Как проверить позиции сайта и собрать семантическое ядро с помощью XMLRiver, Топвизора, KeyAssort и др

Проверка позиций сайта и сбор семядра с помощью XMLRiver (парсера Яндекса и Google)
Уж не знаю, почему, но моя муза, наверное, улетела отдыхать на моря. Авторское вдохновение потихоньку иссякло, и я не могу нарыть тем для новых материалов. Поэтому пришло время потрусить поисковики. Но парсинг выдачи поисковых систем – дело заковыристое. Приходится с прокси мучиться или десятки капч решать… На что товарищи по цеху говорят, что я отстал от времени и предлагают догнать прогресс с помощью XMLRiver.
В чем сложность парсинга в Яндексе и Гугле
Google и другие поисковые системы всячески борются за повышение релевантности выдачи. Но тогда почему сбор семантического ядра, его оптимизация или снятие позиций сайта превращается для вебмастера в танец с бубном. Причем такие пляски продолжаются уже не первый год. И я, видимо, уже привык осуществлять парсинг Google под свой танец – обходя блокировки поисковиков с помощью прокси и антикапч.
Но, видимо, практикуемый вашим покорным слугой способ давно устарел. О чем не раз уже намекали мои сотоварищи. И вот представился случай постичь более прогрессивный метод парсинга – с помощью XMLRiver.
Как в этом помогает XMLRiver
Парсер поисковой выдачи Гугла и Яндекса позволяет осуществлять выборку данных из SERP в формате XML. Его механизм схож с принципом работы Яндекс.XML. Но в отличие от него XMLRiver предоставляет прямую выдачу и как следствие, расширенный набор настроек, позволяющих сегментировать получаемые данные по множеству параметров.
Сервис можно использовать для:
- Проверки наличия веб-страниц сайта в поисковом индексе.
- Снятия позиций.
- Глубокого анализа поисковой выдачи по заданным запросам.
- Сбора семантического ядра.
- Сбора данных для кластеризации СЯ.
Его преимущества по сравнению с конкурентными решениями:
- Возможность парсинга не только органических результатов поиска, но и отдельных блоков выдачи (колдунщики, быстрые ответы и т.д.), а также Google News, Google Images и Google Shopping.
- Анализ рекламных объявлений конкурентов.
- Скорость сбора данных по Google превышает 15 тысяч запросов в час.
- Сбор данных с сервиса можно осуществлять с помощью бесплатной программы XMLRiver.Parser с последующей выгрузкой данных в CSV формате.
Нативный API сервиса без проблем интегрируется с популярным специализированным ПО и веб-приложениями, осуществляющими парсинг выдачи основных поисковых систем.

*при клике по картинке она откроется в полный размер в новом окне
Схема работы с XMLRiver:
- Регистрируемся.
- Пополняем счет.
- Настраиваем параметры гео и необходимые опции.
- Копируем URL для запросов.
- Вставляем в используемую программу ключ API и осуществляем беспроблемный (без капч и блокировок) сбор данных из результатов поиска.
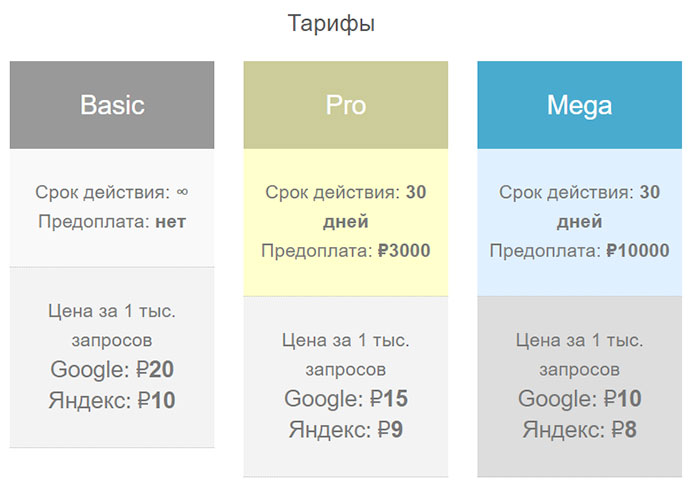
Услуги сервиса предоставляются в виде подписок с оплатой за каждый запрос. Стоимость одного кило запросов к Google стартует от 10 руб., к Яндексу – от 8 руб.
А теперь проверим, насколько рассматриваемый сервис удобен и полезен для решения насущных проблем вебмастера…
Как начать парсить выдачу Google и Яндекса с помощью XMLRiver
Быстрый и беспроблемный парсинг Гугла мне нужен, чтобы найти тематические форумы для проставления ссылок, нынче это называется крауд-маркетинг. Для этого в связке с XMLRiver будет трудиться программа XMLRiver.Parser.
Что да как делаем (пошагово):
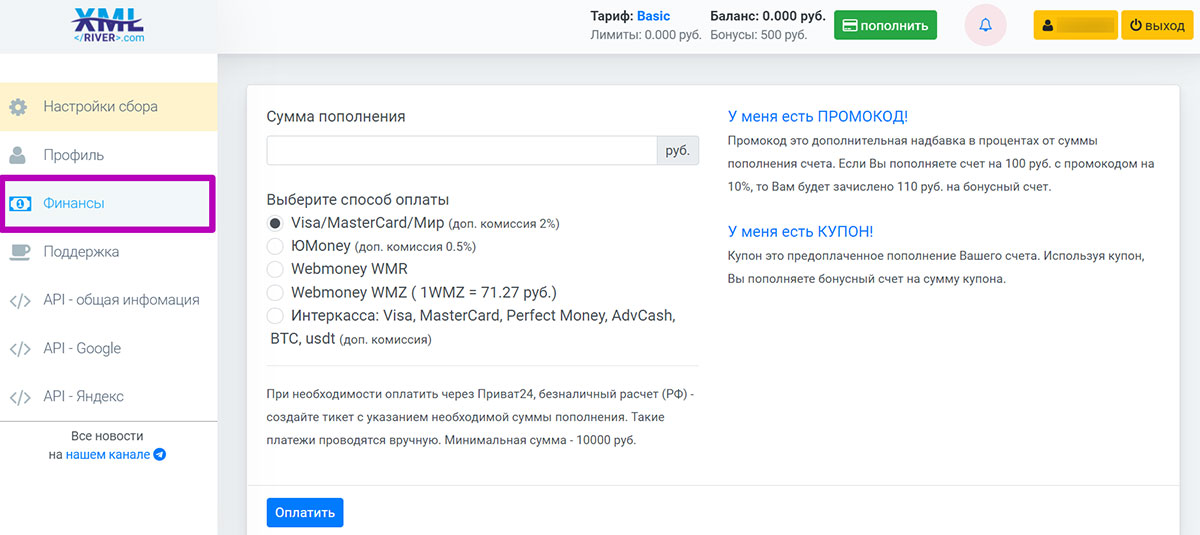
- Регистрируемся на сайте.
- В личном кабинете пользователя сервиса переходим в раздел «Финансы» и пополняем счет любым удобным для нас способом. Даже можно и криптовалютой.
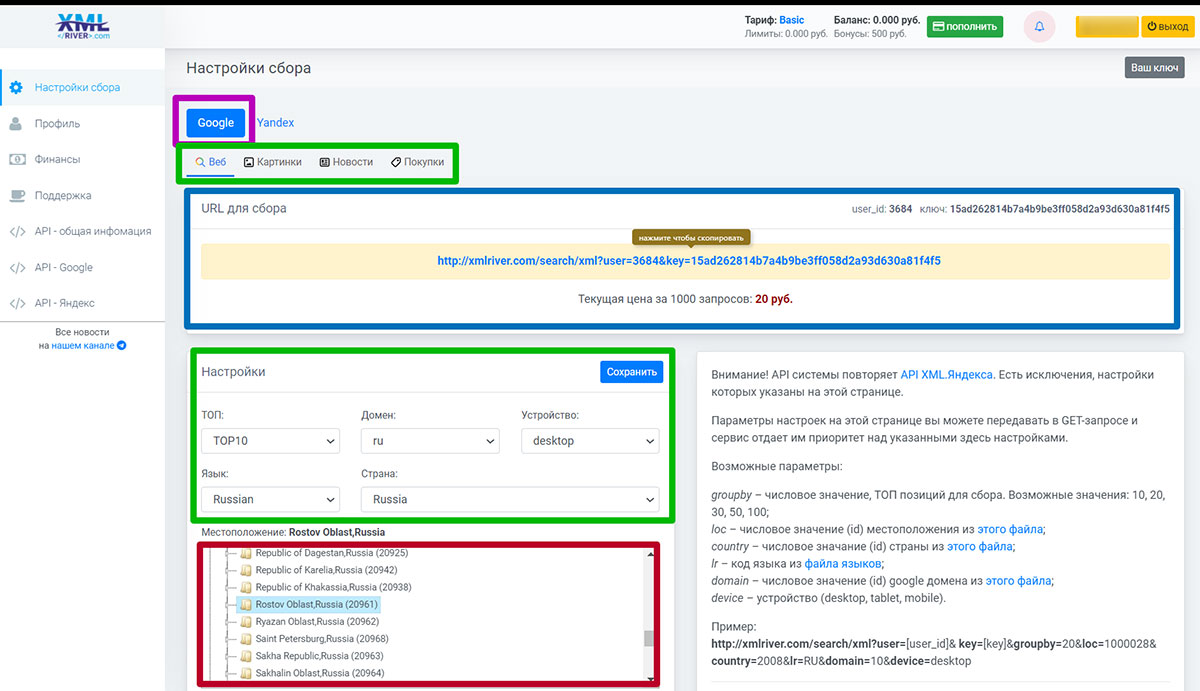
*при клике по картинке она откроется в полный размер в новом окне - На вкладке «Настройки сбора» выбираем поисковик, тип выдачи (органика, поиск по картинкам, новости или покупки). В нашем случае это будет Google органика.
*при клике по картинке она откроется в полный размер в новом окне - Перед тем как парсить выдачу Google, в настройках устанавливаем охват выборки по ТОПу, доменной зоне, типу устройства, языку и гео. Ставим топ20, т.к. форумы, которые находятся дальше, ранжируются плохо и нам не нужны.
- В дополнительных параметрах указываем расширенные форматы выдачи и блоки SERP, которые нужно анализировать. А также (если нужно) активируем подсветку ключевых слов в выборке и задаем календарный период. Для нашей задачи всё это не надо.
- Теперь осталось скопировать значение URL-адреса для сбора (см. скриншот выше) и вставить его в программу.
*при клике по картинке она откроется в полный размер в новом окне
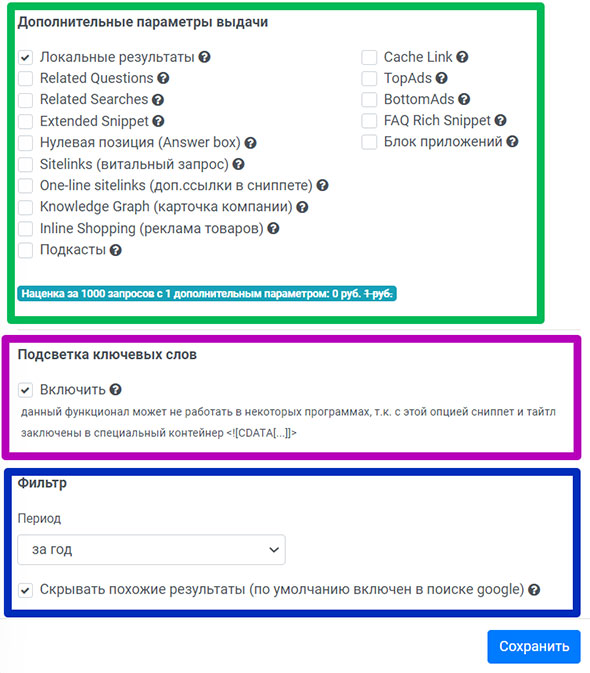
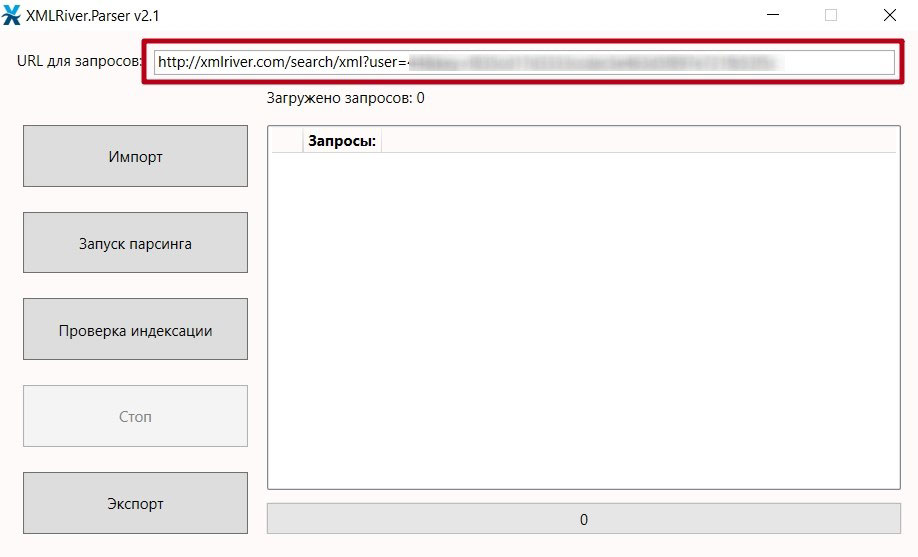
Останавливаемся, чтобы проанализировать содеянное. Мы настроили параметры XMLRiver, которые позволят парсить выдачу Гугла в нужном направлении. И затем легко и быстро подключили сервис к сторонней программе.
Что дальше:
Нам нужны ключевые слова, по которым ранжируется наша страница, к каждому из которых мы добавим следующие конструкции:
- inurl:showthread
- inurl:viewtopic
- inurl:forum
- inurl:showtopic
Сделать это проще всего в notepad++. Копируем список фраз в 4 разных документа (у нас 4 конструкции, которые надо добавить к фразам) и делаем замену, используя регулярное выражение (обратите внимание на режим поиска внизу окна):
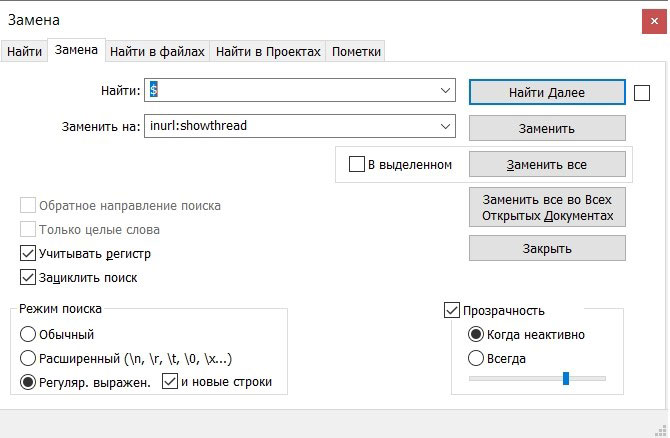
В результате данной замены получаем такой список:
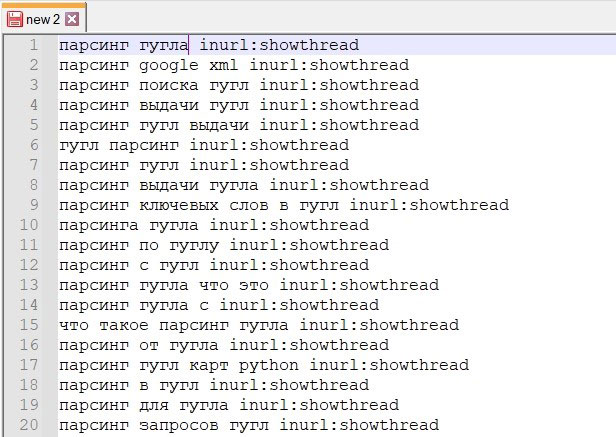
Проделываем тоже самое для трёх других конструкций и объединяем 3 списка. А дальше самое интересное – импортируем окончательный список фраз в XMLRiver.Parser и запускаем сбор данных:
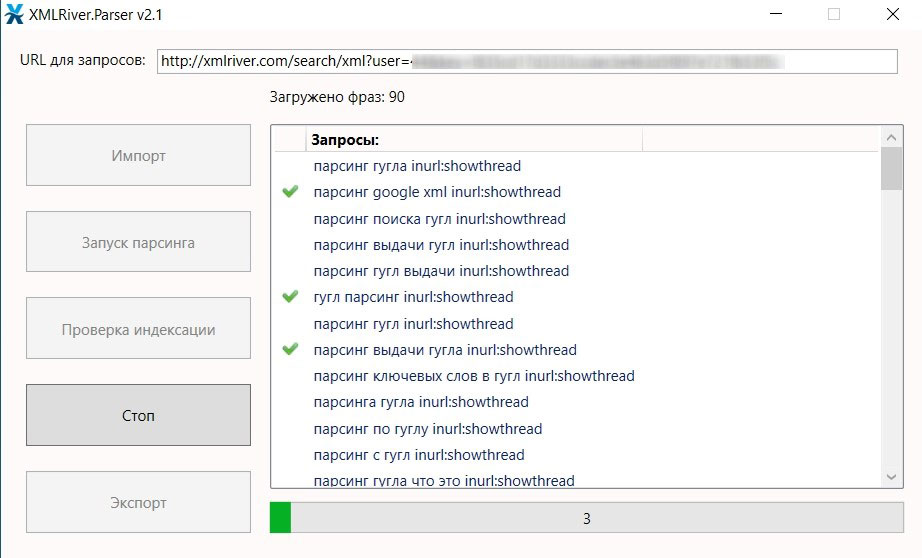
*при клике по картинке она откроется в полный размер в новом окне
Дальше экспортируем полученные результаты и получаем самый сок, лучшие по мнению Google топики на форумах, где обсуждают искомую тему:

*при клике по картинке она откроется в полный размер в новом окне
Впечатления от работы приложения, интегрированного с XMLRiver:
Буквально за каких-то пять минут программа уже собрала из поисковой выдачи тысячи топов за очень скромный бюджет.
Насколько хорош XMLRiver?
По сравнению с более старыми способами XMLRiver позволяет намного быстреепарсить SERP в Гугл. Например, процесс сбора семантики занимает не несколько часов, а в среднем 20-30 мин. И при этом не нужно заморачиваться с заполнением проверочных капч от поисковиков или с подключением «антикапчевых» сервисов.
Конечно, для повышения эффективности анализа выдачи можно использовать прокси. Но с данным инструментом тоже не все так гладко. Ведь найти поставщика качественных proxy очень сложно. К тому же даже самые надежные айпишники обладают одним негативным свойством – не вовремя вылетать, сбоить и в разы замедлять скорость интернет-соединения. В результате процесс парсинга превращается в процедуру длиною в жизнь.
Да и стоимость использования антикапч и прокси тоже влетает вебмастеру в копеечку, что сопоставимо с оплатой услуг XMLRiver.
Тогда как парсить Google быстро, выгодно и без головной боли? Конечно же, с помощью XMLRiver. При тестировании возможностей сервиса я выделил следующие его преимущества:
- Простота интеграции – с ней справится даже новичок. Для интеграции инструмента со сторонней программой достаточно лишь вставить один URL для запросов.
- Большое количество настроек на борту – они позволяют указать гео и блоки выдачи, которые нужно парсить (при условии, что программа отображает дополнительные блоки выдачи).
- Обеспечивает бесперебойный режим работы.
- Охватывает все типы выдач Google – поиск по картинкам, товары, новости и обычный SERP.
- Низкая стоимость.
Горько это признавать, но я действительно отстал в своем профессиональном развитии. Прокси и антикапчи – уже прошлый век. Сегодня все продвинутые SEO-специалисты и вебмастера парсят выдачу с помощью XMLRiver. Ведь это удобней, эффективней и выгоднее.
Топвизор — мониторинг и проверка позиций сайта
Хочу сегодня продолжить свои изыскания в области определения и дальнейшей периодической проверки позиций, занимаемых моим сайтом в поисковой выдаче популярных в рунете поисковиков. Полезно всегда быть в курсе и знать по каким запросам продвижение идет хорошо, а по каким пробуксовывает или даже откатывается назад, чтобы вовремя понять причину и принять меры.
Что примечательно, наш сегодняшний герой, имя которому Топвизор, умеет не только снимать позиции, но и предлагает собрать для вас семантическое ядро, т.е. помогает подобрать те самые ключевые слова (будущие поисковые запросы), по которым вы и будете продвигаться в дальнейшем.
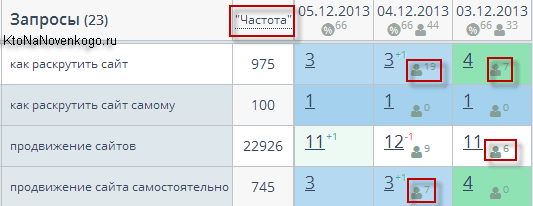
Кроме отображения ежедневной динамики изменения позиций вашего сайта (в выдаче Гугла, Яндекса и Майл.ру) и частотности этих запросов (точной или общей, по вашему усмотрению) Топвизор может показывать и тот трафик, что вы получили по каждому конкретному запросу в тот или иной день. Узнайте подробную информацию про Топвизор: цены, возможности, сравнение с конкурентами.
Есть и цветовая дифференциация в сводной таблице, которая визуально помогает оценить, насколько все хорошо и какие общие тенденции наблюдаются. Кроме этого недавно у них появилась возможность снимать позиции в Яндексе (а вскоре и в Google) бесплатно. Каким образом, спросите вы? Ну, позволю себе создать интригу и сказать, что об этом вы прочитаете в продолжении данной публикации.
Возможности онлайн сервиса TopVizor
Думаю, что прежде, чем приступать к детальному описанию всех возможностей данного онлайн сервиса, следует вкратце описать все имеющиеся на данные момент в нем особенности. Что примечательно, новый функционал появляется у них с завидной регулярность, что не может не радовать.
- Запросы, по которым вы хотите отслеживать позиции, можно будет загрузить вручную (копипастом или из файла), а можно будет их подобрать прямо в окне Топвизора, причем стоить это будет сущие копейки. Другими словами, не отходя от кассы вы сможете набросать семантическое ядро либо для всего проекта, либо для отдельных статей.
При этом вам нужно лишь указать начальную фразу (основную), для которой в Вордстате будут скопированы обе колонки, а там же можно будет вытащить ключевые слова содержащие эту фразу из поисковых подсказок Яндекса, Google и Майл.ру. Получите целую гору ключевиков, которую затем просеете с помощью двух расположенных ниже пунктов. - По всем вводимым вами запросам можно проверить их частотность по Яндекс Вордстату, причем доступна не только общая частотность, но и с отсеиванием пустышек (точная). Благодаря этому вы сможете выкинуть из собираемого семантического ядра все бесперспективные ключевые слова.
- Совершенно бесплатно вместе с частотностью будет определена и цена клика в Яндекс Директе, которая обычно назначается для этого запроса.
Зачем это нужно? А чтобы понять, какие ключевые слова являются сильно конкурентными и, возможно, исключить их из семядра (во всяком случае, для своего информационного ресурса я именно так и делаю). - В Топвизоре ожно настроить съем позиций по запросу (вручную), либо автоматически (ежедневно в назначенный вами час или после апа Яндекса). На первых порах существования ресурса или в период его бурного продвижения самое то будет ежедневно мониторить позиции, а затем можно уже перейти на режим «от апа к апу» или же вообще «от случая к случаю».
- Количество проверяемых запросов в ваших проектах никак не регламентируется, ибо плата взимается поштучно (одна проверка по одному ключевому слову в одной поисковой системе — пять копеек). Причем, при внесении на счет суммы, например, больше десяти тысяч рублей вы получить еще пять тысяч (или больше) в качестве бонуса и при большом количестве запросов стоимость их проверки может существенно снизиться (оптом дешевле).
- Для пробы пера вам на баланс сразу после регистрации зачисляется десяток рублей, что вполне достаточного для проверки позиций по двум сотням запросам или по чуть меньшему количеству, если вы еще решите сборку семядра потестить.
- Если вы захотите поделиться своими лимитами в Яндекс XML с Топвизором, то получите возможность ежедневно проверять определенное количество запросов бесплатно. Например, для моего блога это число будет равно 390, а о том, как узнать сколько будет отмерено халявки именно вашему сайту, читайте чуть ниже по тексту.
Имеется возможность открыть доступ Топвизору к данным вашего аккаунта в Яндекс Метрике и Вебмастере, чтобы видеть, сколько именно посетителей пришло к вам по данному конкретному поисковому запросу (очень наглядно и может заставить задуматься о настройке более привлекательного сниппета или тайтла).
При этом еще и в сводной статистике по вашему сайту сможете видеть число посетителей пришедших с трех основных поисковых систем рунета за последние сутки, отслеживать динамику изменения числа проиндексированных страниц и количества обратных ссылок ведущих на ваш ресурс.
- Если структура вашего сайта такова, что вы используете поддомены, то вовсе не обязательно будет создавать для каждого из них новый проект — достаточно поставить всего лишь одну галочку при добавлении основного домена.
- Сео конторам и фрилансерам может показаться удобной опция предоставления гостевого доступа к аккаунту в Топвизоре с довольно-таки гибкой системой настроек возможностей гостя. При необходимости можно даже полностью передать аккаунт в руки другому пользователю, достаточно только указать его Емайл в этом сервисе по онлайн проверке позиций и сборке семантического ядра.
- Ну и, кончено же, отчеты.
Их можно будет сформировать либо вручную на странице просмотра динамики позиций, либо настроить их автоматическую отправку на указанный Емайл еженедельно или же ежемесячно. - В Топвизоре действует реферальная программа с очень даже высоким процентом отдачи — 10% от сумм, потраченных привлеченными вами клиентов. У них уже имеются рекламные материалы в виде баннеров наиболее популярных размеров, выполненных в цветовой гамме основного сайта, что вполне логично.
Естественно, что прежде вам нужно будет зарегистрироваться, а потом достаточно кликнуть мышь по баннерочку нужного размера и его код автоматом упадет в ваш буфер обмена с уже зашитой в нем реферальной ссылкой. Лепота. - По всем произведенным в сервисе платным операциям ведется журнал, где можно увидеть отчет по каждой копеечке. Пополнить баланс можно традиционными Вебманями и Пайпалами, а через Робокассу всем остальным. Для индивидуальных предпринимателей, ООО и всех желающих будет возможен ввод сумм больших пяти тысяч рублей по безналу.



