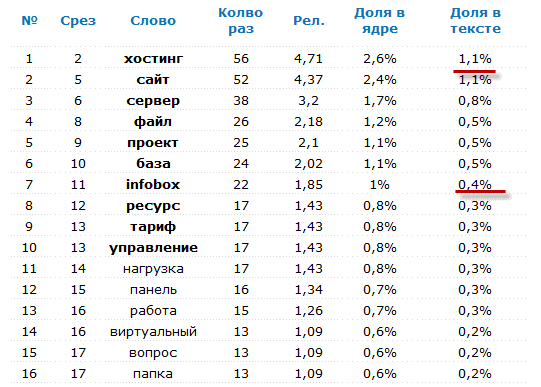
Ключевые слова — что это такое и почему они так важны для текстов
Здравствуйте, уважаемые читатели блога KtoNaNovenkogo.ru. Такое понятие как ключевые слова является основополагающим при анализе текстов. Причем как художественных, так и текстов, которые ранжируются поисковыми системами в интернете.

По ним можно легко понять, о чем идет речь в данном тексте, а значит и отнести его к той или иной категории. Поисковые системы используют это понятие, чтобы сортировать страницы всех сайтов интернета в соответствии с запросами пользователей.
Чем четче будут заданы ключевые слова в тексте — тем выше будут шансы получить много читателей для своего сайта из поисковых систем.
Что такое ключевые слова
Сначала посмотрим, что представляет из себя этот термин в общем смысле:
Ключевое слово — фраза или слово в тексте, способная в совокупности с другими ключевыми словами дать описание содержания текстового документа, выявить его тематику. В вебе используется главным образом для поиска. Набор ключевых слов близок к аннотации, плану и конспекту, которые тоже представляют документ с меньшей детализацией.

В области SEO этот термин означает примерно тоже самое:
Чтобы найти нужную информацию в Интернете, пользователи вводят в поисковую строку соответствующие слова (поисковые запросы), и по результатам поиска находят подходящий источник, то есть сайт. Эти поисковые запросы, по сути, идентичны ключевым словам, под которые затачивался текст страниц этих сайтов.
То есть, в поисковых системах по определенным поисковым запросам пользователям показывают только те страницы, которые заточены точно под эти же ключевые слова, либо очень близкие к ним по значению. И только между такими страницами ведется ранжирование (расстановка сайтов в выдаче по степени релевантности поискового запроса и ключевых слов текста страницы).
Все вместе это на языке поисковых систем называют тестовым ранжированием. Если ваш текст про что-то, но это что-то вы называете не так, как это спрашивают у поисковых систем пользователи, то ваша страница будет ранжироваться хуже, либо не будет и вовсе участвовать в ранжировании по данному запросу.
Вес ключевого слова в зависимости от связки Html тегов
Не верьте тем оптимизаторам, которые, живя вчерашним днем, говорят, что все решает оптимизация внешняя (получение внешних обратных ссылок). Поисковики сейчас стремятся всеми силами уйти от главенства ссылочного ранжирования, т.к. этот фактор оказался настолько сильно заспамлен, что уже не вызывает у них доверия.
Нет, конечно же, внешние ссылки по-прежнему рулят, но уже не играют первую скрипку при ранжировании по тем или иным поисковым запросам. Все больше внимания поисковики стали обращать на внутреннюю и поведенческую оптимизацию сайтов, постепенно отодвигая ссылочное на второстепенные роли.
Немного отвлекусь и обращу ваше внимание на то, что если будут не совсем понятны употребляемые в статье SEO термины, то ознакомьтесь предварительно с этой публикацией — Как продвигать сайт начинающему вебмастеру.
Но вернемся к нашим экспертам и результатам их исследования касаемо влияния различных факторов внутренней оптимизации на продвижение. Напомню вам, что по методологии исследования , в каждой группе факторов за сто процентов берется наиболее значимый — в нашем это добавление ключевых слов в мета тег Title. Все остальные факторы будут оценены относительно этого мегафактора.
Итак, после того, как мы разобрали влияние заключения ключевых слов в различные Html теги, опираясь на самую первую таблицу исследования, пора переходить к следующей таблице «Влияние связок HTML тэгов на вес ключевого слова для страницы»:

Сразу хочу обратить ваше внимание, что здесь приведены не только те факторы внутренней оптимизации (а точнее их связки), которые влияют в положительную сторону, но и те, которые оказывают негативное влияние. Таких негативных связок вам нужно будет избегать в будущем, а также устранить уже имеющиеся огрехи. Ну это все была «агитация за советскую власть», и уже, наверное, пора переходить к конкретике.
Итак, первые три строчки рассматриваемой таблицы («Ключевое слово в H1-H6 & в P», «КС в STRONG, B, EM & КС на странице», «КС в KEYWORDS и КС на странице») имеют разную степень влияния на успешность продвижения сайта по мнению экспертов, но смысл, заложенный в этих пунктах, примерно одинаковый: ключевые слова в заголовках, тегах акцентирования и KEYWORDS должны быть релевантны тексту на странице.
Т.е. эти ключевые слова должны присутствовать в тексте, а не только в упомянутых Html тегах. Думаю, что суть понятна — не надо выделять тегами все имеющиеся ключи, а только их небольшую часть.
Небольшое влияние оказывает «Последовательное употребление заголовков», т.е. когда у вас уровни используемых заголовков следуют в порядке их вложенности (убывания значимости). Но кроме положительно влияющих на продвижение факторов, в этой таблице упомянуты и отрицательные моменты, которых нужно будет по возможности избегать.
Самое страшное зло, которое вы можете причинить своему проекту, это употребление в H1 — H6 тегов выделения STRONG, B, EM, также не следует использовать более одного раза на странице заголовки уровня H1.
Кроме этого негативное влияние на продвижение может оказать заключение H1 — H6 в теги ссылки (если у вас на странице со статьей заголовок является ссылкой на эту же самую страницу, то приложите все усилия, чтобы это исправить).
Ключевые слова в заголовках Title и H1 — H6
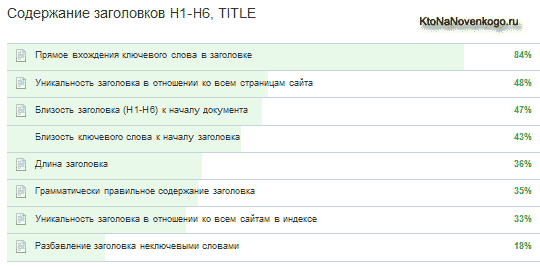
Итак, прямое вхождение ключевого слова в заголовок, по мнению экспертов, имеет очень большое влияние на успешность раскрутки. Под прямым вхождением следует понимать точное соответствие (падеж, число и т.д.) выбранному вами поисковому запросу.
А под заголовками здесь, наверное, подразумеваются не только Title, но и H1 — H6, хотя, конечно же, ключевые слова в тайтле имеют гораздо больший вес, чем в них, и именно в Title нужно, по мнению экспертов, обязательно употреблять прямое вхождение.
Когда мы рассматривали способы подбора семядра в Вордстате Яндекса, то использовали для уточнения «операторы кавычек и восклицательных знаков», для того, чтобы определить реальное количество запросов именно по точному вхождению ключевых слов.
Прямое вхождение будет отличаться от точного только тем, что допускает включение знаков препинания между ключевыми словами.
Следующим пунктом идет уникальность заголовка в отношении ко всем страницам сайта. Здесь имеется в виду скорее всего именно Title, ибо они просто обязаны быть уникальными и ни в коем случае не повторяться, ибо поисковики этого не любят и не преминут вам об этом напомнить на соответствующих страницах панели вебмастеров от Google или Яндекс Вебмастера, описанного тут.
Правда достичь уникальности всех тайтлов довольно сложно из-за несовершенства большинства CMS, но к этому нужно стремиться и важность уникальных тайтлов еще раз подчеркивает оценка экспертов. Возможно, вам окажутся полезными следующие материалы по этой теме: формирование правильного Title в Joomla и для WordPress.
Дальше в рассматриваемой таблице идут два пункта «Близость (H1-H6) к началу документа» и «Близость ключевого слова к началу заголовка», имеющих довольно-таки существенное влияние на продвижение сайта. Ну тут, наверное, понятно, что имеет смысл использовать ключевые слова в различных заголовках ближе к их началу (по возможности), а также располагать H1 — H6, по возможности, ближе к началу оптимизируемого текста.
Наверное, следует оговориться, что данные рекомендации эксперты дают прежде всего для продвижения по среднечастотным и высокочастотным поисковым запросам, которые к тому же еще и являются, как правило, высоконкуретными. Поэтому при этом нужно использовать все нюансы оптимизации по максимуму для попадания в топ.
Мы же с вами, уважаемые читатели, скорее всего будем продвигаться по НЧ и нам не нужно будет фанатично следовать рекомендациям, которые можно вывести на базе исследования, а нужно будет адаптировать их под свою ситуацию.
