами либо добавляете очередной пункт в ТЗ программисту.
Аудит Seo-тегов для всех страниц сайта
Какие SEO теги существуют? Ну, изначально их было три: Title, description и keywords. Однако, keywords уже давным-давно стал рудиментом. Представляете, изначально он был придуман, чтобы поисковики понимали, по каким запросам ваш сайт ранжировать (добавлять в Топ). Глупые они тогда были.
Что главное в рамках этого этапа аудита:
- Во-первых, Title и description должны быть (какие именно читайте в приведенной выше статье). В смысле, наличествовать. Страница без Title считайте что не существует для поисковиков. Description тоже важен, но уже не так. О таких страницах (без тайтлов) вам с радостью расскажут Гугл и Яндекс Вебмастер в блоках с найденными ошибками. Также это наглядно можно увидеть с помощью такой бесплатной программы, как Xenu Link, если отсортировать собранные ею данные по столбцу „titile“ (увидите пустые ячейки).
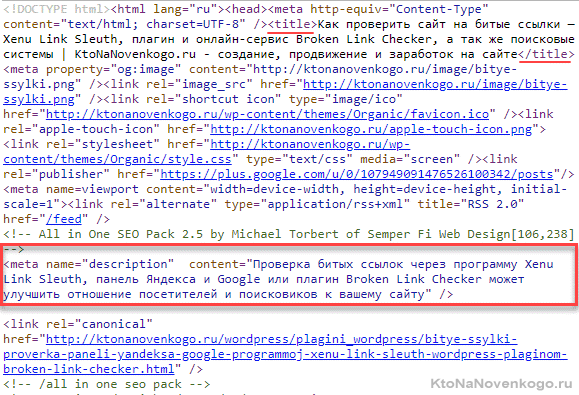
- Во-вторых, не должно быть одинаковых Тайтлов у страниц в рамках одного сайта. Они должны хоть чем-то отличаться, даже если это карточки с похожими товарами. О таких ошибках вам опять же сообщат в панели вебмастеров Яндекса и Гугла (у меня таких ошибок нет, а посему скрин привести не могу, но вы покопайтесь сами). Если сайт небольшой, то одинаковые теги Title вы и с помощью Xenu Link сможете выявить.
Если сайт совсем маленький, то можно посмотреть Тайтлы и Дескрипшены вручную просто нажав Ctrl+U на клавиатуре (посмотреть исходный код страницы):
Что делать, если ошибки такого рода были найдены? Если это статьи или карточки товаров, то просто измените чутка Тайтлы или настройте автоматическую их генерацию для карточек на основе шаблона.
У меня такая проблема была на страницах с пагинацией (типа главной на этом блоге, где внизу есть нумерация). Я просто закрыл страницы пагинации от индексации (через мета-тег Роботс) и добавил на всякий случай к ним мета-тег Каноникал указывающий первую страницу как каноническую.
Если ничего не поняли, то программист поймет обязательно и быстро решит для вас выявленные на этом этапе аудита проблемы. А иначе зачем вы ему деньги платите?
Проверка склейки зеркал
Поисковики такие глупые, что считают некоторые совершенно одинаковые на наш взгляд страницы разными. Например, для Яндекс и Гугла страницы со слешем и без слеша в конце будут разными:
https://ktonanovenkogo.ru
и
https://ktonanovenkogo.ru/
А также доменное имя сайта с www и без www для них воспринимают как два разных сайта:
https://ktonanovenkogo.ru
и
https://www.ktonanovenkogo.ru
Ну, как бы и ладно, что нам с этого, убудет что ли. Таки убудет. Контент-то на этих страницах и сайтах будет одинаковый. А это что? Правильно. Дублирование контента, чего очень не любят поисковики. Почему? Потом что мы одним и тем же забиваем их базу, а значит для ее хранения нужно больше „железа“ и больше денег. А лишние деньги поисковики тратить не любят.