Регистрация в TopVizor, добавление сайта и настройка проекта
Ну, а теперь поговорим об этом поподробнее. Как театр начинается с вешалки, так и работа в онлайн сервисе — с регистрации. Для этой цели служит расположенная в верхней части окна главной страницы Топвизора кнопка «Регистрация».
Достаточно будет указать свой Емайл и вас автоматически авторизует в Топвизоре (пароль потом пришлют на указанный почтовый ящик).
При желании вход можно будет осуществить и без регистрации — с помощью аккаунта в одной из используемой вами соцсетей (сработает только в том же браузере, где вы залогинены в социальной сети).
Первое, что вы увидите после авторизации на topvisor.ru — это страницу с данными по вашим проектах, которых, собственно, пока еще нет. Зато будет иметь место 10 рублей на балансе, что позволит протестировать возможности данного сервиса.
Создадим же не мешкая свой первый проект в Топвизоре простым нажатием на имеющийся в левой верхней части окна плюсик. Вам будет предложено ввести доменное имя исследуемого сайта:
После этого вам незамедлительно предложат выбрать те поисковые системы (из трех возможных), в которых вы планируете снимать позиции для данного сайта. Извиняюсь, пока писал начало этого обзора, в интерфейсе Топвизора, кроме традиционных Яндекса, Гугла и Go.mail, появились в выпадающем списке межрегиональные Yandex.com и Google.com.
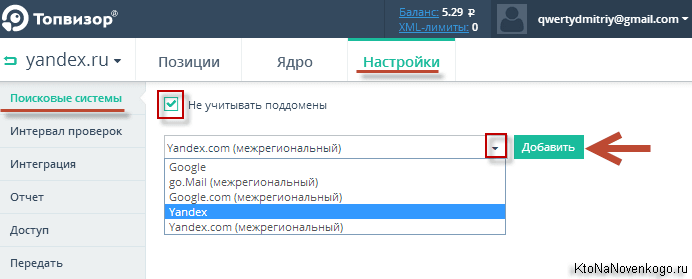
Чтобы добавить поисковик нужно будет воспользоваться расположенной справа кнопкой. Причем, если добавлять обычные Яндекс и Гугл, то для них еще потребуется выбрать регион, для которого потом и будут сниматься позиции. Регионов можно выбрать при необходимости несколько, но для каждого из них позиции будут сниматься за отдельную оплату.
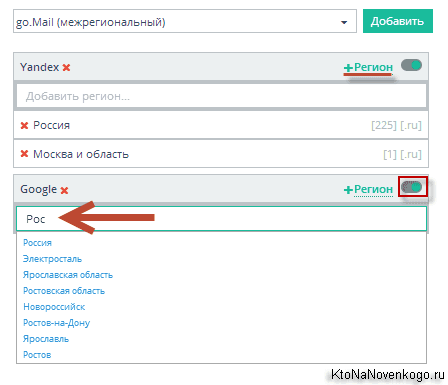
Как вы знаете, есть запросы геозависимые и нет (например, «доставка пиццы» и «поэзия Пушкина»). В первом случае все понятно, а вот во-втором нужно выбирать именно тот регион, в котором вы хотите посмотреть позиции по данному запросу, либо любой другой, т.к. если запрос геонезависимый, то выдача различаться не должна. Например, лично я для мониторинга таких проектов использую регион «Россия».
Красные крестики служат для удаления поисковой системы или ненужного региона, а переключатель справа — для временной отмены съема позиций по данному поисковику. У межрегиональных Go.mail, Yandex.com и Google.com региона выбирать не потребуется. Обратите внимание, что кнопки Сохранить нигде нет, ибо все применяется на лету, что достаточно необычно, но прикольно.
Да, еще хочу сказать, что именно здесь вы можете снять пресловутую галочку «Не учитывать поддомены», чтобы реализовать упомянутую чуть выше по тексту возможность (не добавлять все поддомены по отдельности).
И еще обратите внимание, что для поисковой машины Google имеется возможность задать язык интерфейса (поисковой выдачи):
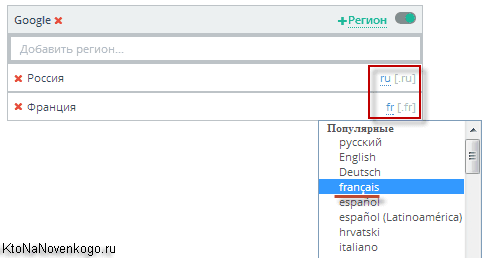
Зачем это нужно? Для проверки позиций в буржунете. Если я буду пробивать запрос на французском языке в регионе Париж с русским интерфейсом и французским, то выдача будет отличаться. Если нас интересует выдача для коренного жителя, живущего во Франции, а не русского туриста, находящегося в Париже, то нам надо выбирать именно французский интерфейс (выдачу на этом языке).
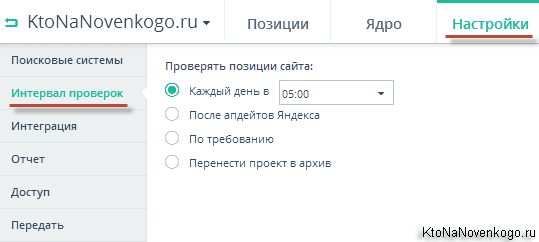
Давайте пробежимся также и по остальным настройкам в интерфейсе Топвизора, раз уж мы тут оказались волею судеб. Следующая вкладка называется «Интервалы проверок» и тут вы можете выбрать один из трех основных вариантов (ежедневное снятие позиций в нужный вам час, после апдейта Яндекса или же вы сами решите, что пришло время узнать правду), а так же можно вообще приостановить работу по данному проекту (перенести его в архив) в силу каких-то причин.
Далее у нас на очереди вкладка «Интеграция». Тут вы вольны будете настроить выгрузку статистики из Яндекс Метрики в Топвизор, ну и из Yandex Webmaster тоже можно получить некоторые данные. Если у вас оба этих сервиса завязаны на один аккаунт Яндекса, то подключив один из них, второй подключится автоматически.
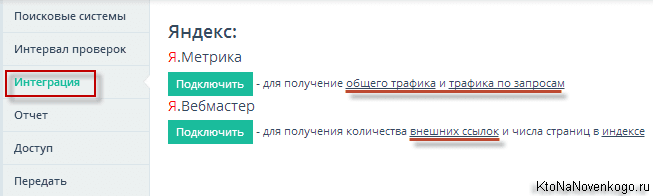
После интеграции будет отображаться номер вашего счетчика в Метрике, а также будет возможность принудительно обновить данные, подгружаемые с этих сервисов (обычно они раз в сутки обновляются автоматически).
Как я уже упоминал, при желании вы можете настроить еженедельное или ежемесячное получение отчетов о снятых позициях в виде CSV файла на указанный тут Емайл (для вас самих или для клиента, которому вы подвязались продвигать сайт):
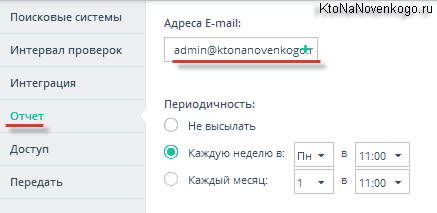
На вкладке «Доступ» вы сможете добавить Емайл адрес того респондента, которому хотите предоставить полные или урезанные права на управление данным проектом (ваш основной Емайл по умолчанию будет наделен максимальными полномочиями). Единственное что, этот пользователь должен быть зарегистрирован в Топвизоре.
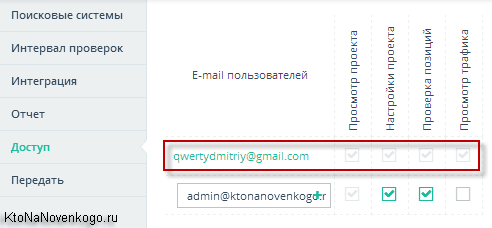
Ну и, наконец, на последней вкладке настроек сможете передать управление данным проектом по съему позиций для данного сайта какому-то другому пользователю данного сервиса, Емайл которого и нужно будет указать в имеющейся там форме.
Но это еще не все. Помните я говорил о возможности бесплатно определять позиции при помощи передачи своих лимитов из Яндекс.XML. Что это такое?
Ну, если говорить про XML от зеркала рунета, то его можно сравнить с ранее описанным мною поиском для сайт от Яндекса, но в случае использования XML серьезно повышается гибкость и варианты использования этой версии поиска (например, все та же поисковая системе Нигма использует эту технологию для доступа к базе Яндекса).
Но не суть. Главное понимать, что выдача в Яндекс.XML практически идентична выдаче основной (отличия проявляются обычно только на кануне очередного апдейта), а значит она вполне подойдет для проверки позиций.
Но XML для Топвизора является резервным вариантом, на случай, когда съем позиций с основной выдачи по форс мажорным обстоятельствам будет не возможен. Чтобы не нагружать свои сервера в Яндекс.XML имеют место быть лимиты на количество запросов, которые выделяются каждому сайту, желающему использовать эту технологию. Своих собственных лимитов у Топвизора, естественно, не хватит на нужды всех его пользователей.
Однако, лимиты можно передавать официальным путем. Поэтому вам и предлагают передать не нужные вам лимиты, а взамен получить определенное количество бесплатных проверок позиций (10% от числа переданных лимитов). Еще раз обращаю внимание, что квоты на использование XML будут задействованы в Топвизоре только в случае форс мажора, а позиции снимать бесплатно вы сможете хоть каждый день.
Для того, чтобы узнать выделенные именно вам лимиты, перейдите на эту страницу, поставьте галочку в самом низу о принятии условий и, перейдя на вкладку «Информация о лимитах», сможете узнать пределы выделенные для тех сайтов, что у вас висят на этом аккаунте в Яндекс Вебмастере:
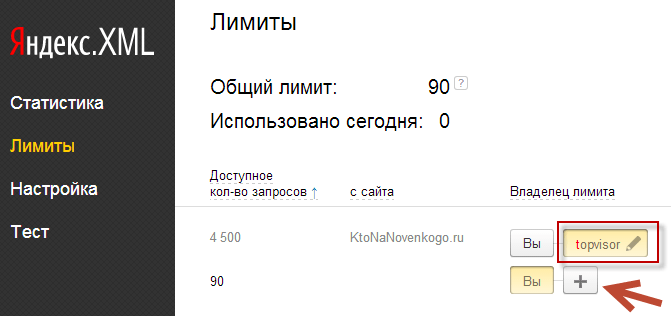
Для передачи лимитов служит приведенная там ссылочка. Инструкция по передачи находится на вкладке «Яндекс-XML» (из контекстного меню вашего логина нужно будет выбрать пункт «Профиль»).
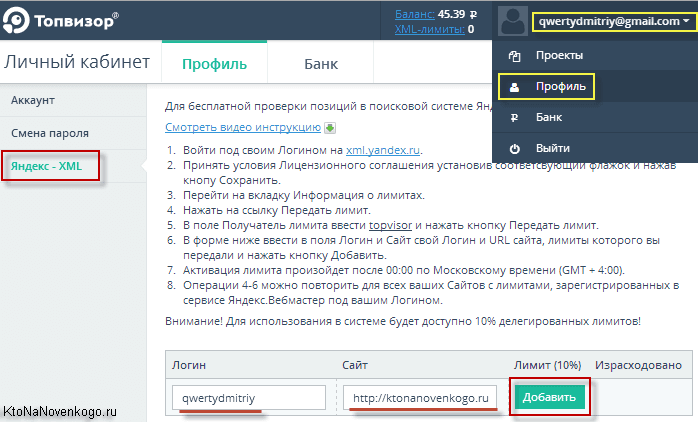
На этой странице Топвизора вам нужно будет указать свой логин в Яндексе и Урл того сайта, чьи лимиты вы передали.

Все, десять процентов запросов от общего числа переданных лимитов (в моем случае это 370) можно будет пробивать каждый день бесплатно, что не может не радовать.
Добавление запросов и подбор семядра средствами TopVizor
Все, с настройками покончено и пора переходить к очень интересной возможности этого онлайн сервиса, а именно к подбору семантического ядра. Для этого нужно будет из верхнего меню перейти на вкладку «Ядро». Тут вас ждет серый квадрат Малевича, на котором красуется большой знак плюс. Замечательно, именно по нему и кликаем мышью.

На приведенном скриншоте уже был создана одна группа с поисковыми запросами, по которым потом будут сниматься позиции, но вы на это не смотрите. После клика по плюсику, слева от него появится пустая форма с названием «Новая группа». Дважды кликнув по этому названия мышью вы получите возможность его изменить.
Сразу оговорюсь, что кликнув по зеленой точке рядом с названием группы запросов, вы эту самую точку перекрасите в красный цвет, что повлечет за собой прекращение съем позиций по данной группе. Но нам в данный момент интересны способы заполнения появившейся формы ключевыми словами, имеющими отношение к нашему сайту.
Есть несколько вариантов добавления запросов для проверки в Топвизоре:
- Вы можете вводить по одной ключевой фразе в поле «добавить запрос» в самом низу открывшейся формы и жмякать на расположенный рядом маленький плюсик. Ключевик запрыгнет в форму и останется там жить, пока вы не нажмете на появляющийся слева от него крестик или не перетащите его мышью в другую группу запросов на этой же странице.
Перетащить мышью можно будет и все содержимое формы, ухватив его за расположенный в нижнем правом углу значок (см. на скриншоте). Если у вас уже имеется готовый список ключевых слов (у меня, например, он есть и я периодически проверял позиции по нему в Site-Auditor, но проблема была в том, что список этот содержал тысячи ключей и на съем уходило несколько дней ручного труда), то кликните по второй иконке из расположенной слева вверху панели инструментов.
На ней еще нарисовано облачко со стрелочкой вверх и она выделена на обоих верхних скриншотах. Нашли? Замечательно.
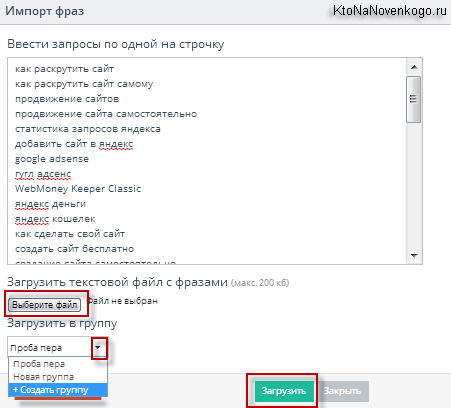
В открывшемся окне у вас будет опять же две возможности: либо методом копипаста через буфер обмена вставить уже готовый список ключевиков в приведенную форму (по одному ключу в стоке), либо загрузить уже готовый файл, в котором запросы представлены в таком же виде.
Обратите внимание, что в нижней части окна вы вольны не только выбрать одну из уже существующих групп ключевых слов, но и создать новую, что может быть иногда полезно. Ну, и кнопку «Загрузить» нажать не забудьте.
Третий способ вам может пригодиться тогда, когда вы еще, например, только планируете написание статьи на определенную тему, но еще не совсем уверены под какие именно поисковые запросы вы ее будете оптимизировать, чтобы иметь шанс попасть по ним в Топ и что намного важнее — понять, будете ли вы получать по ним трафик вообще, даже в случае попадания в Топ1.
Другими словами нам нужно собрать и просеять от пустышек и бесперспективных запросов семантическое ядро. Обычно для этой цели у вебмастеров имеются два источника получения списка ключевых слов — статистика Яндекса под название Вордстат и поисковые подсказки Yandex, Гугла или Майл.ру, которые можно спарсить программным способом.
Собственно, TopVizor именно эти инструменты и предлагает вашему вниманию для сбора и расширения семядра. Ну, и еще он предлагает собрать частотность по всем этим запросам, а также определить цену клика в Яндекс Директе.
Если запрос окажется не востребованным (например, менее 20 вводов в выдаче за месяц), то его можно смело удалять из списка. Так же, если цена за клик в Директе по нему баснословная, то стоит задумать о перспективности траты средств на его продвижение.
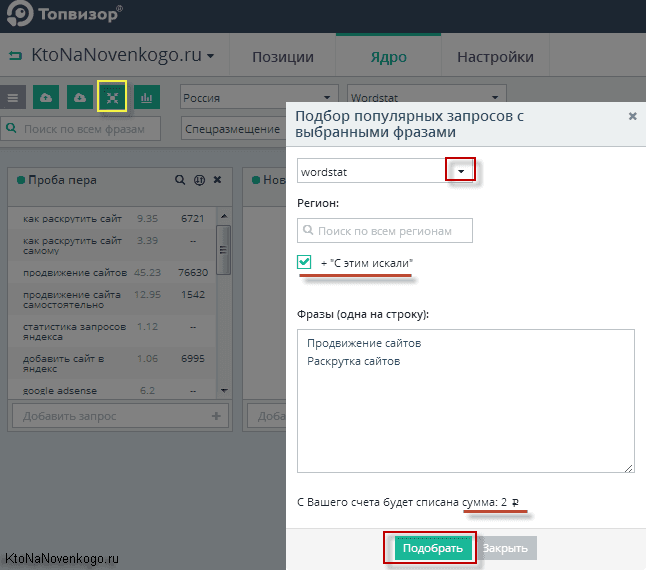
Посмотрим, как это все реализована на практике в Топвизоре. Для этого на панели инструментов вкладки «Ядро» нужно нажать на четвертую иконку, показанную на скриншоте:
Появится окно с возможностью выбора области парсинга (Вордстат или поисковые подсказки). При выборе Вордстата у вас будет возможность собрать данные не только из левой колонки, но из правой, просто установив галочку «С этим искали».
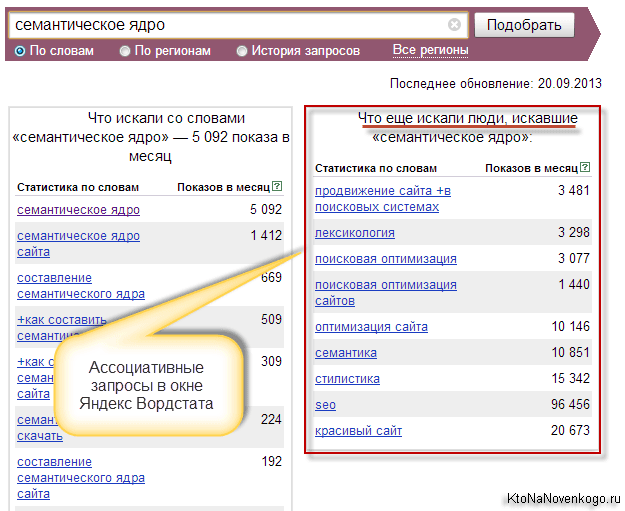
Позволю себе напомнить, что в левой колонке Wordstat выводятся словосочетания включающие то, что вы задали в качестве отправной точки, а в правой отображаются ассоциативные запросы, которые пользователи задавали Яндексу в той же самой поисковой сессии.
После начала парсинга у вас появятся несколько новых групп (для каждого начального запроса и для каждой колонки Вордстата), где в момент получения данных будет бегать змейка или начнет заполняться стакан фигурками из тетриса. По окончании процесса вы получите соответствующие списки:
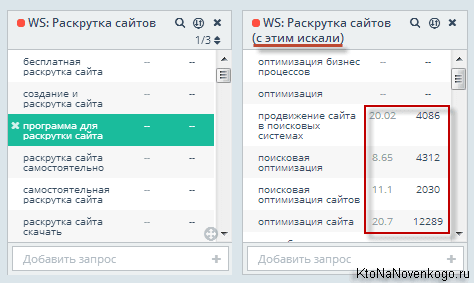
Например, для фразы «раскрутка сайтов» мы получили данные из левой и правой колонки Wordstat в показанном на скриншоте виде. Обратите внимание, что для некоторых из ключевиков уже показана частотность (вторая колонка цифр) и стоимость клика в Директе (первая).
Откуда они взялись, если мы ее не снимали? Просто эти данные уже оплатили другие пользователи Топвизора, а он нам любезно предложил воспользоваться цифирьками, хранящимися у этого сервиса в кеше. Чем больше будет пользователей, тем реже придется платить за съем частотности.
Нам же для полноты картины и начала дальнейшего анализа семантического ядра не хватает данных из поисковых подсказок популярных поисковиков рунета. По определению, это наиболее часто задаваемые поиску вопросы, которые и подсовываются всем подряд, чтобы облегчить труд по поиску нужных буковок на клавиатуре.
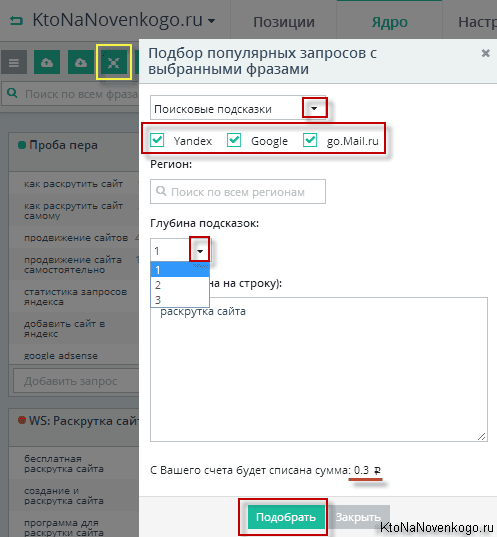
Парсинг подсказок в этой сервисе активируется той же самой четвертой кнопкой на панели инструментов вкладки «Ядро», но в открывшемся окне вам нужно будет выбрать другой вариант из выпадающего списка:
Можно собрать подсказки со всех поисковиков, а можно только с нужных вам. Кроме этого, чуть ниже можете выбрать глубину подсказок (от 1 до 3). Что это такое? Хороший вопрос, на который не так-то просто ответить словами, ибо это проще увидеть и услышать из уст популярного блогера:
Для каждого поисковика будет собрана своя группа запросов выдранных из подсказок. Обратите внимание, что стоимость парсинга, выводимая внизу формы, будет зависеть как от числа выбранных поисковых систем, так и от глубины подсказок. Варьироваться она может от десяти копеек до полутора рублей, что, в общем-то, совсем не много.
Проблематика сбора полноценного семантического ядра
Вполне логично, что сервис, осуществляющий мониторинг позиций сайта по различным ключевым запросам, может помочь эти самые запросы подобрать. Вообще, процесс сборки полного пула запроса весьма сложен. Как правило, многие оптимизаторы отделываются лишь сбором малой части ядра, тем самым существенно затрудняя путь к успеху своего сайта (читайте про пять основных ошибок при продвижение коммерческого сайта).
Наиболее полное ядро можно собрать, если использовать все имеющиеся для этого инструменты (а не только Yandex Wordstat). Можно, например, проанализировать те запросы, по которым на сайт уже приходят посетители (в Топвизоре это позволяет сделать «Магнит»), можно собрать ключи по всем возможным сервисам, предназначенным для рекламодателей контекстной рекламы, а также можно подключить поисковые подсказки и ключи, собранные в панелях поисковых систем для вебмастеров.
Однако, даже при полном охвате всего пула запросов по данной тематики (что, по большому счету, маловероятно из-за огромного «длинного хвоста»), этот список еще нельзя будет назвать полноценным семантическим ядром, ибо не решен главный вопрос. Заключается он в том, что же с этими самыми собранными запросами делать.
Можно попробовать отвести под каждый из них отдельную страницу и написать соответствующие тексты (читайте про 8 основных ошибок и 6 советов по оптимизации текстов для успешного продвижения сайта). Но это будет просто нерентабельно, да и практически не реализуемого для ядра в десятки или даже сотни тысяч запросов. Что же делать?
В общем-то, вариант только один — группировать запросы для оптимизации под отдельные группы отдельных страниц вашего сайта. Но при этом встает еще одни не менее важный вопрос — какие запросы можно объединять в группы, а какие нельзя?
Нужно понимать, что объединить-то нужно не просто по своему желанию, а чтобы они все сумели попасть в Топ (точнее в целый ряд Топов по числу объединенных запросов) при том, что размещены они все будут на одной странице. Поэтому вопрос сводится к следующему — какие запросы можно объединить на одной страницы без ущерба для их продвижения.
Есть разные методики (от аналитики до наития), которые используют составители семантических ядер. На мой взгляд, неплохим принципом может служить: одна проблема — одна страница с ее решением. Или что-то подобное. Но все же это гадание на кофейной гуще, ибо в Яндексе за это дело отвечает бездушная машина под названием Матрикснет, которая с человеческой логикой считается не всегда.
Однако, нам может помочь одна из пяти приведенных выше недоработок оптимизаторов — анализ конкурентов. Можно ведь внимательно посмотреть на тех конкурентов, которые попали в Топ по многим из продвигаемых вами ключевым словам, и проанализировать, какие именно группы запросов они объединяли на одной странице, чтобы повторить за ними, ибо это, априори, сработало по крайней мере один раз и может сработать снова.
Другое дело, что делать это все вручную крайне трудозатратно. Если с небольшим числом высокачастотных и среднечастотных запросов при должном подходе справиться можно, то низкочастотники, и уже тем более «длинный хвост» (сверх низкочастотные запросы) охватить вручную не получится, как ни старайся. Да и вообще, человеко-часам можно будет найти куда более лучшее применение, чем заниматься тем, что может сделать машина (программа или алгоритм).
Собственно, с недавних пор всю эту рутину взял на себя TopVizor. Сбор семантического ядра через него частично платный (за отдельные операции), но, по сути, это сущие копейки за такую работу. Ведь это основа для всего будущего и текущего продвижения сайта, без которой ничего достичь путного не получится. Давайте посмотрим алгоритм работы модуля «Ядро» в Топвизоре и отдельно остановимся на его изюминке — кластеризации запросов на основе выдачи Яндекс или Google.
Сборка семядра для сайта в TopVizor
Итак, в интерфейсе сайта Топвизор переходите из левого меню на вкладку «Ядро» (вторая иконка сверху) и осматривайтесь.
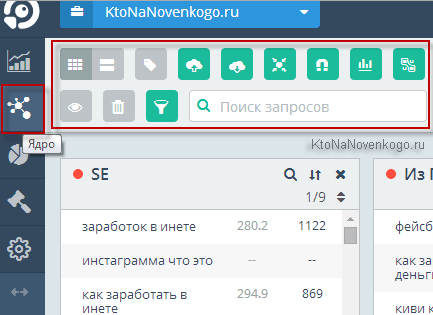
За прошедший год набор инструментов в верхней панели существенно расширился (видимо, сказалась плотная работа с пользователями сервиса, которые высказывали свои чаяния и пожелания).
Добавилась, например, возможность переключения из режима просмотра «в виде блоков» (который используется по умолчанию) в режим «таблиц» (сдвоенная пиктограмма в начале панели инструментов). Блоки хорошо подходят для переброски ключевых слов между группами, а таблицы лучше подходят для изучения ключей внутри одной группы (больше данных отображается и повышается наглядность).
Далее идет иконка активирующая маркер (можно будет выбрать цвет для пометок определенных ключей в группах), а за ней находятся иконки для экспорта и импорта запросов. Примечательно, что запросы теперь можно импортировать (загружать) в виде списков с указанием групп, к которым должны принадлежать те или иные слова (формат записи в этих списках должен быть такой — «запрос;урл целевой страницы;название группы»).
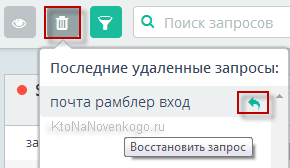
Еще несколько мелочей, которые существенно повышают удобство работы, на мой взгляд. Для удаления ненужного запроса достаточно подвести к нему курсор мыши и кликнуть по значку корзины, появившейся слева от него. Однако, все мы люди, а значит можем запросто удалить что-то нужное по неосторожности. Теперь в панели инструментов появилась кнопку «Корзина», где хранятся два десятка удаленных последними запросов, которые при желании можно будет восстановить.
Рядом с ней слева вы увидите кнопку с глазом, которая позволяет временно убрать с экрана не нужные вам в данный момент работы блоки (группы запросов), чтобы они не мешались занимая место и излишне запутывая вас. Удобно. Там же вы найдете иконку фильтра (с воронкой), которая поможет вам отфильтровать, например, только ВЧ запросы, если возникнет такая необходимость. Ну, и естественно строка поиска, куда можно начать вводить слова запроса и сразу видеть результат фильтрации.
Ну и, конечно же, заслуживает всех похвал реализация механизмов перетаскивания мышью ключевых слов внутри или между группами (для переноса всех запросов из блока подведите курсор к ее правому нижнему краю до появления обводки), а также выстраивание блоков (хватая их мышью за «шапку») в нужном вам порядке. Вместо использования кнопки «глаз» можно не нужные пока блоки с группами перетащить за область просмотра, создав тем самым второй экран, на который можно будет перейти по нажатию на появившуюся вверху точку (как в слайдерах). Удобно, очень даже.
Собственно, пора начинать. Сбор ядра можно начать с инструментов поисковых систем, таких как Яндекс Вордстат, Google Keyword Planner и т.п. В Топвизоре все это можно сделать, нажав на кнопку «Подбор ключевых слов» в верхней панели инструментов.
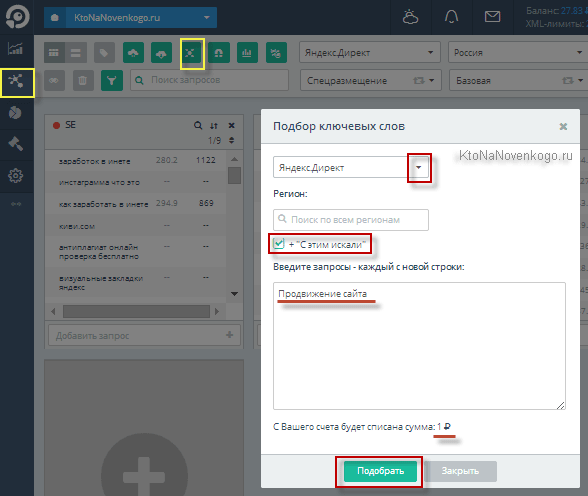
Из выпадающего списка можно выбрать для начала Яндекс Вордстат (можно и галочку будет поставить, чтобы собирались данные не только левой, но и правой колонки Вордстата). В расположенной чуть ниже форме нужно будет вписать изначальные ключевые слова, от которых мы будем плясать. Где их взять? Из головы, у конкурентов или каким-то еще способом.
Каждый из этих начальных запросов (обычно это высокочастотник) будет прогоняться через Вордстат, и в результате вы получите десятки, сотни или даже тысячи образованных от него фраз, которые вводят пользователи поисковой системы Яндекс. Пока мы их все просто собираем, а чуть позже уже выявим пустышки и отбросим неподходящие еще по каким-либо причинам.
Если вы стремитесь собрать вообще все, что только можно, то кроме Вордстата стоит собрать ключи и из Google Keyword Planner (Адвордса), а также из панели вебмастерова Майл.ру и панели Bing. Кроме этого, кое-что полезное можно вытянуть и из поисковых подсказок (фраз, которые вы видите под поисковой строкой в момент набора запроса).
Повторяющиеся запросы, собранные в разных системах, Топвизор автоматически отсеет, что очень удобно. В итоге мы получим довольно приличный список уникальных запросов по интересующей нас тематики. Однако, не все возможные варианты изначальных ключей можно предусмотреть. Зачастую, что-то существенное остается за кадром. Поэтому нужно будет продолжить сбор ключей.
Для этого мы используем следующую иконку из верхней панели инструментов с изображением магнита. Называется она «Подбор ключевых слов по трафику из Я.Метрики и Google Analytics», что уже о многом говорит. Если вы еще не провели интеграцию с Метрикой и Аналитиксом, то прокрутите эту статью вверх и немедленно исправьте это упущение.
В открывшемся окне «магнита» можно будет выбрать статистику, из которой будут выдергиваться ключи, а также чуть правее выбрать период времени, за который будет осуществляться выборка.
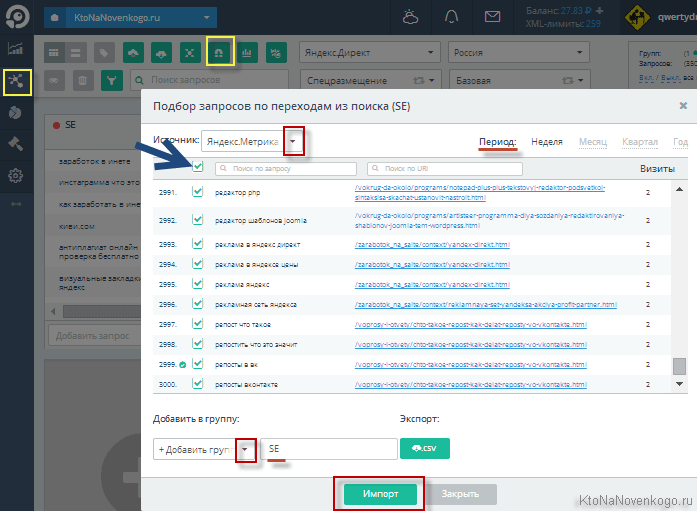
Запросов будет, скорее всего, много. В моем случае выдается по три тысячи штук из каждой системы статистики (видимо, это потолок). Все их или только часть можно пометить галочками, после чего выбрать уже существующую группу (или ввести название для новой) и нажать на кнопку «Импорт». Все помеченные галочками ключи будут перемещены в нее и вы сможете начать с ними работать. Естественно, что выгрузка производится бесплатно.
Теперь у нас имеет огромная куча уникальных запросов соответствующих нужной тематике. Однако, не все из них одинаково полезны, ибо многие из них пользователи вообще никогда не используют при своем обращении к поисковым системам, а значит продвижение по ним совершенно не даст никакого результата. Так как же выявить эти самые «пустышки»?
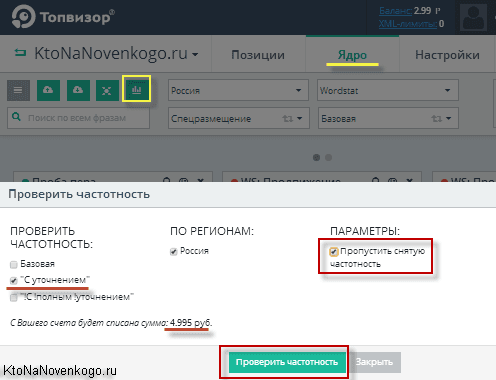
Довольно просто — нужно будет собрать по ним точную или фразовую частотность (читайте про операторы Вордстата). В Топвизоре для этой цели имеется отдельный инструмент, который можно активировать нажатием по иконке «Проверка частотности» на верхней панели инструментов:
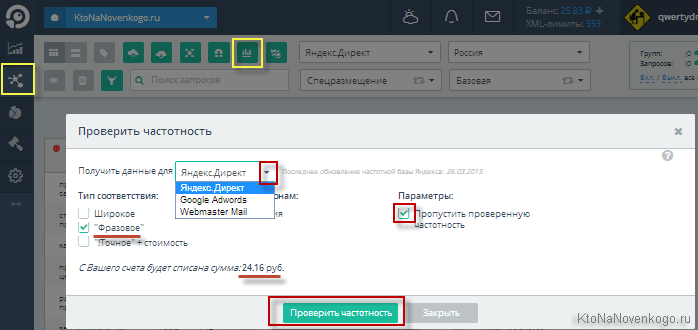
«Пробивать» частотность можно по трем системам: Вордстату (Директу), Адвордсу и Вебмастеру Майл.ру. Широкое соответствие не позволит вам выявить пустышки, поэтому выбираем либо фразовое (учитываются запросы пользователей содержащие только эти слова и фразы, но в любой словоформе), либо точное (учитывается еще и словоформа — род, число, падеж). Также можете выбрать регион. Стоимость проверки будет зависеть от числа ваших запросов и типов частотности, которые вы хотите снимать.
Потом ставите фильтр, по которому отсеиваются запросы, имеющие частотность меньше заданной вами. Какой именно порог выбрать, зависит от тематики вашего сайта. Например, в недвижимости запрос с единичной частотностью может вполне привести к одной продаже в год, а это по-любому окупит расходы на его продвижение. В другой же тематике запросы ниже сотни могут быть не рентабельными в продвижении.
Ну, и теперь мы подошли к самому интересному. Если вы сделали все правильно, то в сухом остатке у вас сейчас имеется огромная куча ваших целевых запросов, которые желательно было бы использовать при продвижении. Но писать под каждый из них текст (отводить отдельную страницу) было бы верхом нерентабельности и расточительства. Поэтому их надо объединить в группы, под которые и будут оптимизироваться итоговые страницы вашего сайта.
Автоматическая группировка запросов в Топвизоре
Вот как раз этого финального аккорда и не хватало в TopVizor, но теперь он появился. Это кнопочка «Кластеризация ядра» в верхней панели инструментов. Нужно понимать, что после выполнения кластеризации все созданные вами ранее группы буду разбиты, а запросы перемещены между вновь созданными.
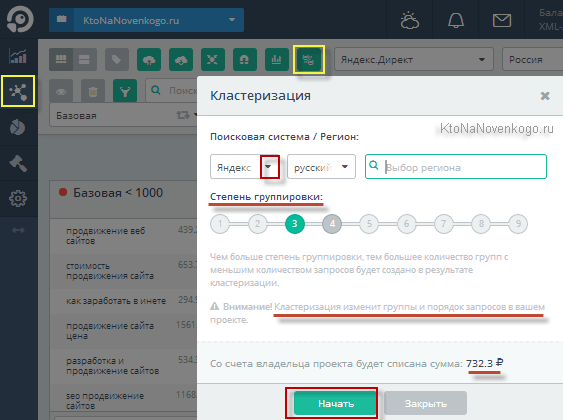
В инструменте группировки вы можете выбрать поисковую систему, на основании данных которой будет осуществляться группировка. Что выбрать? Ну, очевидно тот поисковик, под который вы собираетесь продвигаться и штурмовать Топы. То же самое касается и региона (если вы его не выберите, то выборка будет осуществляться по региону Россия).
Немного поясню принцип, используемый при группировке. По каждому из запросов вашего семядра в поисковую систему будет отправлен запрос и будут сняты данные по Топ 10 (Урлы страниц попавших в Топ — веб-документы). Потом система анализирует, какие страницы сумели попасть сразу в несколько Топов (по разным запросам). Что это означает? А означает то, что данные запросы вполне можно объединить (сгруппировать) для продвижения на одной странице (в одном веб-документе), и это не домыслы, а факты, подтвержденные самой поисковой системой.
Название такой группы Топвизор задаст в соответствии с самым частотным запросом в этой группе. Если по каким-то запросам не будет найдено повторений посадочных страниц (веб-документов), то они будут помещены в отдельную группу «Запросы без связей». В этом случае нужно будет подумать либо про расширение семядра в сторону использования созвучных с ними запросов, либо отводить под продвижение каждого из них отдельную страницу на вашем сайте (исходя из их частотности и целесообразности сего действа).
В TopVizor кластеризацию можно делать и для собранного в нем же семядра (как в нашем примере), и для импортированного списка ключевых слов (если вам уже кто-то подобрал запросы и их осталось только распределить по страницам). Стоимость перегруппировки составляет 0,01 руб. за запрос.
В окне «Кластеризация» также имеется возможность указать степень группировки. Что это такое? Фактически это число документов в выдачи, по наличию которых в Топах будет осуществляться группировка запросов. Например, если выбрать единичку, то достаточно будет найти в Топ 10 один документ, который по данным запросам туда попал, и на основе этих данных можно составлять группу.
Но один факт это ведь еще не тенденция, поэтому лучше, чтобы таких совпадений было бы хотя бы штуки три. С ходу наверное не совсем все ясно, но может быть гайд от разработчиков будет вам более понятен, чем мои пространные объяснения:

Сам процесс кластеризации займет какое-то время (зависит от числа запросов в вашем семантическом ядре, ибо 1000 запросов обрабатывается примерно две-три минуты). По окончании вы увидите много блоков с вновь созданными группами, которые уже можно смело начинать переносить на отдельные страницы сайта (одна группа — одна страница) в виде написанных и оптимизированных под них текстов.
Само собой разумеется, что съем позиций по этим вновь сгруппированным запросам пока вестись не будет (слева от названия группы будет показана красная точка). Для запуска же съема позиций по ним (например, после публикации страницы вашего сайта под них оптимизированных) достаточно будет кликнуть по этой самой красной точке в нужной группе, чтобы она стала зеленой.
Ну и, кончено же, будет уместно посмотреть на результат, который может получиться после автогруппировки запросов в Топвизоре — пример (файлик в формате CSV).
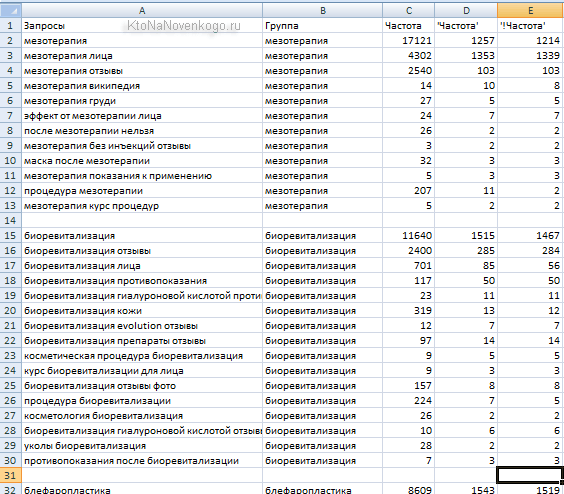
Как бы очень даже удобно. Запросы разбиты на группы под отдельные страницы, а также отсортированы по частоте. Остается только написать под них тексты, либо дооптимизировать уже существующие.
Проверка частотности запросов и цены клика для них в Яндекс Директе
Вот, смотрите. Мы собрали запросы из левой и правой колонки Вордстата, спарсили поисковые подсказки и получили целый набор групп ключевиков. Теперь настала пора избавиться от пустышек и бесперспективных. Для этого нужно будет пробить частотность в Yandex Wordstat по всем этим ключевым фразам.
Этой цели служит пятая иконка на панели инструментов вкладки «Ядро». В открывшемся окне вы вольны будете выбрать, какую именно частотность хотите определить (из трех возможных, описанных чуть ниже), в каком регионе и хотите ли при этом сэкономить, поставив галочку, запрещающую обновление уже имеющихся данных (которые снимали вы или другие пользователи Топвизора).
Но в самый интересный момент у меня кончились те десять рублей, что выдаются при регистрации. Поэтому пришлось выбрать из выпадающего меню моего логина пункт «Банк» и перейти в открывшемся окне на вкладку «Оплата».

Собственно, про доступные способы оплаты я уже упоминал, ну, а я как обычно воспользовался своим кошельком в Вебманях.
После совершения платежа я все-таки запустил съем частности по всем собранным запросам, который сопровождался волнообразной полосатостью кнопки:
Через несколько секунд появилась оранжевая табличка, призывающая обновить страницу и ознакомиться с результатами.
Если вы вдруг по-прежнему не у всех запросов увидите значение частоты их использования, то не спешите ругать Топвизор и требовать вернуть ваши деньги.
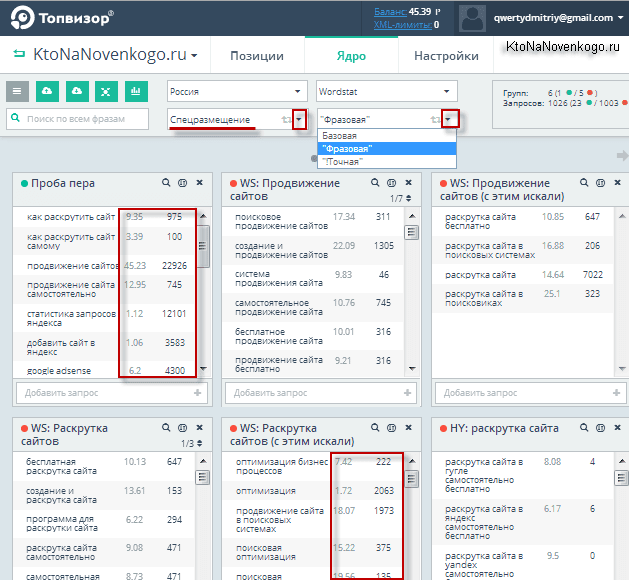
Дело в том, что снимать можно три значения частотности (общую, фразовую и точную). Я, например, снимал фразовую, а по умолчанию в верхнем выпадающем списке выбрана общая. Поэтому, просто выбрав фразовую частотность, я получил показанную на скриншоте картину маслом.
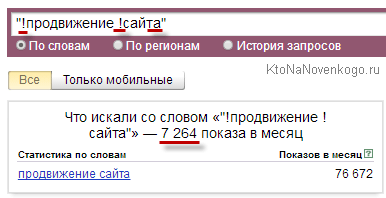
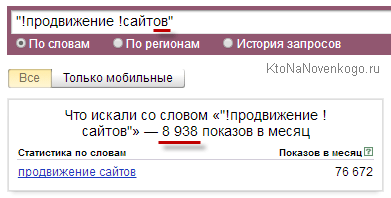
Да, забыл сказать пару слов про этим самые частотности. Ничего сложно в этом нет и корни сей градации уходят в описанные мною операторы поиска Яндекса, а именно кавычки и восклицательный знак проставленный перед словом. Эти же операторы и с тем же назначением можно использовать и в окне Вордстата при вводе запроса (заключать его в кавычки или ставить ! перед каждым словом).
- Обычная — вводите запрос как есть и получаете все словосочетания, которые включают в себя данную фразу, хотя реальная частотность запроса этого ключа может быть и нулевой.
- Фразовая — запрос заключается в кавычки и в результате будут посчитаны запросы именно этих слов, но во всех возможных морфологических формах (падежах, числах).
Лично я предпочитаю именно этот вариант, ибо оптимизировать статью под строгую морфологическую форму я не в силах, хотя иногда стоит понять в каком виде лучше всего ключевик употребить в тайтле. - Точная — кроме кавычек добавляем еще и восклицательный знак перед каждым словом. В результате будет посчитана частота ввода этого словосочетания (именно в этой морфологической форме) пользователями Яндекса в течении месяца.
Откуда взялась такая разница в цифрах? Очевидно, что имеет место быть запрос(ы) с теми же самым ключевыми словами, но в другой словоформе, который отъедает оставшиеся цифирьки. Для нашего примера нетрудно догадаться, что это будет множественное число:
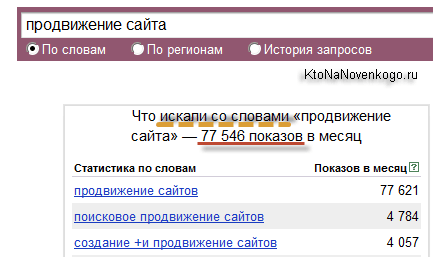
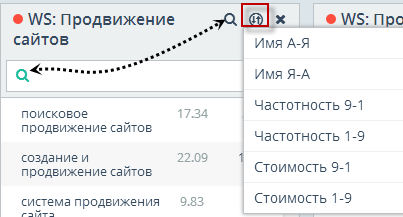
Собранные в каждой группе запросы можно сортировать по алфавиту, по частоте, а также и по стоимости клика в Яндекс Директе. Если ключевых слов в группе много, то можно воспользоваться внутренним поиском.
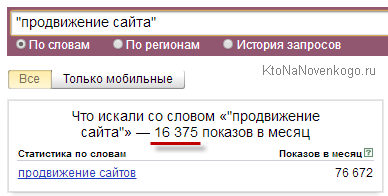
Теперь вам только останется пробежаться по всем группам запросов и поудалять те, что имеют близкую к нулю частотность и у которых зашкаливает цена за клик. Например, запрос «продвижение сайта» имеет цену за Спецразмещение в 45 рублей за клик (пожалуй, что именно этот вариант отображения цены лучше всего характеризует перспективность продвижения), что слишком дорого и говорит о чудовищной конкуренции по этой ключевой фразе.
Я бы никогда не стал оптимизироваться под нее, хотя бывают случаи, когда продвижение по СЧ приводит сайт в Топ по ВЧ. Собственно, у меня в Топ 10 сейчас блог уже не попадает по фразе «продвижение сайта» (хотя он и бывал на девятой позиции), но даже текущее место на второй странице объясняется лишь действием алгоритма Спектр, а не моими финансовыми вливаниями.
Когда поудаляете все лишнее, то можно все ключевые фразы перетащить в одну группу, а лишние удалить. На этом добавление запросов и сборка ядра подошла к концу, а мы продолжаем изучать возможности Топвизора уже по проверке и отображения позиций сайта в выдачах Яндекса, Гугла или Майл.ру.
Проверка позиций сайта в TopVizor
Переходим на вкладку «Позиции» из верхнего меню. Сразу же оговорюсь, что попасть туда же можно будет и из контекстного меню вашего логина, выбрав пункт «Проекты» и кликнув на открывшейся странице по показанной на скриншоте иконке.
Обратите внимание, что я разрешил Топвизору взять данные из моих аккаунтов в Метрике и Вебмастере, поэтому могу наглядно наблюдать динамику по следующим параметрам на этой странице:
- Большая зелена кнопка служит для ручного запуска съема, а внизу отображается стоимость такой операции.
- Число посетителей за последние сутки, которые пришли на мой сайт с поисковых систем Яндекс, Гугл и Майл.ру (для каждой в отдельности)
- Число страниц в индексе Яндекса и Google
- Количество обратных ссылок по версии Вебмастера
- Тиц и Пр
- Наличие в каталогах Яндекса, Дмоз или Майл.ру — кликнув по зеленой галочке можно попасть на страницу данного каталога с описанием вашего сайта
Но это мы отвлеклись, а теперь давайте, наконец, зайдем на вкладку «Позиции» и посмотрим что там к чему.
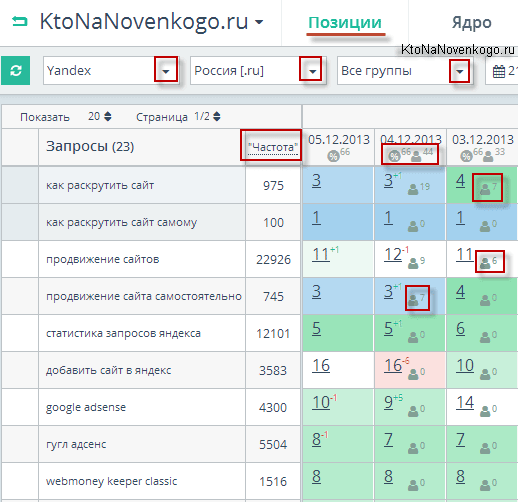
Из верхнего меню с помощью выпадающих списков выбираете поисковую систему, регион, а так же группу запросов, для которой хотите посмотреть динамику изменения позиций за последнее время.
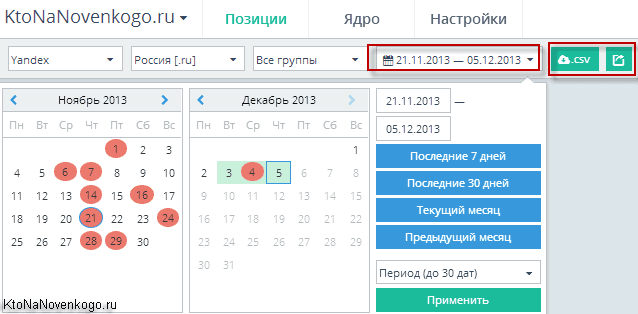
Чуть правее расположено окно выбора отчетного периода и кнопки для выгрузки данных в формате CSV и Html (последняя позволяет как отправить данные по почте, так и скачать на компьютер).
Если внимательно взглянуть на таблицу со снятыми позициями, то можно заметить, что рядом с некоторыми позициями стоят циферки (отличные от нуля) взятые из Метрики, которые говорят о том, сколько человек в этот день пришли к вам на сайт, введя данные слова в той поисковой машине, для которой вы просматриваете позиции.
Имеется отдельная колонка с частотностью данных запросов. Но какая именно из трех возможных частот отображается и как их поменять? Довольно просто — кликаете по слову «частота» и оно будет отображаться с кавычками, с восклицательным знаком или в естественном виде. Очень удобно, на мой взгляд.
Вверху каждой колонки проставлена дата проверки позиций. Если по ней кликнуть, то произойдет сортировка данных в таблице по значениям цифирек в колонке. Под датой вы сможете увидеть процентное соотношение запросов, которые попали в Топ 10 и суммарный трафик, которые они привели на ваш ресурс.
Что примечательно, если кликнуть по любой позиции в этой таблице, то вы перейдете на ту страницу своего сайта, которая является для этого запроса целевой (приземляющей) по версии того поисковика, который вы выбрали из верхнего правого списка. Урлы этих страниц также попадают в CSV файл при выгрузке.
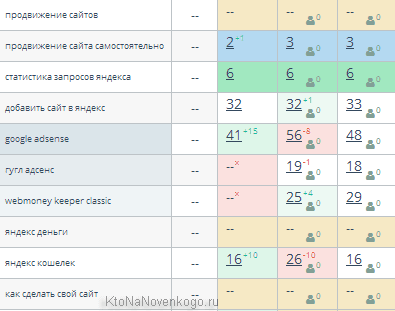
Сами клетки с позициями имеют цветовую дифференциацию по следующему принципу:
- Розовая подсветка говорит о том, что все плохо и ваш сайт по данному запросу провалился по крайней мере на одну страницу в глубь серпа (имеются в виду настойки выдачи по умолчанию, когда на странице отображаются 10 сайтов с ответами).
- Желтый фон тоже не сулит ничего хорошего, ибо говорит, что вашего сайта не видать в обозреваемом Топвизором пространстве (первые 100 позиций). В Google у меня как раз много подобных цветовых решений по данным ключевым словам:
- Зеленый цвет говорит о том, что сайт находит в Топ 10, но еще не попал в Топ3.
- Голубоватый — желанный Топ3 достигнут
- Салатовый цвет обнадеживает хотя бы тем, что запрос стал по крайней мере на одну страницу ближе к Топу.
Кому может быть полезен этот онлайн сервис?
Ну, вроде бы все, чем хотел с вами поделиться. Получилось довольно объемно, но и возможностей у данного онлайн сервиса оказалось больше, нежели у традиционного инструмента по снятию позиций.
Получается, что сервис будет удобен не только тем, кто проверяет позиции, но и тем, кто работает с семантическим ядром, а это могут быть, например, люди, которые пользуются системами контекстной рекламы или другие пользователи, которым нужно подобрать ключевые слова.
Что примечательно, за время тестирования не было ни одного лага связанного с медленной работой этого онлайн сервиса. Создавалось впечатление, что работаешь с десктопной программой. А каким вам, уважаемые читатели, показался сервис Топвизор?
Идея реализовать в Топвизоре полноценную цепочку инструментов для пошаговой сборки семантического ядра мне очень понравилась. Можно будет включится в это дело как с самого начала, так и на любом шаге, импортировав уже имеющиеся у вас запросы и добрав все недостающие запросы до получения полноценно семядра.
Ну, а модуль кластеризации позволил все этого дело оформить в завершенную логическую цепочку, когда на выходе уже получаем список ключевых слов с постраничной привязкой. Останется только передать его оптимизаторам, чтобы те составили задания для копирайтеров. Либо сделать это все самому.
KeyAssort — как составить семантическое ядро и создать структуру сайта
Хочу сделать очередной заход на тему «сбора семядра». Сначала будет немного лирики, как полагается, а потом много практики, может быть и несколько неуклюжей в моем исполнении. Итак, лирика. Ходить с завязанными глазами в поисках удачи мне надоело уже через год, после начала ведения этого блога. Да, были «удачные попадания» (интуитивное угадывание часто задаваемых поисковикам запросов) и был определенный трафик с поисковиков, но хотелось каждый раз бить в цель (по крайней мере, ее видеть).
По сути ж ведь нет ничего зазорного в том, чтобы заранее понять, в какие чудесные слова облекают свои хотелки те, кому будут адресованы будущие публикации. Учтя это (собрав семантику под статью), мы повышаем шансы на успех (покорение Топа по этим фразам — см. словарь SEO-балбеса). По этому поводу была написана статья про работу с Вордстатом и этап сбора семядра.
Потом захотелось большего — автоматизации процесса сбора запросов и отсева «пустышек». По этой причине появился опыт работы с Кейколлектором (и его неблагозвучным младшим братом) и очередная статья на тему автоматизации процесса подбора поисковых запросов. Все было здорово и даже просто замечательно, пока я не понял, что есть один таки очень важный момент, оставшийся по сути за кадром — раскидывание запросов по статьям.
Писать отдельную статью под отдельный запрос оправдано либо в высококонкурентных тематиках, либо в сильно доходных. Для инфосайтов же — это полный бред, а посему приходится запросы объединять на одной странице. Как? Интуитивно, т.е. опять же вслепую. А ведь далеко не все запросы уживаются на одной странице и имеют хотя бы гипотетический шанс выйти в Топ.
Собственно, сегодня как раз и пойдет речь об автоматической кластеризации семантического ядра посредством KeyAssort (разбивке запросов по страницам, а для новых сайтов еще и построение на их основе структуры, т.е. разделов, категорий). Ну, и сам процесс сбора запросов мы еще раз пройдем на всякий пожарный (в том числе и с новыми инструментами).
Какой из этапов сбора семантического ядра самый важный?
Сам по себе сбор запросов (основы семантического ядра) для будущего или уже существующего сайта является процессом довольно таки интересным (кому как, конечно же) и реализован может быть несколькими способами, результаты которых можно будет потом объединить в один большой список (почистив дубли, удалив пустышки по стоп словам).
Например, можно вручную начать терзать Вордстат, а в добавок к этому подключить Кейколлектор (или его неблагозвучную бесплатную версию). Однако, это все здорово, когда вы с тематикой более-менее знакомы и знаете ключи, на которые можно опереться (собирая их производные и схожие запросы из правой колонки Вордстата).
В конце концов, есть и бесплатный Букварис, который позволяет очень быстро стартануть в сборе запросов. Также можно заказать частным образом выгрузку из монстрообразной базы Ahrefs и получить опять таки ключи ваших конкурентов. Вообще, стоит рассматривать все, что может принести хотя бы толику полезных для будущего продвижения запросов, которые потом не так уж сложно будет почистить и объединить в один большой (зачастую даже огромный список).
Все это мы (в общих чертах, конечно же) рассмотрим чуть ниже, но в конце всегда встает главный вопрос — что делать дальше. На самом деле, страшно бывает даже просто подступиться к тому, что мы получили в результате (пограбив десяток-другой конкурентов и поскребя по сусекам Кейколлектором). Голова может лопнуть от попытки разбить все эти запросы (ключевые слова) по отдельным страницах будущего или уже существующего сайта.
Какие запросы будут удачно уживаться на одной странице, а какие даже не стоит пытаться объединять? Реально сложный вопрос, который я ранее решал чисто интуитивно, ибо анализировать выдачу Яндекса (или Гугла) на предмет «а как там у конкурентов» вручную убого, а варианты автоматизации под руку не попадались. Ну, до поры до времени. Все ж таки подобный инструмент «всплыл» и о нем сегодня пойдет речь в заключительной части статьи.
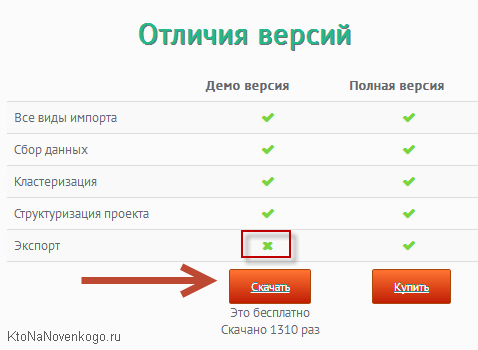
Это не онлайн-сервис, а программное решение, дистрибутив которого можно скачать на главной странице официального сайта (демо-версию).
Посему никаких ограничений на количество обрабатываемых запросов нет — сколько надо, столько и обрабатывайте (есть, однако, нюансы в сборе данных). Платная версия стоит менее двух тысяч, что для решаемых задач, можно сказать, даром (имхо).
Но про техническую сторону KeyAssort мы чуть ниже поговорим, а тут хотелось бы сказать про сам принцип, который позволяет разбить список ключевых слов (практически любой длины) на кластеры, т.е. набор ключевых слов, которые с успехом можно использовать на одной странице сайта (оптимизировать под них текст, заголовки и ссылочную массу — применить магию SEO).
Откуда вообще можно черпать информацию? Кто подскажет, что «выгорит», а что достоверно не сработает? Очевидно, что лучшим советчиком будет сама поисковая система (в нашем случае Яндекс, как кладезь коммерческих запросов). Достаточно посмотреть на большом объеме данных выдачу (допустим, проаналазировать ТОП 10) по всем этим запросам (из собранного списка будущего семядра) и понять, что удалось вашим конкурентам успешно объединить на одной странице. Если эта тенденция будет несколько раз повторяться, то можно говорить о закономерности, а на основе нее уже можно бить ключи на кластеры.
KeyAssort позволяет в настройках задавать «строгость», с которой будут формироваться кластеры (отбирать ключи, которые можно использовать на одной странице). Например, для коммерции имеет смысл ужесточать требования отбора, ибо важно получить гарантированный результат, пусть и за счет чуть больших затрат на написание текстов под большее число кластеров. Для информационных сайтов можно наоборот сделать некоторые послабления, чтобы меньшими усилиями получить потенциально больший трафик (с несколько большим риском «невыгорания»). Как это сделать опять же поговорим.
А что делать, если у вас уже есть сайт с кучей статей, но вы хотите расширить существующее семядро и оптимизировать уже имеющиеся статьи под большее число ключей, чтобы за минимум усилий (чуток сместить акцент ключей) получить поболе трафика? Эта программка и на этот вопрос дает ответ — можно те запросы, под которые уже оптимизированы существующие страницы, сделать маркерными, и вокруг них KeyAssort соберет кластер с дополнительными запросами, которые вполне успешно продвигают (на одной странице) ваши конкуренты по выдаче. Интересненько так получается...
Как собрать пул запросов по нужной вам тематике?
Любое семантическое ядро начинается, по сути, со сбора огромного количества запросов, большая часть из которых будет отброшена. Но главное, чтобы на первичном этапе в него попали те самые «жемчужины», под которые потом и будут создаваться и продвигаться отдельные страницы вашего будущего или уже существующего сайта. На данном этапе, наверное, самым важным является набрать как можно больше более-менее подходящих запросов и ничего не упустить, а пустышки потом легко отсеяться.
Встает справедливый вопрос, а какие инструменты для этого использовать? Есть один однозначный и очень правильный ответ — разные. Чем больше, тем лучше. Однако, эти самые методики сбора семантического ядра, наверное, стоит перечислить и дать общие оценки и рекомендации по их использованию.
- Яндекс Вордстат и его аналоги у других поисковых систем — изначально эти инструменты предназначались для тех, кто размещает контекстную рекламу, чтобы они могли понимать, насколько популярны те или иные фразы у пользователей поисковиков. Ну, понятно, что Сеошники этими инструментами пользуются тоже и весьма успешно. Могу порекомендовать пробежаться глазами по статье про работу со статистикой поисковых запросов, а также упомянутой в самом начале этой публикации статье про семядро и Я.Вордстат (полезно будет начинающим).
Из недостатков Водстата можно отметить:
- Чудовищно много ручной работы (однозначно требуется автоматизация и она будет рассмотрена чуть ниже), как по пробивке фраз основанных на ключе, так и по пробивке ассоциативных запросов из правой колонки.
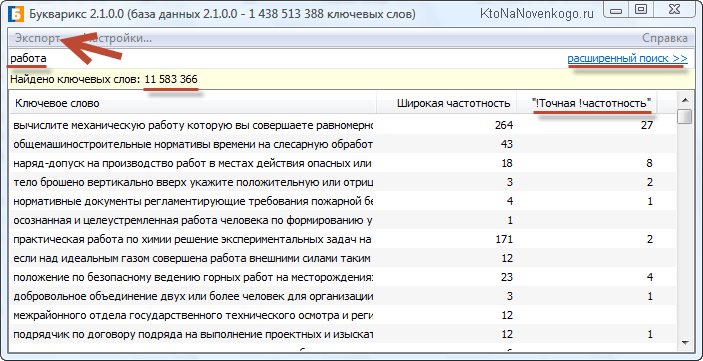
- Ограничение выдачи Вордстата (2000 запросов и не строчкой больше) может стать проблемой, ибо для некоторых фраз (например, «работа») это крайне мало и мы упускаем из вида низкочастотные, а иногда даже и среднечастотные запросы, способные приносить неплохой трафик и доход (их ведь многие упускают). Приходится «сильно напрягать голову», либо использовать альтернативные методы (например, базы ключевых слов, одну из которых мы рассмотрим ниже — при этом она бесплатная!).
- КейКоллектор — несколько лет назад появление этой программы было просто «спасением» для многих тружеников сети (да и сейчас представить без КК работу над семядром довольно трудно). Лирика. Я купил КК еще два или три года назад, но пользовался им от силы несколько месяцев, ибо программа привязана к железу (начинке компа), а она у меня по нескольку раз в год меняется. В общем, имея лицензию на КК пользуюсь SE — так то вот, до чего лень доводит.
Подробности можете почитать в статье «Автоматизация сбора семядра в Slovoeb». Обе программы помогут вам собрать запросы и из правой, и из левой колонки Вордстата, а также поисковые подсказки по нужным вам ключевым фразам. Подсказки — это то, что выпадает из поисковой строки, когда вы начинаете набирать запрос. Пользователи часто не закончив набор просто выбирают наиболее подходящий из этого списка вариант. Сеошники это дело просекли и используют такие запросы в оптимизации и даже пытаются их накручивать.
КК и SE позволяют сразу набрать очень большой пул запросов (правда, может потребоваться много времени, либо покупка XML лимитов, но об этом чуть ниже) и легко отсеять пустышки, например, проверкой частотности фраз взятых в кавычки (учите матчасть, если не поняли о чем речь — ссылки в начале публикации) или задав список стоп-слов (особо актуально для коммерции). После чего весь пул запросов можно легко экспортировать в Эксель для дальнейшей работы или для загрузки в KeyAssort (кластеризатор), о котором речь пойдет ниже. - СерпСтат (и другие подобные сервисы) — позволяет введя Урл своего сайта получить список ваших конкурентов по выдаче Яндекса и Гугла. А по каждому из этих конкурентов можно будет получить полный список ключевых слов, по которым им удалось пробиться и достичь определенных высот (получить трафик с поисковиков). Сводная таблица будет содержать частотность фразы, место сайта по ней в Топе и кучу другой разной полезной и не очень информации.
Не так давно я пользовал почти самый дорогой тарифный план Серпстата (но только один месяц) и успел за это время насохранять в Экселе чуть ли не гигабайт разных полезняшек. Собрал не только ключи конкурентов, но и просто пулы запросов по интересовавшим меня ключевым фразам, а также собрал семядра самых удачных страниц своих конкурентов, что, мне кажется, тоже очень важно. Одно плохо — теперь никак время не найду, чтобы вплотную заняться обработкой всей это бесценной информации. Но возможно, что KeyAssort все-таки снимет оцепенение перед чудовищной махиной данных, которые нужно обработать. - Букварикс — бесплатная база ключевых слов в своей собственной программной оболочке. Подбор ключевиков занимает доли секунды (выгрузка в Эксель минуты). Сколько там миллионов слов не помню, но отзывы о ней (в том числе и мой) просто отличные, и главное все это богатство бесплатно! Правда, дистрибутив программы весить 28 Гигов, а в распокованном виде база занимает на жестком диске более 100 Гбайт, но это все мелочи по сравнению с простотой и скоростью сбора пула запросов.
Но не только скорость сбора семядра является основным плюсом по сравнению с Вордстатом и КейКоллектором. Главное, что тут нет ограничений на 2000 строк для каждого запроса, а значит никакие НЧ и сверх НЧ от нас не ускользнут. Конечно же, частотность можно будет еще раз уточнить через тот же КК и по стоп-словам в нем отсев провести, но основную задачу Букварикс выполняет замечательно. Правда, сортировка по столбцам у него не работает, но сохранив пул запросов в Эксель там можно будет сортировать как заблагороссудится.
Наверное, еще как минимум несколько «серьезных» инструментов собора пула запросов приведете вы сами в комментариях, а я их успешно позаимствую...
Как очистить собранные поисковые запросы от «пустышек» и «мусора»?
Полученный в результате описанных выше манипуляций список, скорее всего, будет весьма большим (если не огромным). Поэтому прежде чем загружать его в кластерезатор (у нас это будет KeyAssort) имеет смысл его слегка почистить. Для этого пул запросов, например, можно выгрузить к кейколлектор и убрать:
- Запросы со слишком низкой частотностью (лично я пробиваю частотность в кавычках, но без восклицательных знаков). Какой порог выбирать решать вам, и во многом это зависит от тематики, конкурентности и типа ресурса, под который собирается семядро.
- Для коммерческих запросов имеется смысл использовать список стоп-слов (типа, «бесплатно», «скачать», «реферат», а также, например, названия городов, года и т.п.), чтобы заранее убрать из семядра то, что заведомо не приведет на сайт целевых покупателей (отсеять халявшиков, ищущих информацию, а не товар, ну, и жителей других регионов, например).
- Иногда имеет смысл руководствоваться при отсеве показателем конкуренции по данному запросу в выдаче. Например, по запросу «пластиковые окна» или «кондиционеры» можно даже не рыпаться — провал обеспечен заранее и со стопроцентной гарантией.
Скажите, что это слишком просто на словах, но сложно на деле. А вот и нет. Почему? А потому что один уважаемый мною человек (Михаил Шакин) не пожалел времени и записал видео с подробным описанием способов очистки поисковых запросов в Key Collector:
Спасибо ему за это, ибо данные вопрос гораздо проще и понятнее показать, чем описать в статье. В общем справитесь, ибо я в вас верю...
Настройка кластеризатора семядра KeyAssort под ваш сайт
Собственно, начинается самое интересное. Теперь весь этот огромный список ключей нужно будет как-то разбить (раскидать) на отдельных страницах вашего будущего или уже существующего сайта (который вы хотите существенно улучшить в плане приносимого с поисковых систем трафика). Не буду повторяться и говорить о принципах и сложности данного процесса, ибо зачем тогда я первую часть этой стать писал.
Итак, наш метод довольно прост. Идем на официальный сайт KeyAssort и скачиваем демо-версию, чтобы попробовать программу на зуб (отличие демо от полной версии — это невозможность выгрузить, то бишь экспортировать собранное семядро), а уже опосля можно будет и оплатить (1900 рубликов — мало, мало по современным реалиям). Если хотите сразу начать работу над ядром что называется «на чистовик», то лучше тогда выбрать полную версию с возможностью экспорта.
Программа КейАссорт сама собирать ключи не умеет (это, собственно, и не ее прерогатива), а посему их потребуется в нее загрузить. Сделать это можно четырьмя способами — вручную (наверное, имеется смысл прибегать к этому методу для добавления каких-то найденных уже опосля основного сбора ключей), а также три пакетных способа импорта ключей:
- в формате тхт — когда нужно импортировать просто список ключей (каждый на отдельной строке тхт файлика и с русской кодировкой определитесь заранее, чтобы кракозябры не получить).
- а также два варианта экселевского формата: с нужными вам в дальнейшем параметрами, либо с собранными сайтами из ТОП10 по каждому ключу. Последнее может ускорить процесс кластеризации, ибо программе KeyAssort не придется самой парсить выдачу для сбора эти данных. Однако, Урлы из ТОП10 должны быть свежими и точными (такой вариант списка можно получить, например, в Кейколлекторе).
Да, что я вам рассказываю — лучше один раз увидеть:
В любом случае, сначала не забудьте создать новый проект в том же самом меню «Файл», а уже потом только станет доступной функция импорта:
Давайте пробежимся по настройкам программы (благо их совсем немного), ибо для разных типов сайтов может оказаться оптимальным разный набор настроек. Открываете вкладку «Сервис» — «Настройки программы» и можно сразу переходить на вкладку «Кластеризация»:
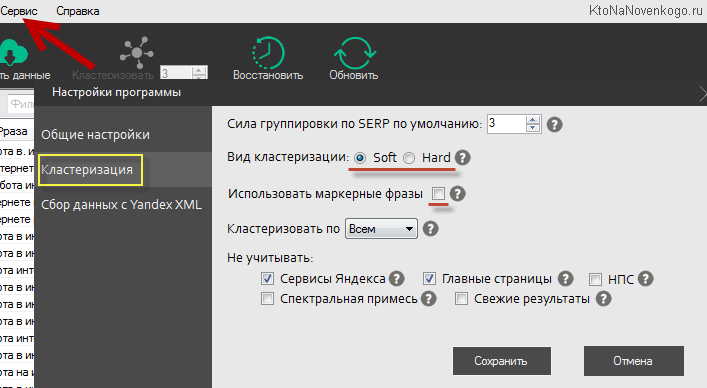
Тут самое важное — это, пожалуй, выбор необходимого вам вида кластеризации. В программе могут использоваться два принципа, по которым запросы объединяются в группы (кластеры) — жесткий и мягкий.
- Hard — все запросы попавшие в одну группу (пригодные для продвижения на одной странице) должны быть объединены на одной странице у необходимого числа конкурентов из Топа (это число задается в строке «сила группировки»).
- Soft — все запросы попавшие в одну группу будут частично встречаться на одной странице у нужного числа конкурентов и Топа (это число тоже задается в строке «сила группировки»).
Есть хорошая картинка наглядно все это иллюстрирующая:
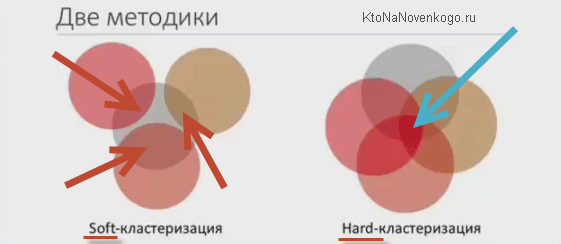
Если непонятно, то не берите в голову, ибо это просто объяснение принципа, а нам важна не теория, а практика, которая гласит, что:
- Hard кластеризацию лучше применять для коммерческих сайтов. Этот метод дает высокую точность, благодаря чему вероятность попадания в Топ объединенных на одной странице сайта запросов будет выше (при должном подходе к оптимизации текста и его продвижению), хотя самих запросов будет меньше в кластере, а значит самих кластеров больше (больше придется страниц создавать и продвигать).
- Soft кластеризацию имеет смысл использовать для информационных сайтов, ибо статьи будут получаться с высоким показателем полноты (будут способны дать ответ на ряд схожих по смыслу запросов пользователей), которая тоже учитывается в ранжировании. Да и самих страниц будет поменьше.
Еще одной важной, на мой взгляд, настройкой является галочка в поле «Использовать маркерные фразы». Зачем это может понадобиться? Давайте посмотрим.
Допустим, что у вас уже есть сайт, но страницы на нем были оптимизированы не под пул запросов, а под какой-то один, или же этот пул вы считаете недостаточно объемным. При этом вы всем сердцем хотите расширить семядро не только за счет добавления новых страниц, но и за счет совершенствования уже существующих (это все же проще в плане реализации). Значит нужно для каждой такой страниц добрать семядро «до полного».
Именно для этого и нужна эта настройка. После ее активации напротив каждой фразы в вашем списке запросов можно будет поставить галочку. Вам останется только отыскать те основные запросы, под которые вы уже оптимизировали существующие страницы своего сайта (по одному на страницу) и программа KeyAssort выстроит кластеры именно вокруг них. Собственно, все. Подробнее в этом видео:
Еще одна важная (для правильной работы программы) настройка живет на вкладке «Сбор данных с Яндекс XML». Что такое Яндекс XML и что такое лимиты вы можете прочитать в приведенной статье. Если вкратце, то Сеошники постоянно парсят выдачу Яндекса и выдачу Вордстата, создавая чрезмерную нагрузку на его мощности. Для защиты была внедрена капча, а также разработан спецдоступ по XML, где уже не будет вылезать капча и не будет происходить искажение данных по проверяемым ключам. Правда, число таких проверок в сутки будет строго ограничено.
От чего зависит число выделенных лимитов? От того, как Яндекс оценит ваши сайты добавленные в панель Вебмастера. Посмотреть лимиты можно перейдя по этой ссылке (находясь в том же браузере, где вы авторизованы в Я.Вебмастере). Например, у меня это выглядит так:
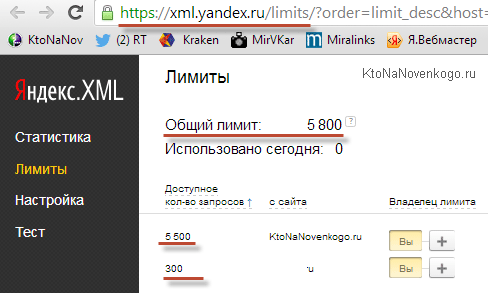
Там еще есть снизу график распределения лимитов по времени суток, что тоже важно. Если запросов нужно пробить много, а лимитов мало, то не проблема. Их можно докупить. Не у Яндекса, конечно же, напрямую, а у тех, у кого эти лимиты есть, но они им не нужны.
Механизм Яндекс XML позволяет проводить передачу лимитов, а биржи, подвязавшиеся быть посредниками, помогают все это автоматизировать. Например, на XMLProxy можно прикупить лимитов всего лишь по 5 рублей за 1000 запросов, что, согласитесь, совсем уж не дорого.
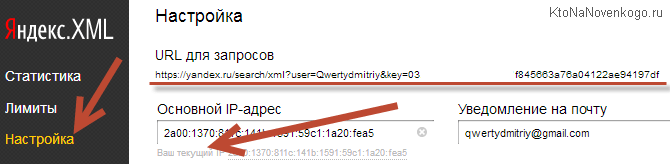
Но не суть важно, ибо купленные вами лимиты все равно ведь перетекут к вам на «счет», а вот чтобы их использовать в KeyAssort, нужно будет перейти на вкладку "Настройка« и скопировать длинную ссылку в поле „URL для запросов“ (не забудьте кликнуть по „Ваш текущий IP“ и нажать на кнопку „Сохранить“, чтобы привязать ключ к вашему компу):
После чего останется только вставить этот Урл в окно с настройками KeyAssort в поле „Урл для запросов“:
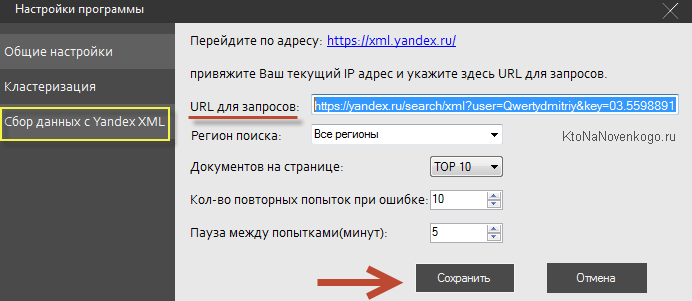
Собственно все, с настройками KeyAssort покончено — можно приступать к кластеризации семантического ядра.
Кластеризация ключевых фраз в KeyAssort
Итак, надеюсь, что вы все настроили (выбрали нужный тип кластеризации, подключили свои или покупные лимиты от Яндекс XML), разобрались со способами импорта списка с запросами, ну и успешно все это дело перенесли в КейАссорт. Что дальше? А дальше уж точно самое интересное — запуск сбора данных (Урлов сайтов из Топ10 по каждому запросу) и последующая кластеризация всего списка на основе этих данных и сделанных вами настроек.
Итак, для начала жмем на кнопку „Собрать данные“ и ожидаем от нескольких минут до нескольких часов, пока программа прошерстит Топы по всем запросам из списка (чем их больше, тем дольше ждать):
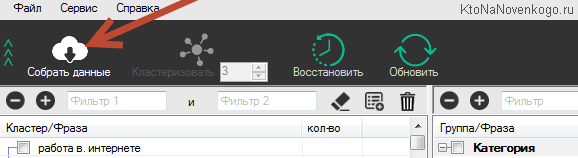
У меня на три сотни запросов (это маленькое ядро для серии статей про работу в интернете) ушло около минуты. После чего можно уже приступать непосредственно к кластеризации, становится доступна одноименная кнопка на панели инструментов KeyAssort. Процесс этот очень быстрый, и буквально через несколько секунд я получил целый набор калстеров (групп), оформленных в виде вложенных списков:
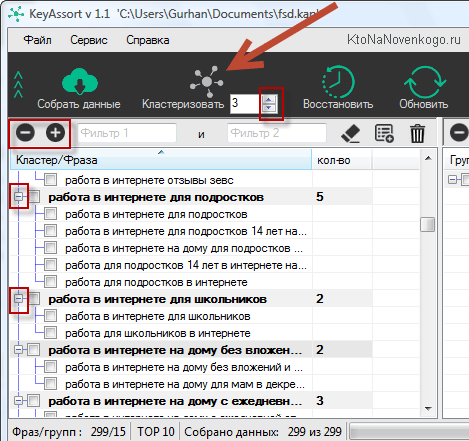
Подробнее об использовании интерфейса программы, а также про создание кластеров для уже существующих страниц сайта смотрите лучше в ролике, ибо так гораздо нагляднее:
Все, что хотели, то мы и получили, и заметьте — на полном автомате. Лепота.
Хотя, если вы создаете новый сайт, то кроме кластеризации очень важно бывает наметить будущую структуру сайта (определить разделы/категории и распределить по ним кластеры для будущих страниц). Как ни странно, но это вполне удобно делать именно в KeyAssort, но правда уже не в автоматическом режиме, а в ручном режиме. Как?
Проще опять же будет один раз увидеть — все верстается буквально на глазах простым перетаскиванием кластеров из левого окна программы в правое:
Если программу вы таки купили, то сможете экспортировать полученное семантическое ядро (а фактически структуру будущего сайта) в Эксель. Причем, на первой вкладке с запросами можно будет работать в виде единого списка, а на второй уже будет сохранена та структура, что вы настроили в KeyAssort. Весьма, весьма удобно.
Ну, как бы все. Готов обсудить и услышать ваше мнение по поводу сбора семядра для сайта.
SE Ranking — как автоматически проверять позиции и находить ошибки
Сегодня хочу поговорить про один из вариантов проверки позиций, занимаемых сайтом в той или иной поисковой системе, в том или ином регионе России или даже мира. Сайты бывают разные: коммерческие и региональные или же информационные, которым регион совсем не важен, но наш сегодняшний герой удовлетворит потребности их всех.
Не всегда и не у всех найдется время, чтобы тратить его на ручной съем позиций. К тому же, эта надоедливая капча... Удобно, когда статистика обновляется ежедневно и автоматически, когда можно видеть динамику по сравнению со вчерашним днем или месяцем, когда все это богатство можно повертеть в руках и посмотреть на графиках. В общем, пришло время сделать шаг вперед.