Примером этого суждения может послужить следующий пункт рассматриваемой таблицы под названием «Длина заголовка», которая по мнению экспертов оказывает влияние, но не столь сильное.
Наверное, при продвижении по ВЧ и СЧ будет иметь смысл делать короткие заголовки для того, чтобы ключевые слова не потеряли в них свой вес. В то время как при продвижении по НЧ будет иметь смысл делать их подлиннее, тем самым расширив количество ключей, по которым сможет ранжироваться данная статья.
В строке «Грамматически правильное содержание» имеется в виду, наверное, не орфографическая грамотность Title, а правильное стилевое составление заголовков с использованием ключевых слов в правильных падежах, числах и т.п.
Ведь можно тупо использовать прямое вхождение ключевых слов, но при этом получить коряво написанное предложения с точки зрения русского языка (твоя моя не понимай), хотя говорят, что и корявые тексты с прямым вхождением ключей в заголовке тоже рулят, но, наверное, до поры до времени.
«Уникальность заголовка в отношении ко всем сайтам в индексе» имеет небольшое влияние на успешность продвижения вашего проекта, но все равно не стоит тырить их у конкурентов из топа, в надежде встать рядом с ними. «Разбавление заголовка неключевыми словами» иногда может быть полезн, наверное, в силу приобретения большей естественности.
В таблице «Содержание элементов абзаца STRONG, EM, B» говорится о том, что заключать в теги выделения в первую очередь желательно именно прямое вхождение ключевых слов, но также можно их разбавлять и неключевыми словами, наверное, опять же для придания естественности.
Ключевые слова в тексте страницы

Из приведенной таблицы «Ранжирование по ключевым словам» видно, что самую большую важность имеет употребление прямого вхождения поискового запроса на странице. Т.е. хотя бы один раз (а лучше будет даже несколько раз) в тексте должно быть употреблено прямое вхождение ключевого слова.
Но кроме этого в тексте следует еще употреблять другие словоформы этого ключа (падежи, числа и т.д., вплоть до изменения части речи), а также разбавлять как прямые вхождения, так и словоформы ключевых слов другими неключевыми добавками. Таким образом вы повышаете естественность употребления ключей в вашем тексте.
Тут, наверное, наиболее интересной является последняя строчка «Удаление частей составного словосочетания друг от друга», которая в очень сильной степени может отрицательно повлиять на ваши усилия по продвижению сайта.
Дело в том, что ключевые слова из многих поисковых запросов нужно будет употреблять в тексте только рядом с друг другом, не добавляя между ними другие фразы, которые могут в этом случае свести на нет все ваши усилия по насыщению текста ключевиками.
Поисковые системы в этом случае могут не учесть данные ключевые слова, как единый поисковый запрос и, соответственно, это отрицательно повлияет на ранжирование.
Правда некоторые запросы можно запросто разбивать другими словами, но это все зависит от видения данной ситуации поисковыми машинами, которые при анализе будут ориентироваться на все другие проиндексированные сайты похожей тематики и смотреть, как у них употреблены ключи из поискового запроса — слитно или же с разделением.
Влияния HTML тэгов на вес ключевого слова
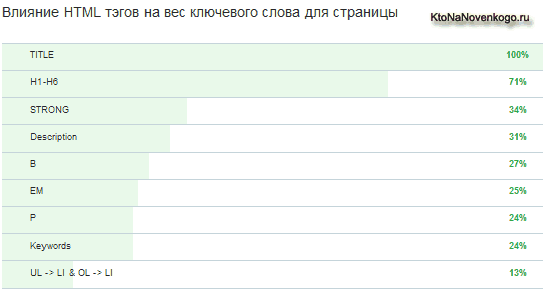
Итак, в таблице показано влияние HTML тэгов на веса ключевого слова для страницы. Что это вообще такое? Ну, наверное, вы понимаете, что для того, чтобы поисковая система поняла о чем ваше статья (по какому запросу ее нужно будет ранжировать), вам придется не один раз употребить в тексте так называемые ключевые слова (фактически слова из того запроса, по которому вы хотите попасть в Топ).
P.S. Если вам не совсем понятны используемые мною термины, то ознакомьтесь предварительно с этой публикацией — Как продвигать сайт начинающему вебмастеру.
Так вот, простое упоминание ключевых слов в тексте это хорошо, но еще лучше, если они иногда будут заключены в специальные Html теги, которые позволяют увеличить их вес. Тем самым вам не нужно будет излишне заспамливать текст ключами для получения той же релевантности поисковому запросу.
В приведенной на рисунке таблице как раз и указаны в порядке убывания влияния те Html теги, в которые следует заключать ключевые слова. Но оговорюсь, что ни в коем случае не все ключевики из текста, а только их небольшую часть.
По методологии исследования, в каждой отдельной группе факторов, влияющих на успешность раскрутки проекта, за сто процентов берется значение того фактора, за который эксперты отдали больше всего балов. В группе внутренней оптимизации таким супер фактором стал мета тег Title (аплодисменты, переходящие в овации).
О том, что такое Title, читайте по приведенной ссылке, но кроме этого важно знать про способы автоматического формирования правильного тайтла в Джумле и в WordPress, а также про то, как прописать тайтл в Joomla и как это сделать в WordPress.
Саму важность добавления ключевых слов в этот мета тег для успешного поискового продвижения сайта очень трудно переоценить, и эксперты в этом вопросе единодушны.
Следующим по важности внутренним фактором при рассмотрении различных Html тегов является добавление ключевых слов в заголовки уровней от H1 до H6. Вообще, в других таблицах исследования будут приведены данные, говорящие о том, что в текстах желательно использовать различные заголовки, таблицы, картинки, списки и т.п. способы структурирования текста с помощью тэгов.
- Как вставлять изображения в Html код с помощью тега IMG описано тут и тут
- Как создавать гиперссылки — здесь
- Маркированные и нумерованные списки — тут
- Таблицы различной сложности и вложенности — тут
- Html формы — здесь
- Форматирование текста в HTML, Html шрифты, Strong, Em, B, I — тут
Но употребление ключевых слов в заголовках H1 — H6 оказывает самое сильное влияние на увеличение веса этих ключей после Title. Это нужно знать и применять, но использование очень большого количества заголовков в небольшом по размеру тексте может быть рассмотрено поисковыми системами как спам со всеми вытекающими последствиями.
Поэтому вставляйте H1 — H6 и употребляйте в них ключевые слова, но без фанатизма, а только на благо удобству восприятия материала пользователями (не забываете, что поведенческие факторы ранжирования сейчас в фаворе).
Дальше в таблице влияния HTML тэгов на вес ключевого слова для страницы идет ряд тегов, имеющих по мнению экспертов примерно равное влияние на продвижение сайта.
Причем о влиянии заключения ключей слов в теги STRONG, B и EM на повышение релевантности страницы поисковому запросу я знал и раньше, но вот то, что ключевые слова включенные в мета тэг Description обладают теми же самыми свойствами, не знал.
Честно говоря для меня это новость, ибо то, что мета тег Description нужно обязательно заполнять (как Description в Joomla и в WordPress), т.к. на его основе может быть сформирован сниппет в поисковой выдаче Google, я не раз писал, но при этом свято верил, что включенные в него ключевики нужны только для того, чтобы быть выделенными жирным в сниппете. А оказывается, что они тоже влияют на ранжирование и это для меня стало новостью и своеобразным открытием.
По поводу выделения ключевых слов тегами STRONG, B и EM хочу еще добавить, что не стоит делать через CSS текст, выделенный ими, по внешнему виду не отличимым от обычного текста (так советовали раньше многие SEO специалисты). В одной из таблиц исследования говорится, что это может отрицательно повлиять на успешность продвижения вашего проекта. Возможно, что поисковики умеют сами это определять или же реагируют по факту письма Платону от доброжелателя.
Сам я использую в 95 процентах STRONG для выделения некоторых ключевых слов и изредка EM, а тег B практически вообще не использую. Почему именно так повелось, сейчас уже сказать затрудняюсь — просто привычка, наверное.
Давайте продолжим. По результатам опроса экспертов получается, что в некоторой степени на увеличение релевантности страницы поисковому запросу также влияет и заключение ключевых слов в теги абзаца P и добавление их в Keywords (для Joomla и WordPress его можно прописать точно так же, как и Description, о котором мы говорили чуть выше).
С последним утверждением я согласен, ибо в хелпе поисковиком написано, что ключевые слова в Keywords будут учтены, если они реально встречаются в тексте, в противном случае эти ключи могут быть расценены как спам.
Но вот про абзац P не совсем понятно, ибо практически на всех сайтах этот тег используется и весь текст будет заключен в абзацы. Хотя, возможно, тут идет речь о том, что пренебрежение абзацами или их замена на двойной BR может привести к понижению релевантности страницы поисковому запросу. В общем, это тоже оказывается нужно учитывать при продвижении.