Второй очевидный минус. Внешние ссылки будут проставляться людьми и так и так (со слешем, без него, с www и без него). Если эти зеркала не склеены, то поисковик (он на самом деле не такой тупой) выберет что-то одно как главное зеркало. А что будет с теми ссылками, что ведут не на главное зеркало? Правильно, они не будут приняты в расчет, что повлияет в худшую сторону на ранжирование сайта.
Поэтому зеркала нужно склеить с помощью 301 редиректа (мы этим говорим поисковикам, что это перенаправление делается навсегда в отличие от временного 302 редиректа). После этого дубли исчезнут в глазах поисковиков, а все ссылки будут учтены в независимости от того был у них в конце слеш или нет, а также было ли www или нет.

Как провести аудит склейки зеркал? Довольно просто. Открываете в браузере ваш сайт и начинаете в адресной строке над ним глумиться. Для начала допишите перед доменом (после http://) три буквы www или, наоборот, сотрите их, если они там были. Потом нажмите Энтер на клавиатуре. Что произошло?
- Страница обновилась, а в адресной строке ваше изменение сохранилось. Это плохо — зеркала не склеены.
- Страница обновилась, но в адресной строке www исчезло. Это здорово, ибо именно так и отрабатывает 301 редирект у склеенных зеркал. Проверьте все то же самое и с другими страницами сайта. В идеале везде должно редиректить на главное зеркало (оно у вас может быть как с www, так и без www — вообще не важно).
Теперь проведите тот же эксперимент со слешем. Если на главной странице в адресной строке его в конце нет, то добавьте и нажмите Энтер на клавиатуре. Если слеш остался, то склейки такого типа зеркал нет — надо будет дорабатывать. Если слеш изчез, то все ОК и зеркала такого типа тоже оказались склеены.
Проверяем дальше. Добавьте в конце адреса главной страницы „/index.php“, чтобы получилось так „https://ktonanovenkogo.ru/index.php“. Жмите на Энтер. Редиректит на основное зеркало (в моем случае „https://ktonanovenkogo.ru“). Если нет (/index.php остается), то поздравляю — вы нашли еще одно не склеенное зеркало.
То же самое проверьте с /index.html и т.п. Забыл сказать, что нормальным вариантом при таких добавках будет также появление страницы 404 (не найдено). В этом случае тоже дублей не будет, а ссылки с index после Урла главной страницы генерят только движки сайтов, но никто из людей на вас внешнюю ссылку в таком виде не поставит.
Что делать, если на этом этапе аудита вы нашли не склеенные зеркала? Похвалить себя, а потом либо самим попробовать сие безобразие поправить опираясь на эту и еще вот эту публикацию, либо добавить еще один пункт в ТЗ программисту. Для него эта проблема выеденного яйца не будет стоить.
P.S. Если аудит показал, что зеркала (например, с www и без www) не были склеены, то в качестве будущего главного лучше выбрать то, которое таковым посчитала поисковая система. Для коммерческих запросов основным поисковиком является Яндекс, а посему нужно ввести в его строку домен вашего сайта и подвести курсор мыши к названию вашего сайта в выдаче. В нижнем левом углу браузера вы увидите адрес вашего сайта и именно такой вид стоит выбрать для главного зеркала (с www или без него).
Проверка битых ссылок на сайте
Что это такое? На вашем сайте всегда будут иметь место ссылки двух типов:
- Внутренние — ведущие на другие страницы вашего же сайта.
- Внешние — ведущие, соответственно, на другие ресурсы.
Так вот, оба этих вида ссылок могут быть битыми, испорченными, то есть не приводящими к открытию страницы, на которые они по идее должны вести.
Почему это может происходить:
- Вы сами ошиблись при вставке ссылки (ввели URL адрес с ошибкой, допустили ошибки в теге гиперссылки).
- Страница, на которую ведет эта ссылка могла со временем поменять адрес или вовсе быть удаленной (перенесенной). Это могли сделать вы сами на своем сайте (или ваш программист) и не учесть данное изменение в перелинковке. На чужом сайте могло произойти то же самое и внешняя ссылка в результате этого стала битой.
- Если это была внешняя ссылка, то могла даже исчезнуть не только сама страница, но и весь сайт. Кстати, несказанно грустно это наблюдать.