Кроме этого у них есть возможность использовать онлайн проверку позиций (имеется в арсенале даже приложение для мобильных устройств), а можно установить скрипт себе на сервер и вообще забыть про какие либо ограничения на количество и глубину пробиваемых позиций.
Причем позиции можно отслеживать не только в Яндексе и Гугле, но и в Бинге и в Яху, и для каждой поисковой системы можно будет выбрать любой доступный ей регион по всему рунету (вплоть до города) и даже миру (тем, кто делает сайты для буржунета, последнее будет актуально).
Возможности SE Ranking по съему позиций и их анализу
Что дает SE Ranking оптимизатору или же обычному владельцу сайта, который прикладывает усилия к его раскрутке и хочет своевременно отслеживать результаты предпринятых им действий:
- Выбор между двумя видами сервиса: онлайн и скрипт.
- В первом случае, заботу о смене IP адресов, при запросе к поисковым системам и практически мгновенной съеме позиций, берет на себя SE Ranking (используются его прокси и его сервера в облаке), но при этом существует предельное число запросов, которые можно будет пробивать таким образом.
- При использовании скрипта, который устанавливается на хостинг пользователя, все ограничения по количеству запросов, числу отслеживаемых сайтов и глубине их пробития снимаются, но вот прокси уже вам придется настраивать самим, да и нагрузку вы будете создавать при проверке позиций именно на сервер своего хостинга.
Большинство пользователей ориентированы на поисковые системы России, Украины, Беларуси (рунета), где правят бал Google и Яндекс, поэтому SE Ranking умеет снимать позиции отдельно для любого региона этих стран (вплоть до города) в любой из основных поисковых систем (Яндекс, Гугл, Бинг, Яху).
Но далеко не все сайты ориентированы на рунет, ибо в буржунете трафика намного больше, а значит больше возможностей для заработка, поэтому данный сервис позволяет пробивать, например, выдачу по Гуглу для любой страны мира.
- Мне понравилась возможность привязать Гугл Аналитикс к этому сервису и получать дополнительные полезные данные для анализа. Например, вместе с позициями по запросам (и их динамикой) показывается тот трафик, что можно будет привлечь именно в том регионе, который интересует пользователя.
- Для каждого запроса и выбранной поисковой системы SE Ranking показывает ссылку на релевантную страницу, что довольно удобно.
- Если у вас есть конкуренты, то актуально будет отслеживать и их позиции по тем же самым поисковым запросам, которые пробиваете вы сами. Можно будет отследить эффективность их действий направленных на продвижение и опираться на эту информацию при собственной раскрутке. Для каждого проекта можно добавить пяток сайтов конкурентов
- Упомянутый чуть выше Сайт-аудитор пробивает первые пятьдесят позиций в выдаче в поисках вашего ресурса. Иногда этого достаточно, а иногда нет. Данный сервис позволяет задавать глубина сбора позиции, которая варьируется вплоть до 300 в случае онлайн сервиса и до 1000 — в случае использования скрипта.
- На основе полученных данных, в SE Ranking можно будет вручную или автоматически формировать отчеты в формате PDF, CSV или Excel. Вы сами задаете, что именно должно быть в отчете, также имеется возможность добавить на них свое лого, что может быть актуально для SEO компании, передающей отчет клиенту. Им же будет полезна и возможность предоставления гостевого доступа к определенному проекту, чтобы заказчик мог сам просматривать позиции своего сайта (оценивать работу оптимизатора).
- Любой зарегистрировавшийся пользователь получает в свое распоряжение бесплатный доступ к сервису (по тарифному плану „лайт“) на две недели. Также имеет место схема возврата средств, в случае неудовлетворения возможностями сервиса в течении месяца.
Ну, и видеоролик поясняющий можно посмотреть:
Сразу хочу оговориться, что предоставляемые этим сервисом возможности не бесплатны. Собственно, было бы странно, если бы было наоборот. Хотя есть определенная халявка, которой можно воспользоваться — две недели бесплатного тестирования SE Ranking на минимальном тарифном плане. Вполне достаточно, на мой взгляд, чтобы понять его суть и оценить его полезность для решения ваших задач.
Чтобы получить эти самые халявные 14 дней, вам достаточно будет зарегистрироваться на сервисе — либо с помощью придумывания традиционных логина и пароля, либо посредством подключения ваших аккаунтов из социальных сетей:
В случае использования социалок вам нужно будет регистрироваться в SE Ranking в том же браузере, через который вы в эти социальные сети и ходите. Достаточно будет только принять то, что данный сервис получит доступ к адресу вашей почты и данным, которые вы посчитали нужным сообщить этой социалке. В общем-то, такой способ авторизации стал уже вполне привычным.
В случае регистрации путем придумывания логина и пароля — сразу предложат авторизоваться без ненужного подтверждения емайл адреса. В любом случае обрадуют тем, что вам доступен двухнедельный триал:
Если у вас вдруг интерфейс отобразился на незнакомом вам языке (для меня, например, они все не знакомы, кроме „великого и могучего“), то достаточно будет зайти в настройки (иконка с тремя полосками в правом верхнем углу) и на первой вкладке в самом низу выбрать нужный вам язык:
С другой стороны, если 50 пробиваемых запросов и 5 сайтов для проверки на бесплатном тарифе (двухнедельном) вам будет недостаточно для оценки работоспособности SE Ranking, то вы можете оплатить на месяц и более высоких тариф. При этом, если вас что-то не устроит, то денежку вам вернут:

Повысить свой тарифный план можно будет все в тех же самых настройках (три палочки, как у Гугл Хрома в правом верхнем углу) на вкладке „Онлайн-подписка“:
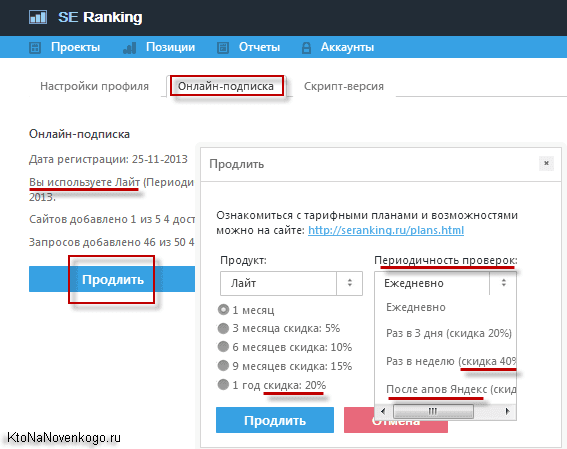
Обратите внимание, что стоимость тарифного плана зависит не только от периода, за который вы его оплачиваете (чем больше, тем дешевле), но и от того, как часто вы хотите снимать позиции по тем запросам, которые добавили.
Сервис по умолчанию это делает каждые сутки, но если вам так часто это делать не требуется, то вы можете получить очень существенную скидку при выборе трехдневного периода съема позиций (20 процентов), недельного (40 процентов скидка) или можно даже определять новые значения позиций только после очередного апдейта Яндекса (опять же 40% в минус, что приятно).
Ну, а пока писал этот абзац, я увидел, что у них имеется сообщение о проведении первой акции — дополнительные 20% скидки тем, кто станет подписчиками в их группах в социалках. В общем, еще чуток скидок и SE Ranking будет должен вам за использования их сервиса. Хотя, если серьезно, то сейчас самое время оплатить годовой абонемент, ибо получится совсем дешево.
Кроме этого есть возможность получить демо-доступ к админке SE Ranking, чтобы посмотреть имеющиеся там инструменты и оценить функционал. Но все же на своем сайте (сайтах) опробовать это дело будет гораздо интереснее, ибо будут пробиваться и анализироваться именно ваши запросы, по которым именно вы пытаетесь попасть в Топ и получать трафик, а не чьи-либо еще.
Добавляем сайты и запросы для проверки позиций через SE Ranking
Как я уже упоминал, интерфейс мне понравился. У них существует три языковых версии (русская, англицкая и немецкая) и во всяком случае к русской у меня никаких претензий нет. Для начала на главной странице вам предложат добавить свой первый сайт (одноименную кнопку вы найдете сразу в трех местах страницы, что не позволит вам потеряться).
Мастер добавления нового проекта в SE Ranking состоит из трех шагов:
- Сначала вам будет предложено указать название сайта и его Урл, а также согласиться с тем, что позиции начнут сниматься сразу по окончании добавления данного проекта. Если хотите это дело пока отложить, то выберите другой вариант из выпадающего списка „Сбор данных“.
На втором шаге вам будет предложено добавить поисковые запросы, позиции по которым вы хотите отслеживать для указанного на первом шаге сайта. В бесплатной триал версии можно добавить 50 запросов для пяти сайтов.
Вводятся они стандартно — по одному в каждой строке, ну а чуть позже вы получите возможность, при необходимости, разбить их на группы. Не забудьте нажать на кнопку „Добавить“, расположенную чуть ниже.
После этого вы увидите строчки с введенными ключевыми словами, которые можно будет перемещать мышью относительно друг друга, удалять лишние и редактировать набранные с ошибкой.
Можно будет их и группировать, с помощью кнопки „Перенести в“:
Кнопка „Далее“ перенесет вас в будущее.На третьем шаге вам будет предложено выбрать соответствующие пары: поисковая система — страна и регион в ней. Таких пар сервис SE Ranking позволяет добавить пять штук, например, Яндекс-Россия, Яндекс-Украина, Google-Россия и Гугл-Украина.
Для создания каждой из них нужно нажать на кнопку „Добавить“ и они будут показаны в приведенном чуть ниже списке. Также для каждой пары нужно выбрать регион, например, город, в котором вы продвигаетесь. Ну и, собственно, останется только нажать на кнопку „Завершить“.
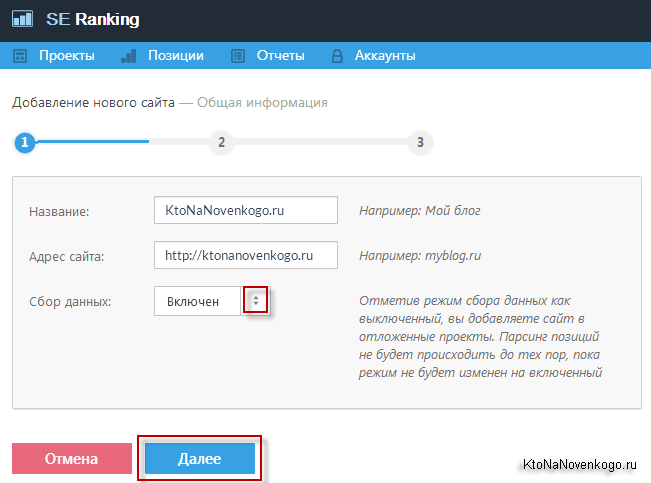
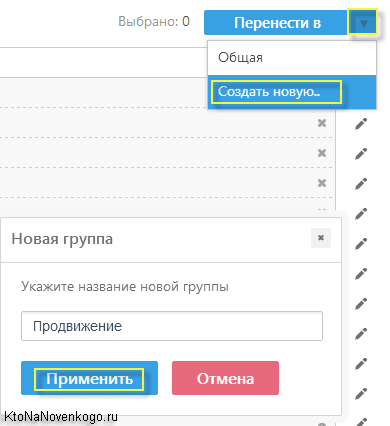
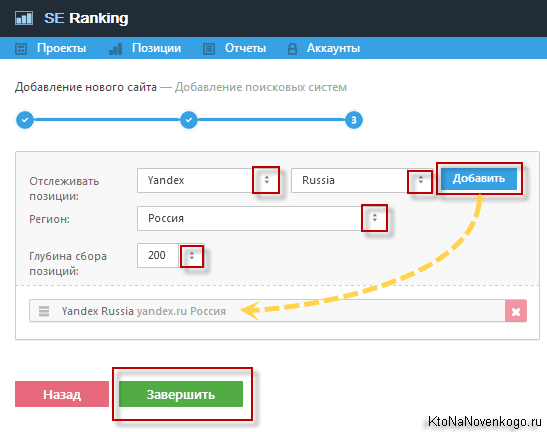
В принципе, через минуту-другую можно уже переходить на вкладку „Позиции“ и смотреть результаты съема. Если что-то захотите изменить в данном проекте, то на первой вкладке „Проекты“ будет возможность отредактировать только что введенные нами данные.
На вкладке „Позиции“ вам нужно будет в первую очередь выбрать тот сайт (проект), для которого хотите посмотреть статистику.
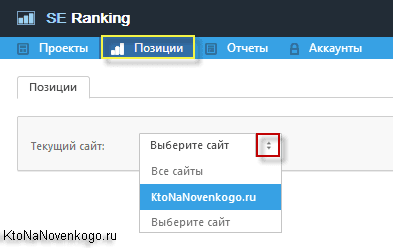
После этого в ваше распоряжение на первой вкладке будет предоставлен фильтр, с помощью которого можно задать диапазон дат, для которых будут отображаться снятые позиции, убрать, при желании, лишние поисковые системы, ограничить число запросов или выбрать конкретную группу, данные по которой вы хотели бы исследовать.
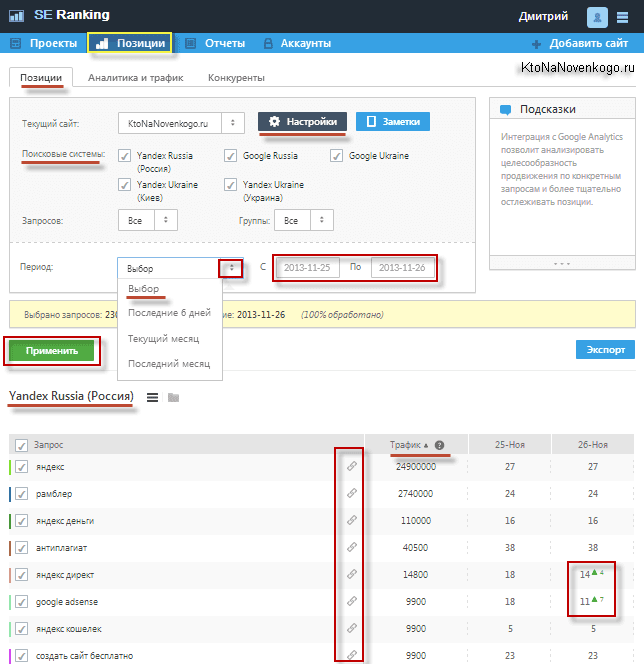
Кнопочка „Настройка“ позволит перейти к уже описанному окну настройки проекта (с тремя вкладками), а соседняя с ней кнопка позволит добавить к данному проекту комментарии, которые потом помогут освежить в памяти те действия, которые вы свершили в плане раскрутки сайта и которые привели к столь печальным (или, наоборот, радостным) событиям.
Подключение Аналитикса и конкурентов, создание отчетов
Данные по всем поисковым системам выводятся последовательно, поэтому прокрутите список до конца, чтобы с ними ознакомиться. Очень наглядно видна динамика процесса роста или спада позиций по разным запросам (зеленые и красные стрелочки), а также с помощью иконки в виде цепочки можно всегда посмотреть на тут страницу, которую данный поисковик посчитал наиболее релевантной данному ключевому слову.
При желании, вы можете экспортировать данные по позициям в файл с помощью соответствующей кнопки (адреса целевых страниц тоже копируются):
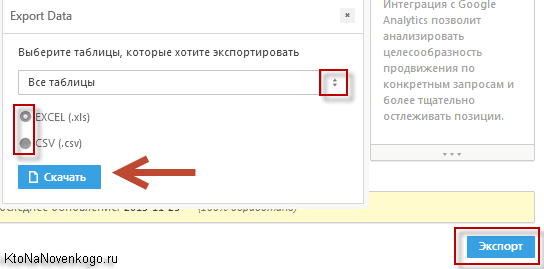
В колонке „Трафик“ на приведенном скриншоте можете видеть цифирьки, которые отображают не что иное, как количество посетителей в месяц, вводящих данный запрос в этой поисковой системе в выбранном вами регионе. Цифирьки эти довольно полезны, чтобы представлять потенциал продвижения сайта и попадания по этим ключам в Топ.
Правда для того, чтобы в этой колонке цифры отображались, вам нужно будет подключить свой аккаунт в Гугл Аналитиксе к сервису SE Ranking (если таковой счетчик был установлен у вас на сайте). Для этого достаточно всего лишь перейти на вкладку „Аналитика и трафик“ и нажать на соответствующую кнопку:
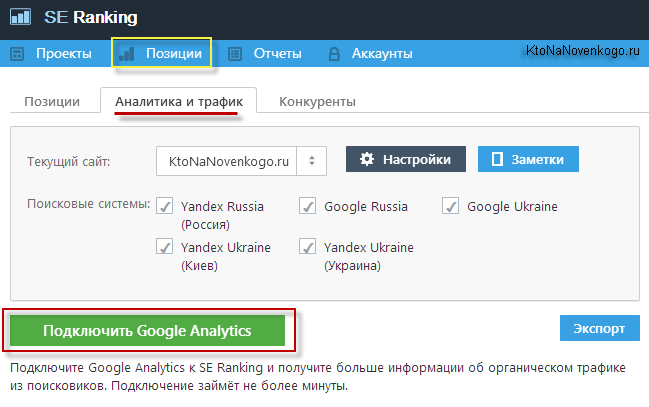
Вас попросят подтвердить полномочия приложения SE Ranking по доступу к вашей статистике посещений:
После чего вам сообщат об успешном подключении Гугл Аналитикса к вашему аккаунту и на этой же вкладке „Аналитика и трафик“ вы сможете увидеть много интересной статистики по ваших запросам, которая была извлечена из этого мега-счетчика.
Но даже если вы не имеете кода Аналитикса на сайте, то на этой вкладке все равно есть на что посмотреть, хотя бы взять „Обзор позиций“, где приведено число запросов в различных Топах (три, десять и т.д.):
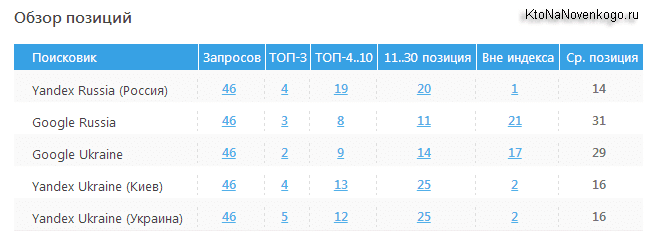
Ну, и стоит еще сказать про третью вкладку на странице „Позиции“, которая обзывается „Конкуренты“. Зачем она нужна? Допустим, что по тем же самым запросам у вас идет неравная борьба с рядом „коллег по цеху“ и вам важно будет отслеживать их успехи в этой войне.
Собственно, на этой вкладке вы как раз и можете добавить пяток самым завзятых „друзей“, чтобы SE Ranking снял позиции по тем же ключам и для них. Жмете на кнопку „Добавить конкурента“ и просто вводите его название и Урл сайта:
Через несколько минут система снимет позиции по ним и вы сможете посмотреть эти данные на этой же вкладке, нажимая на показанные иконки:
А чуть выше будет показан сравнительный график.
Давайте перейдем на вкладку „Отчеты“. Тут есть возможность создать отчет по требованию (ручной), либо запланировать их автоматическое создание. Нажав кнопку „Настройки“, вы можете добавить название своей СЕО компании (если вы таковой являетесь) и загрузить ее логотип, чтобы эти данные потом фигурировали на страницах отчета в формате PDF.
Для создания отчета задаете нужный период, выбираете, при необходимости, конкретную группу запросов, а так же ставите или снимаете галочку для вывода статистической информации со вкладки „Аналитика и трафик“ и решаете, будет ли отображаться количество просмотров выдачи по данным запросам за месяц.
Созданный отчет будет храниться на сервере SE Ranking и вы всегда сможете скачать его либо в PDF, либо в CSV.
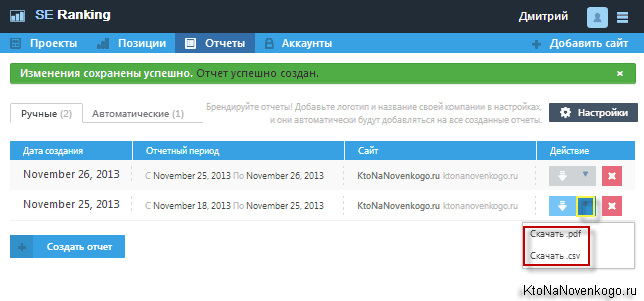
На вкладке „Аккаунты“ можете создать профиль для ваших клиентов или компаньонов.
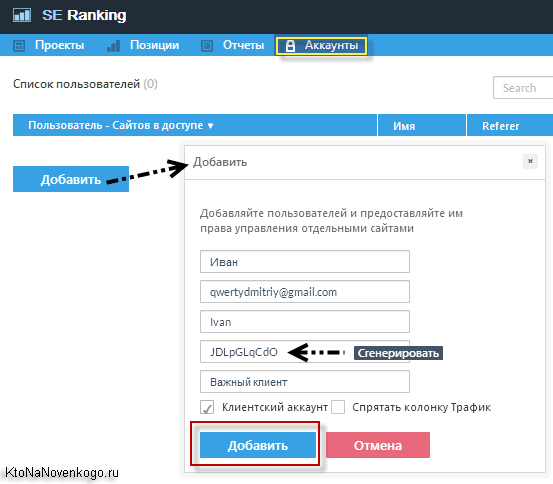
После этого вы сможете распределить, каким клиентам данные о позициях каких сайтов следует показывать:
Да, еще пару слов скажу про мобильное приложение SE Ranking. С одной стороны можно ведь просто зайти на их сайт, войти в свой аккаунт с мобильника и посмотреть то, что нужно — динамику изменения позиций после апдейта Яндекса или еще что.
С другой стороны, работа с сайтом через мобильник, например, в дороге может быть сложна в силу большого количества элементов управления, которые вам, по большому счету, для быстрого просмотра и не нужны. Вот тут, как мне кажется, мобильное приложение сильно выигрывает у сайта, пусть и оптимизированного под маленькие экраны.
Правда существует оно пока только для Ios (грозятся и под Андроид создать подобное). На мой Айпад оно прекрасно встало. Естественно, что сначала нужно будет авторизоваться:
Ну, а потом выбрать нужную поисковую систему и посмотреть последние изменения в динамике позиций ваших сайтов:
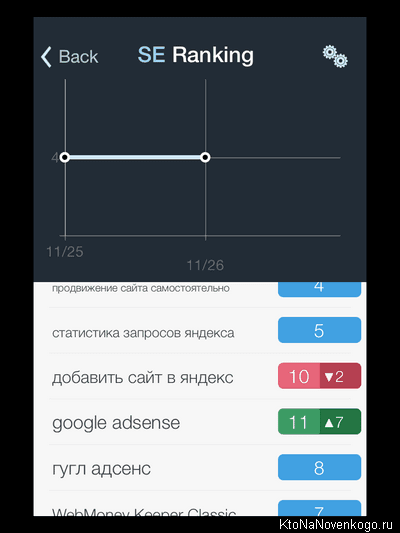
Скрипт-версия SE Ranking, тарифы на ее покупку и оплату онлайн проверок позиций (возможные скидки)
Судя по всему, скрипт предоставляет в ваше распоряжение тот же самый интерфейс, что и онлайн версия, но он не имеет ограничение на количество проверяемых поисковых запросов, в то время как даже на самом дорого тарифе онлайн-сервиса имеет место быть ограничение в 2500 запросов.
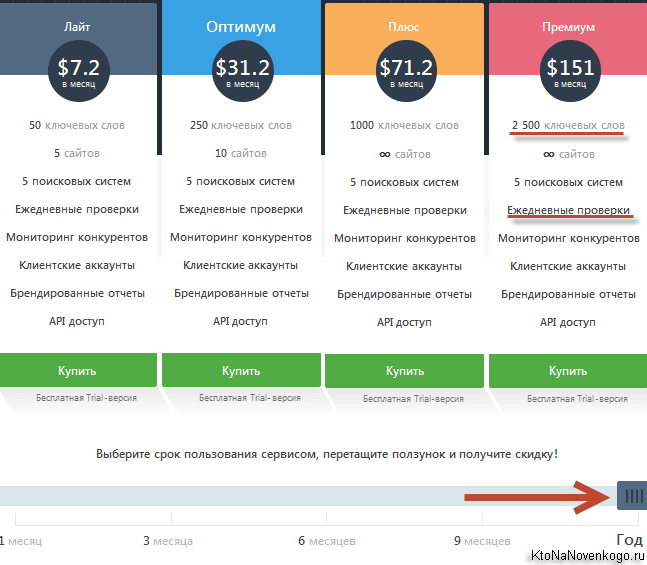
Внизу на скриншоте расположен движок срока оплаты, который я сдвинул на год, чтобы посмотреть минимальные тарифы. Тут еще нужно учесть, что, например, при снижении частоты проверки позиций до одного раза в неделю вы получите еще сорокапроцентную скидку (подробнее смотрите чуть выше по тексту), что позволит существенно снизить тарифы.
Кроме этого сейчас действует акция, по которой можно получить еще двадцать процентов скидки за вступление в группы SE Ranking в социалках. Поэтому минимальный тариф станет равен нескольким долларам в месяц, что совсем не обременительно даже для обычных вебмастеров, а не Сео компаний.
Кому-то этого количества запросов будет достаточно и он не хочет возиться с установкой скрипта и вероятным расширением возможностей хостинга, ибо съем большого числа позиций будет отъедать какие-то дополнительные ресурсы у сервера вашего хостера. Да и с прокси тоже придется повозиться, ибо с одного ip отправлять такое огромное количество запросов поисковики не позволят.
Но зато все эти трудности меркнут перед тем количеством ключевых слов, которое можно будет ежедневно пробивать. Вообще, презентация скрипта выглядит весьма заманчиво:

Имеется два варианта скрипта, первый из которых, наверное, рассчитан на обычных вебмастеров или оптимизаторов-фрилансеров, а второй — на Сео конторы (клиентские аккаунты доступны):
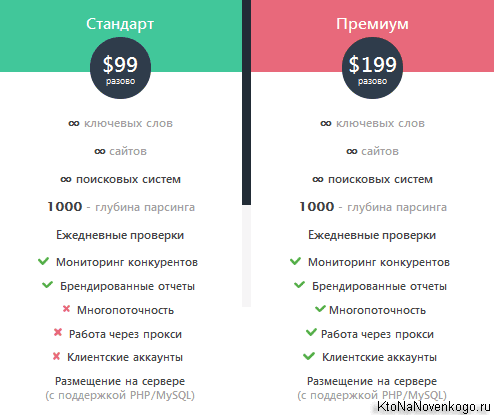
Разработчики обещают работоспособность скрипта SE Ranking на любых хостингах и серверах с поддержкой PHP и MySQL, что обнадеживает. Другое дело, что триала у скрипта нету, а хотелось бы его потестировать, ибо штука интересная.
Раз уж речь зашла об оплате скрипта или абонентской плате за автоматическое определение и проверку позиций в онлайн версии SE Ranking, то стоит упомянуть, что они используют не совсем обычную систему приема платежей под названием Avangate, которая позволяет производить оплату как кредитными картами, так и привычными Вебманями, Киви и Пайпалами (можно и банковским переводом):
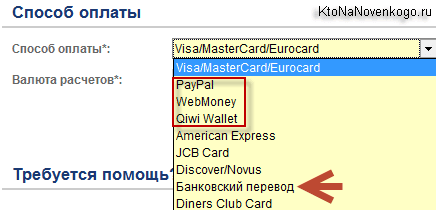
Для пользователя, как я понимаю, никаких дополнительных трат в виде комиссий это не повлечет, но зато гарантирует конфиденциальность передаваемых данных, например, при оплате все с тех же карточек. Похоже, что серьезная штука, хотя я о ней и слышу впервые.
Чуток про основной функционал сервиса — проверку позиций
Как я и анонсировал, в основном мы сегодня будем говорить про бесплатные возможности этого сервиса (которых раньше, если не брать в расчет бесплатный тестовый период, и не было вовсе), но все же для начала позволю вам вкратце напомнить, что он из себя представляет и какие услуги предоставляет. Основная услуга — это проверка позиций вашего сайта по заданным вами поисковым запросам в основных поисковых системах рунета. В связи с тем, что сейчас во всю используется региональность, то снимать позиции можно будет с точностью до города (если вам, конечно же, это будет нужно).
Чуть выше я довольно подробно описал возможности SE Ranking и варианты работы с ним: можно использовать либо онлайн-сервис, оплачивая количество проверяемых запросов, либо купить скрипт и поставить его к себе на сервер, полностью избавившись от каких-либо ограничений. Если со скриптом все понятно (заплатили около девяти тысяч рублей и пользуйтесь), то в плане тарифов онлайн-сервиса есть некое разделение:
- Вы можете выбрать помесячную абонентскую плату по одному из тарифных планов (цена зависит от числа проверяемых запросов и количества добавляемых сайтов):
Сейчас, кстати, можно в каждом тарифе менять число запросов с помощью выпадающего списка, что еще больше повышает гибкость. Обратите внимание на ползунок с количеством месяцев, расположенный под этой тарифной таблицей. Сравните цены при выборе оплаты за месяц и за год, чтобы почувствовать разницу (скидка довольно приличная получается). Да, еще и цены для рунета теперь стали в рублях отображаться, что опять же плюс при текущем нестабильном курсе.
Кстати говоря, рамочкой на предыдущем скриншоте я как раз и выделил те бесплатные опции, которые стали сейчас доступны всем в SE Ranking, но о них чуть ниже мы поговорим.
- Либо выбрать вариант оплаты за каждую проведенную сервисом проверку. Тарифы тут в буквальном смысле копеечные и зависят от глубины проверки выдачи (среди скольких первых сайтов найденных поисковиком по данному запросу сервис будет отыскивать ваш).
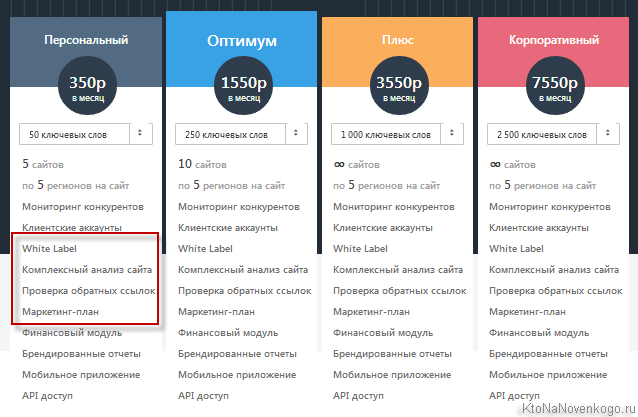

Какой же вариант лучше выбрать? Тут все зависит от числа регионов и поисковых систем, по которым вы хотите проводить проверку. Если их больше пяти, то выбирайте вариант с абонентской платой, ибо в нем учитывается не число проверок, а число запросов.

Всю остальную информацию по работе с сервисом SE Ranking вы можете почерпнуть из приведенной по ссылке статьи.
Если попробовать тезисно выразить основные особенности SE Ranking, то получится, наверное, примерно так:
- Возможна настройка различной глубина и периодичности проверки (например, только после очередного апдейта Яндекса), что может существенно снизить расходы, например тем, кто продвигает свои собственные проекты.
- В течение 14 дней доступен бесплатный доступ, необходимо только зарегистрироваться.
- Кроме уже существующей с момента открытия сервиса возможности подключение Аналитикса (для анализа трафика по продвигаемым запросам), теперь то же самое можно проделать и с Яндекс Метрикой (если Аналитикс у вас на сайте не установлен). Это позволит не просто „тупо“ отслеживать позиции по вашим запросам, но и выявлять, например, среди них пустышки, которые трафика не приносят. Посмотреть это все можно, перейдя в „Позиции“ — „Анализ трафика“ — „Трафик“:
Ну, и плюс вся остальная статистика вашего сайта будет доступна в этом же интерфейсе, что довольно-таки удобно. - В системе имеет место быть сохранение релевантных Урлов (адресов страниц вашего сайта, которые данной поисковой системой были признаны наиболее подходящими для ответа на данный запрос). Если вдруг произойдет смена такой страницы (поисковики — капризные создания), то SE Ranking вам об этом просигналит, чтобы вы срочно принимали меры, ибо новая страница может быть не готова для приема посетителей по данному запросу.
- За последний месяц система сохраняет поисковую выдачу и вы можете, например, посмотреть как менялось положение сайтов (не только вашего) в ней за последнее время. Иногда это бывает полезно.
- SE Ranking рассчитывает такую штуку, как видимость сайтов. По сути, он берет в расчет все позиции занимаемые вами по продвигаемым запросам, но соотносит их с частотностью этих самых запросов. Таким образом, по значению видимости вы четко можете отслеживать успешность продвижения, ибо зачастую массовый подъем НЧ может создавать ложное впечатление роста, когда СЧ и ВЧ стоят на месте или падают. Видимость, в этом плане, все расставит по местам и вы поймете вектор движения, в том числе и по отношению к вашим конкурентам, для которых этот показатель тоже будет рассчитываться (вкладка „Конкуренты“ — из выпадающего списка „Видимость“.
- Лично мне нравятся в системе довольно-таки наглядные графики и интуитивно понятный интерфейс (не перегруженный). В нем довольно сложно заблудиться, а это совсем немаловажно.
- Можно настроить создание автоматических отчетов в форматах pdf, xls, csv, html, например, для показа их вашим клиентам, чьи сайты вы продвигате. При желании процесс создания отчета можно будет инициировать вручную.
- В добавок к мобильному приложению для iOS появилась еще и версия для Андроида. Оба они позволяют при минимуме телодвижений оперативно (на ходу) отслеживать положение продвигаемых сайтов.
- Расширенный мониторинг конкурентов, который подразумевает отслеживание конкурентов по тем же запросам, что и ваш собственный сайт (информация о Топ-10 по каждому запросу), а также общий список всех конкурентов с возможностью просмотра их параметров и данных о посещаемости.
- Очень высокая скорость сбора данных даже при большом количестве запросов (мои 700 запросов буквально за минуту-две снимаются). Ну, и судя по отзывам специалистов — высокая точность съема (самому лень проверять было).
- Ну, как бы еще много всего, но уж вы это сами смотрите либо в демо-режиме, либо заказав бесплатное двухнедельное тестирование сервиса. При этом функционал постоянно дорабатывается, и разработчики по просьбам пользователей могут добавить любую функцию. Да, еще для удобства работы может быть создано неограниченное количество аккаунтов с доступом к отдельным проектам (например, для клиентов, чьи сайты вы продвигаете).
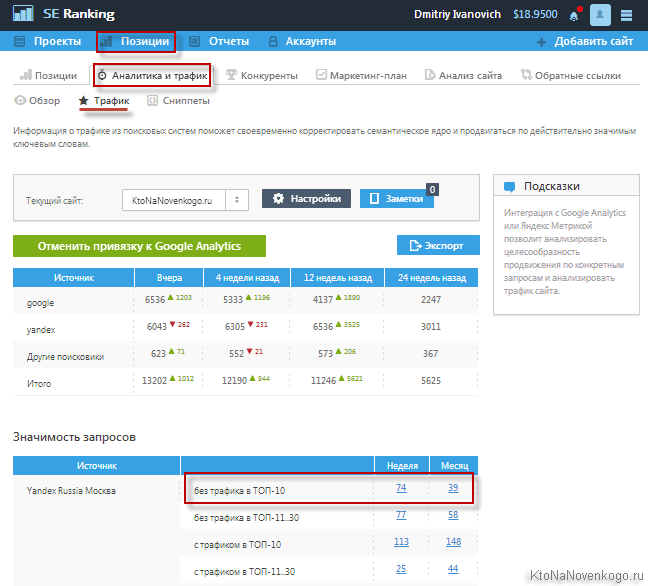
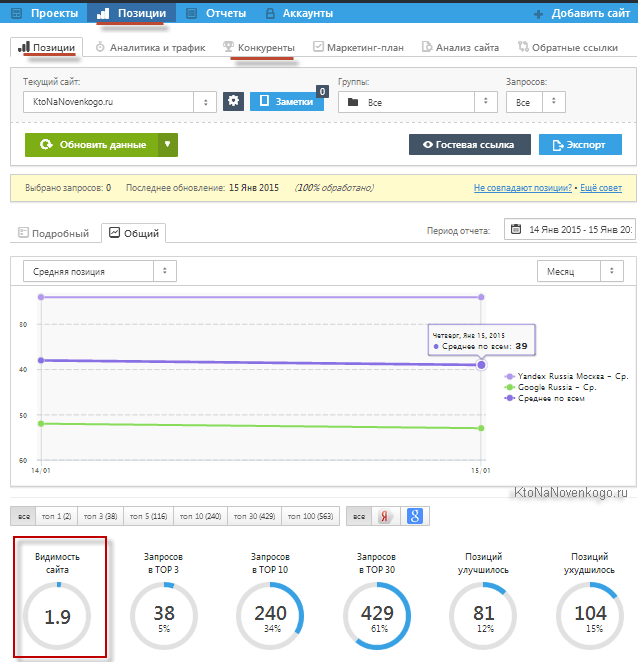
Бесплатный экспресс-анализ всех страниц вашего сайта
Первый из бесплатных сервисов, о которых я хотел бы упомянуть — это экспресс-анализ сайта. Причем анализ осуществляется не просто для домена, как это происходит в большинстве бесплатных сервисов, а для всех страниц сайта. SE Ranking лично мне очень понравился своей наглядностью, удобством и скоростью работы. Как-то я говорил про похожий сервис от Мегиндекса, но текущий продукт мне понравился больше.
Как провести анализ своего сайта? Достаточно будет просто создать аккаунт в SE Ranking, после чего нажать на открывшейся странице на кнопку „Добавить сайт“. В случае отображения страницы не на русском, нужно будет зайти в настройки (иконка с тремя полосками в правом верхнем углу) и на первой вкладке в самом низу выбрать нужный вам язык.
При добавлении запросов (в триальном режиме их можно будет добавить до 50 штук) вам предложат подключить Аналитикс или Метрику к аккаунту, что желательно будет сделать, ибо оттуда вам может быть предложено добавить наиболее перспективные для отслеживания запросы.