Ну и последним пунктом в таблице влияния на вес ключевого слова для страницы идут теги списков, заключение ключей в которые практически никак не влияет на релевантность страницы этому поисковому запросу. Но списки в текстах использовать периодически все равно надо, ибо по результатам этих же исследований структурирование и придание разнообразия тексту нравится поисковикам. Про подбор ключевых слов читайте по приведенной ссылке.
Вот так вот долго мы разбирались с рекомендациями экспертов по поводу влияния тэгов акцентирования. Осталось еще очень много сводных таблиц с различными факторами, в той или иной степени влияющих на успешность продвижения, но думаю, что там дело пойдет быстрее, ибо сложнее всего бывает с разжевыванием самых простых вещей.
Нужно ли продолжать это делать, решать вам, уважаемые читатели. Попрошу вас высказаться в комментариях, во-первых, по поводу рассмотренных сегодня факторов влияющих на ранжирования, а во-вторых, по поводу продолжения подобного разжевывания всех оставшихся результатов исследований. Спасибо за внимание и с нетерпением жду разгромных комментариев, которые всегда имеют место быть в моих статьях по тематике продвижения сайтов.
Подбор ключевых слов и анализ текста на переоптимизацию
Важным моментом при написании текстов является изначальный выбор правильных ключевых слов, на которые вы будете делать акцент (изредка и очень аккуратно выделять их тегами STRONG, использовать их равномерно в тексте и иногда во внутренних заголовках). В будущем ваша статья будет бороться за ТОП поисковой выдачи по запросам, в которых будут использоваться эти ключевые слова, на которые вы сделали акцент.
Я, в большинстве случаев, выбираю ключевики интуитивно, хотя для этой цели существует довольно-таки удобный инструмент Яндекса под названием "Статистика ключевых слов", о котором довольно подробно писал в статье про Вордстат и составления семантического ядра сайта.
Например, если вы точно не знаете какой именно вариант ключа будет лучше, то можете ввести их оба в форму Вордстата и наглядно увидеть, что чаще всего заращивают пользователи:
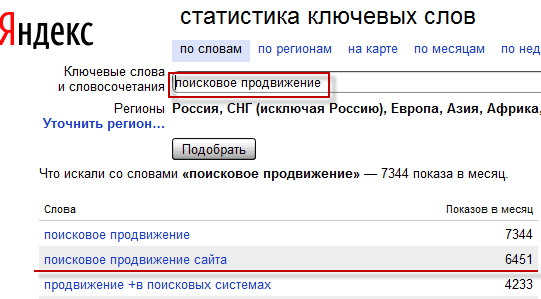
Выбрав наиболее частотный вариант, вы сможете побороться за топ по более перспективному запросу. В противном случае, можно так неудачно выбрать ключевые слова для статьи, что даже попав в ТОП по многим сверхнизкочастотным запросам (меньше 100 в месяц), существенного трафика так и не получите.
У Google тоже есть сервис по подбору ключевых слов, который вы тоже можете использовать. Подробнее про него читайте в моей публикации на тему анализа статистики поисковых запросов в Яндексе и Гугле, расположенной тут.
Не стоит выделять во всем тексте материала исключительно только ключевые слова. За это можно словить фильтр, как я, например. Можно разочек выделить тегом STRONG точное вхождение, а дальше уже стронги использовать только для реального подчеркивания важности определенных фраз для ваших читателей, а не в угоду поиску.
Таким образом посетителям будет легче ориентироваться в тексте. Для этой же цели я использую промежуточные заголовки, которые не только и не столько включают ключевые слова, но и помогают читателям найти интересующее их место в тексте.
Конечно же, в подборе и употреблении в тексте нужных ключей в различных словоформах или их синонимов, очень много зависит от интуиции, которая будет работать тем лучше, чем больше опыта в области поискового продвижения у вас будет.
После того, как вы напишите статью, обязательно проанализируйте ее текст в сервисе ISTIO. Если ваш материал уже опубликован, то введите его адрес в верхнее поле и нажмите на кнопку «Отфильтровать текст», в результате чего в поле «Текст для анализа» появится его содержимое и вам останется только нажать на кнопку «Анализ текста».
Если материал вы опубликовать еще не успели, то в этом случае скопируйте его и вставьте в поле «Текст для анализа», после чего нажмите кнопку «Анализ»:

Откроется новое окно, где в области «Наиболее частые слова (БЕЗ стоп-слов)» посмотрите, какие из них являются наиболее употребляемыми в данном материале. В идеале, в самом верху этого списка должны находиться ключевики, по которым вы хотите продвинуть данную статью.
Но зачастую наиболее употребляемыми оказываются не ключевые, а совершенно к ним не относящиеся слова. У меня во многих постах частота слов «сайт» или «страница» сильно превышает употребление ключевиков.
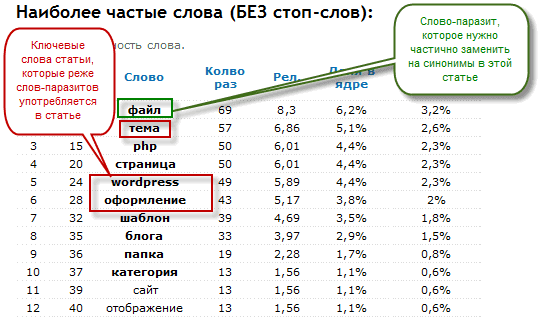
Такая ситуация печальна (мешают очень часто употребляемые слова, которые не являются по вашей задумке ключевыми). Продвигаемую страничку должно «тошнить» именно ключевыми словами, тогда вероятность попадания их ТОП, будет значительно выше. Понятие «тошнота» мы рассмотрим чуть позже, а пока просто примем к сведению этот факт.
Когда страницу «тошнит» именно от ключевых слов, то это хороший шанс на попадание в ТОП по поисковому запросу, содержащему данные ключевики. Правда это же может быть и причиной попадания под упомянутый чуть выше фильтр за переоптимизацию.
Поэтому не спамте ключами, а употребляйте их не чаще одного раза в абзаце и лучше всего в разных словоформах или даже в виде синонимов. Мне кажется, что такой процент будет безопасным.
Все описанные выше действия, относящиеся к понятию внутренняя оптимизация сайта, мы должны делать при каждом написании статей, но даже оптимальное выполнение всех этих условий не гарантирует вам стопроцентный успех (только 0.99 процентов).
Тем более, что даже, если вы правильно составили заголовок статьи, употребив в нем ключевые слова, мета-тег заголовка страницы TITLE, который является одним из самых значимых рычагов оптимизации, может быть сформирован не оптимальным образом.
Оптимальный мета-тег TITLE (заголовок страницы, содержимое которого вы можете увидеть в самом верху окна браузера) должен иметь вид: Название статьи — Название проекта. Для того, чтобы формировались правильные TITLE, можете воспользоваться следующими материалами по данной теме:
- Настройка TITLE в All in One SEO Pack для WordPress
- Title для Joomla
- TITLE с помощью плагина ARTIO JoomSEF
Но одновременно Тайтл является и вашим бесплатным объявлением в выдаче поисковых систем, а значит он должен быть привлекательным для пользователей. Про хитрости составления правильных TITLE читайте тут.
Боремся с дублями контента и настраиваем перелинковку
Для многих движков вебсайтов так же очень остро встает проблема дублирования контента, когда на страничках вашего проекта с разными адресами присутствует один и тот же текст. Поисковые системы относятся к этому плохо, а почему — я писал в этой статье про то, как работают поисковые системы.
В WordPress для этих целей можно использовать возможности универсального SEO плагина All in One SEO Pack, ссылка на который приведена чуть выше. В нем можно активировать возможность проставления на страничках с дублями специального мета-тега CANONICAL, который укажет поисковику на адрес оригинала данного материала. Как это сделать, читайте все в том же материале про чудесный плагин.
Я, например, так же для избежания дублирования контента в своем блоге на WordPress запретил в All in One SEO Pack индексацию страниц с временными архивами и архивами тегов, разрешив только индексацию с содержанием рубрик.
В результате документов в индексе Яндекса и Гугла стало меньше, но зато там уже не будет дублей, да и удаленные документы у меня не несут особой смысловой нагрузки. Лучше меньше, да лучше. Тем более, что в Google эти странички скорей всего попали бы в дополнительный (сопливый) индекс, поиск по которому не ведется и про который речь шла здесь.
Так же во избежании дублирования контента на главную страничку блога выводятся только анонсы материалов, а их полные версии открываются по ссылке «Читать далее», текст которой я сделал индивидуальным для каждой статьи с помощью тега MORE, как описано тут.
Тоже самое можно сделать и для блога на Joomla — подробнее об этом читайте в этом материале.
Так же для борьбы с дублированием контента можно прибегнуть к помощи файла ROBOTS.TXT, возможности которого описаны тут, там же вы найдете и примеры наиболее удачных файлов для Joomla, Вордпресс и форума Smf.
Внутренняя перелинковка позволяет перераспределить статический вес (pagerank, описанный здесь) между страницами вашего сайта.