В любом случае вы должны регулярно проводить полный аудит всех имеющихся на сайте ссылок на предмет того, не появились ли среди них битые (ведущие в никуда). Почему это так важно? Поисковые боты ходят только по ссылкам и если у вас будет слишком много путей, по которым пройти нельзя, то они могут обидеться.
В лучшем случае, ваш сайт с кучей битых ссылок будет выглядеть для поисковых систем непрезентабельно. Это как магазин с облупившейся витриной, разбитыми стеклами и поломанными ступенями — доверия не вызывает. Битые ссылки будут всегда и везде — такова их природа. Нужно просто регулярно проводить проверку и исправлять (или удалять) те пути, по которым пройти невозможно.
Естественно, что переходить по всем ссылкам на всех страницах сайта будет не нужно. Это процесс можно легко автоматизировать. Как это сделать? Об этом можно почитать тут — Проверка битых ссылок.
Я делаю так:
- Раз в несколько месяцев прогоняю свой блог через сервис Broken Link Checker (подробнее о нем читайте в приведенной статье). Он проводит аудит очень быстро — минут за десять, наверное (но находит далеко не все). Я лечу или удаляю найденные пути ведущие в никуда и еще на несколько месяце об этом забываю.
- Раз в год или чуть больше я прогоняю сайт через программу Xenu Link Sleuth. Она бесплатная и расскажет о вашем сайте вообще все. Работает она долго — зато найдет все, что побилось или поломалось. Потом долго и нудно все это лечу, чтобы еще на год-два забыть об этом.
Естественно, что все это можно переложить на плечи программиста ничто вам не помешает проконтролировать выполненную им работу по описанным выше методикам.
Проверка наличия ЧПУ-адресов
Есть такой термин ЧПУ. Означает человеко-понятные урлы. Урлы — это адреса страниц вашего сайта. В принципе, они могут быть двух видов:
- Формируемые движками сайтов, когда после домена следуют знак вопроса и куча непонятных параметров (цифро-букв). Например, „https://ktonanovenkogo.ru/?p=59164“. Это не очень хорошо, ибо человек глядя на такой адрес мало что понимает.
- Но бывают Урлы преобразованные к виду понятному человеку (ЧПУ). Вот так, например:
https://ktonanovenkogo.ru/wordpress/bitye-ssylki-proverka-paneli-yandeksa-google-programmoj-xenu-link-sleuth-wordpress-plaginom-broken-link-checker.html
Тут видны разделы, в которых помещена эта статья и их, кстати, можно открыть просто удалив все лишнее справа от последнего слеша (сам иногда так делаю на других сайтах, если там нет хлебных крошек). Да и сам Урл представляет из себя вполне себе читаемый вариант заголовка, написанный транслитом.
Считается оптимальным использовать именно латиницу (транслитерацию с русского), нежели кириллицу. Связано это с особенностями работы поисковиков и некоторыми другими возникающим на ровном месте проблемами.
Что делать, если взглянув в адресную строку своего (или продвигаемого вами) сайта вы обнаружили, что Урлы не вида ЧПУ? Все зависит от возраста сайта. Если он только что появился и даже еще толком не проиндексировался, а также трафик на него пока не велик — смело подключайте ЧПУ. Как подключить ЧПУ в WordPress я как-то уже писал, но ваш программист сможет это с легкостью сделать для любого движка.
Если сайт уже имеет приличный трафик с поисковых систем, то ничего не трогайте. Да, ЧПУ лучше, но если вы сейчас его подключите, то трафик потеряете (хотя если делать грамотно, то можно и не потерять, но нужен спец). Возможно, что со временем он вернется, но я бы не рисковал. Считайте, что результатом этого этапа аудита для вас стало знание как нужно было делать, если бы была возможность начать все сначала.
Аудит внешних ссылок
Это не SEO-аудит на предмет качества, количества и содержания проставленных на ваш сайт ссылок (об этом мы еще в отдельной статье поговорим). Это аудит ссылок ведущих с вашего сайта. В идеале с него не должно быть проставлено ничего лишнего и уже тем более открытого для индексации, но это в идеале.