Собственно, после завершения процесса добавления сайта и будет активировано проведение экспресс-анализа. Причем, вам на почту придет письмо с краткими результатами этого анализа и сообщения о выявленных критических и особо важных недочетах. Несмотря на скорость проведения анализ получается довольно глубоким и затрагивает многие области, влияющие на успех продвижения:
- В начале как обычно приводится информация касаемо домена (главной страницы), а также указывается общая оценка вашего сайта и приводится количество просканированных страниц и найденных существенных недочетов.
- Технический аудит — проверяется склейка зеркал с WWW и слешем на конце (очень важно для успеха продвижения), а также отсутствие дублей главной страницы (с index.php, index.html, index.htm и тд.). Еще проверяется работа ЧПУ и правильность файлов роботс и карты сайта. Ну, и наличие флеша и фреймов на сайте. У меня их нашли (видимо баннеры и видеоролики, которые подключаются через айфрейм).
- Анализ мета-тегов — наличие title и description, а также их соответствие оптимальным кондициям по длине. Еще очень важным параметром является наличие дублирования тайтлов (заголовков страниц). От этого нужно избавляться. У меня раньше их было много (в основном страницы создаваемые при пагинации, но я их закрыл от индексации в роботсе, добавив директиву
Disallow: */page/).
Однако, SE Ranking нашел у меня дублированный тайтл у статьи и рубрики (они одинаково назывались), а также у карты сайта созданной на основе Sitemap Generator, которая разбивалась на страницы. Пришлось и это дело почикать в роботсе. - Анализ страниц — проверка кодов ответов сервера при обращении к страницам и наличия тега rel=»canonical", который является очень важным инструментом для борьбы с частичным и полным дублированием контента.
- Анализ ссылок и перелинковки — тут вы увидите число битых ссылок (с ошибкой 4** — я их как раз недавно пофиксил), число ссылок закрытых в rel="nofollow", а также число страниц с количеством исходящих ссылок более сотни (у меня одна такая нашлась — «Проверка сайта»).Ну, и еще ссылки без анкора (у меня это кнопочки социалок).
Причем все это можно детализировать, нажав на ссылку «Посмотреть ссылки». Например, в случае битых ссылок можно будет найти страницы сайта, где они проставлены.
- Анализ текстов на страницах на предмет их дублирования, также поиск страниц с малым количеством контента и не заполненным или отсутствующим тегом заголовка H1. Тоже дело важное, как впрочем и все остальное в современном Сео.
- Оценка юзабилити — наличие фавикона, страницы 404, проверка скорости сайта, валидация (Html и CSS кода) и т.п.
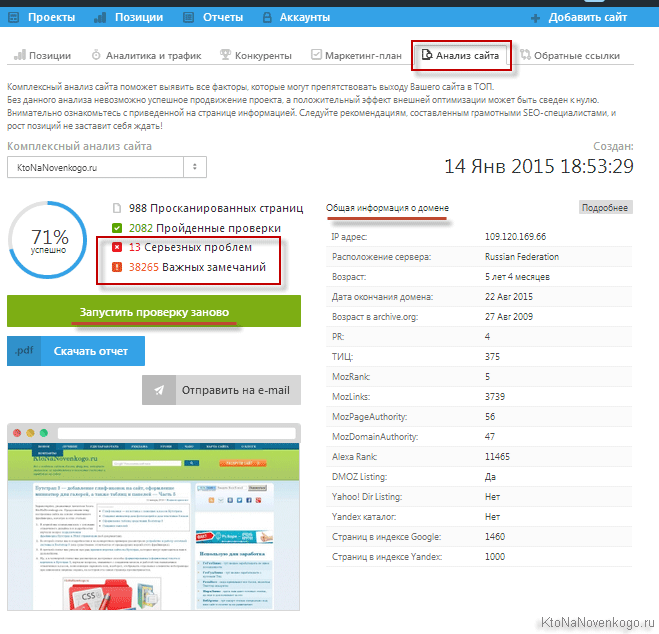
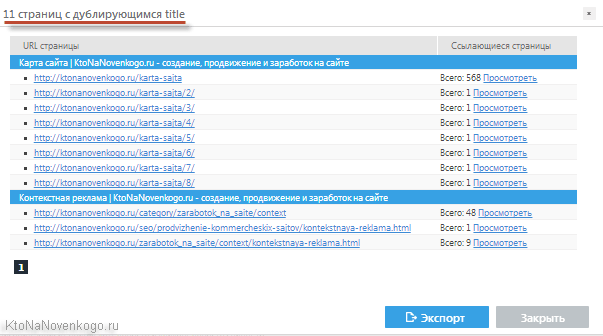
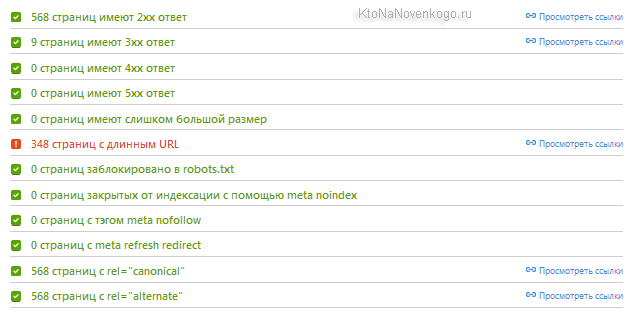
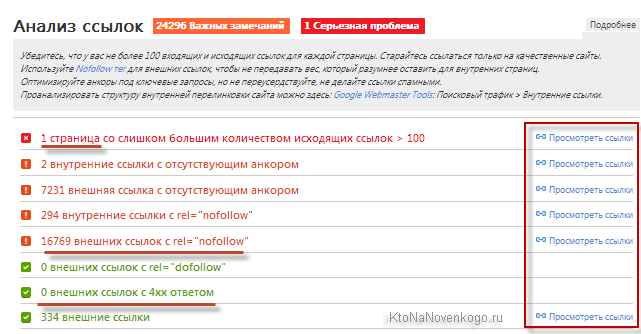

Еще раз хочу подчеркнуть, что сервис анализирует все страницы сайта, и все найденные ошибки и критические места можно будет детально рассмотреть и поправить. Да и просто кинуть взгляд на общее положение дел у вас на сайте всегда бывает полезно, ибо зачастую упущенные мелочи как раз и являются камнем преткновения для успешного продвижения и покорения Топов.
Мониторинг обратных ссылок в SE Ranking
Анализ обратных ссылок — прикольная возможность. По сути, вы можете бесплатно проанализировать 1000 обратных ссылок, которые имеются у вашего сайта. Идет проверка на их наличие и на показатели страницы, с которой эта ссылка проставлена.
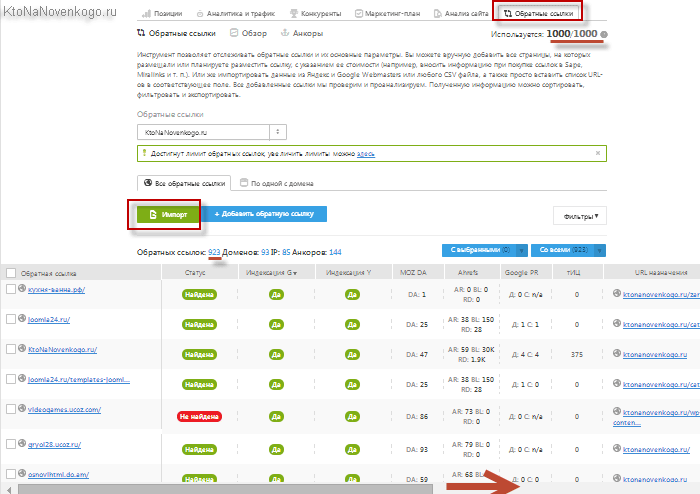
Под спойлером «Фильтры» кроется масса инструментов для отбора интересных вам доноров. Сами обратные ссылки вы можете ввести вручную или списком (например, из Яндекс или Гугл Вебмастеров, как будет показано ниже). Параметры по донорам вытягивают из Моза (бывший СеоМоз), из Ахрефса и прочих авторитетных источников.
Сервис, на мой взгляд, можно использовать для:
- Отслеживания судьбы купленных вами ссылок (например, ГоГетЛинкс, РотаПост или WebArtex ) или полученных по обмену. Т.е. мониторить их на наличие и на предмет авторитетности донора.
- Ну, а также можно использовать его для общей оценки вашей ссылочной массы. Для этого можно будет вытянуть все обратные ссылки, которые собрали Гугл и Яндекс Вебмастеры за время их наблюдения за вашим сайтом. Кто же лучше самих поисковиков может рассказать о ваших бэклинках? Как вытянуть эти ссылки? Довольно просто.
Например, в панели Яндекса для вебмастеров достаточно будет пройти по этому пути и скачать архив со списком бэклинков: «Индексирование сайта» — «Входящие ссылки» — «Загрузить данные»
Не наблюдаете ссылки для скачивания? Не беда. Пройдите по приведенной выше ссылке и ознакомьтесь с решением данной проблемы.
В панели Google Webmaster Tools все примерно то же самое, но путь будет следующим:
После чего можно будет импортировать скачанный список с помощью соответствующей кнопочки. Кстати, в случае Гугл Вебмастера можно поступить проще — связать его аккаунт с SE Ranking с помощью кнопочки «Подключить». А вот для Яндекса такой возможности не предусмотрено — только добавление заранее скачанного архива с обратными ссылками.
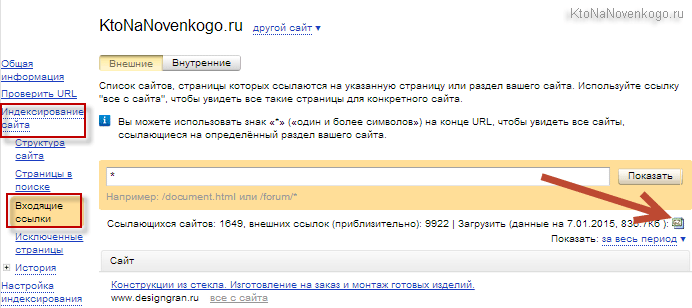
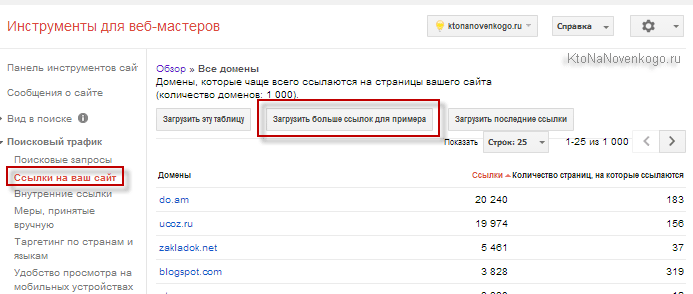
Собственно, добавление этого сервиса (пусть и частично бесплатного, ибо за цифры сверх 1000 бэков придется доплачивать) позволяет еще больше углубить понимание того, в правильном ли направлении вы ведете продвижение (насколько качественные ссылки закупаете и контролировать их наличие).
Маркетинг-план вашего продвижения (пошаговый чек-лист SEO-оптимизации сайта)
Еще более интересная и оригинальная задумка для подобного рода сервисов. Дело в том, что далеко не все вебмастера имеют представление о том, какие шаги должны быть выполнены для достижения поставленной цели — покорения Топов по «вкусным» запросам. Ну, как бы про ссылки все слышали, а вот что кроме этого и в какой последовательности выполнять? Да, даже если вы сами не продвигаете, то все равно должны держать руку на пульсе и контролировать процесс.
Мне, например, часто задают вопрос по поводу последовательности шагов. А объяснить это проще всего именно с помощью чек-листа, когда есть список дел, которые требуется выполнять в заданной последовательности, проставляя галочки напротив уже проделанных операций и отслеживая процент выполненной работы. Это дисциплинирует, помогает не пропустить что-то важное при оптимизации сайта и в то же время стимулирует к достижению ста процентов от намеченного. Это именно маркетинг-план, которому нужно следовать, либо следить, чтобы следовали нанятые вами исполнители.
Живет он на одноименной вкладке вашего аккаунта в SE Ranking:
Пунктов (шагов) много и все они разбиты на те же разделы, что мы могли наблюдать чуть выше при просмотре страницы с экспресс-анализом сайта. Однако, авторы не отделались просто наименованием задачи. Они снабдили их поясняющей информацией под спойлерами «Подробнее» и ссылками на статьи по данной тематике. Очень комплексный подход, который я тоже хотел бы реализовать у себя на блоге, но пока вот руки не доходят (да и глаза боятся объема работы).
Молодцы разработчики, теперь буду на этот чек-лист отсылать тех, кто обращается ко мне по вопросам о шагах, которые нужно предпринимать для продвижения и оптимизации сайта. Да и самому надо будет пробежаться по всем этим пунктам — наверняка что-нибудь было упущено при моем довольно-таки не системном подходе к продвижению.
White Label — для ваших клиентов SE Ranking будет выглядеть, как проект вашей собственной разработки
Еще одна неординарная опция, которая предоставляется бесплатно всем пользователям оплатившим любой тариф. Заинтересует она, наверное, в первую очередь владельцев SEO-контор и фрилансеров, занимающихся продвижением и оптимизацией сайтов. White Label позволяет придать вам солидности в глазах ваших клиентов, ибо они будут думать, что вы используете свой фирменный софт, а не аутсорсите услугу в SE Ranking (читайте что такое аутсорсинг?).
Как вы наверное догадались, имеется возможность настроить интерфейс онлайн-сервиса так, что в шапке и футере будут отображаться данные вашей компании, на странице входа (где пароль вводят) тоже будет ваш лого висеть, да и письма будут приходить с почты вашего домена (и опять же с вашим лого, а не с лого SE Ranking), ну и, наконец, даже в адресной строке ваши клиенты при работе с сервисом (когда вы им предоставите доступ) будут видеть что-то вида seo.ktonanovenkogo.ru или top.ktonanovenkogo.ru (не важно, ибо это будет поддомен вашего домена), что вызовет у клиента полную уверенность, что это вы создали это замечательное ПО.
В общем, White Label позволяет по полной программе пустить пыль в глаза клиенту (причем даже не надо ничего говорить, ибо он и сам все увидит и оценит). При этом каких-то особых усилий реализация всего выше описанного не займет. Просто переходите на вкладку «Настройки»- «Персонализация сервиса» и буквально на нескольких экранах вам предлагают настроить все, о чем я говорил выше:
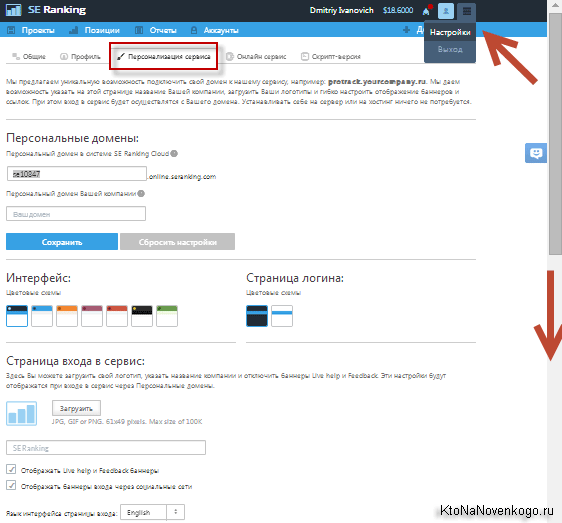
Проще, пожалуй, что и не придумаешь.
Подытоживая хочу сказать, что в SE Ranking очень серьезно за этот год поработали над своим проектом (и похоже продолжают над ним активнейшим образом работать). Добавилось много того, что делает сервис более удобным и функциональным, чем у конкурентов. Ну и, конечно же, бесплатный аудит, мониторинг обратных ссылок и SEO чек-лист делают его очень привлекательным для гораздо большего числа посетителей, часть из которых со временем станет клиентами.
В общем, предлагаю зарегистрироваться и потестировать все собственноручно, ибо лучше один раз попробовать, чем сто раз об этом прочитать...
Модуль «Позиции», или проверка позиций по запросам
SE Ranking предлагает создать проект в разделе “Проекты”. Здесь нужно указать название, адрес сайта, глубину сбора позиций, периодичность отчетов и прочее. Далее в разделе “Позиции” необходимо выбрать созданный проект и добавить запросы для анализа и отслеживания.
Удобно, что в рамках одного проекта можно смотреть позиции по разным странам и городам. До недавних пор проверять их возможно было в поисковых системах Google, Yandex, Yandex Mobile, Yahoo, Bing. Сейчас подключили еще мониторинг позиций в Youtube, Google Maps и Google Mobile. В ближайшее время, как сказал саппорт, подключат и Амазон.

*при клике по картинке она откроется в полный размер в новом окне
Целевая страница. В процессе создания проекта оптимизатор предоставляет список запросов, по которым нужно вести отслеживание. Задавать для них конкретные URL сервис SE Ranking не рекомендует. Он автоматически определяет, какие страницы по каким запросам ранжируются. Если целевая страница в выдаче изменяется, система уведомляет об этом.
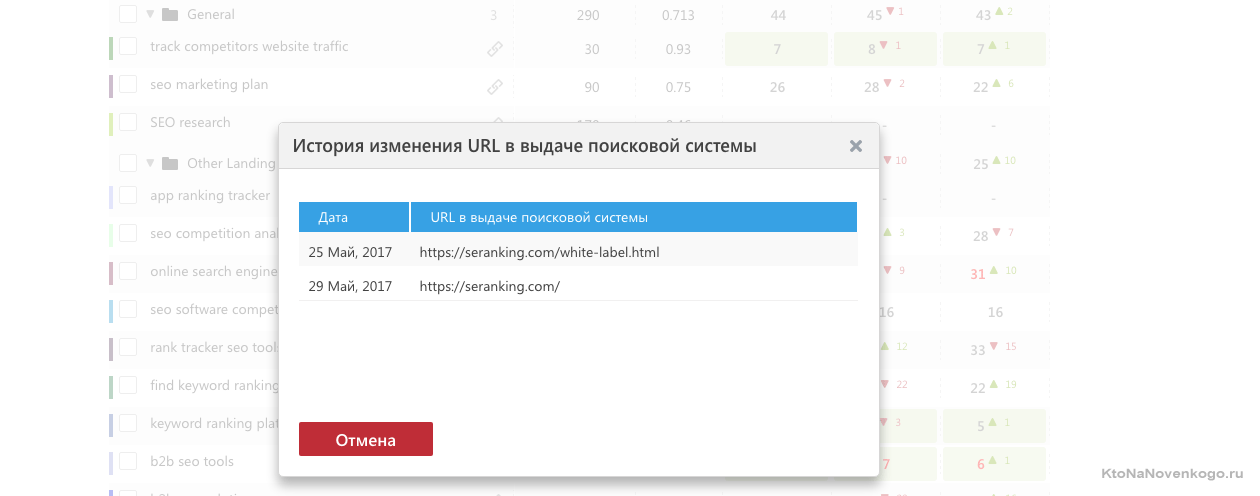
*при клике по картинке она откроется в полный размер в новом окне
Если нужно задать конкретный URL, то сделать это можно в любой момент, поменяв настройки проекта.
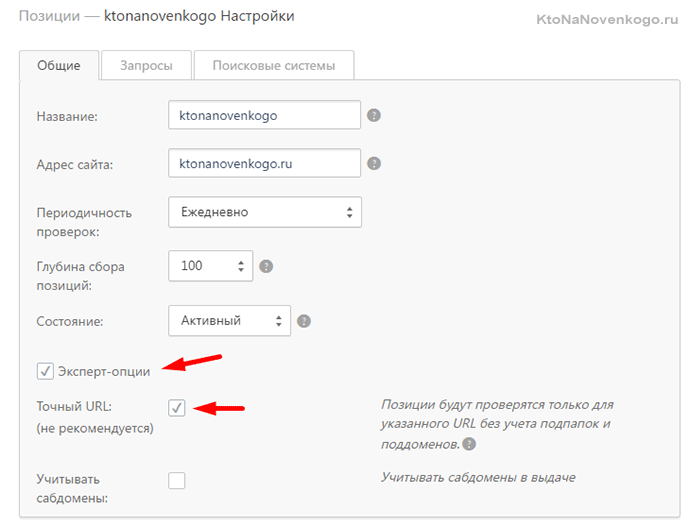
Или просто кликом по нужному запросу обозначить целевую страницу.
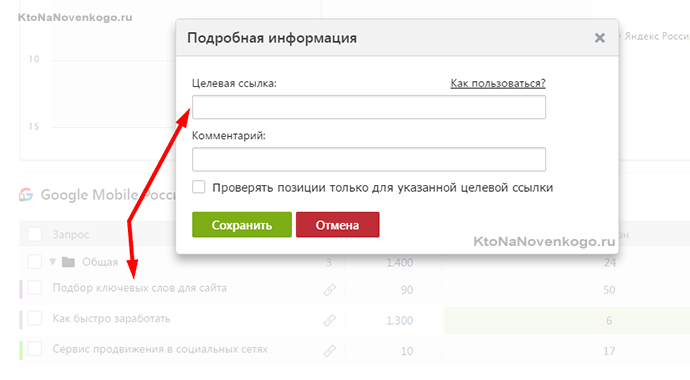
В рамках проекта запросы легко группируются в отдельные папки. Например, вы можете задать группы по частотности – ВЧ, СЧ и НЧ, по тематикам и любым другим критериям.
Статистика представлена в виде таблиц с настраиваемыми столбцами и в виде графиков, на которых наглядно показана средняя позиция запроса, прогноз трафика, видимость сайта и процент запросов в ТОП-10. Можно фильтровать статистику по временным интервалам. Тут же можно добавить до пяти конкурирующих проектов, чтобы в режиме реального времени анализировать их позиции по тем же ключевым словам, поисковым системам и регионам, по которым отслеживается и ваш сайт.
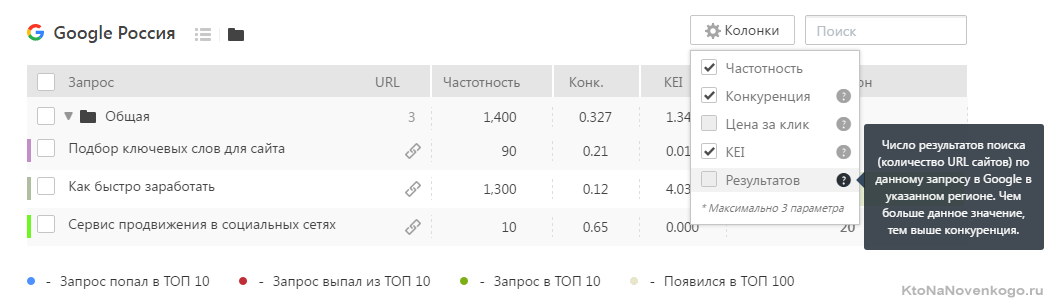
*при клике по картинке она откроется в полный размер в новом окне
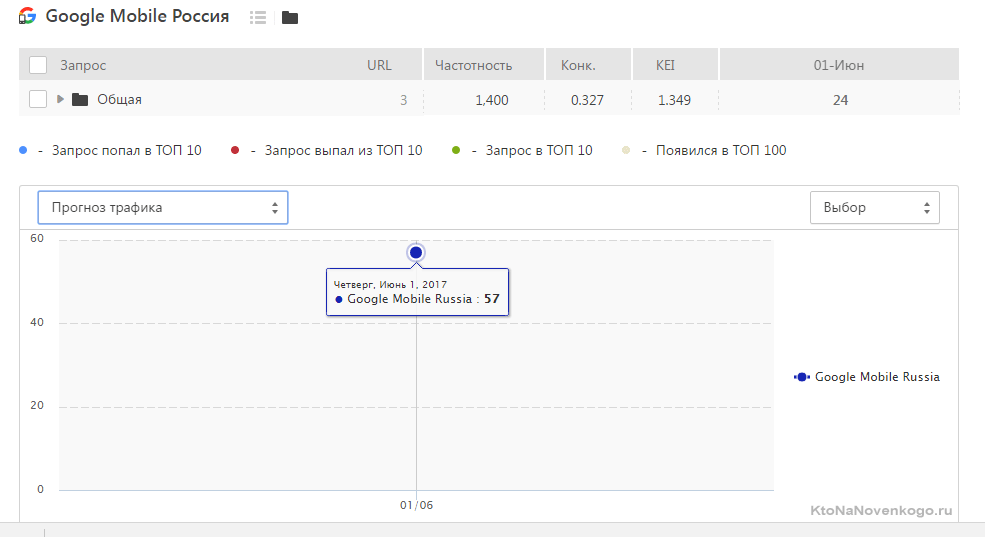
*при клике по картинке она откроется в полный размер в новом окне
Другие полезные опции в рамках инструмента:
- Возможность сравнения данных по двум датам;
- Просмотр динамики средней позиции;
- Прогноз трафика по запросам;
- Видимость запросов в поисковых системах;
- Сравнение позиций запросов в поисковиках.
SEO/PPC Анализ конкурентов
Анализ конкурентов SEO/PPC — это инструмент, который позволяет следить за позициями конкурентов в органическом поиске и в контекстной рекламе.
Доступна подробная статистика по запросам конкурентов в органике с динамикой их роста/падения в выдаче. Просто введите адрес конкурента или ключевую фразу, чтобы собрать данные по имеющимся соперникам.
*при клике по картинке она откроется в полный размер в новом окне
В разделе анализа платной выдачи можно просматривать, какие объявления размещают конкуренты в контекстной рекламе, сколько их по каждому ключевому запросу, на каких позициях находятся. В системе также есть архив предыдущих кампаний в контекстной рекламе.
*при клике по картинке она откроется в полный размер в новом окне
Этот инструментарий можно использовать не только для поиска и аналитики конкурентов, но и для подбора семантики. В разделе «Анализ ключевых слов – Похожие ключевые слова» можно просмотреть данные по подобным запросам, включая частотность, количество сайтов в выдаче, конкуренцию и прочее. В SE Ranking собрана самая большая база ключевиков в СНГ. Для тех, кто двигается “на запад” есть большие базы для анализа конкурентов во Франции, Италии, Канаде, Испании, США, Нидерландах, Великобритании, Дании.
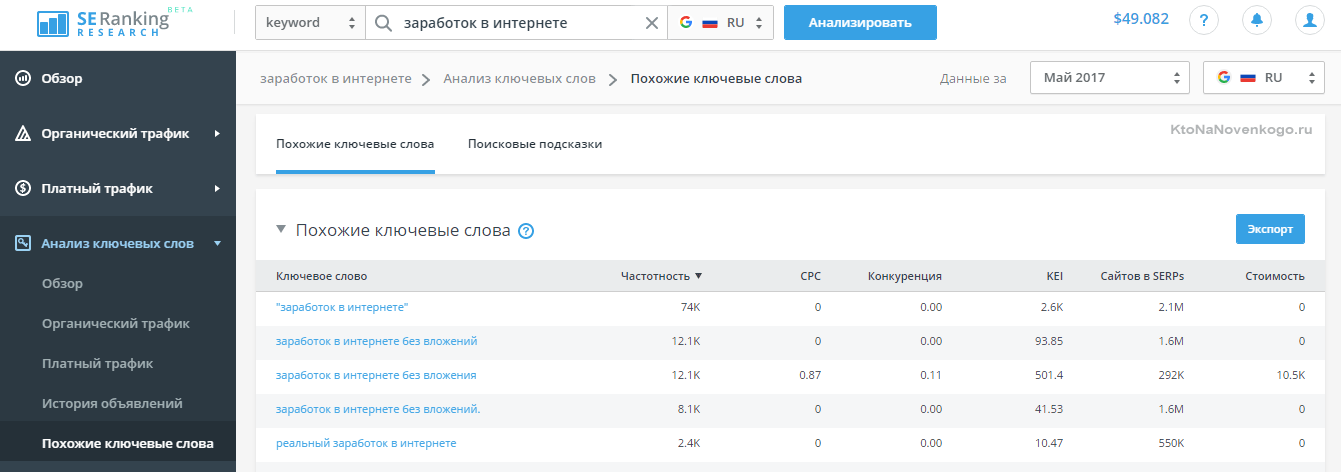
*при клике по картинке она откроется в полный размер в новом окне
SEO аудит страницы
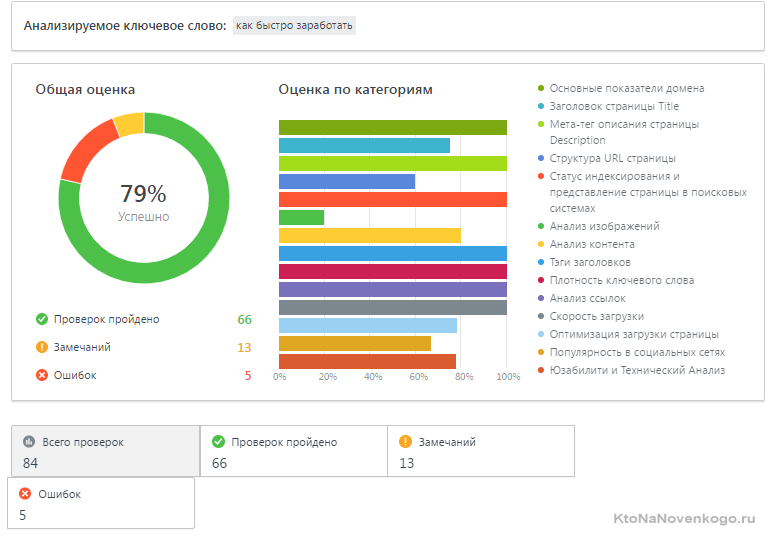
*при клике по картинке она откроется в полный размер в новом окне
Cервис создаст комплексный отчет об ошибках, проведет подробный SEO аудит страницы с точными данными. Для этого нужно указать URL страницы и ключевик, под который она заточена.
К анализируемой странице прилагается перечень рекомендаций, который базируется на актуальных требованиях поисковых систем. Специалисты SE Ranking следят за изменениями алгоритмов ПС и постоянно добавляют новые или убирают неактуальные пункты из аудита.