Честно скажу, что по началу совсем не заморачивался с внутренней перелинковкой. В том смысле, что делал ее, как бог на душу положит, а не так, как велит научный подход к вопросу, о котором я писал тут. А вы знаете оптимальную схему перелинковки для продвижения сайта исключительно по низкочастотным поисковым запросам? На самом деле, один из вариантов вы найдете по приведенной ссылке.
Однако, она должна сводиться к тому, чтобы странички сайта, те на которых размещены статьи, получили бы максимально возможный статический вес.
Я уже написал довольно большой мануал по Google PageRank и привел чуть выше ссылку на него. Но понятие статического веса используют все поисковые системы, а не только Гугл, просто у него есть тулбарное значение ПР, которое можно узнать и посмотреть, а у других поисковиков открытой информации о статическом весе страниц нет.
Но принцип перераспределения статвеса остается примерно таким же, как и в случае с Гугл PageRank — с одной страницы на другую передается вес по ссылке, но не полный, а только его часть (раньше считали что это 0.85, но сейчас склоняются к цифре 0.1).
Все расчеты в различных схемах внутренней перелинковки выполняются за несколько итераций (повторных вычислений), пока разница между соседними вычислениями не будет достаточно малой. Тогда считают, что рассчитали статический вес передаваемый по ссылкам в данной схеме.
В них не учитывают ссылочное ранжирование (динамический вес), т.к. передаваемый статвес не зависит от текста ссылки (анкора). Так вот, в случае продвижения по НЧ, нам нужно будет нагнать наибольший вес на статьи. При обычном раскладе внешние ссылки у большинства проектов проставлены на главную, а значит нам нужно будет его перераспределить с главной на внутренние страницы.
Вот так будет выглядеть идеальная схема под НЧ:
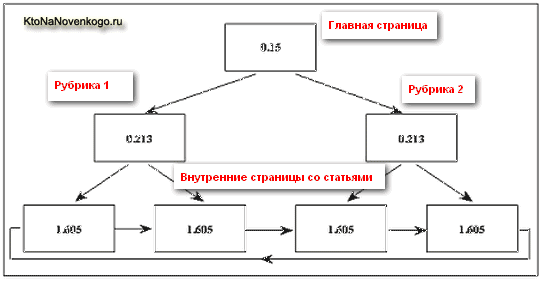
Стрелочками показаны направления ссылок. Как вы можете видеть, статический вес перераспределился в пользу страниц со статьями, убавив статический вес главной и рубрик. При простановке на главную нескольких внешний обратных ссылок, мы получим такую картину маслом:
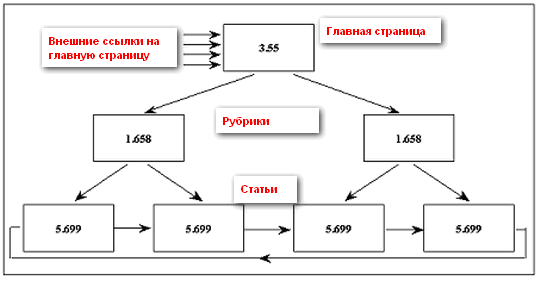
Но наилучшим вариантом будет простановка внешних обратных ссылок не на главную, а непосредственно на страницы с текстовыми материалами. В этом случае расклад получится следующим:
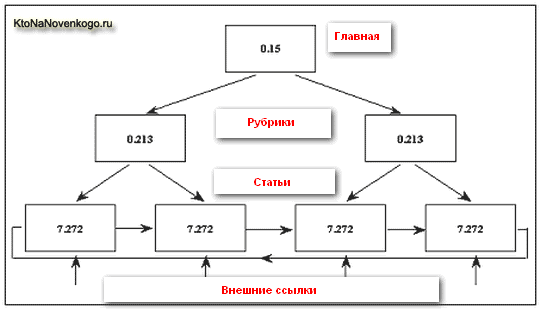
Поэтому при продвижении по НЧ следует учитывать то, что лучше всего покупать (или получать в результате обмена) обратные ссылки на внутренние страницы, а не на главную.
Но данная схема перелинковки является сложно реализуемой, ибо нарисовать картинку это одно, а реализовать все это на реальном проекте — совсем другое. На практике считается не плохим вариантом создание небольшого блока ссылок внизу статьи (подсказывающих пользователю аналогичные по тематике материалы). Что то подобное я реализовал у себя и описал тут и тут.
Я так же активно проставляю ссылки на другие свои материалы прямо в тексте статей, что улучшает внутреннюю перелинковку, а так же способствует увеличению количества страниц, просмотренных одним пользователем. Показатель глубины просмотра возможно учитывается поисковыми системами при составлении мнения о том или ином ресурсе.
Умеренная оптимизация текста под ключевые слова
Обычно внутренняя поисковая оптимизация сайта включает в себя написание текста статьи с таким расчетом, чтобы в ней встречались выбранные вами ключевые слова, по которым вы хотите попасть в Топ 10 поисковой выдачи. Как часто должны включаться ключи в тексте статьи — отдельный вопрос, но, пожалуй, их плотность в свыше 1-2 процента от общего числа слов в статье будет максимально допустимой, а если больше, то это уже спам и искусственная накрутка.
Позволю себе напомнить вам некоторые материалы, на которые я ссылался в первой части мануала по продвижению и которые могут вам пригодиться как раз при рассмотрении сегодняшних вопросов. Во-первых, это серия материалов по внутренней оптимизации, а также некоторые советы по внутренней оптимизации под Google.
Ключевые слова в тексте старайтесь употреблять в разных словоформах (падежах, числах и т.п.) и не употреблять их дважды в пределах одного предложения или даже абзаца, а еще старайтесь равномерно распределить их по статье. Для усиления их влияния, некоторые из них (ни в коем случае не все, а то поисковики дадут вам по рукам) можно выделить тегам STRONG или EM, а также ключевики можно использовать в заголовках h1-h6.
Не знаете Html тегов? Это довольно просто и доступно, попробуйте для восполнения пробелов воспользоваться данной рубрикой HTML для начинающих.
Теперь самое важное — обязательно употребите ключевые слова в мета теге Title (заголовке страницы). Если этого не сделать, то продвинуть данную статью будет крайне сложно или вообще невозможно. Вообще, про самостоятельное продвижение я уже писал довольно подробно, поэтому после прочтения этой публикации не примените ознакомиться с материалом по приведенной ссылке.
Title мало того, что должен включать в себя ключевики, он должен правильно формироваться используемой вами CMS (системой управления контентом). Ибо зачастую в нем сначала идет название всего ресурса, а уже только потом название данной конкретной статьи. Чем это плохо?
Да всем плохо. В Title поисковыми системами учитывается только ограниченное число слов, и если название вашего проекта очень длинное, то все тайтлы будут для поисковиков одинаковыми, что не принесет вам никакой пользы, а только лишь один вред.
В правильно сформированном в автоматическом режиме тайтле в начале должно идти название статьи, расположенной на этой странице, а уже только после него название вашего ресурса. Это обязательно нужно учитывать при создании сайта (формирование правильного Title в Joomla и тайтлы в WordPress).
Также правильно составленный и сформированный мета тег Title, о котором читайте тут, может оказать существенное влияние на пользовательские факторы, что, в свою очередь, может как помочь, так и помешать продвигать свой сайт. Но об этом уже читайте в третье части данного мануала.
При написании текста статей следует еще учитывать тот факт, что Яндекс и Гугл отдают предпочтение хорошо структурированным текстам, в которых используются заголовки различных уровней (H1-H6), если объем текста будет достаточно большим для этого. Но заголовок уровня H1 на каждой странице должен быть в единственном числе, иначе это может быть засчитано как спам.
Все остальные уровни заголовков можно использовать неограниченно, но они должны соблюдать вложенность (внутри заголовка уровня H3 можно использовать заголовки H4-6, но не H2). Ну и ключевые слова в заголовки не забудьте добавлять, ибо их влияние после заключения в эти теги заголовков несколько увеличивается. Опять же, спамить нельзя ни в коем случае.
Также поисковикам нравится, когда текст разбавляется различными Html списками, таблицами или изображениями. При вставке изображения в текст с помощью тега IMG, обязательно пропишите ему атрибут ALT, в котором употребите ключевые слова, ибо они тоже будут учтены поисковыми системами.
Да и само изображение получает шанс поучаствовать в поиске по изображениями от Яндекса и Google. Правда реальный трафик с поиска по картинкам может существовать только в определенных тематиках, но несколько десятков переходов в сутки вам тоже, наверное, не помешают. Названия файлов с изображениями тоже можно будет составить из ключевых слов преобразованных транслитом.
Еще один важный момент, который может в той или иной степени повлиять на то, насколько просто будет вам продвигать сайт — это активация ЧПУ (человеко-понятных урлов) в используемой вами CMS. Это дает возможность заменить адреса (URL) страниц с вида (edit.php?post_type=page) на понятный пользователям и поисковым системам вид (https://ktonanovenkogo.ru/gde-vzyat-vneshnie-ssylki).