Откуда могут взяться лишние внешние ссылки? Ну, есть варианты.
- Вам сделали сайт и зашили в него ссылку на компанию-разработчика.
- Вам поставили шаблон, в котором были вшиты внешние ссылки (или даже код Сапы для продажи ссылок).
- Сайт заражен вирусом (или его взломали), что опять же может выразиться в появлении несанкционированных вами внешних ссылок.
- Ваш программист или администратор барыжат продажей ссылок с обслуживаемых ими сайтов (у них ведь есть полный доступ к коду).
Если вы думаете, что сможете найти их визуально, то могу вас разочаровать, ибо сие крайне маловероятно. А посему нужно взглянуть на сайт глазами поисковика, а точнее его бота. Сделать это можно только с использованием софта или специальных сервисов. Каких именно?
- Да все та же программа Xenu Link Sleuth собирает данные обо всех ведущих с вашего сайта ссылках. Отсортируйте ее результаты по первому столбцу „Addres“ и вы увидите весь список внешних ссылок.
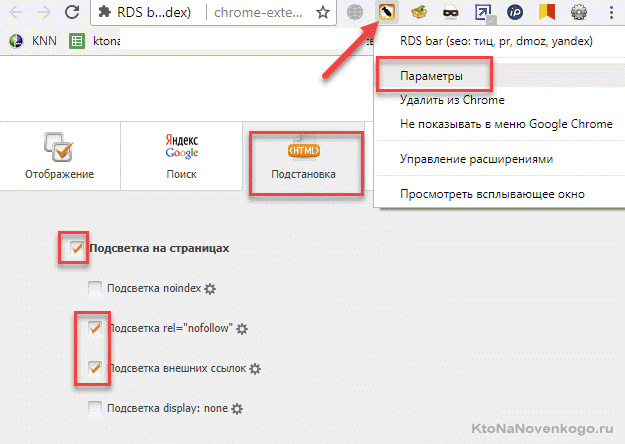
- Можно использовать замечательный СЕО-плагин для браузера RdsBar. В его настройках включите „Подсветку внешних ссылок“:
В результате на открытой в браузере странице все внешние ссылки будут перечеркнуты, а те из них что открыты для индексации будут обведены красным пунктиром (это совсем плохо):
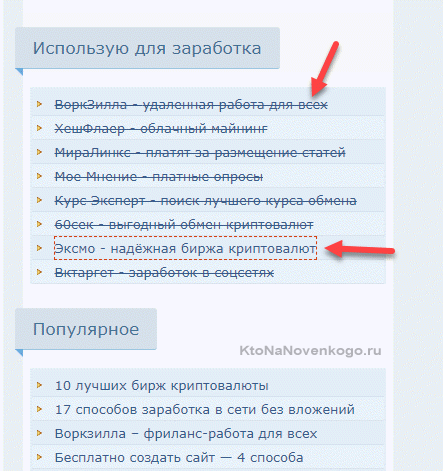
Внимательно осмотрите таким образом все „показательные“ страницы особенно во периметру (шапка, футер, сайдбр). Но опять же, визуально не все можно увидеть. - Можете использовать этот сервис (потребуется лишь регистрация). Вводите там адрес страницы и получаете список всех ведущих с нее ссылок. Внешние ссылки будут подсвечены красным цветом. Если ее анкор (текст ссылки) в соответствующем столбце перечеркнут, то значит она закрыта для индексации (в ней прописан атрибут rel=»nofollow", хотя вес по ней все равно утекать будет).
- Есть похожий инструмент для постраничной проверки исходящих ссылок в Pr-Cy. Ищите в столбце «Внешние ссылки» те строки, где нет красной надписи NOFOLLOW.
Если «левые» внешние ссылки в результате аудита будут найдены, то дайте задание программисту на их удаление либо сами попытайте понять «откуда у них ноги растут». Зачастую они могут быть глубоко вшиты в код шаблона (зашифрованы) и для их удаления потребуются определенные навыки. Думаю, что программист справится. В крайнем случае поменяйте шаблон (тему оформления).