*при клике по картинке она откроется в полный размер в новом окне
Отчет можно экспортировать в PDF, отправить по e-mail или предоставить клиенту как собственный аудит.
В отчете есть информация о SEO-показателях страницы, о ссылающихся бэклинках и исходящих ссылках, скорости загрузки страницы и прочих технических нюансах.
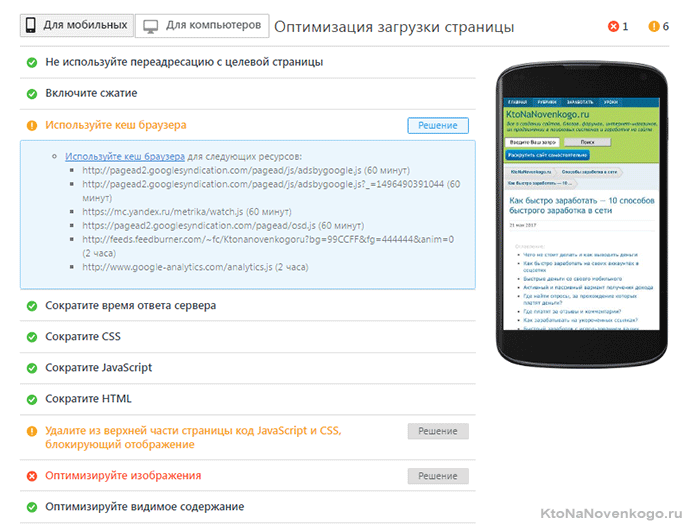
Отображается информация о популярности страницы и сайта в целом в соцсетях.
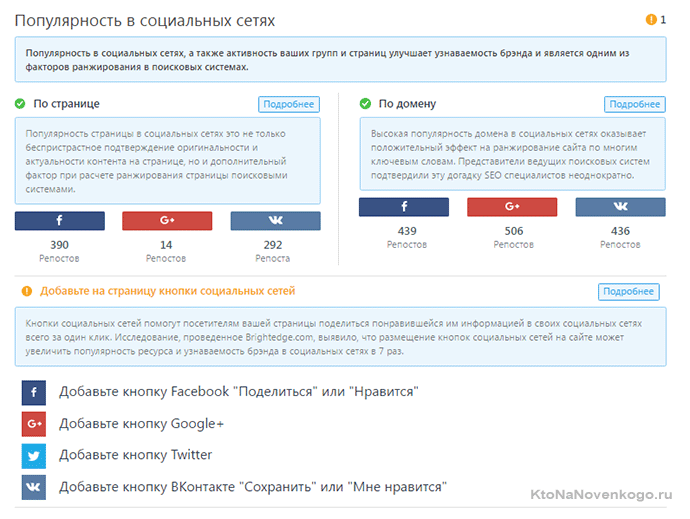
Комплексный и разносторонний SEO-аудит страницы от SE Ranking подскажет, что и как поменять на ней, чтобы улучшить ее ранжирование. В сервисе также можно проанализировать сайт полностью. Эти знания можно использовать для его дальнейшего развития.
Кластеризация ключевиков
Система полностью автоматизирована. Она распределяет ключевые слова по кластерам на основе анализа ТОП-10 поисковых систем. С помощью этого инструмента можно быстро распределить ключевики по сайту, избежать каннибализации, определить, какие запросы лучше ставить на главную, а какие – на внутренние страницы.
Есть масса настроек для дотошных SEO-оптимизаторов, например, точность кластеризации, регион, язык, список сайтов из ТОП-10 по запросу, проверка частотности (точное, фразовое и частотное соответствие), список выделенных слов на страницах выдачи ПС по заданному списку ключевиков.
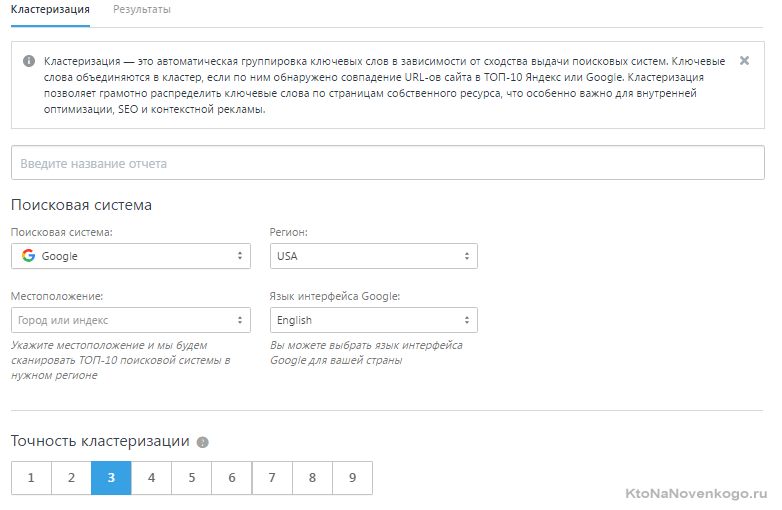
*при клике по картинке она откроется в полный размер в новом окне
Web-монитор
*при клике по картинке она откроется в полный размер в новом окне
Чтобы запустить мониторинг, необходимо добавить список страниц, для которых требуется отслеживание. Система наблюдает за изменением контента, мета-тегов, входящих и исходящих ссылок, индексации в Яндексе и Гугле и прочих параметров.
*при клике по картинке она откроется в полный размер в новом окне
С помощью гибких настроек вы можете задать периодическое сканирование (раз в день/неделю/ месяц, в определенные дни) или запустить его в любой момент.
Анализ бэклинков
С помощью данного инструмента можно узнать:
- Какие бэклинки есть у вас или конкурента;
- Типы ссылок и объем его ссылочной массы;
- Информация о семантике продвижения (по каким запросам продвигается сайт-соперник, какие анкоры использует);
Информация о внешних ссылках обновляется 1 раз в неделю, и если они меняют свой статус, система оповещает об этом.
Анализ каждой входящей ссылки проверяется по 15 параметрам. Можно проверить свой сайт или ссылочную массу любого другого интернет-ресурса. Стоимость сбора бэклинков для одного сайта – 1$.
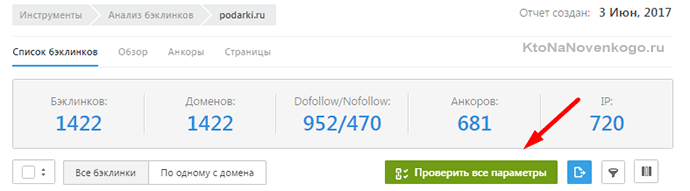
Доступна проверка параметров бэклинков и страниц, на которых они размещены. Можно узнать следующую информацию:
- популярность в социальных сетях;
- тИЦ страницы и сайта в целом;
- анкорный лист бэклинков;
- статус индексации в Google и Яндексе;
- статус ссылки (найдена или нет, код ответа сервера, закрыта ли в nofollow/noindex, в robots.txt);
- рейтинг сайта-донора по Moz, Alexa.
Мониторинг бэклинков
Можно отслеживать на графике, как меняется количество ссылок, просмотреть облако анкоров и оценить, на каких донорах какие анкоры используются. Вы увидите, как происходит прирост ссылочной массы, каков возраст бэклинков.
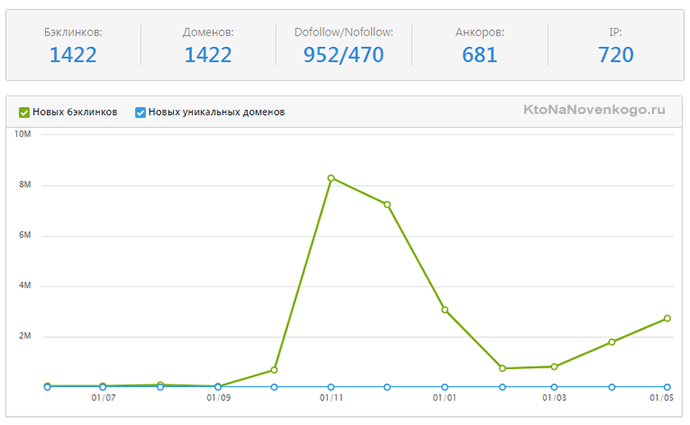
SEO потенциал
С помощью этого модуля можно оценить стоимость привлечения трафика из Google Adwords, количество потенциального трафика из органической выдачи, прогнозируемое количество лидов . Чтобы узнать число лидов, необходимо задать конверсию из посетителей в клиентов, стоимость каждого целевого действия.
Модуль позволяет оценить:
- потенциальный трафик на сайт;
- его стоимость, если бы использовалась для продвижения контекстная реклама в Google Adwords;
- потенциальное количество лидов.
Инструмент поможет определить:
- какое максимальное количество человек можно привести из органической выдачи;
- куда выгоднее инвестировать – в SEO или контекстную рекламу от Google Adwords.
Инструмент находится в разделе «Аналитика и трафик». Выберите проект, перейдите туда и выберите вкладку «SEO потенциал».
*при клике по картинке она откроется в полный размер в новом окне
Чем SE Ranking лучше аналогичных сервисов
Анализ действительно быстрый
В СеРанкинг на проверку более 5k страниц моего сайта ушло около 20 мин. Это отличный результат для облачного сервиса, в котором, кроме этого, есть целая группа других инструментов. И сам отчет получается глубоким и подробным.
*при клике по картинке она откроется в полный размер в новом окне
Обновленный дизайн сделал инструмент еще удобнее и приятнее в работе
В главной панели можно сходу увидеть общее состояние сайта. На общую оценку влияют мельчайшие ошибки, так что сразу не шарахайтесь, если у вас не 100 и даже не 80.
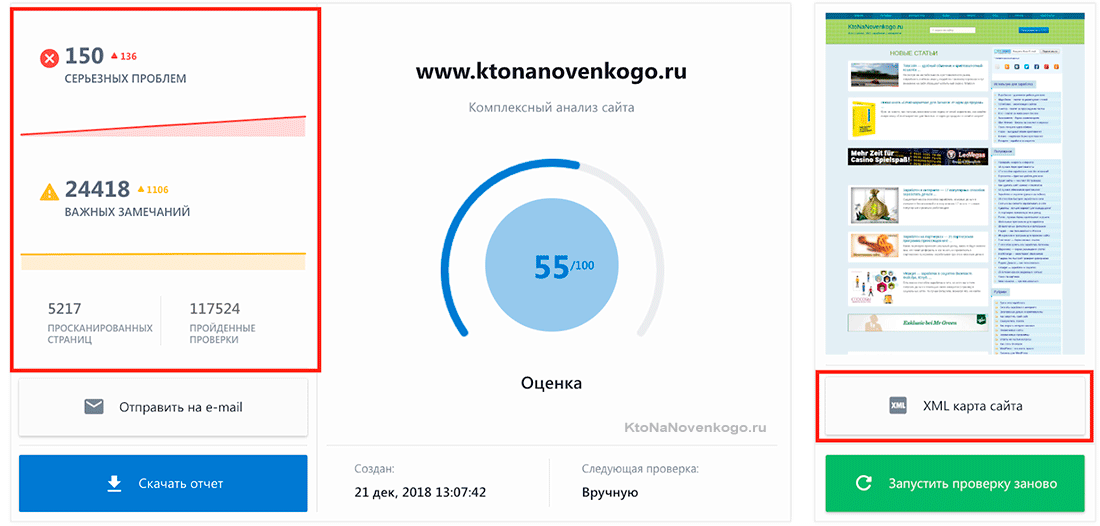
*при клике по картинке она откроется в полный размер в новом окне
Но самое главное, что сам отчет стал удобнее. В нем появилась навигация по разделам, и теперь всю самую нужную инфу можно узнать в два клика, не листая при этом полотно с данными туда-сюда.
Уже в меню видно, по каким разделам больше всего замечаний. Можно сразу перейти в эти блоки, а по ссылке возле каждого пункта с ошибкой посмотреть список URLов, к которым это относится.
*при клике по картинке она откроется в полный размер в новом окне
Анализ показал, что на моем сайте нет XML-карты и тут же предложил ее сгенерировать:

*при клике по картинке она откроется в полный размер в новом окне
И тут пригодилась классная штука – XML-карта в одно действие (в два, если хотите все настроить).
Для этого достаточно подняться к главной панели, нажать на кнопку (на скрине выше) и выбрать нужные настройки.
Подробный отчет по всем разделам технического SEO
Анализ включает 8 аспектов проверки по 70+ параметрам: оценку юзабилити, ссылок, контента, изображений, метатегов, общего тех.состояния – всевозможных нюансов, которые учитывает поисковой бот.
Новичкам будут полезны объяснялки к разным пунктам проверки: что и как нужно исправить. Например, информация, на каких именно страницах слишком массивные изображения и на сколько процентов их нужно уменьшить согласно PageSpeed Insights (и так по каждому пункту).
*при клике по картинке она откроется в полный размер в новом окне
Доступен отдельный экран работы с просканированными страницами
Наконец-то в модуле появилась возможность работать со списком просканированных страниц. На руки получаешь данные по каждому проверяемому элементу и метрикам.
*при клике по картинке она откроется в полный размер в новом окне
Из таблицы можно убрать ненужные метрики или отфильтровать по любой из них. Например, если хотите найти страницы с дублями, с большим количеством внешних ссылок, редиректами, разными контент-параметрами типа количества текста или длины заголовков – их можно найти в два клика. Убирайте колонки с теми метриками, которые вам не нужны. Так таблица станет более компактной и максимально информативной.

*при клике по картинке она откроется в полный размер в новом окне
Бот работает четко по правилам пользователя
Если начинка аудита – параметры проверки – не изменились, то в корне поменялся принцип работы бота. Теперь он полностью настраиваемый.
Настроить можно объем сканирования (какие страницы сайта охватывает анализ), работу анализатора (как и что он проверяет) и формат результатов (регулярность отчета, его полнота, вид).
По порядку.
Пользователь самостоятельно определяет, насколько глубоко пойдет бот. Доступные опции:
- Подключить к анализу поддомены;
- Открыть боту доступ к страницам, закрытым в robots.txt, или запретить ему сканировать URLы с определенным параметром (например, при A/B тестах);
- Открыть доступ к закрытым доменам (нужно будет дать логин и пароль);
- Загрузить свой список URLов для проверки.
Всё это можно определить в настройках источника страниц для сканирования, правилах проверки и настройках парсера:

*при клике по картинке она откроется в полный размер в новом окне
Кроме того, можно вручную установить количество обращений анализатора к серверу. На деле, если пользователю важно не перегружать сервер, а результаты аудита он готов подождать дольше, можно снизить количество обращения к серверу в секунду в разделе «Лимиты и ограничения».
Наконец, в самых спорных параметрах анализа пользователь может изменить допустимые значения. Например, инструмент по умолчанию будет считать ошибкой тайтл больше 70ти символов. У большинство статей на КтоНаНовенького тайтл от 100 до 150 символов, что оправдано информационным характером блога. Т.е. мне не нужно, чтобы тул отмечал каждую страницу с тайтлом больше 70ти. Теперь это не проблема. Можно вручную выставить диапазон значений по мета-тегам, H-тегам, количеству редиректов и ссылок со страницы. Последнее особенно актуально для сайтов-агрегаторов или даже для блогов с обзорными статьями по разным продуктам.
Теперь, когда мы разобрали, как можно регулировать охват и глубину анализа, а также учет ошибок, переходим к отчету.
Полный брендированный отчет об аудите улетает клиентам по расписанию
Нужно сказать, что отчетом я называю и общие результаты анализа, доступные в инструменте. И PDFку, в форме которой его можно экспортировать.
Так вот что касается результатов анализа – можно установить расписание автоматических проверок: раз в неделю или в месяц. Сделать это можно как в разделе «Настройки» (- «Расписание»), так и с помощью кнопки «Запустить проверку заново» на главной панели.
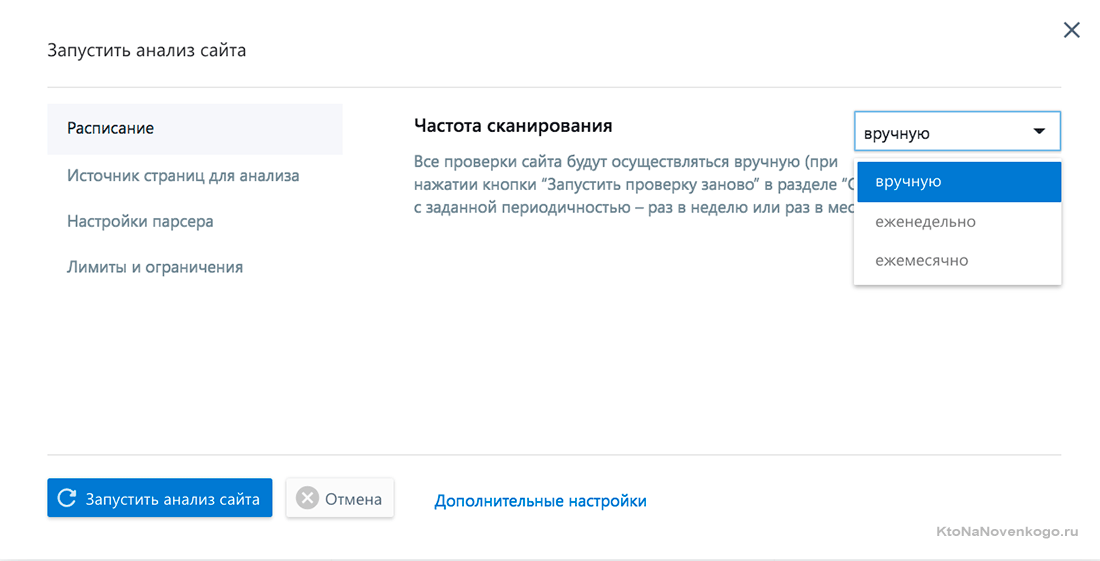
*при клике по картинке она откроется в полный размер в новом окне
Здесь же доступны другие основные настройки.
Короче, настроить можно все и отовсюду.
Что касается PDFки, то ее можно даже забрендировать, если воспользоваться тулами того же SE Ranking – White Label или еще одним инструментом платформы – Отчеты.
В случае с White Label можно персонализировать всю систему, чтобы и общие отчеты, и отчеты по разделам (например, по позициям или бэклинкам) не выдавали источник – SE Ranking, – а были подписаны именем и украшены логотипом Вашей компании.
*при клике по картинке она откроется в полный размер в новом окне
То же самое с инструментом «Отчеты».
ЛАЙФХАК для тех, кто хочет автоматом рассылать отчет на несколько емейлов
Если хотите получать свежий отчет по аудиту сайта еженедельно не только на свою почту, но и на емейлы коллег, нужно пойти по такому маршруту:
Отчеты ➝ Автоматические ➝ +Создать отчет
Увидите окно конструктора:
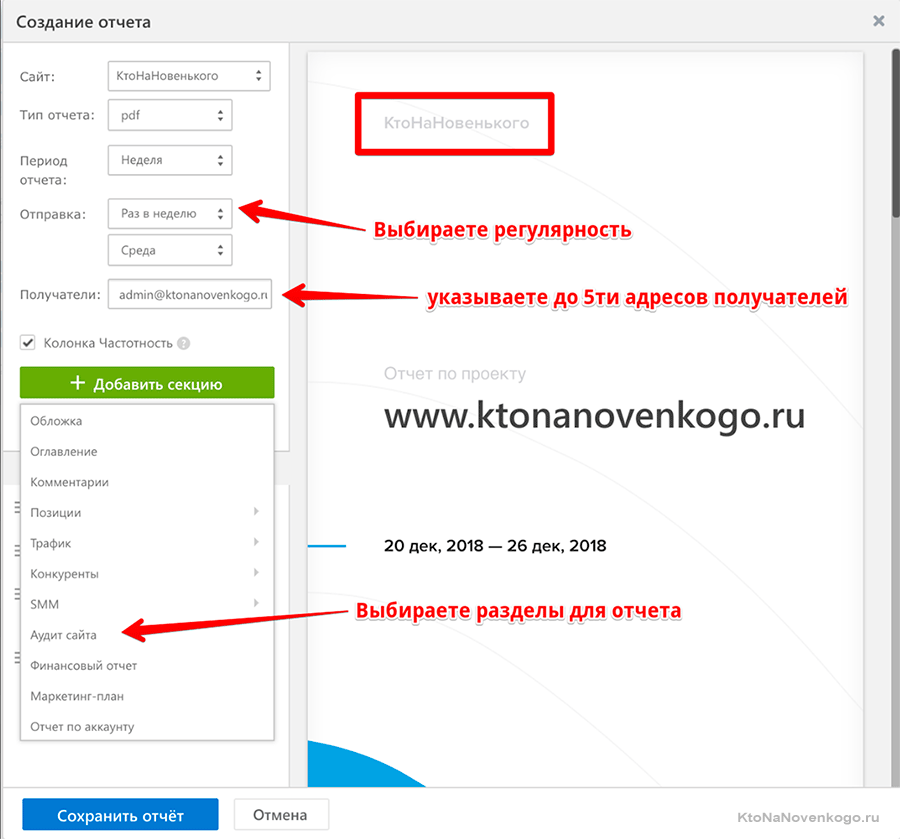
*при клике по картинке она откроется в полный размер в новом окне
В настройках отчета включаете в него те разделы, которые хотите показать коллегам и вводите емейлы адресатов. Бесплатно можно указать не больше 5ти.
Возвращаемся к главному экрану модуля «Отчеты». Жмем «Настройки», вписываем имя своей компании и добавляем лого.
![]()
Все. Теперь ваш отчет по аудиту будет каждую неделю уходить по адресам, которые вы указали в настройках.
Выводы
SE Ranking – это мощный инструментарий, обернутый в интуитивно простой интерфейс. С ним вы легко проанализируете сайт по огромному количеству параметров и сформируете профессиональный отчет для клиента на продвижение, сможете адекватно и максимально точно отслеживать эффективность SEO-стратегий, исправлять ошибки сайта и так далее.
SE Ranking прост в освоении и подойдет даже начинающему оптимизатору. Хотя и профи не останутся к нему равнодушными, так как сервис экономит время. К тому же, каждые 1-2 месяца выходят ощутимые обновления: базы по странам для анализа конкурентов, новые инструменты (такие как лидогенератор), фильтры для внешних ссылок. Так что управляться с проектами любой сложности становится еще проще.
Rankinity — сервис проверки позиций сайта в режиме реального времени
Если вам необходим сервис, который будет точно и быстро показывать позиции вашего сайта в поисковых системах. То к вашему вниманию сервис проверки позиций Rankinity.ru.

Сервис действительно точно определяет позиции в таких поисковых системах как Google и Яндекс, позволяет анализировать видимость конкурентов и имеет множество возможностей.
Основные возможности сервиса Rankinity
Проверка позиций в режиме реального времени
На данный момент, это первый сервис, который полностью работает в режиме реального времени.
Вы мгновенно получаете информацию о измененных позициях, без перегрузки страницы.
Если позиции по сайту изменились, то они автоматически обновятся в вашем браузере.Анализ конкурентов в результатах поиска
Сервис позволяет отслеживать позиции сайтов конкурентов в результатах поиска и делать их сравнение.
В итоге мы видим динамику по самым основным конкурентам и может хорошо анализировать нишу по вашему сайту.Разные поисковые системы
Сейчас система проверяет позиции в поисковых системах Google и Яндекс.
Точная проверка в Яндекс
В Rankinity можно указать нужный регион и точно проверять по нему позиции по сайту.
Проверка в Google
Тем, кто продвигают сайты под разные регионы, сервис крайне полезен. В Rankinity можно проверять позиции по всем странам и регионам, в которых есть Google.
Локальная проверка позиций
Как уже было сказано выше, сервис позволяет проверять позиций по любым странам и городам.
Это возможно как в Google, так и в поисковой системе Яндекс.Совместная работа над проектом
В системе можно дать данные о вашем проекте вашим сотрудникам или исполнителям.
Как в Google Analytics можно расшарить доступ для пользователей, так и в системе Rankinity можно дать доступ любому зарегистрированному пользователю, если вы захотите.
Если один из участников проекта добавляет ключевые слова, то другие это сразу же смогу увидеть.
Таким образом совместная работа по проектам становится более удобной и эффективной.Гибкие интервалы проверки позиций
Часто для проектов нет смысла проверять позиции ежедневно, и в Rankinity можно самому задавать интервал проверки.
Частоту сканирования можно вернуть в любое время, а сокращение интервала сканирования даст значительную экономию бюджета на проверке позиций сайта.
Это касается больше крупных проектов, у которых многотысячные ядра ключевых запросов, и нужно постоянно смотреть динамику и видимость.
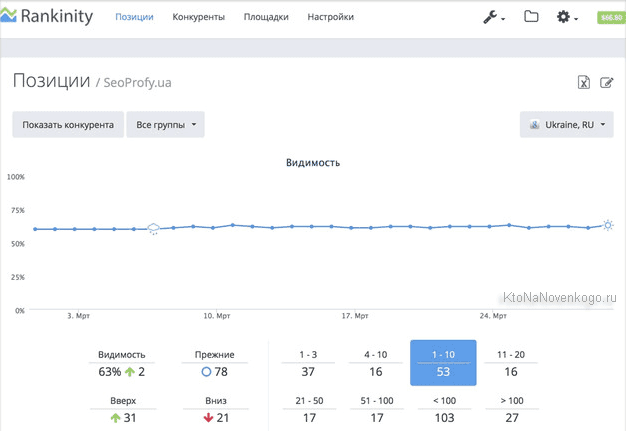
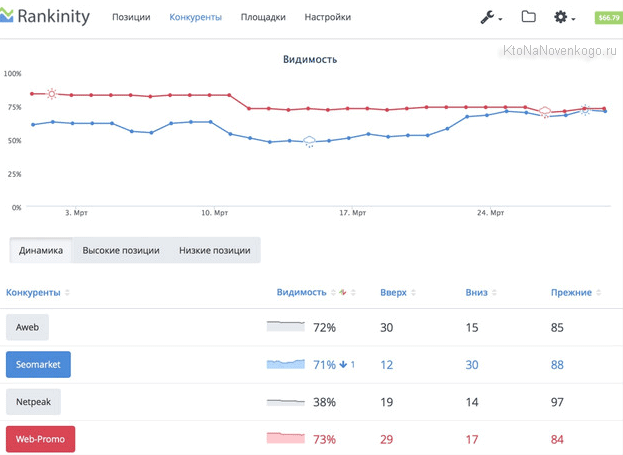
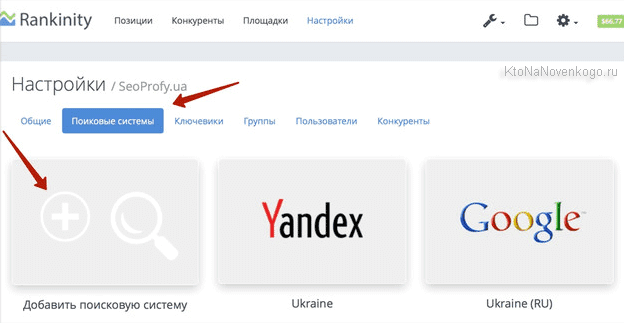
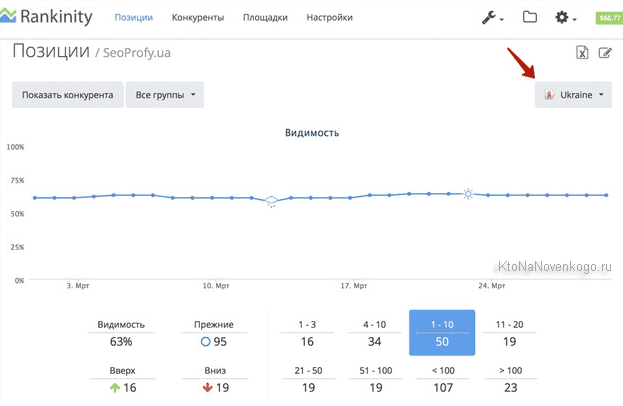
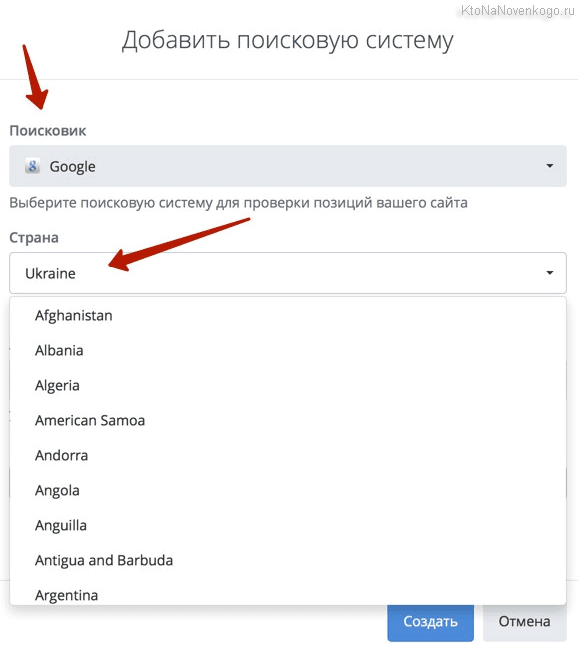
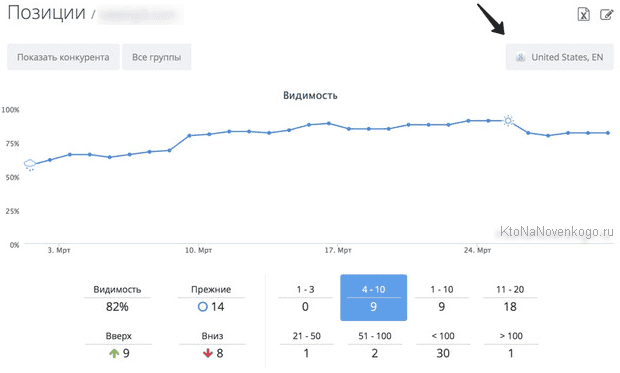