ЧПУ ссылки дают сразу два преимущества. Во-первых, вашим посетителям будет легче ориентироваться даже просто используя Урлы страниц, особенно, если вы включите в них названия разделов и категорий, к которым они принадлежат.
А, во-вторых, ключевые слова, написанные транслитом в URL подверженных такому преобразованию, будут учитываться поиском, что наглядно можно увидеть в поисковой выдаче по любому запросу (они будут выделены жирным). Это опять же будет привлекать больше внимания пользователей и повышать ваши поведенческие характеристики.
ЧПУ лучше делать на транслите, а не на кириллице. В качестве разделителя используйте тире, ибо оно воспринимается поисковыми системами, как символ разделения слов (в отличии от символа подчеркивания). О его включении читайте подробнее здесь — SEF для Joomla, ARTIO JoomSEF, ЧПУ в WordPress.
Внутренняя оптимизация должна тоже в обязательном порядке включать и перелинковку. Что это такое и для чего она нужна? Для примера зайдите на сайт Wikipedia и убедитесь, что со страницы с любой статьей будет идти множество ссылок на другие публикации прямо из текста материала (я не говорю про элементы навигации, меню и т.п., говорю именно про гиперссылки, вставляемые из текста, ибо это наиболее эффективный способ линковки).
А теперь скажите — вы часто видите Википедию на первых позициях в выдаче? А это в том числе и за счет такой всеобъемлющей внутренней перелинковки, хотя и не только из-за этого (тут может быть и в трасте причина), но это уже тема для отдельного разговора о нюансах работы поисковых систем.
Есть различные теоретические схемы правильной внутренней линковки, например, перелинковка под низкочастотные запросы. Но лично я делаю ее по схеме «сфера», когда статьи одной тематики ссылаются на множество других, но из этой же темы (говорят, что линковка внутри кластеров одного сайта эффективна, а вот между ними не очень). Получается несколько сфер линковки, которые также связаны и между собой.
В общем случае, ее значимость для продвижения сайта можно сравнить с кровеносной системой человека. Чем больше будет пронизан внутренними ссылками ваш проект (не стоит делать однин большой сквозной блок с ссылками, который будет отображать на всех страницах, а именно линковать из текста статей), тем равномернее будет распределяться по его страницам статический вес (это аналог крови) и тем выше будут стоять страницы вашего проекта в поисковой выдаче.
Статический вес передается между любыми страницами в интернете по гиперссылкам, если они не закрыты от индексации поисковыми системами. Причем не важно, будут ли это страницы вашего же ресурса (внутренние линки) или же это будут страницы других ресурсов (внешние). Поэтому, если ваш проект содержит достаточное количество хорошо перелинкованных между собой страниц, то статический вес (который можно косвенно оценить по тулбарному значению PageRank) может быть очень существенным и позволит страницам стоять выше в выдаче при прочих равных условиях.
Также учтите, что длина текста ваших статей тоже может помочь или, наоборот, помешать успешно продвинуть проект. Текст не должен быть слишком коротким (мне кажется, что нужно хотя бы 1000 слов), но и слишком длинным делать его нет смысла, ибо это было преимуществом несколько лет назад, но после того как оптимизаторы стали злоупотреблять этим фактором, влияющим на релевантность (писать полотенца вроде некоторых моих статьей), поисковики резко снизили влияние длинных текстов на ранжирование.
Однако, короткие статьи рискуют просто выпасть из индекса поисковых систем, особенно, если у вас имеет место быть очень большой сквозной блок (сайдбар, куча меню, навороченный футер и т.п. блоки, отображаемые на всех страницах ресурса). Да, конечно же, Яндекс и Гугл умеют отделять сквозные блоки от полезного контента и учитывают их по разному, но это не мешает им выкидывать короткие посты из индекса за неполное дублирование.
Уникальный контент и проблема дублирования
Мы тут, кстати, подошли к архиважной проблеме, мешающей продвигать ресурсы многим начинающим вебмастерам. Я говорю о дублировании контента. Поймите и запомните раз и навсегда — поисковые системы не любят полные или частичные дубликаты страниц, причем не важно, дубликат ли это вашей же страницы или дубль статьи скомунизженной с другого сайта. Хотя во втором случае наказание может быть более жестким, особенно в последнее время.
Почему им не нравятся дубли в любом виде? Да все очень просто и банально. Индексируя кучу дубликатов, они вынуждены задействовать дополнительные резервы для хранения данных дублей (компьютерные мощности), а любые лишние расходы вызывают у коммерсантов желание бороться с причинами их вызывающими.
Поэтому не допускайте ситуаций, когда у вас могут появиться полные или частичные дубликаты страниц. Что для это нужно делать или не делать? Ну, во-первых, не нужно копипастить чужие статьи, пусть даже и частично. Это не хорошо со всех точек зрения, в том числе и с точки зрения того, что продвигать сайт с не уникальным контентом будет на порядок сложнее, да и риск попасть под страшный фильтр АГС (почти все страницы ресурса будут удалены из индекса Яндекса) или его аналогов в Google, будет крайне высок.
Т.е. получается, что уникальный контент — это тот минимум, который будет вам необходим для того, чтобы успешно продвинуться. Но одного этого, к сожалению, не достаточно. Почему «к сожалению»? Да потому что поисковики еще не так умны, чтобы вровень с человеком уметь отличать хорошие статьи, просто их прочитав.
Они оперируют только такими единицами информации как слова и если вы в своем уникальном, со всех точек зрения, тексте не упомяните несколько раз о чем именно ваша статья, то и в Топе поисковой выдачи по желаемому запросу вам, скорее всего, не бывать.
Поэтому, если хотите иметь трафик с поиска, то окромя написания оригинальных материалов озаботьтесь хотя бы минимальной его внутренней оптимизацией и при возможности перелинковкой, в соответствии с описанными мною выше принципами.
Перебарщивать с внутренней оптимизацией тоже нельзя, но и не делать ее вообще будет довольно глупо и не дальновидно (стеснения употребить несколько раз в тексте ключевые слова, боясь праведного гнева читателей здесь не уместны, ибо мы волей не волей загнаны в такие условия современными алгоритмами). Не забывайте, что вы пишите для людей, а если этих самых людей не будет достаточно приходить с поиска, то и писать вам получается нет смысла.
Продолжим про дублирование контента, ибо мы чуть-чуть сбились. Итак, для того, чтобы сайт можно было продвигать без проблем, нужно избавиться по возможности от всех полных и не полных дублей контента. Будем считать, что тексты у нас уникальные и они достаточно длинные, чтобы не быть признанными поисковыми системами неполными дублями из-за больших сквозных блоков.
Но практически любая CMS (система управления контентом) создает дубли (версии страниц для печати, rss ленты и т.п.) и с этим обязательно нужно бороться.
Способ борьбы заключается в создании запретов для поисковиков, учитывая которые они не посмеют затронуть индексацией дубли. Т.о. мы не только сохраним лицо перед поиском (а нету у нас дублей — вот такие мы белые и пушистые), но и снизим нагрузку на сервер, создаваемую роботами всех поисковых систем. К индексации следует по этой причине также запретить и все служебные файлы используемой вами CMS.
Для запрета индексации мы будет использовать так называемый файл robots.txt, важность которого для последующего успешного продвижения очень трудно переоценить. Если вы по каким-либо причинам считаете, что использовать этот файл не нужно, то вы ошибаетесь, в силу того, что просто не знаете или не учитываете всех положительных моментов от его правильного использования (вы не любите кошек? — просто вы не умеете их готовить).
Подчеркиваю, именно правильного файла robots.txt, потому что довольно часто возникают ситуации, когда начинающие вебмастера запрещают к индексации продвигаемые страницы со статьями, что может привести к полному пропаданию поискового трафика. Работать с этим файлом следует осмысленно и обязательно проверять через Вебмастер Яндекса и Гугла правильность его работы (введите ссылку одной из своих статей и посмотрите, не запрещена ли ее индексация).
Что такое файл robots.txt, какие директивы в нем используются, как будет выглядеть оптимальный robots.txt для Joomla и WordPress, я уже довольно подробно описывал. Советую ознакомиться с этими или какими-либо другими материалами, ибо вещь действительно нужная и полезная, хоть и не сразу понятная.
Те кто использует WordPress могут воспользоваться плагином All in One SEO Pack, помогающим решить целый ряд вопросов по правильной индексации страниц блога, а также позволяющего запретить индексировать страницы с неполными дублями и прописать в шапку страниц дублей специальный новый тег Canonical, который подскажет поисковикам, что перед ними дубль и покажет адрес страницы с оригиналом текста, которую и нужно будет проиндексировать.