Тег Canonical
В чем смысл Canonical? Это инструмент актуальный для Гугла (в меньшей степени для Яндекса), который позволяет на страницах с полностью или частично дублированным контентом оставить метку о том, что это как бы не страница сама по себе, а копия канонической версии страницы (в мета-теге как раз указывается ее адрес) и не нужно ее индексировать.
Где и когда это может понадобиться? Чаще всего таким образом решают проблему со страницами, имеющими пагинацию (это когда внизу будет переход на вторую, третью и другие части этой страницы). У меня это «Главная» и страницы рубрик.

У таких страниц одинаковый Тайтл, H1 и Дескрипшн (зачастую и небольшой SEO-текст, который добавляют для поисковиков), а значит в глазах поисковиков это дубли. Чтобы не искушать судьбу нужно для страниц типа «https://ktonanovenkogo.ru/page/2» добавить в html код тег Canonical с указанием Урла канонической (основной) для нее страницы (в нашем примере это «https://ktonanovenkogo.ru»):
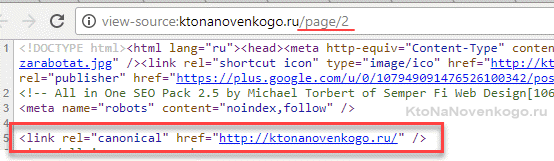
В чем заключает данный этап аудита? Просто пройдитесь по всем страницам с пагинацией и посмотрите прописан ли на вторых, третьих и так далее страницах пагинации этот мета-тег (ищите в исходном коде с помощью Ctrl+U и Ctrl+F) и ведет ли он на правильную каноническую страницу (ту, что без номера, т.е. первую в пагинации — материнскую).
Кроме пагинации Canonical может использоваться и в других случаях. Например, имеет смысл его применять для версий страницы для печати или отдельной мобильной версии. Также он позволяет убрать дубли, создаваемые движком сайта (из-за каких-то своих внутренних багов).
Также Canonical позволяет не засорять индекс различными страницами фильтрации (сортировок) используемых в интернет-магазинах (если только для каждой из таких страниц не формируются свои собственные Тайтлы, H1 и сео-тексты, что делает их уникальными).
Все найденные замечания добавьте в ТЗ вашему программисту. Если интересно, то тут описан мой вариант настройки Canonical для блога на Вордпресс.
Аудит индексации сайта
Суть проверки — это понять насколько полно и правильно индексируется наш ресурс. Для этого достаточно будет просто сравнить число страниц в индексе Яндекс и Гугла с помощью уже упоминаемого выше плагина для браузеров РДС-бар.
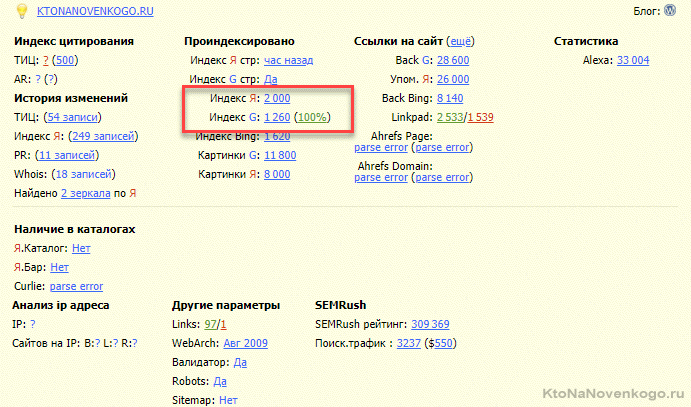
Как видите, у меня в индексе Яндекса на треть страниц больше, чем в Гугле. В принципе это звоночек, который обязательно нужно проверить (как-то я таким образом серьезную проблему выявил, именно сравнив число страниц в индексе).
Для детального анализа можно кликнуть по цифрам в окне РДС-бара и перейти в выдачу Яндекса или Гугла. Очень часто в индекс попадают мусорные страницы типа «поиска по сайту», которые обязательно нужно закрывать от индексации через мета-тег Роботс (читайте об этом выше), но многие забывают. Также в индекс могут попасть и дубли страниц, которые не закрыли с помощью Canonical, как это было описано выше (например, страницы пагинации).