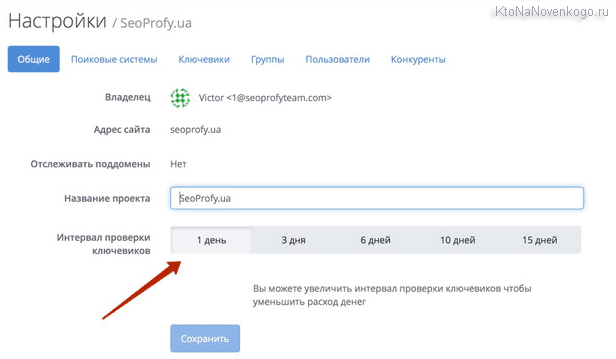
Дополнительные возможности Rankinity
Объединение ключевых слов по группам
Ключевые слова можно легко разбить по необходимым группам, и смотреть видимость по каждой конкретной группе ключевых слов.
Если у вас крупный сайт или интернет магазин, у которого множество направлений, то эта возможность дает лучше анализировать динамику по каждому из направлений.Назначение веса ключевым словам
Вы сами можете назначать, какой вес какая группа ключевых слов будет иметь. Например:
— есть приоритетные направления и запросы
— а есть менее приоритетныеВ системе вы сами можете назначить эти параметры, что даст более четкое виденье роста проекта.
В итоге, вы видите изменения на основании ваших личных приоритетов по сайту.Инфографика быстрого обзора позиций
По каждому ключевому слову автоматически формируется график роста ключевого слова.
Что дает возможность быстро увидеть текущее положение дел по продвигаемым ключевым словам.Анализ ТОП 100 поисковой выдачи по ключевому слову
Сервис сканирует топ 100 по каждому ключевому слову, что позволяет быстро и наглядно смотреть другие результаты поиска.
Гибкая оплата
В Rankinity не нужно ежемесячно вносить одну и ту же сумму. Вы платите только за то, что проверяете в системе.
В итоге очень удобно платить только за реальные проверки, а не абонентскую оплату в месяц.Технология Rankinity
В отличие от конкурентов, Rankinity не использует прокси-сервера для проверки позиций.
Вместо этого применяется уникальная технология полной эмуляции действий пользователя на специально сконфигурированных серверах, что обеспечивает максимальную точность результатов проверки.
При проверке каждого слова запускается браузер, открывается страница поисковика, выставляются все необходимые настройки местоположения и выполняется непосредственный поиск, а затем сбор данных.
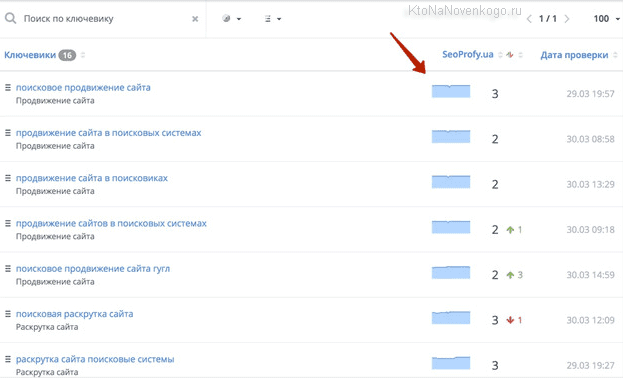
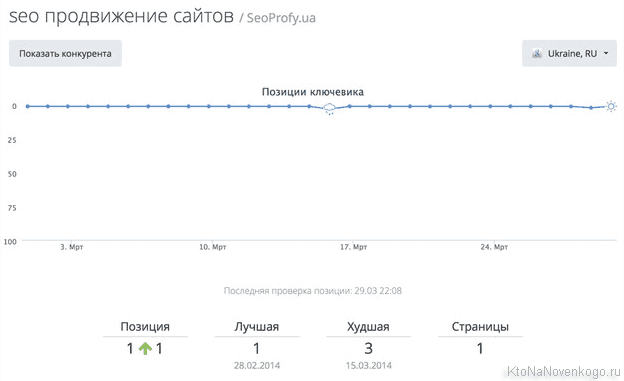
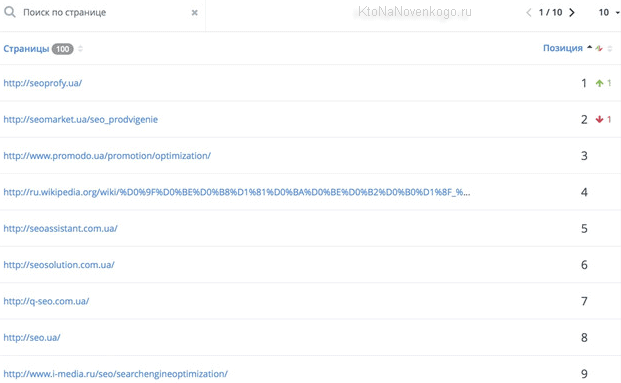
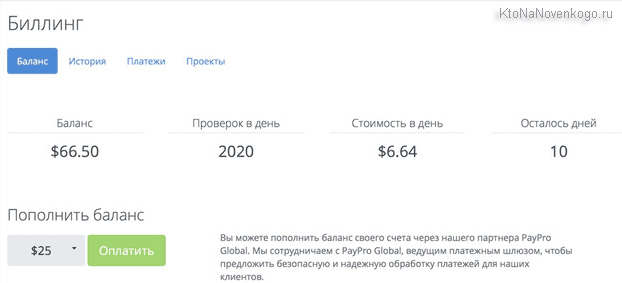
Таким образом, с точки зрения поисковой системы, проверка позиций не отличается от действий реального пользователя. Это и позволяет Rankinity получать максимально точную поисковую выдачу и точно определять в ней позиции, как вашего сайта, так и сайтов конкурентов.
PS: все, кто сейчас зарегистрируется в Rankinity, получат на счет 5$. Это дает возможность протестировать сервис.
Проверка позиций сайта бесплатно в Majento PositionMeter
Сегодняшний SEO-оптимизатор имеет множество различных аналитических инструментов, с помощью которых можно осуществлять снятие позиций по запросам, подбор ключевых слов, получение статистических данных и т.п., однако не все из них удобны и практичны в использовании, а также не все обладают набором необходимых повседневных функций.
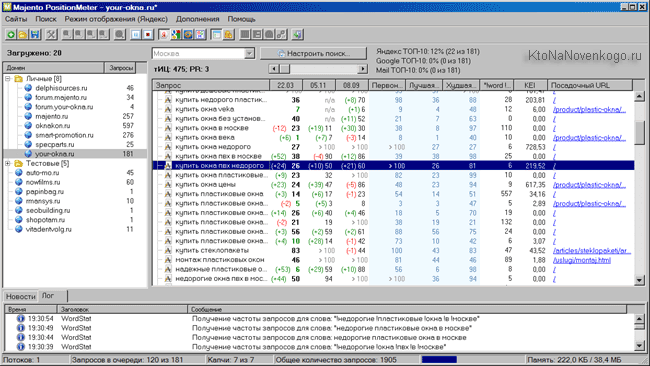
Поэтому, зачастую, оптимизатор вынужден пользоваться одновременно несколькими программами, что, согласитесь, не всегда удобно, и что немаловажно – не всегда бесплатно. Казалось бы, бесплатный продукт не может сравниться по качеству с его платными аналогами. Однако и в данном правиле есть исключения, и это исключение – Majento PositionMeter.
Что под капотом у Majento PositionMeter?
Основная задача данной программы – проверка позиций сайтов в наиболее популярных поисковых системах Яндекс, Google, Mail.ru (при этом поддерживается сканирование запросов с учетом регионов как для Яндекс, так и для Гугла, а также имеется возможность отображения позиций сайта с учетом его поддоменов).
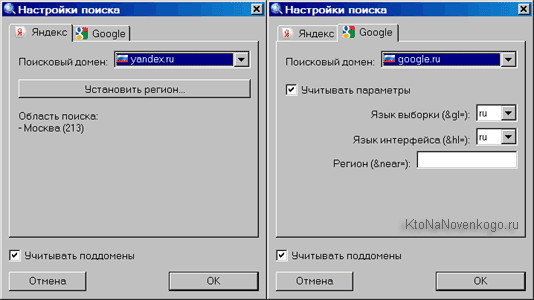
Для автоматизации массовой проверки позиций и избавления пользователя от ручного разгадывания капч, в программе реализована работа с такими сервисами, как Яндекс.XML, ruCaptcha, AntiGate + есть возможность использования списка прокси-серверов для проверки большого количества запросов.
Кроме основного функционала по проверке позиций сайтов, в программе имеется дополнительный набор полезных фишек:
- расчет конкурентности (KEI) и стоимости продвижения запроса
- массовый сбор статистики по Яндекс.Wordstat (с учетом региональности)
- определение посадочных страниц для продвигаемых запросов
- массовая проверка индексации URL
- проверка обратных ссылок на сайт
- массовое определение параметров Яндекс тИЦ и Google Page Rank
- отчеты и графики по динамике позиций
- экспорт отчетов в Excel, CSV и TXT формат
Также в программе имеется набор графических отчетов для визуального анализа. Например, график позиций в ТОП отобразит распределение запросов в ТОП-10, а график позиций сайта даст наглядную картину положения сайта в интересующих поисковых системах.
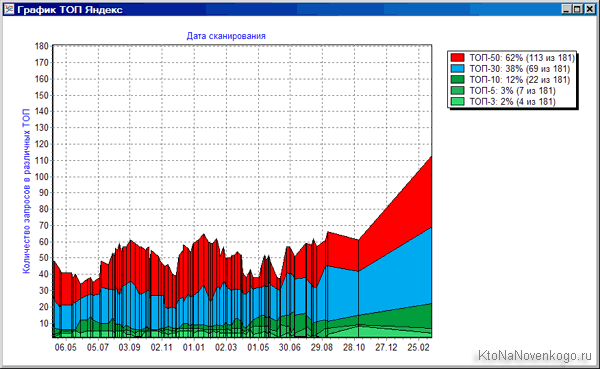
Сама программа имеет портативный формат, т.е. работает без установки на ПК или прямо со сменного носителя, что согласитесь очень удобно.
Таким образом, оптимизатор получает широкий набор инструментов для работы с поисковыми запросами, и все это – совершенно бесплатно! (это же подтверждено и на сайте программы).
P.S. Судя по частоте обновления версий, программа постоянно дорабатывается и улучшается, а также периодически пополняется новым функционалом, что, согласитесь, не маловажно, учитывая бесплатность продукта.
Ссылка на страницу программы: https://www.majento.ru/index.php?page=majento-soft
Ссылка на документацию: https://www.majento.ru/index.php?page=majento-soft-pm-help
Интересно будет услышать ваше мнение об этом инструменте.
Словоеб — бесплатная программа для сбора семантического ядра
Порой нахлынет на тебя тоска зеленая… Начнет давить жаба болотная… Вот так и меня прихватило, когда увидел стоимость составления семантического ядра у профессионалов! А ведь можно и самому состряпать СЯ. Да и не только себе…
Чем собирают семантическое ядро?
Думаете, что семантическое ядро для сайта отбирается вручную? Поэтому и цены такие? Да нет! СЯ собирается «мануально» только на первом этапе сборки. А затем используется «программный» труд… Но обо всем по порядку!
Цель данного материала – понять, как происходит сборка ядра, какие инструменты используются, сколько они стоят. В общем, насколько тяжело компонуется СЯ и что для этого надо (кроме времени и усердия).
Уточнение: мы будем применять минимальный набор средств, необходимых для подбора ключевых слов. При возможности используем бесплатный инструментарий. А если таковых нет, то автору придется раскошеливаться 🙂 .
Чтобы получить набор базовых ключей, поработаем вручную. При этом будем использовать Яндекс.Вордстат. Выбираем синонимы ключевиков и новые словоформы из правой колонки.
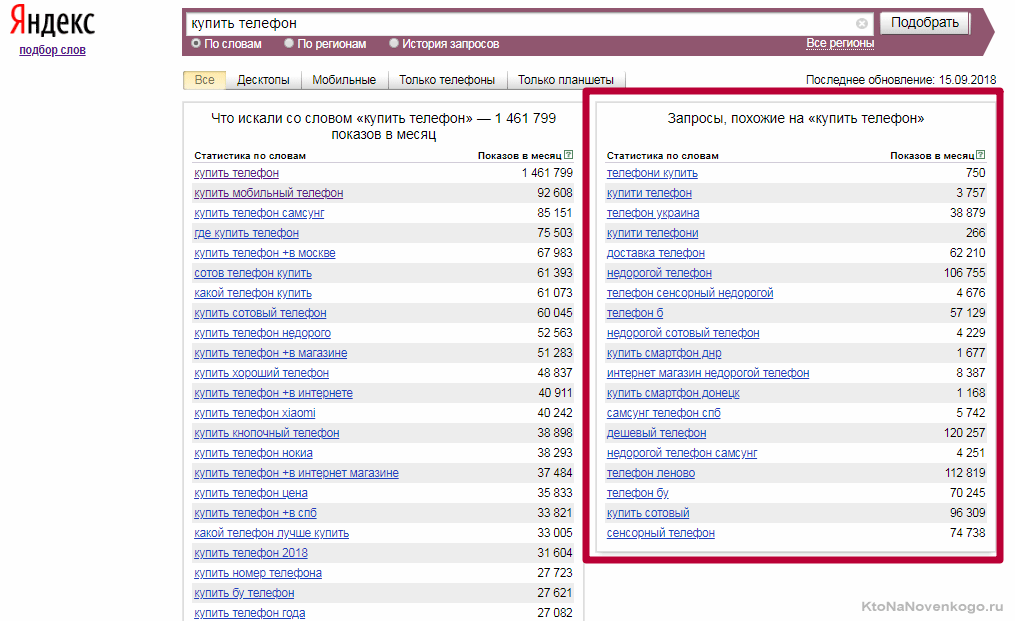
*при клике по картинке она откроется в полный размер в новом окне
Далее расширяем набор «зародыша СЯ» с помощью сервиса для анализа конкурентных площадок. То есть, узнаем, по каким ключам они продвигаются.
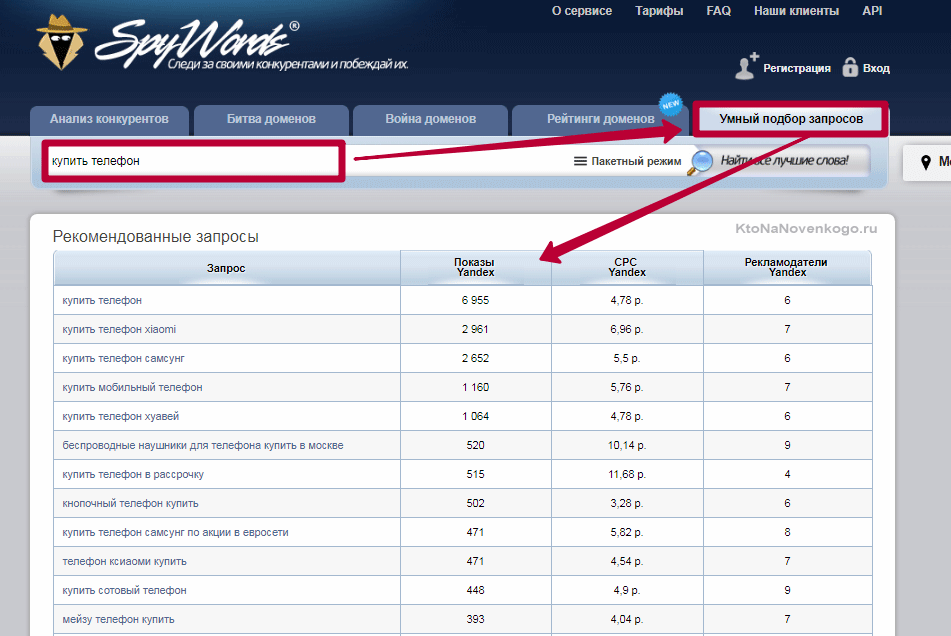
*при клике по картинке она откроется в полный размер в новом окне
Пример выдачи ключевиков на одном из сервисов анализа сторонних площадок.
Пару слов о выборе правильных словоформ и синонимом. Существует несколько тактик их сортировки: по регионам, сезонности, частоте… И более «заумные» стратегии. Причем каждый из семантиков-профи хвалит свою. Но, главное, при отборе правильно настроить собственную логику, отталкиваясь от направления и тематики сайта, для которого формируется СЯ.
Программа «Словоеб»
Это не наглые «происки» автора – так называется бесплатная лайтовая версия парсера Key Collector. Чего делает программа: анализирует базы данных ключей Вордстата и Google AdWords.
Но Словоеб послабее старшего брата и «просеивает» только словари Яндекса. Зато он халявный. Что немаловажно для «здоровья» кошелька начинающего составителя СЯ 🙂 .
Скачиваем эту «матерную» прогу и смотрим на ее интерфейс с широко «распростертыми» глазами.
*при клике по картинке она откроется в полный размер в новом окне
Затем создаем проект и сохраняем его в файловой системе ПК. После чего переходим в настройки приложения.
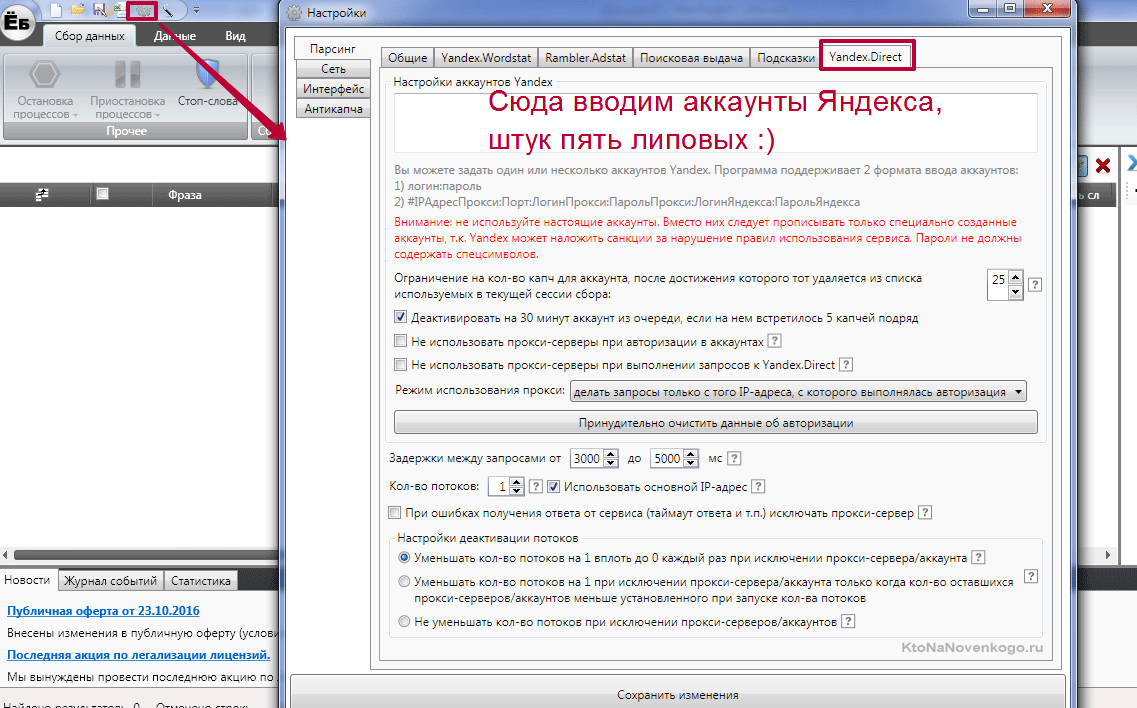
*при клике по картинке она откроется в полный размер в новом окне
В настройки программы закапываться нет нужды. В интернете полно инструкций по Словоебу. Поэтому не будет марать пространство веб-страниц пересказом, и сосредоточимся на важных моментах. Вот и настал первый момент: для дальнейшей работы проги нужны пять фейковых пользовательских профилей в Яндексе.
Не вздумайте вводить свой настоящий! Я знаю, каким образом легко заполучить эти аккаунты. Но об этом позже. Идем традиционным путем: регистрируем 5 почтовых ящиков на Яндексе, запоминаем их логины и пароли.
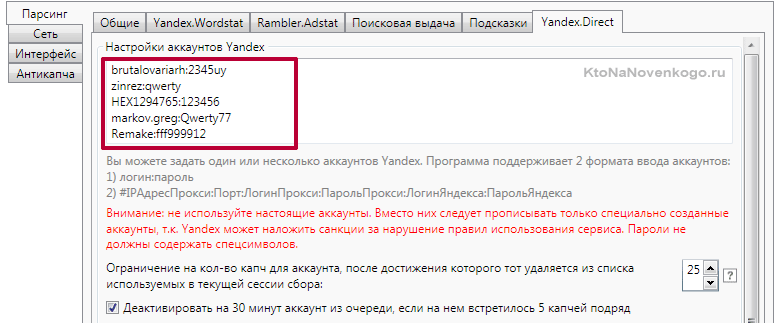
*при клике по картинке она откроется в полный размер в новом окне
Подключаем прокси к Словоебу
Бесплатный сыр и мышеловка.
При составлении семантического ядра не всегда удается избежать траты. Если не подключить сервис антикапчи, то придется долго мучатся. Поэтому тратим свои кровные средства.
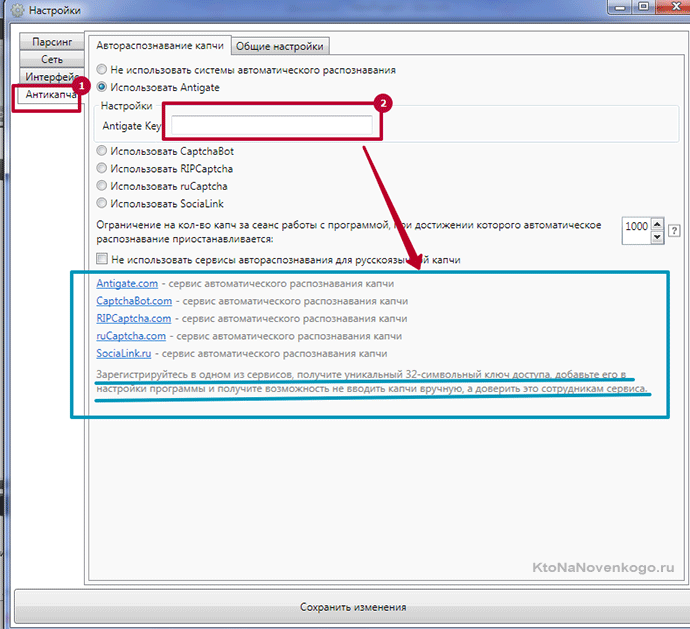
Еще потребуются прокси-серверы, чтобы осуществлять множественные автоматические запросы к словарям Вордстата. Почему прокси? Потому что поисковые систему уже давно и успешно борются с парсингом.
Если не использовать прокси-серверы, то не только изучите все типы капч от Яндекса и Google, но и получите бан на IP. А это уже серьезно. Особенно если у вас статический айпишник.
Чтобы скрыть IP и безопасно использовать множественные многопоточные запросы к Вордстату (через несколько аккаунтов Яндекса), требуется прокси…
Есть же бесплатные – зачем покупать?
И такое мнение бытует! Только Яндекс далеко «не дурак», и не хило палит заюзанные бесплатные прокси-серверы. Да и обеспечивают они медленную скорость обмена данными.
Но такой расклад точно не прельщает. Почему? Ведь мы собираемся заниматься составлением СЯ на профессиональной основе. На программе-парсере еще можно сэкономить (и то в начале карьеры семантика). А на прокси-серверах – лучше не стоит!
Покупая прокси на определенный срок, вы арендуете множество IP. Благодаря чему поисковой системе «кажется», что запросы поступают от разных пользователей. Никакой блокировки, и никаких капч… По крайней мере, если использовать серверы от Proxy-Sale.
Почему этот сервис:
- Предоставляет специализированные прокси под семантические парсеры (и не только).
- Поштучная продажа на минимальный срок – от 1 недели.
- Чем больше приобретаешь, тем меньше стоимость.
Proxy-Sale пользуются многие вебмастера.
*при клике по картинке она откроется в полный размер в новом окне - При приобретении прокси предоставляет бесплатные пользовательские профили Яндекса.
Настройки Словоеба для непрерывного парсинга
После покупки прокси на Proxy-Sale снова заходим в настройки Словоеба (вкладка «Сеть»).
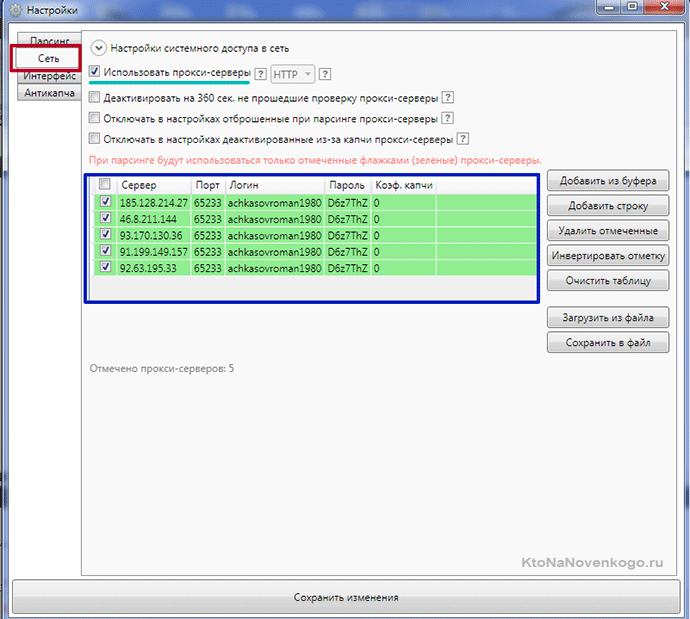
Не забываем сохранять изменения.
Активируем опцию «Использовать прокси-серверы» и вводим в текстовое поле полученные на указанный email прокси. Затем задействуем все приобретенные серверы (работающие отмечены зеленым цветом).
Закрываем окно настроек. Переходим в основной интерфейс программы. В меню сверху выбираем источник для парсинга (правая колонка Вордстат).
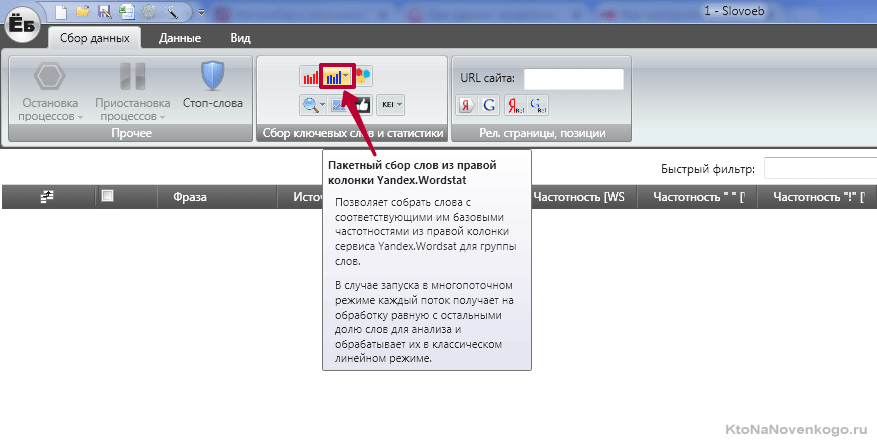
*при клике по картинке она откроется в полный размер в новом окне
После чего вводим первоначально собранные базисы и нажимаем кнопку «Начать сбор».
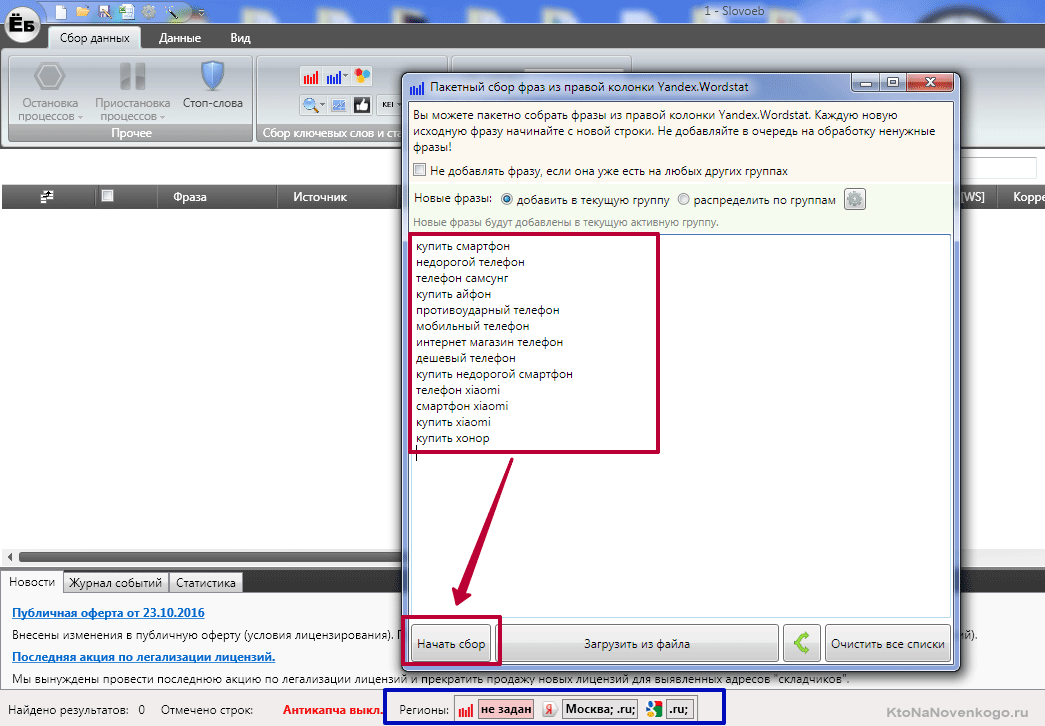
*при клике по картинке она откроется в полный размер в новом окне
Если нужно, внизу можно задать регион и доменную зону парсинга.
Затем фильтруем выдачу ключей по стоп-словам.
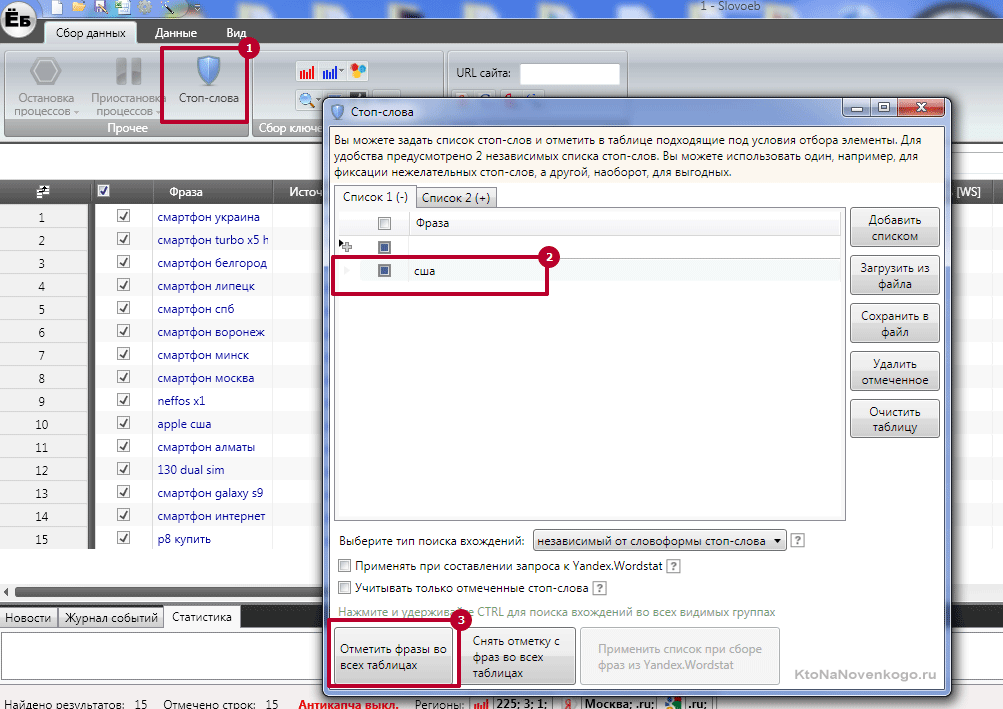
*при клике по картинке она откроется в полный размер в новом окне
Напоследок определяем частотность ключей и удаляем «пустые».
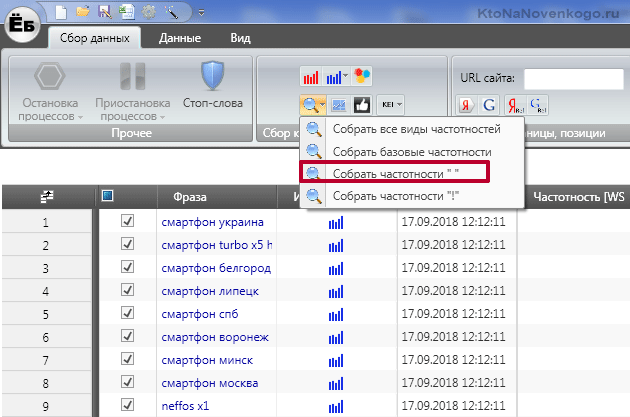
Вот так работают семантики! При этом уровень их профессионализма в большей степени зависит от качества используемых прокси для Кей Коллектора, поэтому на них не стоит экономить. У нас были прокси-серверы «бизнес-класса», поэтому Словоеб летал как Боинг последней модели.
Выводы
Обзор процесса сборки СЯ получился в стиле «галопом по Европам». Множество настроек парсера и всякие тонкости остались за кадром. Но, главное, что мы поняли, как происходит сбор семантического ядра на практике. Понятно, что сразу зарабатывать миллионы на этом деле не получится. Но скомпоновать семантику для небольшого сайтика нам уже под силу!
Комментарии и отзывы (4)
«Уж не знаю, почему, но моя муза, наверное, улетела отдыхать на моря. Авторское вдохновение потихоньку иссякло, и я не могу нарыть тем для новых материалов»
Как вариант, — попробуйте (для разнообразия) написать что-то, не связанное с деньгами и заработком, а так: просто, честно и от сердца (без seo, ключевых слов и прочей ерунды). Заодно посмотрим, сколько будет комментариев под статьей? 🙂
Поддерживаю Андрея! Даёшь старый добрый «каменный век». Тогда статьи здесь были душевнее.
Спасибо большое за статью! XMLRiver использую в КК4, но что у них есть ещё своя утилита не знал. Сейчас потестим )
Спасибо
Ваш комментарий или отзыв