Стоит еще упомянуть о такой вещи, как склейка зеркал сайта с WWW и без него. Вы, наверное, уже встречали в интернете доменные имена как с WWW, так и без него. В принципе, вы скорее всего понимаете, что оба варианта будут являться одним и тем же ресурсом, но вот поисковые системы придерживаются другого мнения и вполне могут посчитать их двумя разными сайтами со всеми вытекающими последствиями. А какие могут быть последствия?
Да, в принципе, самые печальные. Допустим, что обратные внешние ссылки будут проставлены в основном на ваш домен с WWW, а недальновидные поисковики сделают главным зеркалом без WWW. В результате вся накопленная ссылочная масса (результат внешней оптимизации, о которой мы подробно поговорим в третьей части мануала по продвижению для начинающих) будет потеряна.
Так вот, чтобы этого избежать нужно прописать в файле .htaccess несколько строчек для склейки зеркал, а в файле robots.txt добавить для Яндекса специальную директиву Host (см. ссылку на статью выше), предписывающую ему выбрать в качестве главного зеркала тот или иной вариант. Подробнее обо всех этих перипетиях читайте в данном материале — Домены с www и без него и их склеивание.
Итак, мы подобрали низкочастотные и среднечастотные запросы, по которым будем продвигать сайт, написали уникальные тексты с нужными ключевыми словами, одновременно проведя их внутреннюю поисковую оптимизацию, создали разветвленную схему перелинковки, а также запретили к индексации все полные и не полные дубли контента.
Мы молодцы. В общем-то, уже только этого будет достаточно для продвижения и попадания в Топ по некоторым НЧ (во всяком случае по тем, где нет конкуренции между оптимизаторами, т.е. такими же умными челами как и мы с вами).
Надо продвигать сайт комплексно и равномерно с учетом ключевых слов
Но для того, чтобы продвигать сайт успешно и попасть в Топ по большинству намеченных запросов, одной лишь внутренней оптимизации будет не достаточно. Нужно будет обязательно уделить достаточно времени и сил еще двум факторам, влияющим на успешность процесса — внешняя оптимизации и поведение пользователей на вашем ресурсе.
Причем, недочет или ваша недоработка в одном из этих направлений может привести к нивелированию всех успехов, достигнутых по двум другим направлениям продвижения и оптимизации. В современных условиях двигать проект нужно комплексно, одновременно по всем трем фронтам вести неуклонное наступление и успех не заставит себя ждать.
Но о двух других важнейших факторах, позволяющих успешно продвигать сайт самостоятельно, мы поговорим уже в заключительной части этого мануала. Там во всех подробностях рассмотрим влияние на продвижение внешней оптимизации сайта (ссылочное ранжирование), а еще пользовательских факторов, которым в последнее время очень пристальное внимание уделяют поисковые системы.
Учет морфология языка и отличие ВЧ, СЧ и НЧ ключей
В сегодняшней статье мы продолжим тему изучения работы поисковых систем, начатую здесь. Чтобы оптимизировать свой сайт, нужно хотя бы в общем виде представлять, как работают алгоритмы поиска, как они проводят индексацию документов, как осуществляют выборку по индексной базе и многое другое.

Сегодня мы рассмотрим вопрос учета морфологии языка при формировании выдачи (результатов поиска), узнаем какие проблемы сейчас актуальны для Яндекса и Гугла и как они пытаются их решать, а так же подробно рассмотрим виды и особенности запросов пользователей, исходя из их частоты использования. Ну, и немного затронем вопрос, как нужно осуществлять продвижение.
Какие проблемы встают перед поисковиками
Первая и основная проблема, которая встает перед любым алгоритмом, это постоянно растущий размер индексной базы. Ее нужно где-то хранить, а в связи с тем, что размер коллекций постоянно растет, то и места для ее хранения требует все больше и больше. Проблема эта будет стоять перед Яндексом и Google всегда и решать ее можно только за счет увеличения количества серверов в дата-центрах.
Яндекс использует для хранения, на данный момент, уже около десятка дата-центров по несколько тысяч серверов в каждом. При этом он до недавнего времени индексировал только русскоязычный интернет и лишь сейчас выходит на мировой уровень и начинает проявлять интерес к документам на других языках.
Что же говорить о Google, который сейчас занимает одну из лидирующих позиций по сборке компьютеров, в то время как все эти компьютеры идут исключительно на его личные нужды (их используют в дата-центрах для хранения индексной базы).
Второй основной проблемой, стоящей перед поисковиками, является борьба с дубликатами в выдаче. Зачем это нужно? Им просто не хочется тратить понапрасну такое дорогостоящее место для хранения базы. Ведь если выкинуть из нее все дубликаты, то выдача от этого не ухудшится, а вот место, требуемое для хранения, уменьшится, позволив сэкономить немалые средства.
Поэтому Гугл с Яндексом будут вести отчаянную борьбу за искоренение дубликатов. Борются с этим злом они как с помощью их удаления из выдачи, так и превентивными мерами, предписывающими вебмастерам самим бороться с дублирование контента на своих собственных сайтах.
Если вебмастера будут игнорировать это требование поисковых систем, то к их проектам, возможно, будут применены различные санкции в виде наложения фильтров, вылета страниц ресурса из индекса и прочих репрессивных действий. И это можно понять, ибо они защищают свой кошелек (святое для буржуев).
Еще одной проблемой, с которой довольно успешно борются современные гиганты поиска — это спам. Он попадает в выдачу при использовании вебмастерами черных методов оптимизации. Те же самые дорвеи, которые попадают в топ по каким-либо запросам, а при переходе на них пользователя, его перекидывают на совершенно другой ресурс.
Это может быть клоакинг, который заключается в предоставлении разной информации для поисковой системы и для пользователя, перешедшего из выдачи.
Со всеми этими черными методами оптимизации (черное SEO) алгоритмы довольно успешно борются. Те же дорвеи долго не живут, но все же до окончательной победы еще очень далеко, ибо черное СЕО приносит не малый доход владельцам дорвеев и других хитро-оптимизированных ресурсов, а это значит, что они будут изыскивать все новые возможности утереть нос Google и Яндексу.
Так же стоит задача не только хранения постоянно расширяющейся индексной базы, но и проблема ее обновления, для того, чтобы она соответствовала реальной действительности. Нужно не только индексировать новые документы в сети, но и обновлять индексы уже ранее проиндексированных.
Ну, и последняя из глобальных проблем — это понять, что хочет увидеть в результатах поиска пользователь, вводя тот или иной запрос (я уже писал тут, как правильно искать в Google, а здесь, как искать в Яндексе, но даже эти знания не всегда могут помочь).
Понимание намерений пользователя позволит сформировать наиболее подходящую для этого случая выдачу, тем самым удовлетворив запросы пользователя. А удовлетворенный пользователь опять вернется к этому поисковику, т.к. он хорошо понимает, что тот хотел получить в ответ на свой вопрос (хотя он и сам до конца этого не понимал).
Одним из способов, позволяющих конкретизировать запрос пользователя (который реализован в Яндексе и Google), являются всем известные подсказки, которые появляются под строкой поиска в виде выпадающего списка.
Пользователь ввел какое-либо слово в строке, а алгоритм подбрасывает ему наиболее часто встречающиеся варианты вопросов с этим словом. Таким образом поисковики уточняют, что же именно хотел увидеть в ответ пользователь, вводя это слово.
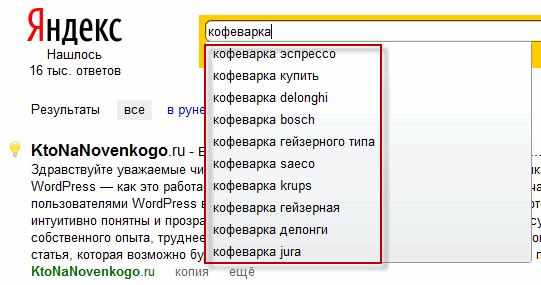
При вводе запроса с грамматическими ошибками, Яндекс покажет вам выдачу с ошибкой, но при этом предположит, что вы все же ошиблись и, возможно, захотите увидеть результаты по грамматически правильно составленному запросу. Для этого пользователю нужно будет только щелкнуть по исправленному варианту написания:
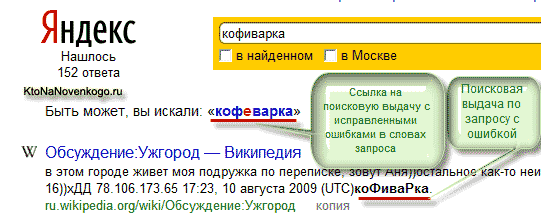
P.S. Сейчас все в точности до наоборот — неправильное написание исправляется автоматически, а чтобы увидеть результаты по вопросу с ошибкой, то придется щелкнуть по специальной ссылке.
Конечно же, идеальным вариантом, на мой взгляд, была возможность пользователю задать область поиска по введенному им вопросу. Что я имею в виду?
Например, когда вы ищите по названию какой-либо модели сотового телефона, то в зависимости от того, на какой стадии выбора продукта вы находитесь, вы захотите увидеть в ответах либо конкретные предложения о продаже, либо материалы, рассказывающие о преимуществах и недостатках данной модели.