У меня проблем не выявилось (скорее баг плагина), ибо я проверил число страниц в индексе через Яндекс Вебмастер (из левого меню «Индексирование» — «Страницы в поиске» и внизу открывшейся страницы выгрузка в формате Эксель) и число выгруженных оттуда страниц совпало с тем, что было в Гугле. Но лучше лишний раз проверить, чем потом проблемы огребать.
P.S. Если на сайте используется структура поддоменов (частое явление для расширения региональности под Яндекс — отдельный домен под каждый новый регион), то нужно учитывать, что в Гугле все страницы на основном домене и поддоменах попадают в общий индекс, ибо он считает их все одним сайтом. Яндекс же поддомены (домены третьего уровня) считает за разные сайты.
Добавлю сюда же быструю проверку структуры вашего сайта. При продвижении коммерческих запросов важно все (это как хотьба по минному полю, где важно идти по следам уже прошедших его). Сама по себе структура будущего сайта в идеале списывается у тех, кто уже находится в Топе по вашим запросам. Просто тупо выписываете структуру (пункты меню) 10 сайтов из топа (исключая агрегаторы, типа Авито), удаляете повторения и вот у вас лучшее из того, что может быть.
Аудит структуры в данном случае будет очень быстрым (поверхностным). Просто выписываете среднее число страниц ваших конкурентов из Топа, которое находится в индексе поисковиков. Вычисляете по ним среднюю температуру по больнице и сравниваете со средним числом страниц вашего сайта в индексе Яндекса и Гула. На основании этого делаете вывод — нужно ли вам еще расширять структуру (если число страниц вашего сайта серьезно меньше) или нет.
Чек-лист по юзабилити и коммерческим факторам
Юзабилити — это удобство взаимодействия с сайтом, которое во многом связано с соблюдением тех стандартов, к которым уже привыкли пользователи интернета и не найдя которые они «сильно расстроятся». Почему так любят соцсети? Потому что там все привычно, на своих местах, понятно и просто. Но и на обычных сайтах есть стандарты дефакто, которые нарушать не стоит.
Коммерческие факторы — это такие элементы сайта (и не только его), которые жизненно необходимо иметь при продвижении под коммерческие запросы. Их довольно много и не все владельцы обращают на это внимание. А между тем, это один из критических факторов, который при всем при том очень легко накрутить (подтянуть до нужного уровня) с минимальными усилиями.
Особенность данного этапа аудита заключается в том, что все эти факторы работают в комплексе. То есть они должны быть хотя бы «по большей части». На данном этапе вам главное провести проверку на предмет наличия всех этих вещей именно на вашем сайте. А уже по его результатам составлять ТЗ программисту на доработку.
- Копирайт (знак копирайта, название и год основания) — пустячок, который обычно в самом низу страницы выводится и выглядит так:
© KtoNaNovenkogo.ru, 2009-2018 | Все права защищены
Быть должен обязательно. Если нет, то сделайте сами или программиста озадачьте. - Логотип — обязательный атрибут (графический или текстовый, как у меня) и при этом он обязательно должен являться ссылкой, ведущей на главную страницу. Это догма, которой ни в коем случае не стоит пренебрегать.
- Форматирование текстов — страница не должна выглядеть как кусок слепленного в один комок текста. Должны быть на уровне CSS проработаны удобные абзацы, юзабельные списки, таблицы, красивые заголовки (подзаголовки) и т.п. Посетитель принимает решение «остаться или уйти» всего за пару секунд и смотрит он в это время не на содержание, а на его подачу.
- Кнопки на сайте — они могут быть графическими или текстовыми, но главное тут не само наличие, а понимание посетителями, что это кнопка. Как этого добиться? Есть такое понятие в CSS как hover-эффект, который позволяет заставить кнопку менять свой вид при подведении к ней мыши. Обычно меняется либо фон кнопки, либо цвет текста, но возможны и другие эффекты. Главное, чтобы было ясно, что это кнопка и по ней можно (нужно) кликнуть. Если этого где-то нет, то озадачьте себя или программиста решением данной проблемы.
- Шрифты — очень портится восприятие сайта (страдает юзабилити), когда на нем используется слишком много разных шрифтов. Всего хорошо в меру и нужно добиваться лаконичности, а не вычурности. Если глазам не доверяете, то кликните по слову правой кнопкой мыши и выберите «Посмотреть код».
- Время и дни работы — очень важный коммерческий фактор. Поисковики это все «берут на карандаш». График работы должен быть выполнен в виде сквозного блока, отображаемого на всех страницах, и размещаться вверху (в шапке) или в внизу шаблона (в футере).
- Регион работы — тоже очень важный коммерческий фактор добавляющий удобства пользователям и нравящийся поисковикам (Яндексу). Как все это лучше оформить подсмотрите у более успешных конкурентов из Топа, по вашим основным ключевым запросам.
- Поиск по сайту — важный юзабилити элемент, который должен быть обязательно на любом сайте. Способов реализации много. Например, можно использовать поиск по сайту от Яндекса или скрипт от Гугла. У каждого движка сайта или интернет-магазина есть свои возможности реализации поиска.
- Хлебные крошки — эта навигационные ссылки, которые помогают посетителям понять, на какой странице они сейчас находятся и при необходимости перейти в раздел, относящейся к этой странице. Вариантов реализации море (даже я описывал их тут и тут).
Они очень сильно повышают юзабилити и лучше будет их реализовать тем или иным способом. Важно и их размещение. Общепринято, что они должны располагаться в верхней левой части страниц, где их и будут искать большинство посетителей.
Вообще, все базовые элементы сайтов должны быть расположены там, где пользователи привыкли их видеть на сайтах лидерах (в вашей нише).
Для каждого движка наверняка найдется свой плагин хлебных крошек либо ваш программист реализует их самостоятельно, что тоже несложно. - Политика обработки персональных данных — стало актуально недавно в связи с новым федеральным законом 152-ФЗ о сборе и защите персональных данных. За несоблюдение сих требований предусмотрены довольно приличные штрафы. Хотя бы политику конфиденциальности разместить стоит и дать на нее ссылку где-нибудь в подвале сайта.
- Кнопка прокрутки вверх — по соображениям юзабилити, такая кнопка желательна (у меня ее нет), но лучше посмотрите на сайты из Топа по вашей тематике.
- Онлайн-консультант — отличный инструмент для повышения не только коммерческих факторов сайта, но и для улучшения поведенческих характеристик и повышения конверсии. Не стоит думать, что для его реализации вам потребуется нанимать сотрудников для ответов или самому все время быть на связи. Просто разрабатываете базу ответов на частые вопросы и отвечать за вас будет «бот». В случае затруднений он предложит клиенту оставить телефон для консультаций, а это ведь первый шаг к продажам. В общем, штука невероятно эффективная при должной настройке.
- Обратный звонок — тоже отличный и почти что обязательный инструмент для коммерческих сайтов (пример смотрите тут). Желательно, чтобы эта кнопка была бы доступна на первом экране любой страницы вашего сайта.
- Ссылки на соцсети — комильфо, если ваш сайт будет представлен в основных соцсетах (ВК, Фб, ОК, Твиттер и т.п.) и на его страницах будут размещены ссылки на эти соцсети (у меня это сделано в правой верхней части сайта).
Это важный фактор, учитываемый поисковиками. Даже для проектов, которым как бы не о чем писать в социалках, есть возможность размещать там экспертные материалы с новостями отрасли вообще. Достаточно постить материалы в одной соцсети, а в остальные их можно просто копировать. - Возможность поделиться в соцсетях — актуально как для информационных (кнопки для расшаривания статей в социалки, например, как эти, эти, эти или эти), так и для коммерческих запросов (возможность поделиться в соцсетях должна быть на всех карточках товаров).
- Блок с новостями (либо новыми статьями) — обязательный атрибут любого сайта. Желательно, чтобы этот блок был доступен с главной страницы или даже был бы сквозным.