Для уточнения своего желания вы, конечно же, можете использовать дополнительные слова, но как бы было здорово иметь возможность поставить галочку в полях «Коммерческий» или «Не коммерческий». И все, этого было бы достаточно для фильтрации того, что вам в данный момент не нужно.
Но это, как я понимаю, либо довольно сложно реализовать, либо имеются какие-либо шкурные интересы у поисковых систем этого не делать. Говорят, что у одной из них когда-то было что-то подобное реализовано, но потом все скурвилось.
Виды ключевых слов в зависимости от их частотности — ВЧ, СЧ и НЧ
Запросы пользователей можно разделить на три группы по частоте их повторения в течении одного месяца. Естественно, что существуют популярные вопросы, которые очень часто используют пользователи при поиске, есть которые используются чуть менее часто и есть вопросы, которые задаются Яндексу или Гуглу крайне редко.
В связи с этим принято относить их к определенной группе:
Высокочастотные запросы (ВЧ) — которые вводят пользователи более десяти тысяч раз в месяц. Продвинуться в топ (первые десять позиций, как правило, делят между собой львиную долю пользователей, набравших этот запрос) по ним очень сложно (я бы даже сказал, что неимоверно сложно) и дорого (несколько десятков тысяч долларов в месяц не предельная цена для продвижения по конкурентным ВЧ), но зато, если вам это удастся, то получите очень большой приток посетителей на ваш ресурс.
И, как результат, повышение уровня продаж. Я говорю продаж, потому что продвигаться по ВЧ будут именно коммерческие проекты, способные платить за это серьезные деньги и которые способны затем отбить их за счет повышения уровня продаж, после попадания ресурса в топ по этому ВЧ.
Что примечательно, тенденция развития современного интернета такова, что процент ВЧ в общей массе поисковых запросов неуклонно снижается. Сейчас он составляет всего лишь несколько процентов от всей массы. Раньше ВЧ имели гораздо больший процент, но сейчас рулят низкочастотные запросы (сильно уточненные ВЧ), о которых речь пойдет чуть ниже.
- Среднечастотные запросы (СЧ) — которые вводят пользователи от тысячи до десяти тысяч раз в месяц. Продвижение по СЧ похоже на продвижение по ВЧ, разве только, что бюджет здесь можно закладывать поскромнее, но и отдача от попадания в топ будет ниже.
Низкочастотные ключи (НЧ) — которые вводят пользователи менее тысячи раз в месяц. На данный момент НЧ забирают на себя львиную долю поискового трафика. Связано это с тем, что НЧ, как правило, состоят из нескольких слов, а тенденция развития интернета, и поисковиков в частности, сейчас заключается в том, что увеличивается число слов в запросах пользователей.
Скажем, если десять лет назад среднее количество слов, вводимое пользователем в поисковую строку, было чуть более одного слова, то сейчас средний запрос состоит почти из трех слов. ВЧ более односложные и их доля в поисковом трафике снижается, а многосложные низкочастотники и сверхнизкочастотники забирают на себя около трех четвертей от всего количества.
Еще одной немаловажной особенность НЧ является то, что по ним можно продвинуться и попасть в топ не используя вообще внешнюю поисковую оптимизацию (покупку ссылок, например). Для продвижения по ним будет достаточно одной лишь грамотной внутренней оптимизации страницы (подробные статьи вы можете найти по этой теме тут и здесь про технический аудит).
Как правило, хорошо оптимизированные внутренние страницы сайта, даже без проставления на них обратных ссылок с нужными анкорами, способны попасть в топ по НЧ. Хотя, для повышения вероятности этого события несколько обратных ссылочек не помешает проставить, но этого можно и не делать.
Стратегия продвижения по низкочастотным ключам
Удел такого блога, как мой (https://ktonanovenkogo.ru/), это НЧ ключи. Стратегия продвижения по ним при этом может быть примерно следующей: каждая отдельная статья затачивается под определенные ключевые слова, которые присутствуют в заголовке страницы TITLE, в промежуточных заголовках статьи, а так же слегка выделяются тегами STRONG или EM в тексте.
Так же, путем использования в тексте ключевых слов достигается определенная тошнота страницы именно по ним, а не по каким либо другим паразитным и мешающим продвижению словам. После этого статья должна сама пробиться в топ по некоторым НЧ, в которых будут присутствовать выбранные ключи.
Так как доля НЧ велика, то таким образом можно получить очень приличный трафик с поисковых систем (у меня он на данный момент составляет чуть менее полутора тысяч посетителей в сутки).
Как учитывается морфология языка в работе поисковых систем
Когда, например, Яндекс, осуществляет индексацию какой-либо странички в интернете, то кроме того, что из оригинального документа создается так называемый обратный индекс, осуществляется приведение всех используемых в нем слов к словарной форме (например, для существительных — именительный падеж единственного числа).
Для того, чтобы это можно было делать в автоматическом режиме, поисковикам необходимо располагать всеобъемлющими словарями, в частности, русского языка.
Используемое в индексируемом документе слово автоматически отыскивается в таком толковом словаре, и вместо оригинала в обратный индекс записывается его словарная форма. Напомню вам, что алгоритмы ищут не по реальным вебстраницам, которые находятся в интернете, а по созданным на их основе обратным индексам, которые создаются в момент индексации этих страниц и обновляются по мере необходимости.
Еще одной немаловажной особенностью формирования обратных индексов является то, что в них не попадают служебные символы (точки, запятые, двоеточия, вопросительные знаки, пробелы и т.д.). Эти символы не способны улучшить качество поиска и повысить релевантность поисковых выдач, а значит их не зачем учитывать.
Так что если у вас проблемы с орфографией, то Яндекс и Гугл об этом даже не будут догадываться, хотя посетители вашего ресурса это, конечно же, заметят.
В связи с чем становится ясно, что не так важно, какие именно знаки препинания или же служебные символы (например, такой — |) вы используете в заголовках страниц (TITLE) или же в обратных ссылках. Но тут тоже есть свои нюансы и хитрости.
Стоп-слова — всякие там предлоги, местоимения, междометия, частицы, союзы, которые сами по себе не несут какой-либо смысловой нагрузки. На данный момент они являются полноценными участниками выдачи, хотя до определенного времени в целях экономии места на серверах, поисковики их не индексировали.
Мы уже говорили, что в обратный индекс попадает словарная только форма. Но при этом учитывается и изначальная форма слова, т.к. на данный момент выдача будет разная для разных форм (падежа, множественного или единственного числа и т.д).
Еще пару лет назад Яндекс не делал разницы (падеж, число и т.д.) в поисковом запросе, а сейчас выдача по запросу с ключевым словом в единственном и множественном числе будет разная.
Комментарии и отзывы (30)
Спасибо за Вашу работу. Часто в Ваших статьях нахожу для себя очень полезные вещи. И эта статья не исключения. Хороших Вам заработков и продолжайте в том же духе.
Мне как очень начинающему блоггеру надо еще многому учиться. Спасибо, что есть такой блог, как Ваш, здесь много полезного для меня.
Добрый день.
Пишу данный вопрос потому как ответ нужно получить как можно быстрее. Прошу не гневаться что тема не соответствует.
Можно ли надеяться на повышение колличества посетителей на сайт, если купить ещё одно доменное имя, которое будет в автоматическом режиме перебрасывать зашедшего на основное доменное имя. Если рассуждать логически — имея два доменных имени можно оставлять ссылку на каждое из этих доменных имён с других ресурсов, получая таким образом ДВЕ РАЗНЫЕ ССЫЛКИ с одного ресурса. Делать это ввиду того, что в интернете не так много мест где можно оставить полезную обратную ссылку. Очень жду ответа. Спасибо огромное за потенциальную помощь.
Евгений
Кроме этого негативное влияние на продвижение сайта может оказать заключение заголовков уровня H1 — H6 в Html теги ссылки (если у вас на странице со статьей заголовок является ссылкой на эту же самую страницу, то приложите все усилия, чтобы данную ссылку с заголовка убрать).
Дмитрий, как можно приложить усилия на то, что не знаешь как сделать.
Если будет время посмотрите к примеру хотя бы стр. http://uotika.ru/otika-blog/skazki-na-sajte
Если навести курсор на заголовок Сказки на сайте, то она по умолчанию заголовок является ссылкой на ту же страницу (саму себя)
При наведение курсора заголовок является ссылкой и написано — Постоянная ссылка на Сказки на сайте.
Дмитрий подскажите пож где у вас описано как это убрать — чтоб ссылкой не отображалось. Я уже «лазил» в админке в Редакторе, но с чего начинать не знаю.
И не знаете Дмитрий случайно, если заголовок — ссылка (он по умолчанию в вордпресе таким стаёт) и это есть плохо, для чего создатели движка так сделали?
Чтоб заголовок был ссылкой.