- Электронная почта на домене — важный фактор, говорящий в пользу вашего сайта. Посмотрите на адрес почты, который указан у вас в контактах. Если Емайл оканчивается не на ваш домен (как, например, admin@ktonanovenkogo.ru), а на yandex.ru или gmail.com, то считайте, что вы выявили серьезную проблему с помощью этого аудита. Не волнуйтесь, создать ящик на своем домене просто и пользоваться им можно будет в привычном вам интерфейсе, если пожелаете (читайте про Емайл на домены в Яндексе и тоже самое у Гугла).
- Для интернет-магазинов актуальна перелинковка в карточках товаров. Осуществляется с помощью блоков «Похожие товары», «Недавно просмотренные», «С этим обычно покупают», рекомендуем и т.д. Стало дефакто обязательным атрибутом, отсутствие которого сразу будет работать в минус вашему ресурсу. Также желательно предлагать посетителям покупку в один клик, что также стало правилом хорошего тона.
- Раздел «Контакты» — один из важнейших коммерческих факторов, сильно влияющий на успешность (и даже возможность) продвижения. В этом разделе обязательно должен быть указан адрес (полный почтовый адрес офиса с индексом), телефон (с кодом города или 8-800, но ни в коем разе не мобильный номер), время работы, Емайл (очень хорошо, если будет форма обратной связи). Также должна быть карта проезда на личном авто, на общественном транспорте и пешком. Я как-то писал про то, как можно создать схему проезда на основе Яндекс Карт и получить карту проезда для сайта от Гугла.
- Варианты оплаты и доставки — на коммерческом сайте обязательно должны быть такие страницы с подробнейшим пошаговым описанием (иногда даже с добавление видео-пояснений). Кроме наличия таких страниц должны быть еще и ссылки на них (на видном месте) в карточках с товарами. Это тоже очень важный коммерческий фактор (характеризующий вашу «услужливость»).


Пора итожить
Пройдясь по всем пунктам приведенного выше аудита вы, возможно, найдете много того, что имело бы смысл изменить, подправить или убрать. Глядя на сайт невооруженным взглядом большинство озвученных выше проблем останутся незамеченным. Считайте, что я вас вооружил. И помните, чего-то неважного тут нет, ибо любая мелочь важна (ведь именно она может отделять вас от успеха).
После того как пройдете по всем пунктам аудита и выявите какие-то ошибки, вы готовите окончательный вариант ТЗ программисту. Выбор программиста это тема для отдельной статьи. Искать их можно на фриланс-биржах, но подходить к выбору стоит тщательно, ибо полагаться на отзывы и рейтинги сложно в силу их частой накрутки.
Программист оценивает фронт работ, озвучивает стоимость и сроки исполнения, после чего вы все это утверждаете и он начинает вносить в сайт необходимые правки (платить ему лучше поэтапно после проверки выполнения каждого пункта ТЗ). Как вариант, можете все делать и сами, но некоторые моменты будут весьма сложны для новичков и можно понаделать «не того».
В следующих статьях данной рубрики планирую подробно поговорить про коммерческие факторы ранжирования, про то, что сегодня из себя представляет SEO, про то нужны ли для продвижения ссылки и как заполучить самую идеальную из них. Подробно поговорим про SEO тексты, LSI фразы и многое, многое другое.
P.S. Гугл опубликовал совсем недавно новую версию своего руководства по поисковой оптимизации для начинающих. Знаете, что самое смешное? Большая часть их рекомендации была озвучена мною выше. Так, что это вовсе не «злое» SEO, в вполне себе «доброе». Во многом, именно эти моменты очень важны и самим поисковикам.
Комментарии и отзывы (2)
Здравствуйте. У меня такой вопрос: где найти нужную строку, колонку, столбец, с ошибками, который выдал валидатор на сайте на вордпрес и где найти эти файлы в которых нужно исправлять ошибки? Может быть у Вас есть уже статья на эту тему? Спасибо. С ув. Сергей
М-да, 1500 сбп размазано на огромный лонгрид. Дизлайк!
Ваш комментарий или отзыв