Случайно наткнулся на ваш сайт, теперь оторваться не могу 🙂 читаю, читаю и читаю...
Спасибо за толковые статьи, в кои-то веке попался ресурс где все толково написано.
Пост как всегда полезный, задал вопрос в посте, а он не отобразился. Куда то пропал.
Жалко
Андрей: пожалуйста и спасибо за пожелание.
Ira101160: пожалуйста.
Евгений: похоже, что вы говорите про продвижение зеркалами. Могу вам посоветовать почитать на эту тему публикацию известного специалиста и теоретика сферы продвижения — http://devaka.ru/articles/mirrors-optimization.
Виктор: для чего разработчики WordPress это делают не знаю, но для того, чтобы убрать ссылку с заголовка статьи на саму себя, вам нужно будет открыть на редактирование файл single.php из папки с темой WordPress. В этом файле найдите строчку кода подобную этой:
<h3 class="title" id="post-<?php the_ID(); ?>"><a href="<?php echo get_permalink() ?>" rel="bookmark" title="Постоянная ссылка: <?php the_title(); ?>"> <?php the_title(); ?> </a></h3>Нужно убрать из этого кода Html теги ссылки страницы саму на себя, ну и, кстати, неплохо бы было заменить заголовки уровня H3 на H1 (или H2). В результате вместо упомянутой чуть выше строчки кода у вас должно получиться нечто подобное:
<h1> <?php the_title(); ?> </h1>Для Joomla, кстати, все можно сделать прямо из админки, что безусловно удобно.
Антон: пожалуйста.
Виктор: комментарии публикуются только после ручной модерации, поэтому и возникает характерная задержка, извините.
Дмитрий, если комментарии добавляются после ручной модерации, то было бы неплохо, чтобы после того, как нажимаешь кнопку «Добавить», появлялось сообщение «Спасибо, Ваш комментарий принят. Он будет опубликован после проверки модератором». Или хотя бы под кнопкой «Добавить» напишите, что комментарии добавляются после ручной модерации. А то нажимаешь кнопку, а ничего не происходит. Не понятно то ли баг, то ли что там не так).
Спасибо большое Дмитрий, но почему то убрать строки кода — ни к чему не привели.
Притом еще в index.php тоже нашёл похожие строки, их тоже снёс — бесполезно.
Название страницы отображается сылкой.
Хотя все изменения я сохранял.
Ну ладно, видно так и останется уже.
Вернул всё по старому.
Что интересно, что уже один раз подобное делал, где то в инете со скинами было как убрать сылку и что надо было снести. Не помогло. Думал что не так написали, но вы уже второй раз я читаю написали так же убрать надо, но не убралось.
Уже думал в кеше запомнил браузер, открывал другим, который стр. не видел эти, сылка была , есть и уже будет на веки вечные.
Виктор: возможно, что вы вносите изменения в файлы не той темы WordPress, которая у вас в данный момент используется или же кеш в WordPress у вас не дает увидеть обновления. В index.php убирать ссылки с заголовков не надо, ибо они улучшают юзабилити и при этом не ухудшают поисковую оптимизацию.
Полезная информация. Я недавно опубликовал запись о Написании СЕО оптимизированной статьи — http://www.harum.ru/?p=150. Многое из того, что указано в Вашей статье следует применять к пунктам, по которым надо писать СЕО статью.
Дмитрий говорит, что:
Да — тема вордпрес стоит ещё одна, та что была по умолчанию.
Это исключить легко — её просто удалю. Она точно уже будет не нужна.
А вот насчёт кэша вордпресса — я даже не то что не думал, не знал о нём.
Запросто он может не даёт увидить (я думал сначала что кеш браузера не даёт, но я писал пробовал другой браузер и чистил кеш)
Дмитрий,раз вы отвечаете, то подскажите еще — а кэш вордпресса можно почистить?
И насколько это трудно?
Просто я думаю наверно из за него. Я еще удивился, single.php -я скопировал на всякий случай, потом стал с него удалять то что вы написали.
Изменений не было. В конце эксперемента я вообще удалил single.php ( осталось пустое поле ( я копию ведь сохранил специально)
И никаких изменений — главное заголовок страницы должен был пропасть — а отображалось всё так же.
Потом восстановил всё как было. То что кэш изменения не показывает вордпресса я не мог догадаться даже.
Виктор говорит, что:
В общем шаблон кот был по умолчанию удалил. Остался один тот на котором сайт.
single.php -Убираю код кот вы писали — без изменений, сношу все там, чистый голый лист, сохраняю изменения перезагружаю страницу в браузере — все по старому и название страницы есть и как ссылка. Значит кеш вордпресса не даёт показать изменения.
Сейчас у гугла поспрашиваю, может где найду как кэш в вордпресе почистить.
Правда опять не знаю — или это можно делать, или нет.
Кто-нибудь знает, как в Joomla убрать ссылки с заголовков, но чтобы в блоге категории заголовки остались со ссылками?
Большое спасибо! Делаю Свой сайт. Ваша информация очень полезна, просто то, что доктор прописал!
Добрый день!
Недавно открыл для себя ваш блог, читая книгу «Поисковая оптимизация от А до Я». Хочу сказать вам огромное спасибо за ту информацию, которой вы делитесь.
Так как мы с женой недавно открыли собственный проект, хотел поинтересоваться по поводу тега H1 и местоположения его в теле страницы. Например сеопульт при анализе ключевых запросов говорит что он расположен слишком близко к началу страницы. И если вас не затруднит возможно дадите несколько рекомендаций по ошибкам которых конечно же масса на нашем проекте, но если возможно хотя бы парочку основных. Адрес нашей странички: http://eooi.ru/
На днях почитывал блог optimizatorsha.ru и посмотрев код страницы увидел ощибки в направлении оптимизации (судя по данной статье). Так вот у неё ,вроде бы на всех страницах ,наблюдается сочетание «a href» и «H1» (и учитывая таблицу ТОПЭксперт это должно влиять неблагоприятно) , но ето абсолютно не мешает быть этому блогу в топе на первых местах по НЧ запросам. Насколько влияют отрицательные факторы приведённые в таблице, и могут ли они выбить из топ10 по НЧ запросам?
Дмитрий а вы что-нибудь знаете о влиянии пересечения тегов с тегом ??
тегов H1-H6 c тегом big то есть хотел сказать
это самые правильные шаги в продвижении...как говорят в рекламе росгосТРАХа «все правильно сделал» — следуйте советам и не прогадаете...
Благодаря вашим советам я уверенно продвигаю свой онлайн журнал http://adosug.com и хотя до этого писал, что SEO это чепуха, то теперь пришлось изменить свое мнение в обратную сторону. Но статьи я сам не пишу, а их покупаю. Поэтому ключевые слова беру из уже готовых статей и прописываю их в мета-тегах. Писать самому, это отнимает столько времени и труда, что просто жуть.
Ответ предыдущему комментатору: если хочешь сделать хорошее дело, сделай его сам.
Дмитрий, у Вас в название блога, а название статьи в . У себя на сайте я сделал в названия статей, а название сайта без тегов заголовка. Как считаете, если сделаю так же как у Вас, то будут ли какие то улучшения в ранжировании?
Дмитрий, у Вас в
<h1>название блога, а название статьи в
<h2>. У себя на сайте я сделал в
<h1>названия статей, а название сайта без тегов заголовка. Как считаете, если сделаю так же как у Вас, то будут ли какие то улучшения в ранжировании?
Не подскажите где вы получаете эту статистику по «Влияние связок HTML на вес ключевого слова.» и т.д. Возможно вы говорили об этом на сайте, но я не смогла найти.
Заранее спасибо
Спасибо, хорошая инфа.
А меня интересует следующий вопрос: к примеру, мое ключевое слово «бизнес» (к примеру, это не мое слово), если после слова я ставлю двоеточие, то оно уже не является ключом для поисковиков? Например: «Бизнес: основные моменты»?
Спасибо, хорошая статья. Не знала насколько html теги влияют на вес ключевых слов, теперь буду иметь в виду. А что бы посчитать число прямых вхождений весомых в тексте инструмент нашла бесплатный — http://www.apollo-8.ru/analiz-saita/keygeneratortext, правда только по одному слову вхождения, а не фразы, но зато частоту слов считает. Помогает избежать переспама
что-то какая-то неувязочка. Вот у вас на блоге title очень большие, а плагин all seo pack пишет, что поисковики не воспринимают больше 60 символов. Кому верить???
Спасибо за полезную и интересную информацию. Продвижение сайтов и оптимизация дает возможность повысить их ранжирование в поисковиках, а, следовательно, увеличить посещаемость. Наращивание количества посещений обязательно приводит к увеличению продаж, расширению клиентской базы и возрастанию доходов. Раскрученный сайт – это работающий на вас ресурс, а не просто страничка в интернете: topmayseo.ru
Давно хочу спросить! А влияет ли как-нибудь вписывание ключевого запроса в начале или коце первого абзаца статьи? 😉
Ваш комментарий или отзыв